mongodb如何避免长时间停留在 STARTUP2 状态
>故障演示故障处理结果案例重现数据准备搭建副本集添加15G的数据(还原备份)过了一会儿(40多分钟),还原完成查看数据情况,oplog.rs大小为9G直接添加新节点测试添加新节点D查看节点D状态查看window资源占用情况运行结果如何避免长时间停留在 STARTUP2 状态?测试一:收缩 oplog.rs 大小(无明显效果)移除节点D,回到ABC原始的三个节点收缩 oplog.rs 大小为 2000M添加节点D(不需要停止节点D服务,不清空上一步骤的 dbpath 文件夹)移除节点D,回到ABC原始的三个节点再次收缩 oplog.rs 大小为2000M再次添加节点D(停止节点D服务,然后清空上一步骤的 dbpath 文件夹,再启动节点D服务)将 oplog 文件大小还原为20G测试二:将集群主节点转为单实例并清空其他节点的dbpath文件夹(有用)将集群服务(所有节点)停止打开主节点A的 mongodb.conf 删掉 replSet=testrs 配置直接删除 local 库,然后停止节点A服务打开主节点A的 mongodb.conf 增加 replSet=testrs 配置然后启动节点ABC服务,验证是否是未搭建的副本集。重新搭建集群,并查看执行效果测试三:将集群主节点转为单实例但不清空文件(有用)停止节点ABC服务并修改三个节点的配置单独进入ABC三个节点服务器,删掉local库再次停止ABC三个节点并修改三个节点的配置验证是否是未搭建的副本集重新搭建集群,并查看执行效果测试四:绝对单实例准备三个单实例停止ABC三个节点,修改配置文件进到节点A的 mongodb 环境进行集群配置其他问题单实例 show dbs 出现 not master and slaveOk=false如何重置集群环境?移除副本节点后,无法重新加回来了
为什么 mongodb 集群的副本节点B状态一直处于STARTUP2?
简答:该副本节点B正在向主节点同步数据,过段时间同步完之后就会自动变成 SECONDARY 状态了。若副本节点处于 STARTUP2 状态,该节点可以进行投票(v5.0+就不可以了)但无法进行查询(命令查有时候是可以查出来的,但是集群不会把查询的命令分给副本节点B,因为此时节点B没同步完数据是不完整的)
故障演示:mongodb版本v5.0
A:主节点 1.5T 数据 oplog.rs 大小有 50G
B:副本节点 600G 数据
C:仲裁节点 2G 数据
集群一共由ABC三个节点组成,已运行1个月,有一天不知道脑子是抽了还是怎么的,把B节点的文件夹清空了,然后 rs.remove('B')将B节点移出集群,心想着等会再把B加回来就行了。
执行rs.add('B')后,再执行rs.status(),怎么B节点的状态不是 SECONDARY ?
mongodb 集群状态详解 Replica Set Member States — MongoDB Manual
后面我又加入一个节点D,发现也是如此,查了一下,原来新加入的节点要将主节点的数据同步下来,等同步完成后,该节点才会投入工作。
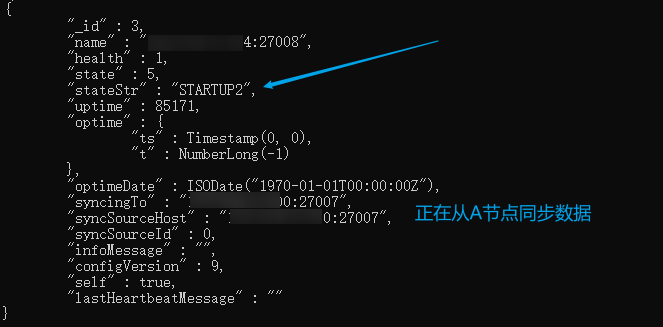
我们可以查看B节点的文件夹大小就可知道同步的进度了,通常这个文件大小会不断增大的直到同步完成。
但是我记得我之前将这1T的数据搭建副本集是没有 STARTUP2 状态的,不过当时这1T的数据是在单机mongo实例上的,当时直接把这个单实例直接转成副本集了,不知道是不是这个原因。
故障处理结果
上面我们讲到直接添加新副本节点,新节点同步数据需要耗费很长时间,状态一直停留在STARTUP2状态,主节点1.5T数据同步了48个小时都没完成,后面我用测试二 处理成功,而且比之前同步要快很多,代价是oplog记录被我删了,所以在同步前或者同步后最好能执行一次全量备份,但是mongodump和mongorestore对于大数据备份很慢。直接看图吧
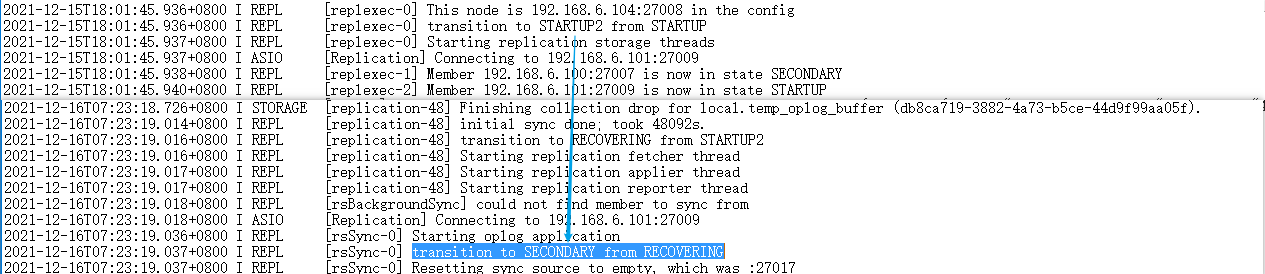
27008这个副本节点的状态变化:STARTUP—>STARTUP2—>RECOVERING—>SECONDARY
整个过程(停留 STARTUP2 状态)花费了近13个小时,这个要比之前快了两倍
案例重现
数据准备
搭建集群、还原数据
搭建副本集

添加15G的数据(还原备份)

过了一会儿(40多分钟),还原完成

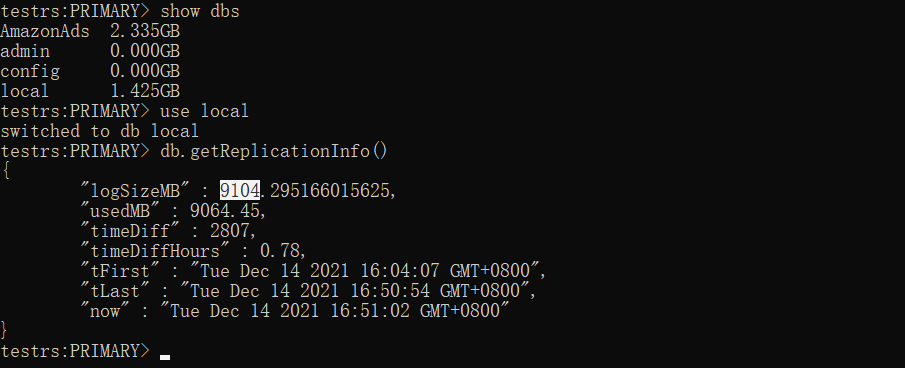
查看数据情况,oplog.rs大小为9G
直接添加新节点测试
添加新节点D
(建议新增一个节点测试,如果删除节点B,那么集群就只剩下2个节点了,很容易发生错误导致无法重新把副本节点B加回来,如下图的错误:rs.add()一直无响应,关于这个问题可以参考这个解决:移除副本节点后,无法重新加回来了)
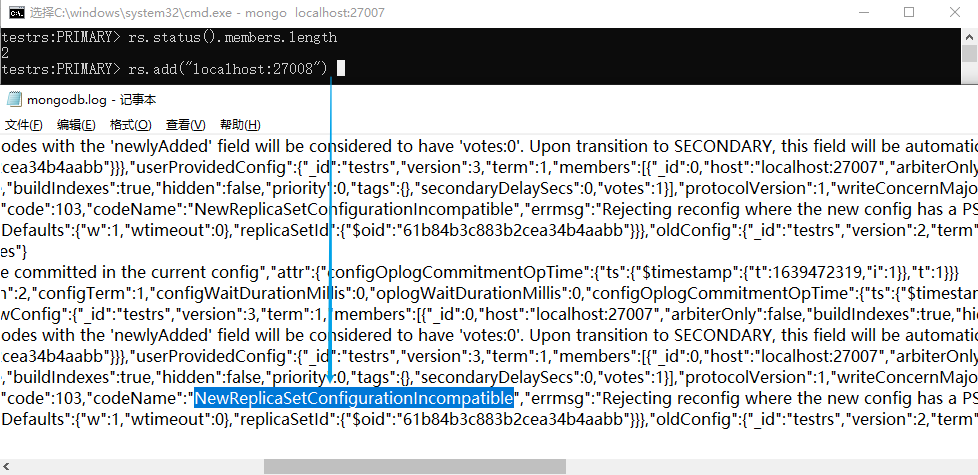
rs.add("localhost:27010") # 添加新节点D
查看节点D状态
状态长时间停留在 STARTUP2 上,当前正在同步数据
xxxxxxxxxx rs.status().members[rs.status().members.length - 1]
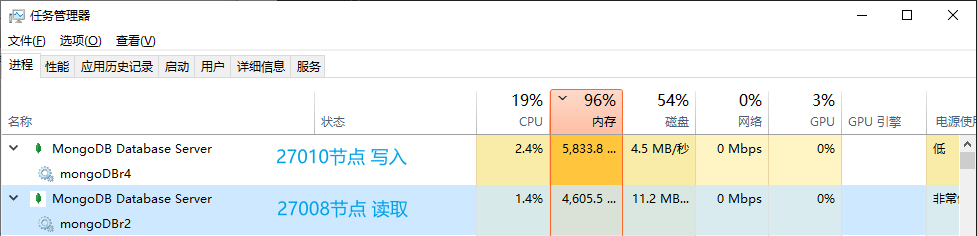
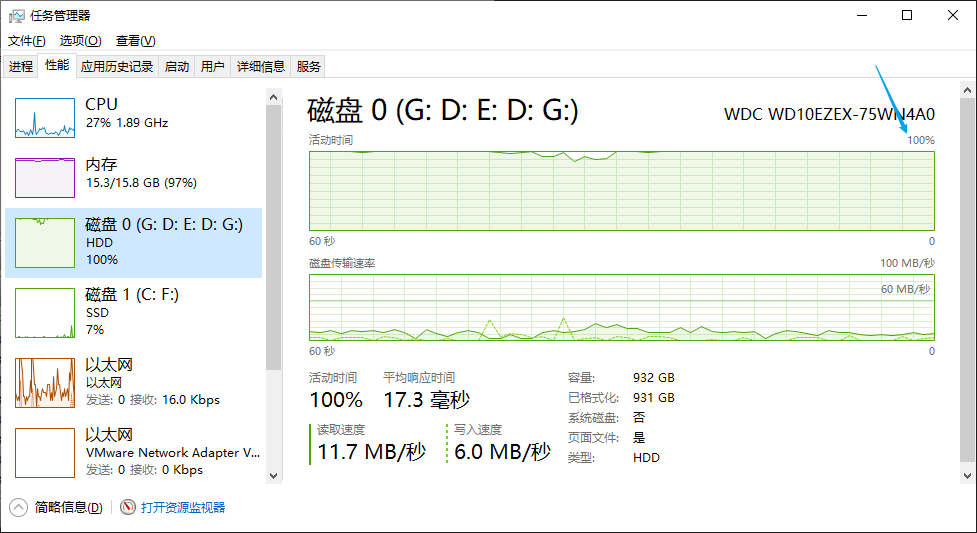
查看window资源占用情况
内存占满
磁盘跑满
运行结果
过了一会儿(数据:15G,oplog:9G 大概使用了10分钟)就自动变回 SECONDARY 状态了
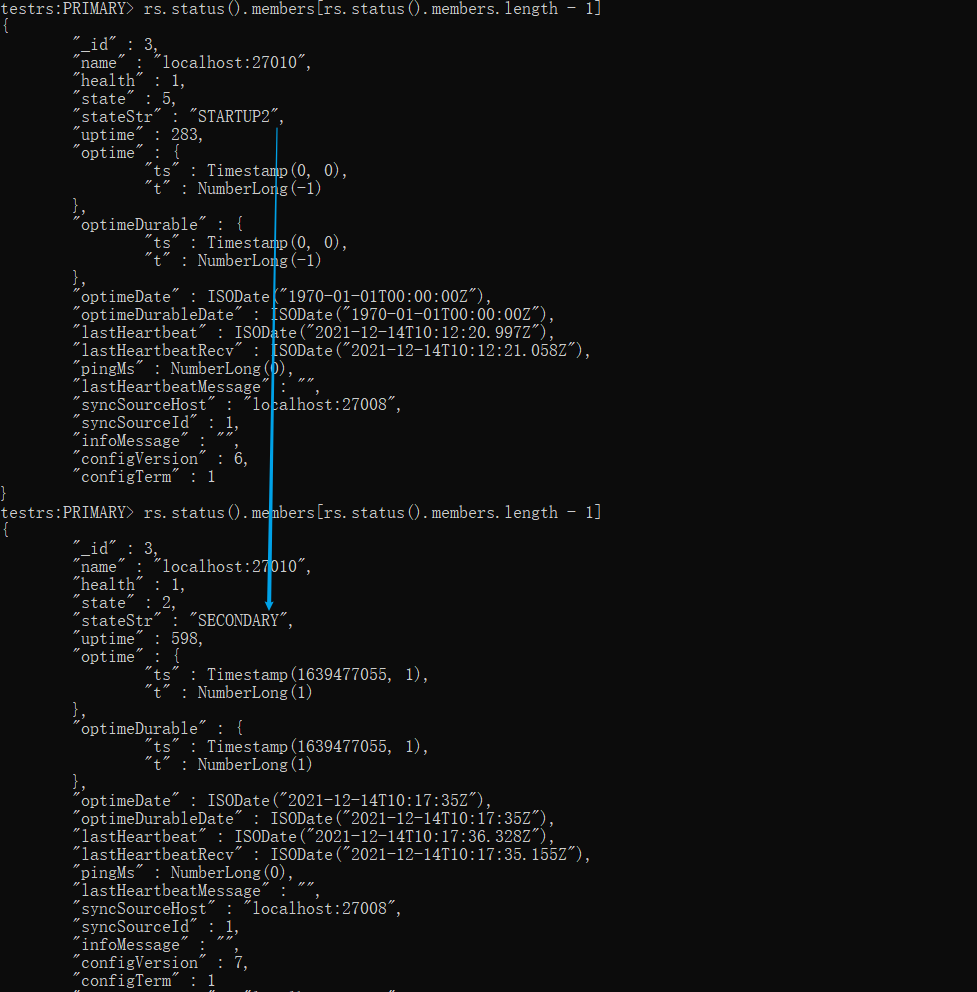
如何避免长时间停留在 STARTUP2 状态?
那有没有什么方法快速一点呢?避免长时间停留在 STARTUP2 状态呢?
测试一:收缩 oplog.rs 大小(无明显效果)
移除节点D,回到ABC原始的三个节点
xxxxxxxxxxrs.remove("localhost:27010")收缩 oplog.rs 大小为 2000M
参考:Mongodb在线修改oplog大小 - SegmentFault 思否
xxxxxxxxxxuse local# 查看当前oplog的大小db.oplog.rs.stats().maxSize# 收缩oplog的大小为2000M,最小为990Mdb.adminCommand({replSetResizeOplog: 1, size: 2000})# 查看当前复制集信息db.getReplicationInfo()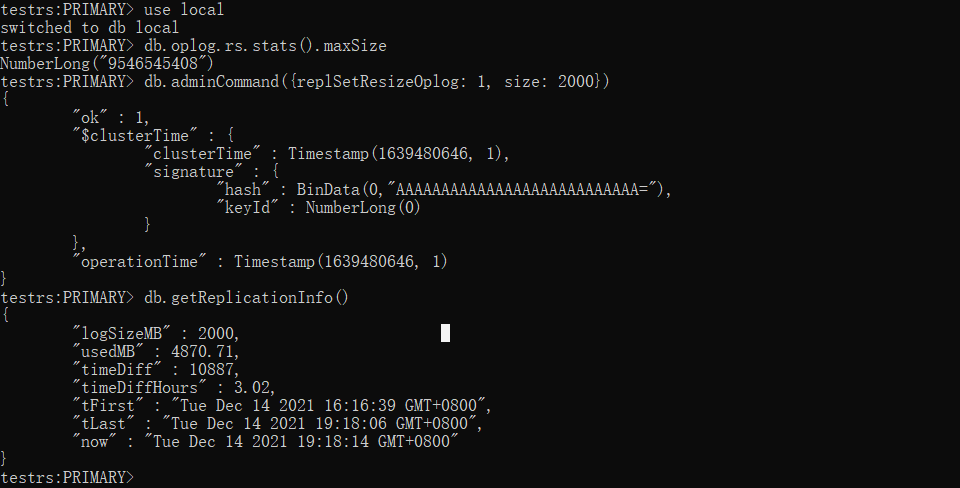
添加节点D(不需要停止节点D服务,不清空上一步骤的 dbpath 文件夹)
然后查看状态,居然没有长时间停留在 STARTUP2 状态上,很快就转为 SECONDARY 状态了,那是不是说明收缩 oplog.rs 是有效果的呢?我们再往下看
xxxxxxxxxx# 添加节点Drs.add("localhost:27010")# 查看节点D的状态rs.status().members[rs.status().members.length - 1]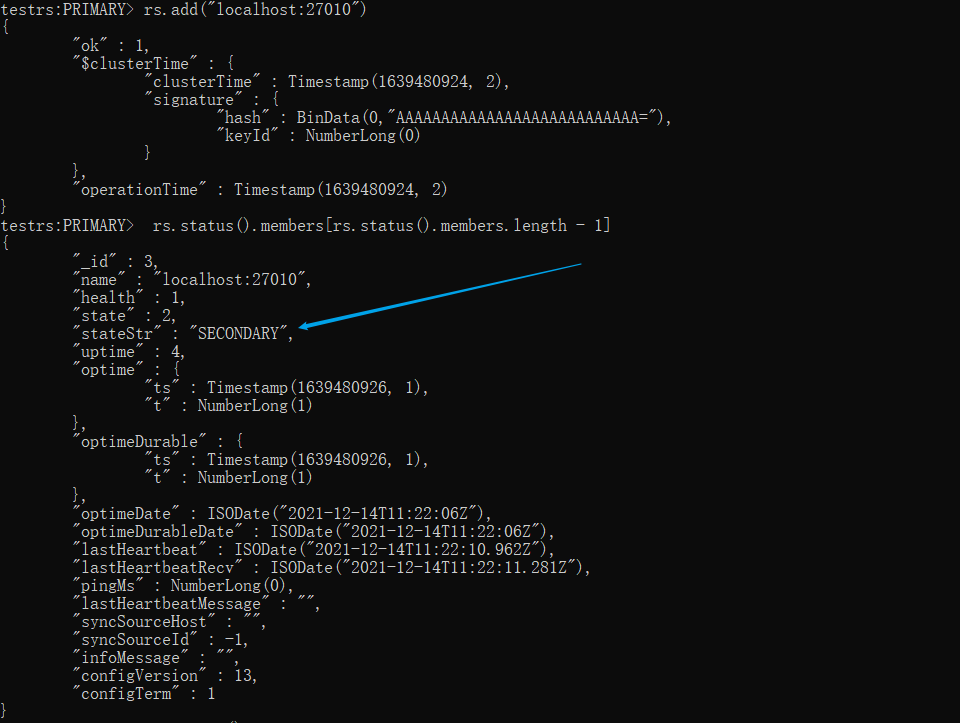
移除节点D,回到ABC原始的三个节点
xxxxxxxxxxrs.remove("localhost:27010")再次收缩 oplog.rs 大小为2000M
参考:Mongodb在线修改oplog大小 - SegmentFault 思否
xxxxxxxxxxuse local# 查看当前oplog的大小db.oplog.rs.stats().maxSize# 收缩oplog的大小为2000M,最小为990Mdb.adminCommand({replSetResizeOplog: 1, size: 2000})# 查看当前复制集信息db.getReplicationInfo()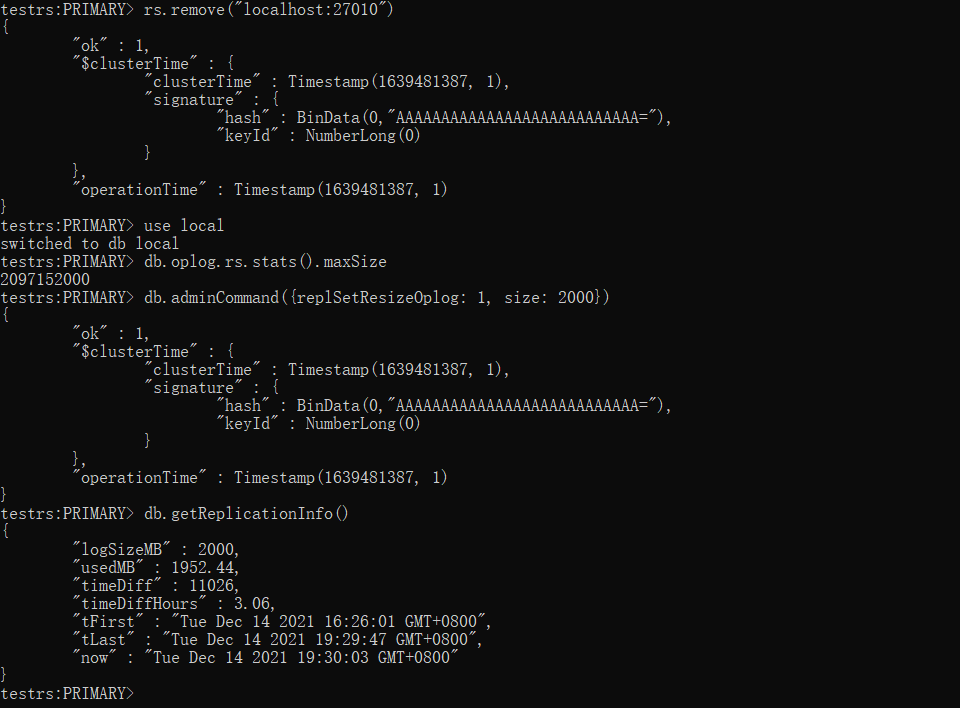
再次添加节点D(停止节点D服务,然后清空上一步骤的 dbpath 文件夹,再启动节点D服务)
然后查看状态。通过下图我们可以看到由 STARTUP2 转向 SECONDARY 也是花了将近10分钟(数据:15G,oplog:2G),所以这个 STARTUP2 状态应该和oplog 文件大小没有太大关系
xxxxxxxxxx# 添加节点Drs.add("localhost:27010")# 查看节点D的状态rs.status().members[rs.status().members.length - 1]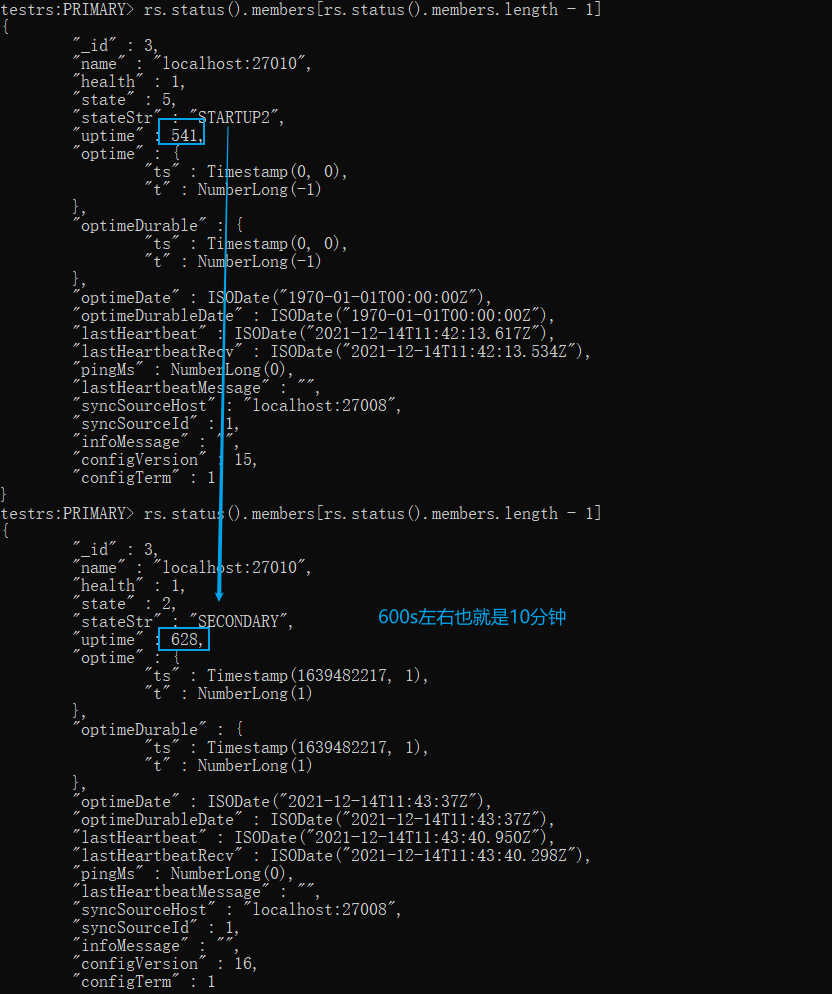
将 oplog 文件大小还原为20G
xxxxxxxxxxdb.adminCommand({replSetResizeOplog: 1, size: 20000})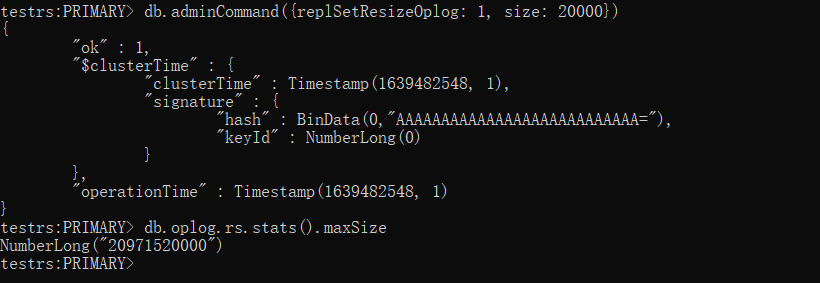
测试二:将集群主节点转为单实例并清空其他节点的dbpath文件夹(有用)
执行一次数据准备并搭建集群环境:节点ABC
将集群服务(所有节点)停止
xxxxxxxxxxuse admin# 等待执行结束就好了db.shutdownServer()打开主节点A的 mongodb.conf 删掉 replSet=testrs 配置
仅启动主节点A服务,以单实例启动,BC节点不要启动

进到节点A的 mongodb 环境,我们可以发现数据并未改变,而且 oplog.rs 大小也没有变小。
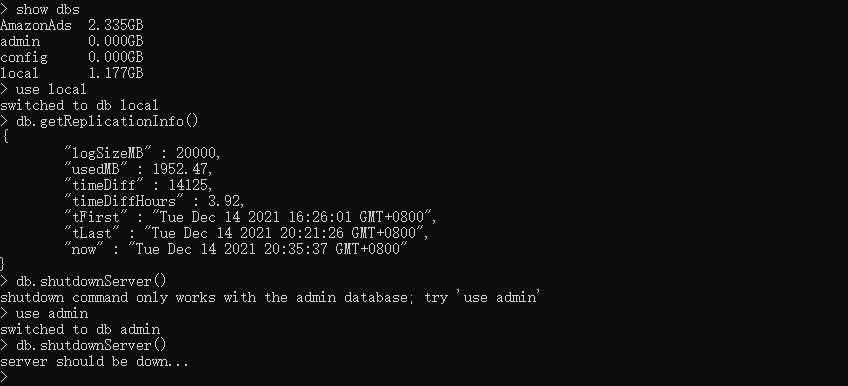
直接删除 local 库,然后停止节点A服务

打开主节点A的 mongodb.conf 增加 replSet=testrs 配置
再将节点B、C的dbpath文件夹和 mongodb.log 文件清空(一定要清空这两个副本节点的数据,不然主节点A启动后状态会变成 STARTUP2 状态)
然后启动节点ABC服务,验证是否是未搭建的副本集。
xxxxxxxxxx#进入到 mongodb环境mongo localhost:27007# 测试是否是未搭建的mongo复制集:执行下面这两条命令会报错rs.status()rs.conf()
重新搭建集群,并查看执行效果
搭建完后并检测节点状态,如下图我们看到整个集群差不多5分钟(数据:15G,oplog:无)就初始化同步完成了,这个速度要比上面的测试一快一倍。
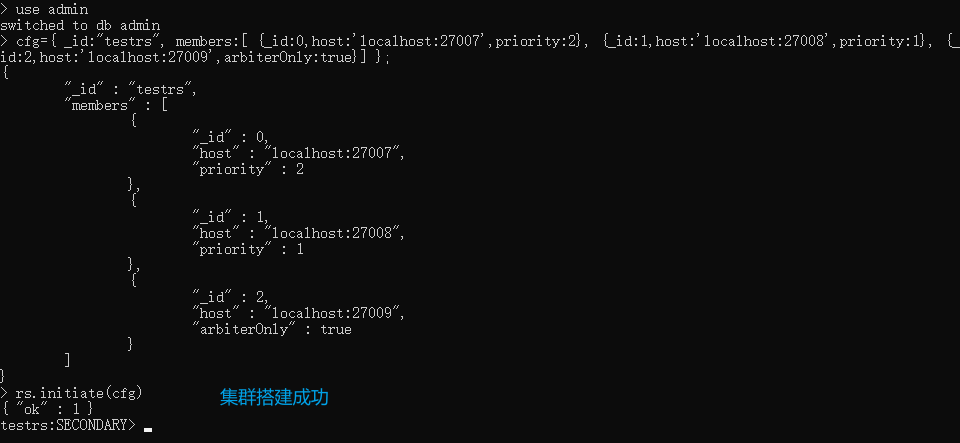
xxxxxxxxxx# 切到admin库use admin# 定义变量 这里的host和_id 要和配置文件一致cfg={ _id:"testrs", members:[ {_id:0,host:'localhost:27007',priority:2}, {_id:1,host:'localhost:27008',priority:1}, {_id:2,host:'localhost:27009',arbiterOnly:true}] };# 初始化节点配置rs.initiate(cfg)# 查看节点配置 rs.status()# 找到StartUp2的节点 我这边是索引为1的节点 然后监听这个节点rs.status().members[1]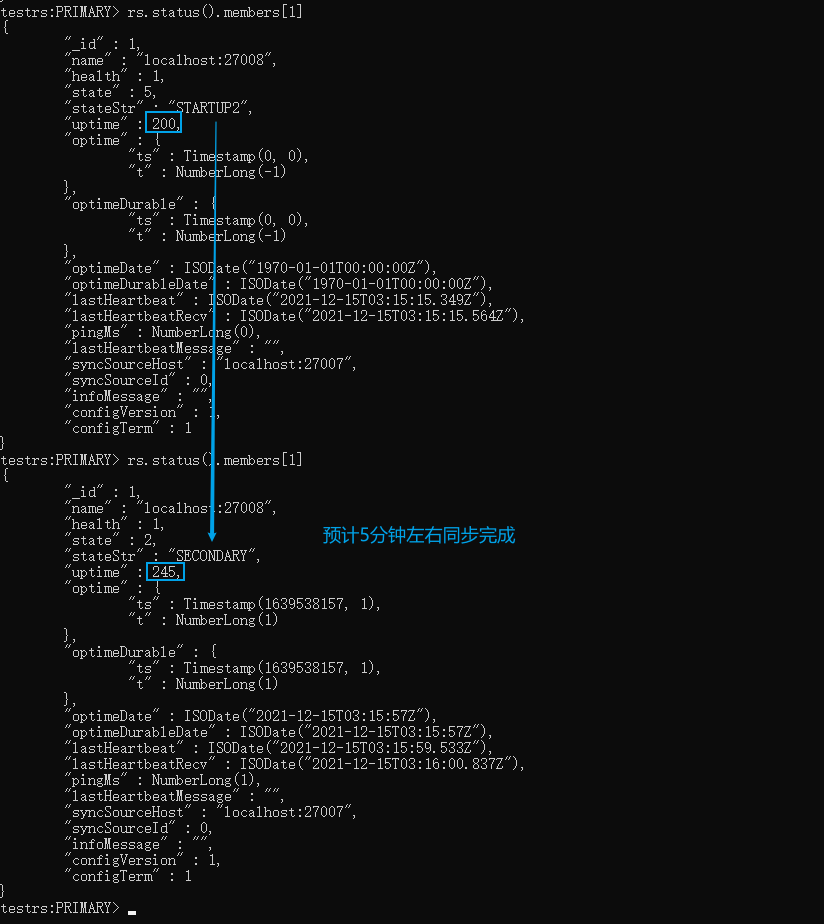
测试三:将集群主节点转为单实例但不清空文件(有用)
执行一次数据准备并搭建集群环境:节点ABC
停止节点ABC服务并修改三个节点的配置
打开节点ABC的 mongodb.conf ,删掉 replSet=testrs 配置,再启动ABC节点.

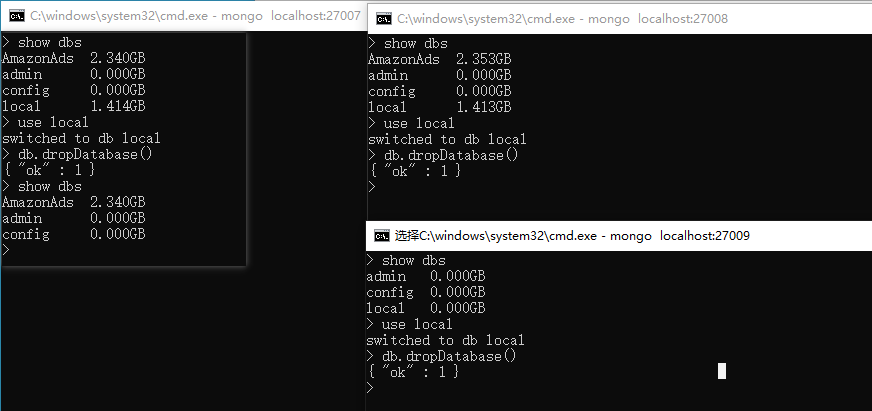
单独进入ABC三个节点服务器,删掉local库
再次停止ABC三个节点并修改三个节点的配置
打开节点ABC的 mongodb.conf ,添加 replSet=testrs 配置,再启动ABC节点
验证是否是未搭建的副本集
xxxxxxxxxx#进入到 mongodb环境mongo localhost:27007# 测试是否是未搭建的mongo复制集:执行下面这两条命令会报错rs.status()rs.conf()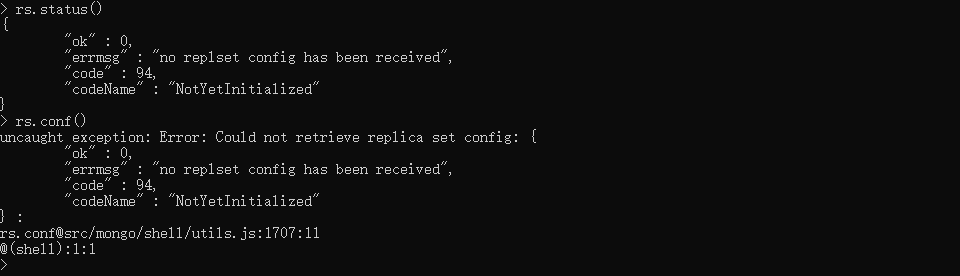
重新搭建集群,并查看执行效果
搭建完后并检测节点状态如下图我们看到整个集群差不多5分钟(数据:15G,oplog:无)就初始化同步完成了,这个速度和 上面的测试二 相差无几,不过这个操作会比较简单一点
xxxxxxxxxx# 切到admin库use admin# 定义变量 这里的host和_id 要和配置文件一致cfg={ _id:"testrs", members:[ {_id:0,host:'localhost:27007',priority:2}, {_id:1,host:'localhost:27008',priority:1}, {_id:2,host:'localhost:27009',arbiterOnly:true}] };# 初始化节点配置rs.initiate(cfg)# 查看节点配置 rs.status()# 找到StartUp2的节点 我这边是索引为1的节点 然后监听这个节点rs.status().members[1]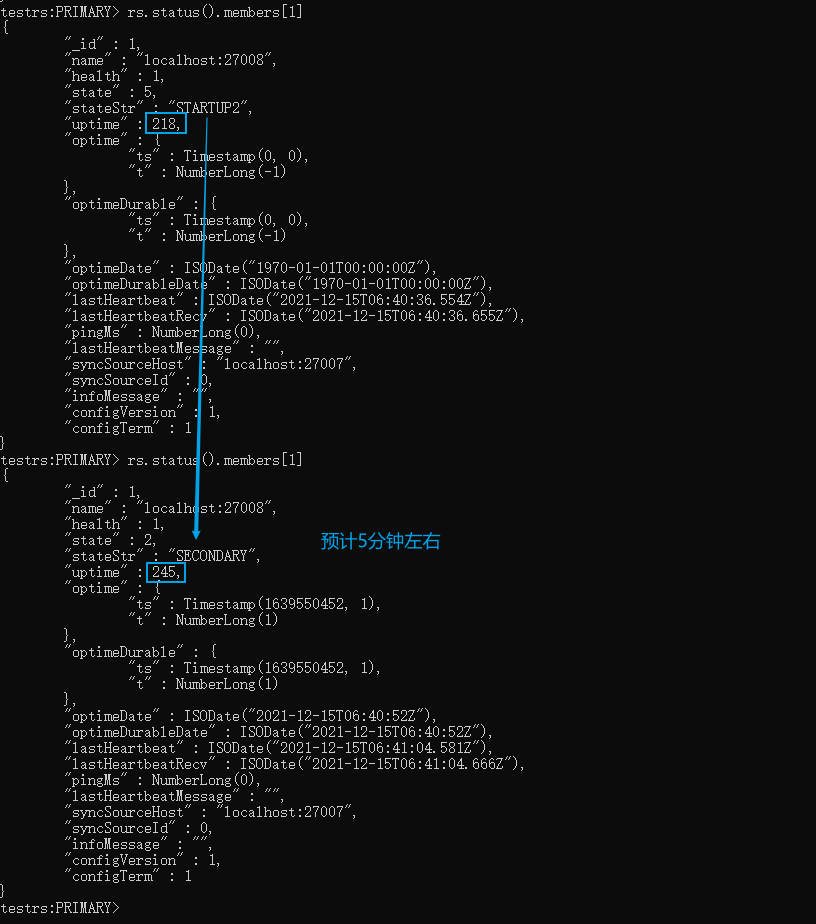
测试四:绝对单实例
执行一次数据准备,无需搭建集群
准备三个单实例
成功启动后,查询只有节点A有数据,BC无数据
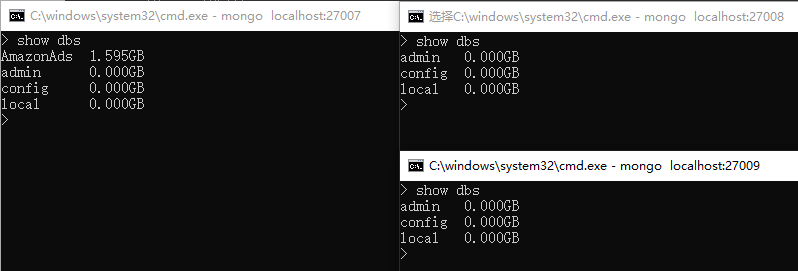
停止ABC三个节点,修改配置文件
打开ABC节点的 mongodb.conf 增加 replSet 的配置,然后重启节点ABC服务
进到节点A的 mongodb 环境进行集群配置
如下图,差不多4分钟左右就可以了,也没快多少。所以为什么之前那个1T的数据那么快就同步完了,是怎么实现的,目前也没测试出来
xxxxxxxxxx# 切到admin库use admin# 定义变量 这里的host和_id 要和配置文件一致cfg={ _id:"testrs", members:[ {_id:0,host:'localhost:27007',priority:2}, {_id:1,host:'localhost:27008',priority:1}, {_id:2,host:'localhost:27009',arbiterOnly:true}] };# 初始化节点配置rs.initiate(cfg)# 查看节点配置 rs.status()# 找到StartUp2的节点 我这边是索引为1的节点 然后监听这个节点rs.status().members[1]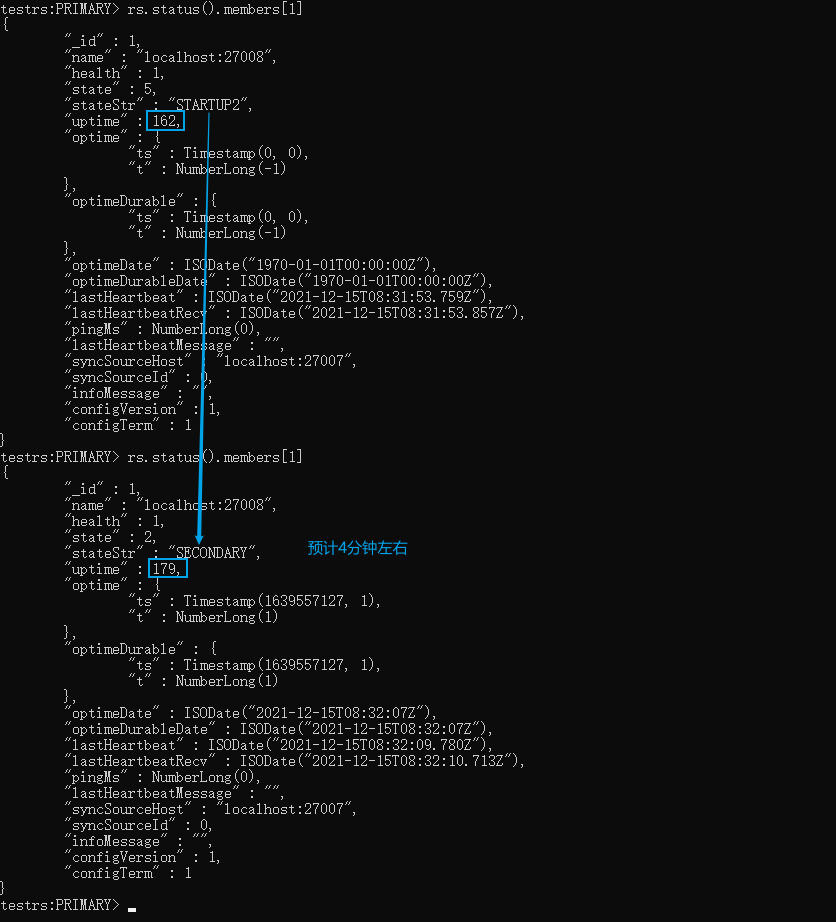
其他问题
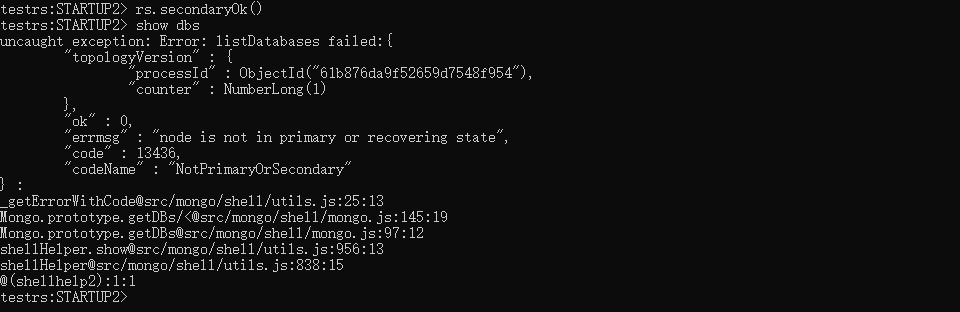
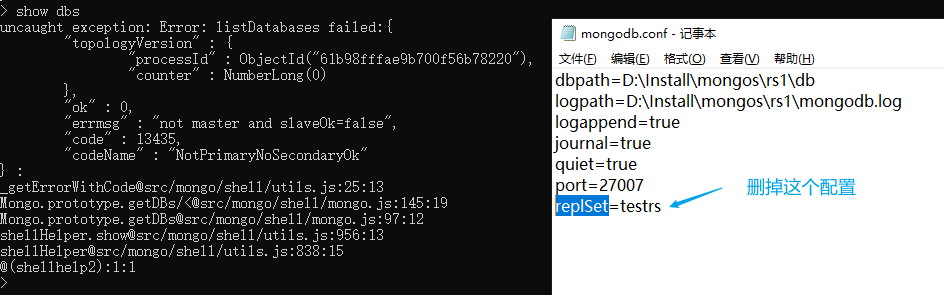
单实例 show dbs 出现 not master and slaveOk=false
你此时并不是"单实例",我可以猜一下你刚才的操作:你是不是直接把所有节点下的 dbpath 文件夹清空了以为这样就可以重置集群环境了。你可以打开你的 mongodb.conf 看看是不是还有 replSet 的配置,有的话把它删了,再重启 mongodb 服务,就可以进到 mongodb 环境执行了。如果你还想搭建副本集,这时你再加上 replSet 的配置,然后重启服务,重新配置副本集了
如何重置集群环境?
集群:ABC节点
停止ABC节点服务,清空ABC节点下的 dbpath 文件夹和 mongodb.log 文件,如果想保留主节点的数据那就不要清空主节点的 dbpath 文件夹.
打开节点A的 mongodb.conf 删掉 replSet 的配置,重启 mongodb 服务,进到节点A的 mongodb 环境,再次停止节点A服务,打开节点A的 mongodb.conf 加上replSet 的配置,启动ABC三个节点的服务,这样就可以重新配置副本集了
xxxxxxxxxx# 切到admin库use admin# 定义变量 这里的host和_id 要和配置文件一致cfg={ _id:"testrs", members:[ {_id:0,host:'localhost:27007',priority:2}, {_id:1,host:'localhost:27008',priority:1}, {_id:2,host:'localhost:27009',arbiterOnly:true}] };# 初始化节点配置rs.initiate(cfg)
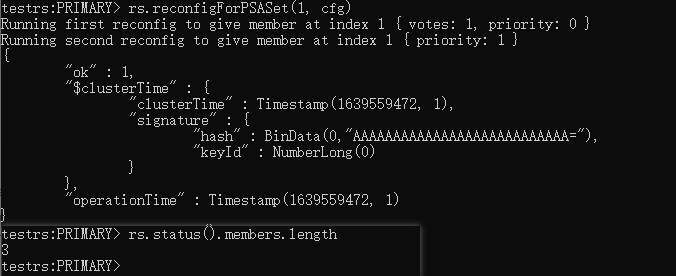
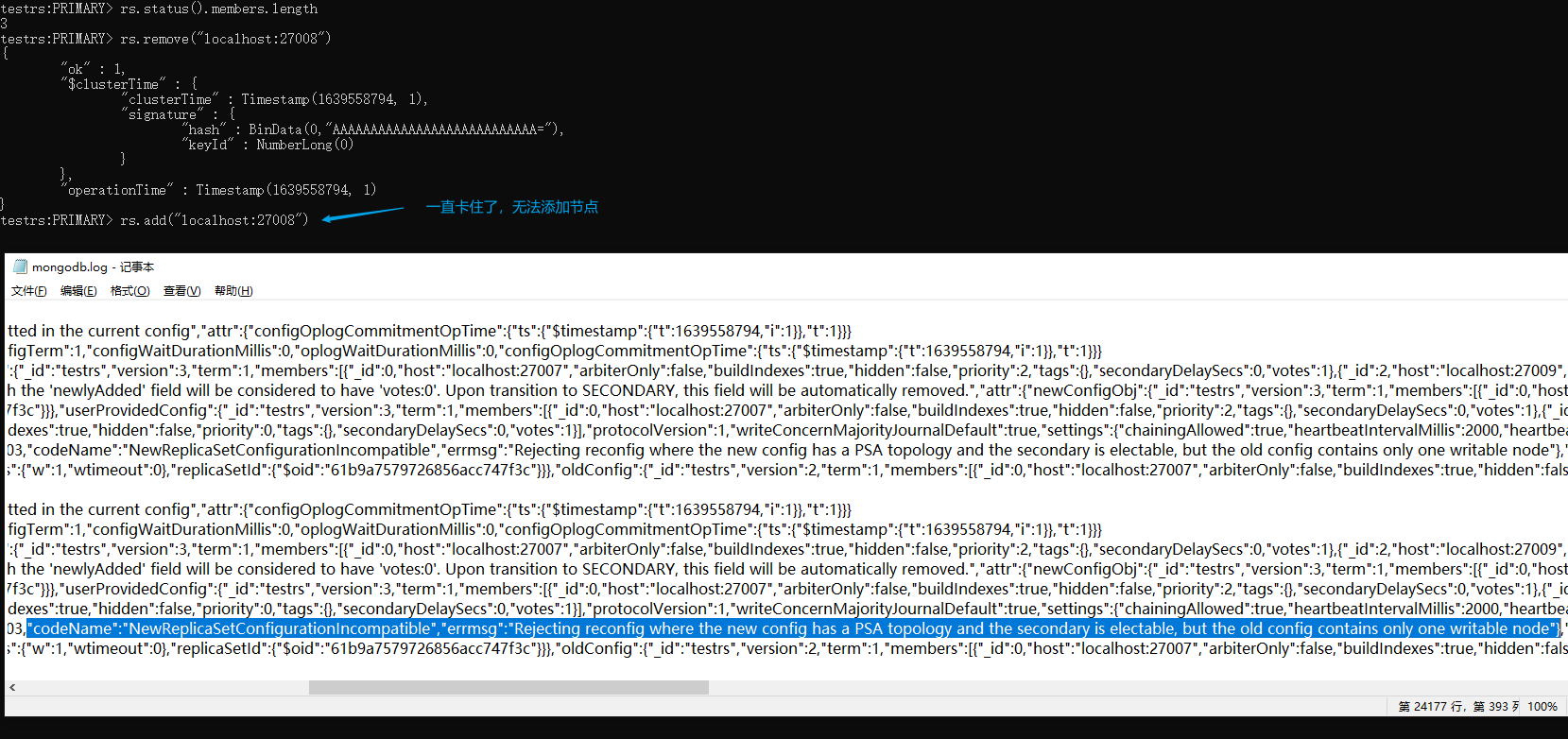
移除副本节点后,无法重新加回来了
移除副本节点后,无法重新加回来了,rs.add() 一直卡住了,我们打开 log 文件可以看到错误信息:
"codeName":"NewReplicaSetConfigurationIncompatible","errmsg":"Rejecting reconfig where the new config has a PSA topology and the secondary is electable, but the old config contains only one writable node"}
解决方案:
参考rs.reconfigForPSASet() — MongoDB Manual
xxxxxxxxxx# 获取当前配置cfg = rs.conf()# 修改当前配置的成员信息cfg["members"] = [ { "_id" : 0, "host" : "localhost:27007", "arbiterOnly" : false, "buildIndexes" : true, "hidden" : false, "priority" : 2, "tags" : {}, "secondaryDelaySecs" : NumberLong("0"), "votes" : 1 }, { "_id" : 1, "host" : "localhost:27008", "arbiterOnly" : false, "buildIndexes" : true, "hidden" : false, "priority" : 1, "tags" : {}, "secondaryDelaySecs" : NumberLong("0"), "votes" : 1 }, { "_id" : 2, "host" : "localhost:27009", "arbiterOnly" : true, "buildIndexes" : true, "hidden" : false, "priority" : 0, "tags" : {}, "secondaryDelaySecs" : NumberLong("0"), "votes" : 1 }]# 使配置生效rs.reconfigForPSASet(1, cfg)