mongodb聚合命令的参考与演示
>Mongodb聚合命令数据准备聚合管道(aggregate)参考$addFields——向文档添加新字段$bucket——根据指定的表达式和存储区边界分组。$bucketAuto——* 根据指定的表达式和存储区数量分组$collStats——返回有关集合或视图的统计信息。$count——* 返回聚合管道此阶段的文档数量计数。$currentOp——查看当前数据库连接信息$facet——在同一组输入文档的单个阶段内处理多个聚合管道$geoNear——* 根据与地理空间点的接近程度返回一个有序的文档流$graphLookup——对集合执行递归搜索$group——* 对数据进行分组$indexStats——返回有关集合的每个索引的使用情况的统计信息$$limit——* 限制经过管道的文档数量$listSessions——列出足以传播到system.sessions集合的所有会话。$lookup——* 对同数据库中的另一个集合执行左外连接$match——过滤,筛选符合条件的文档,作为下一阶段输入$merge——将聚合管道的结果文档写入集合,它必须是管道中的最后一个阶段$out——* 将聚合管道的结果文档写入集合,它必须是管道中的最后一个阶段$planCacheStats——返回集合的计划缓存信息。$project——* 数据投影,主要用于重命名,增加,删除字段$redact——通过基于文档本身中存储的信息来重塑流中的每个文档。$replaceRoot——用指定的嵌入文档替换文档$replaceWith——* 用指定的嵌入文档替换文档$sample——* 从输入中随机选择指定数量的文档。$set——* 向文档添加新字段。$skip——* 待操作集合处理前跳过部分文档$sort——* 按指定的排序键重新排序文档$sortByCount——根据某字段分组,然后计算每个不同组中的文档计数$unionWith——* 执行两个集合的并集$unset——* 从文档中移除/排除字段$unwind——解析输入文档中的数组字段,为每个元素输出一个文档Map-Reduce使用aggregate来替换MapReduce单用聚合操作estimatedDocumentCountcountdistinct其他
Mongodb聚合命令
聚合管道( aggregate )
Map-Reduce
单用聚合操作( estimatedDocumentCount、count、distinct )
数据准备
xxxxxxxxxxuse testdata = [ { _id: 1, name: 'tom', sex: '男', score: 100, age: 34 }, { _id: 2, name: 'jeke', sex: '男', score: 90, age: 24 }, { _id: 3, name: 'kite', sex: '女', score: 40, age: 36 }, { _id: 4, name: 'herry', sex: '男', score: 90, age: 56 }, { _id: 5, name: 'marry', sex: '女', score: 70, age: 18 }, { _id: 6, name: 'john', sex: '男', score: 100, age: 31 }]db.students.insertMany(data)data = [ { _id: 1, province: 'GuangGong', country: 'China', detail: '幸福小区001弄',student_id:6}, { _id: 2, province: 'Tokyo', country: 'Japan', detail: '幸福小区002弄',student_id:6}, { _id: 3, province: 'ShangHai', country: 'China', detail: '幸福小区003弄',student_id:5}, { _id: 4, province: 'BeiJing', country: 'China', detail: '幸福小区004弄',student_id:4}, { _id: 5, province: 'MingGuWu', country: 'Japan', detail: '幸福小区005弄',student_id:3}, { _id: 6, province: 'XiNi', country: 'Australia', detail: '幸福小区006弄',student_id:2}, { _id: 7, province: 'NewYork', country: 'America', detail: '幸福小区006弄',student_id:1},]db.address.insertMany(data)# 查看数据db.students.find().limit(1)db.address.find().limit(1)查看其中一条数据

聚合管道(aggregate)
参考
参考资料:聚合管道快速参考 - MongoDB-CN-Manual (mongoing.com)
MongoDB聚合 - MongoDB-CN-Manual (mongoing.com)
注意:除 $out, $merge和$geoNear阶段之外的所有阶段都可以在管道中多次出现
聚合管道只作查询用途,任何操作都是基于查询结果,并不会影响源文档信息
$addFields——向文档添加新字段
如向文档中添加老师信息:
xxxxxxxxxxdb.students.aggregate([{$addFields:{teacher_name:'lao wang'}}])# 查看源文档信息db.students.find().limit(1)
$bucket——根据指定的表达式和存储区边界分组。
如按照成绩分组分为,0-60:不及格、60-80:及格、80-90:良好、90-100:优秀
注意这是一个左闭右开的区间范围,如 90-100 是不包含 100 分的,而我们提供的区间又没有 100分 这个区间,所以会默认分到"其他"区间
xxxxxxxxxx# groupBy:指定分组字段 boundaries:分组边界(一个数组会分成多个) # default:不满足分组边界的组 output 输出格式db.students.aggregate([ { $bucket:{ groupBy:'$score', boundaries:[0,60,80,90,100], default:'其他', output:{ 'count':{$sum:1}, 'name':{$push:'$name'} } } }])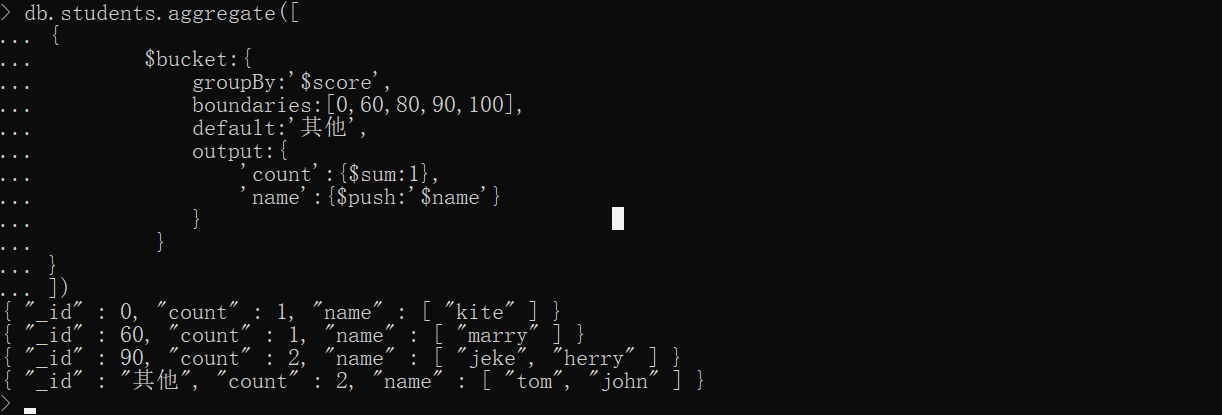
$bucketAuto——* 根据指定的表达式和存储区数量分组
如按照成绩分成3组:
xxxxxxxxxx# groupBy:指定分组字段 buckets:分组数量db.students.aggregate([ {$bucketAuto:{groupBy:'$score',buckets:3}}])# 不指定output默认输出count,指定格式输出加上output即可db.students.aggregate([ { $bucketAuto:{ groupBy:'$score', buckets:3, output:{ 'count':{$sum:1}, 'name':{$push:'$name'} } } }])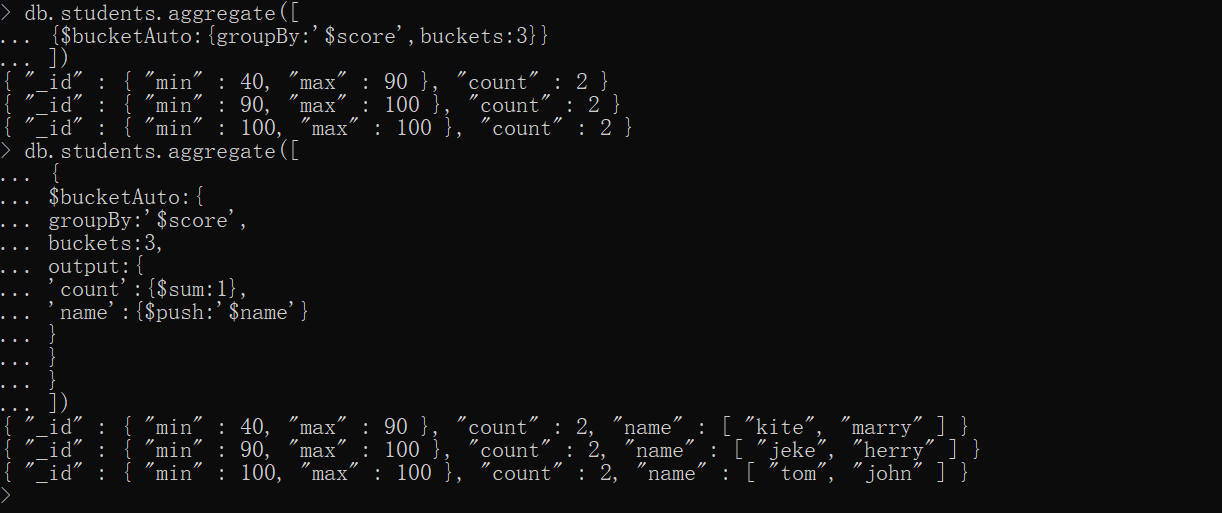
$collStats——返回有关集合或视图的统计信息。
语法:
xxxxxxxxxx{ $collStats: { latencyStats: { histograms: <boolean> }, storageStats: {}, count: {} }}latencyStats——查看延迟信息
latencyStats.histograms——如果true,则将延迟直方图信息也显示出来
storageStats——查看集合的基本存储信息、如集合大小、条数、平均每条大小等等等等
count————————查看集合的总条数
简单演示,默认仅显示集合名称、主机、UTC时间
xxxxxxxxxxdb.students.aggregate([{$collStats:{}}])
查看延迟信息
xxxxxxxxxxdb.students.aggregate([{$collStats:{latencyStats:{}}}])
查看延迟信息、直方图信息(我也不知道直方图是什么,只知道信息更多了)
xxxxxxxxxxdb.students.aggregate([{$collStats:{latencyStats:{histograms:true}}}])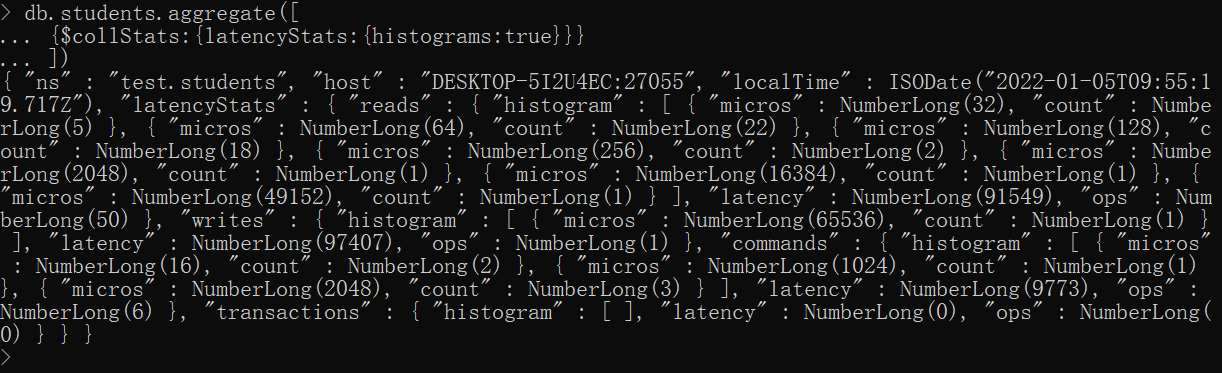
查看集合存储的信息
xxxxxxxxxxdb.students.aggregate([{$collStats:{storageStats:{}}}])
查看集合总条数
xxxxxxxxxxdb.students.aggregate([{$collStats:{count:{}}}])
当然这几个都可以组合一起使用的
$count——* 返回聚合管道此阶段的文档数量计数。
语法:
xxxxxxxxxx{ $count:""}简单示例
xxxxxxxxxx# 获取文档数量db.students.aggregate([{$count:'totalCount'}])# 查看性别为男的数量db.students.aggregate([ {$match:{sex:'男'}}, {$count:'nan_count'}])
$currentOp——查看当前数据库连接信息
语法:
xxxxxxxxxx{ $currentOp: { allUsers: <boolean>, idleConnections: <boolean>, idleCursors: <boolean>, idleSessions: <boolean>, localOps: <boolean> }}简单示例
xxxxxxxxxxdb.getSiblingDB("admin").aggregate([ { $currentOp : { } }])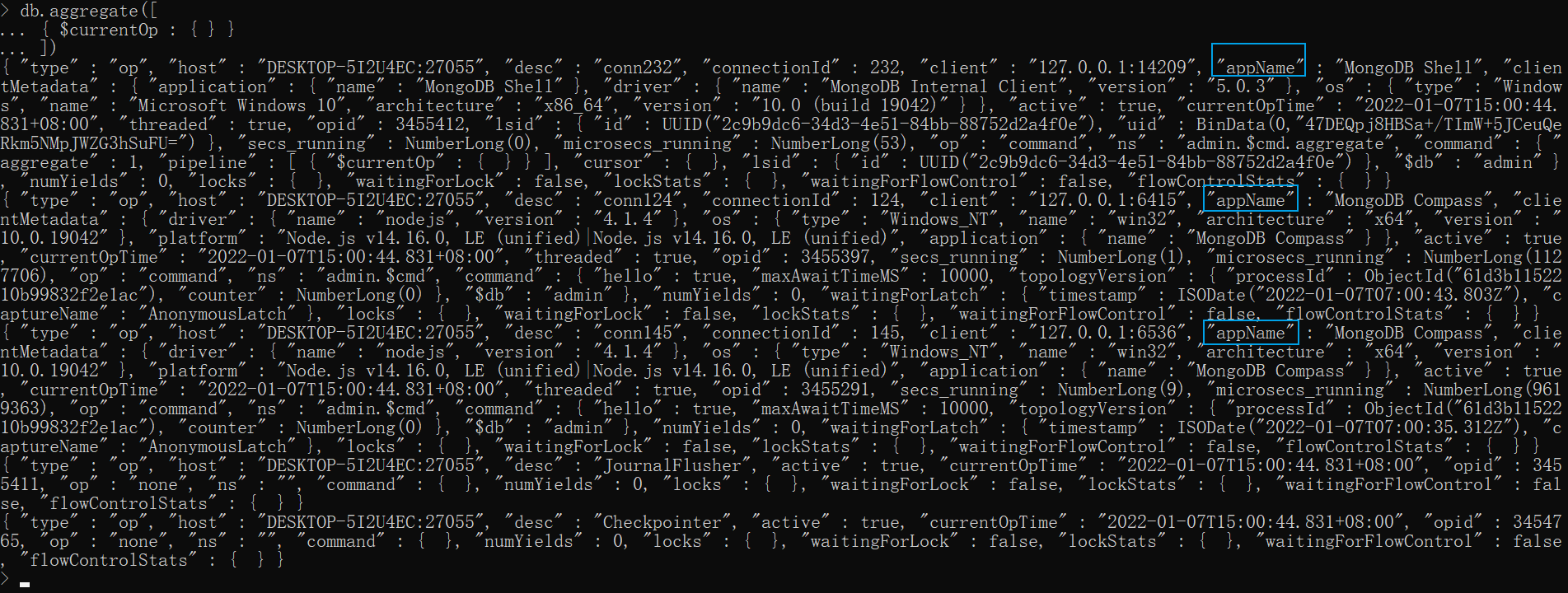
x
db.getSiblingDB("admin").aggregate( [ { $currentOp : { allUsers: true, idleSessions: true } }] )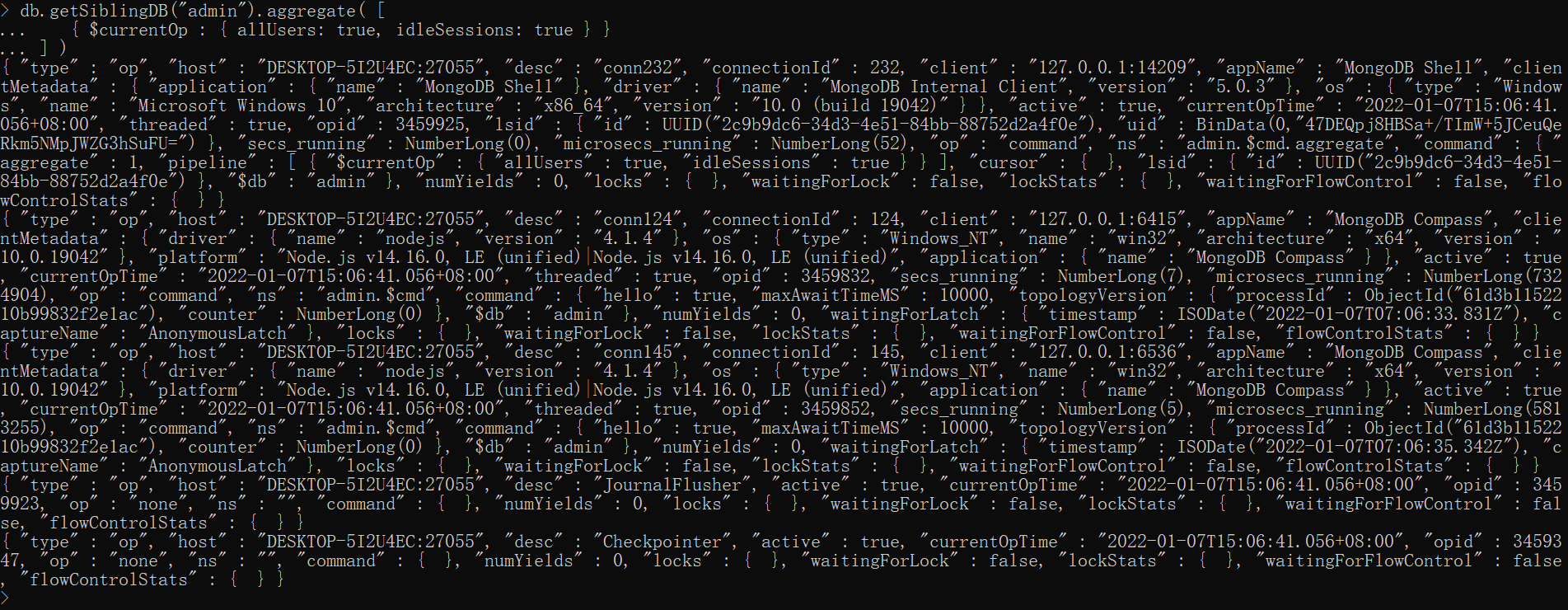
$facet——在同一组输入文档的单个阶段内处理多个聚合管道
v3.4+ 可用
语法:
xxxxxxxxxx{ $facet: { <字段1>: [ pipeline], <字段2>: [ pipeline], ... }}简单示例,如将 age 分成两组,以30为分界线
xxxxxxxxxxdb.students.aggregate([ { $facet:{ sex_lt30:[{$match:{age:{$lt:30}}}], sex_gt30:[{$match:{age:{$gte:30}}}] } }])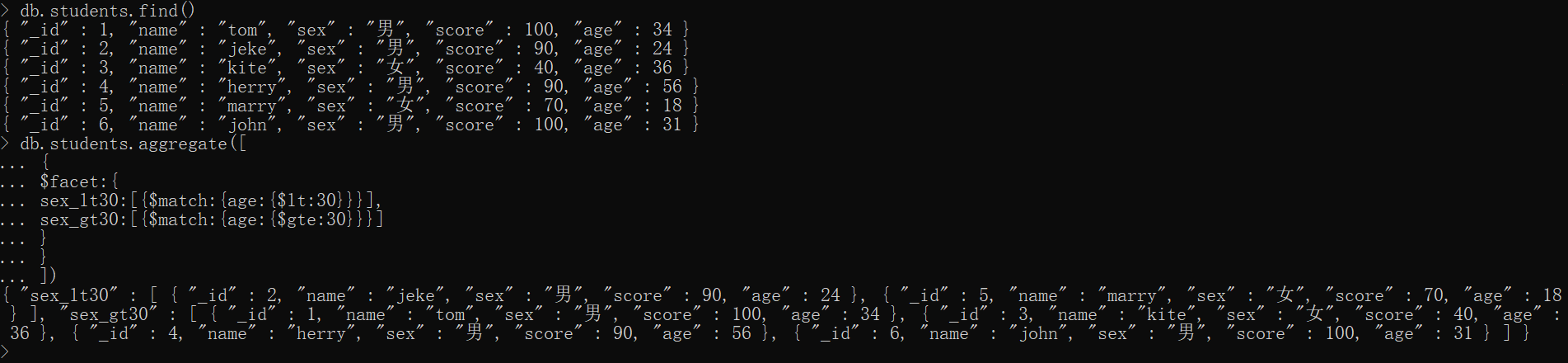
$geoNear——* 根据与地理空间点的接近程度返回一个有序的文档流
语法:
xxxxxxxxxx{ $geoNear: { near: {}, # 目标坐标 distanceField: "xxx.xxx", # 输出字段,真实距离大小 maxDistance: 2, # 距离 query: { }, # 查询 includeLocs: "xxx.xxx", # 输出字段,匹配包含的点 spherical: true # 为true用球面距离。为false,2d索引用平面,2dsphere用球面距离 }}准备数据
xxxxxxxxxxdb.places.insertMany( [ { name: "Central Park", location: { type: "Point", coordinates: [ -73, 40 ] }, category: "Parks" }, { name: "Sara D. Roosevelt Park", location: { type: "Point", coordinates: [ 10, -80 ] }, category: "Parks" }, { name: "Polo Grounds", location: { type: "Point", coordinates: [ 73, 10 ] }, category: "Stadiums" }] )# 创建2d索引db.places.createIndex( { location: "2dsphere" } )简单示例,查询与 [ -73.002, 40.005 ] 距离 1000 米内的点(单位应该是米吧)
x
db.places.aggregate([ { $geoNear: { near: { type: "Point", coordinates: [ -73.002, 40.005 ] }, distanceField: "dist.calculated", maxDistance: 1000, query: { category: "Parks" }, includeLocs: "dist.location", spherical: true } }])$graphLookup——对集合执行递归搜索
语法:
x
{ $graphLookup: { from: <collection>, # 要搜索的目标集合 startWith: <expression>, # 要查找的字段 connectFromField: <string>, # 链接的字段,当前记录 connectToField: <string>, # 链接的目标字段,下一条记录 as: <string>, # 搜索结果的存储区域 maxDepth: <number>, # 递归次数 depthField: <string>, # 当前搜索结果的个数 restrictSearchWithMatch: <document> # 相当于一个简单查找,查找的是 as 结果的数据 }}准备数据
xxxxxxxxxxdb.employees.insertMany([{ "_id" : 1, "name" : "Dev" },{ "_id" : 2, "name" : "Eliot", "reportsTo" : "Dev" },{ "_id" : 3, "name" : "Ron", "reportsTo" : "Eliot" },{ "_id" : 4, "name" : "Andrew", "reportsTo" : "Eliot" },{ "_id" : 5, "name" : "Asya", "reportsTo" : "Ron" },{ "_id" : 6, "name" : "Dan", "reportsTo" : "Andrew" }])官方示例,找领导。
如 Dan,他要向 Andrew 汇报,Andrew 再向 Eliot 汇报,Eliot 再向 Dev汇报,所以 Dan字段就会出现3个领导信息,
再如 Dev,他是最高领导,它不需要向其他人汇报,所以 Dev 不会出现任何领导信息
x
db.employees.aggregate( [ { $graphLookup: { from: "employees", startWith: "$reportsTo", connectFromField: "reportsTo", connectToField: "name", as: "reportingHierarchy" } }] )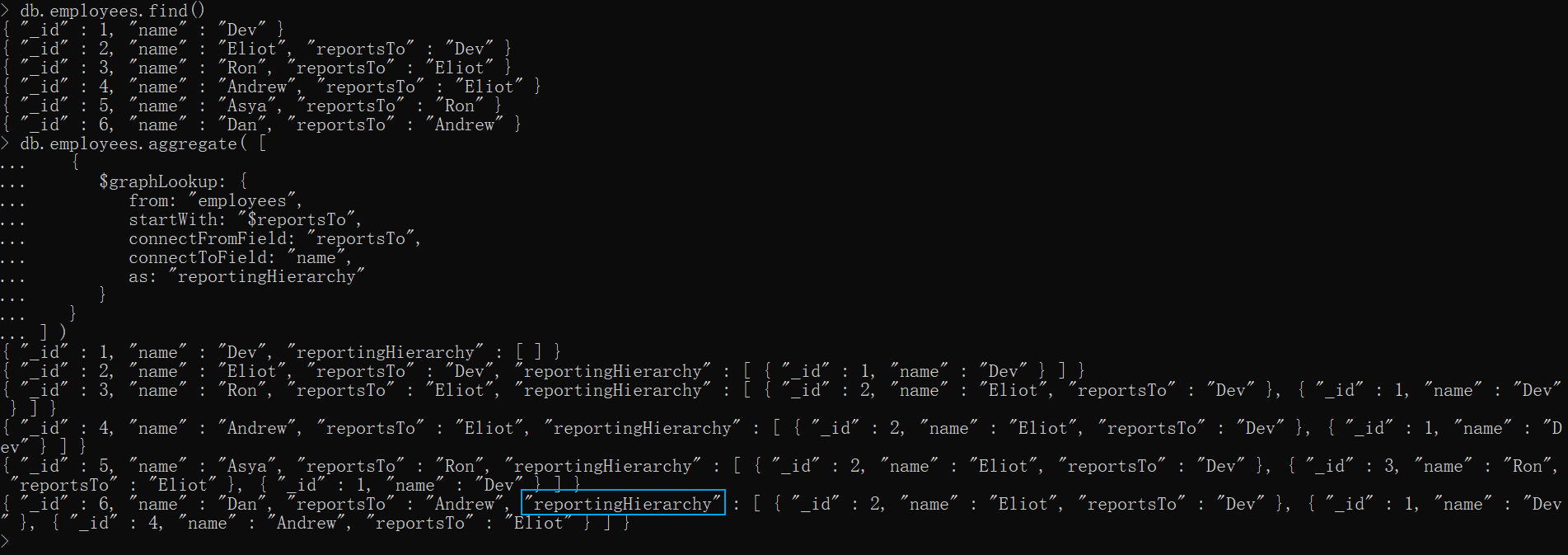
演示
x
db.employees.aggregate( [ { $graphLookup: { from: 'employees', startWith: '$reportsTo', connectFromField: 'reportsTo', connectToField: 'name', as: 'leaders', maxDepth:3, depthField: 'num_leader', restrictSearchWithMatch: {'name':'Dev'} } }] )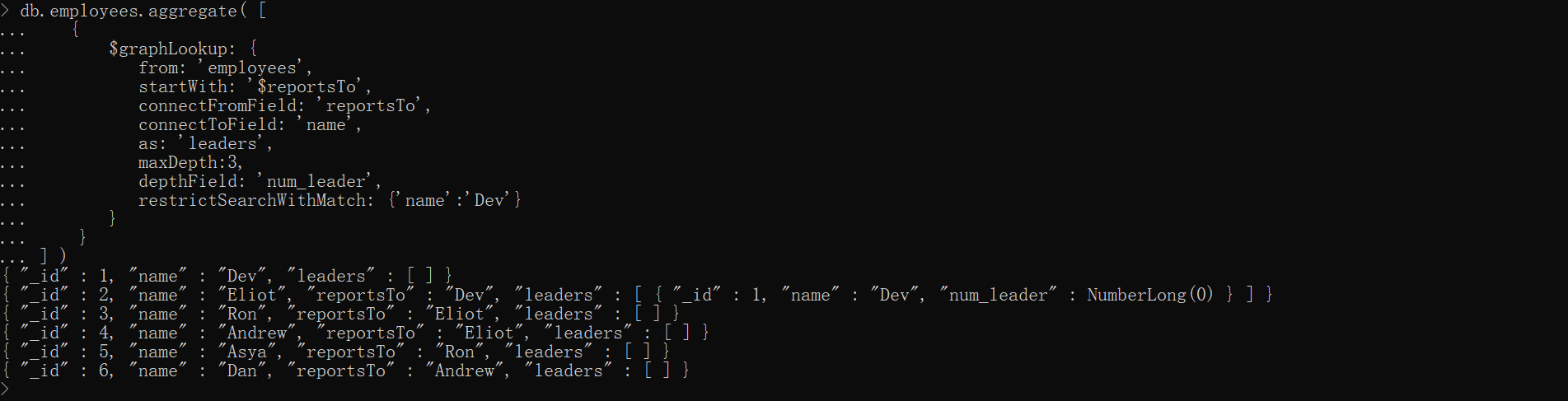
$group——* 对数据进行分组
xxxxxxxxxxdb.students.aggregate([ {$group:{'_id':'$sex','totalCount':{$sum:1}}}])
$indexStats——返回有关集合的每个索引的使用情况的统计信息$
xxxxxxxxxxdb.students.aggregate([ {$indexStats:{}}])
$limit——* 限制经过管道的文档数量
xxxxxxxxxxdb.students.aggregate([{$limit:3}])# 查找性别为男的,并只取2个db.students.aggregate([ {$match:{sex:'男'}}, {$limit:3}])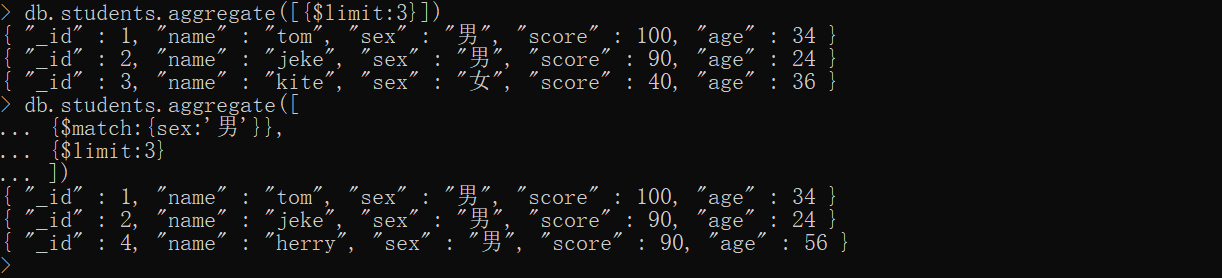
$listSessions——列出足以传播到system.sessions集合的所有会话。
仅对config库有用
xxxxxxxxxxuse configdb.system.sessions.aggregate( [ { $listSessions: { allUsers: true } } ] )
xxxxxxxxxxuse configdb.system.sessions.aggregate( [ { $listSessions: { } } ] )
xxxxxxxxxxuse configdb.aggregate( [ { $listLocalSessions: { users: [ { user: "myAppReader", db: "students" } ] } } ] )$lookup——* 对同数据库中的另一个集合执行左外连接
语法:
xxxxxxxxxx{ $lookup:{ from:'', #左外连的表名 localField:'', #本表的id foreignField:'', #外表的关联id let:{}, #声明变量,对象类型,可选 pipeline:[] #一大堆阶段命令 as:'' # 输出新名称 }}如我们要同时查出学生信息及学生住址
xxxxxxxxxxdb.students.aggregate([ { $lookup:{ from:'address', localField:'_id', foreignField:'student_id', as:'student_info' } }])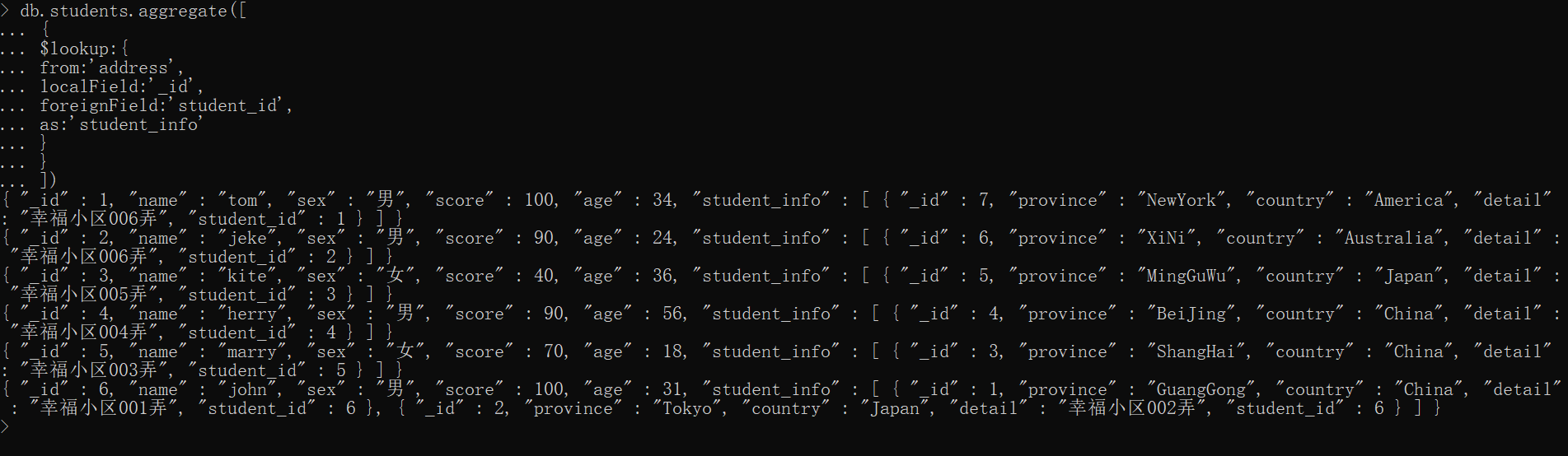
使用 let 做匹配,往往用在两个以上条件匹配时才会用到的
xxxxxxxxxxdb.students.aggregate([ { $lookup:{ from:'address', let:{s_id:'$_id'}, pipeline:[ {$match:{ $expr:{ $and:[ {$eq:['$student_id','$$s_id']} ] } }}, {$project:{'_id':0}} ], as:'student_info' } }])
需要注意的点:
- pipeline 作用域内可以直接读取外表的字段。也可以读取主表的字段,但可能会出现变量作用域混乱的情况,如下图,我们可以看到取到的地址信息都是同一个,这肯定是不正确的
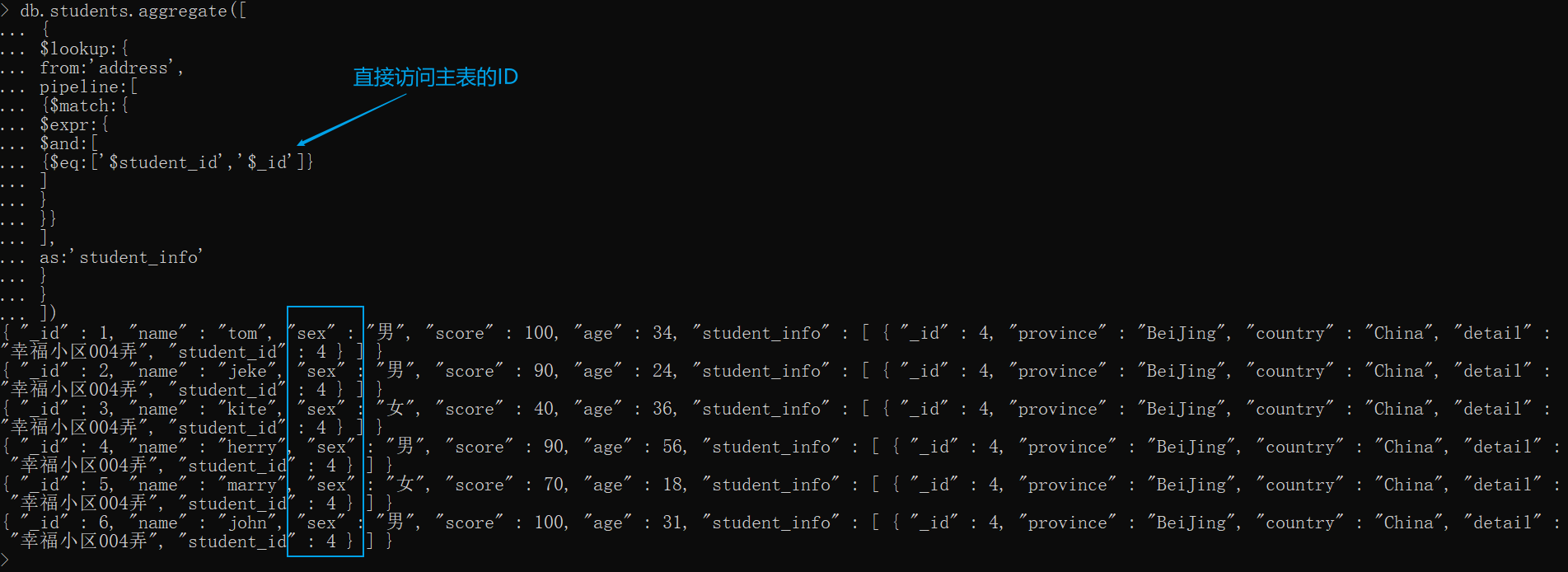
- pipeline 内的 $project 只能限制外表的字段,也就是说只能控制外表哪些字段可以显示哪些不可现实。 {$project:{'_id':0}} 意思是不展示地址表中的 _id 字段,如果要限制主表应该将 $project 与 $lookup 平级,如下:
xxxxxxxxxxdb.students.aggregate([ { $lookup:{ from:'address', pipeline:[ {$match:{ $expr:{ $and:[ {$eq:['$student_id','$_id']} ] } }}, {$project:{'_id':0}} ], as:'student_info' } }, {$project:{'score':0,'age':0,'student_info.detail':0}}])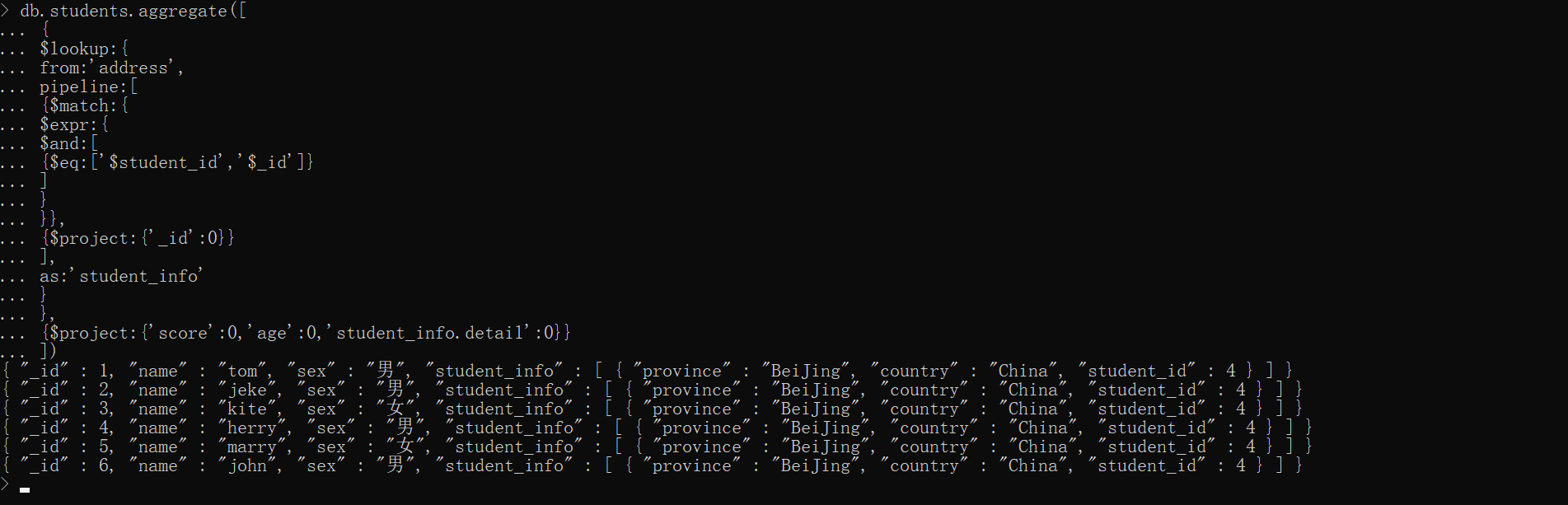
{$project:{'score':0,'age':0,'student_info.detail':0}} 即 不展示学生主表中的 score、age 字段,不展示 student_info.detail 字段
$match——过滤,筛选符合条件的文档,作为下一阶段输入
xxxxxxxxxxdb.students.aggregate([ {$match:{age:{$gte:30}}}])
$merge——将聚合管道的结果文档写入集合,它必须是管道中的最后一个阶段
v4.2+——可以指定输出到某个库某个集合
v4.4+——可以输出到原集合
语法:
xxxxxxxxxx{ $merge:{ into:'', # 表名或 {db:'库名',coll:'表名'} on:'', # 字段名 或 字符串数组 可选,默认全字段,匹配的依据 let:, # 设置变量 whenMatched:'', # 当匹配时的处理方式,replace 替换、merge 合并,默认、keepExisting 保持不变、fail 失败,pipeline 可选值 whenNotMatched:'' # insert 插入,默认、discard 丢弃、fail 失败 可选值 }}简单示例
xxxxxxxxxxshow collectionsdb.students.aggregate([ {$merge:{into:'new_coll'}}])show collectionsdb.new_coll.find() # 将students表的内容输出到 new_coll表中db.new_coll.drop()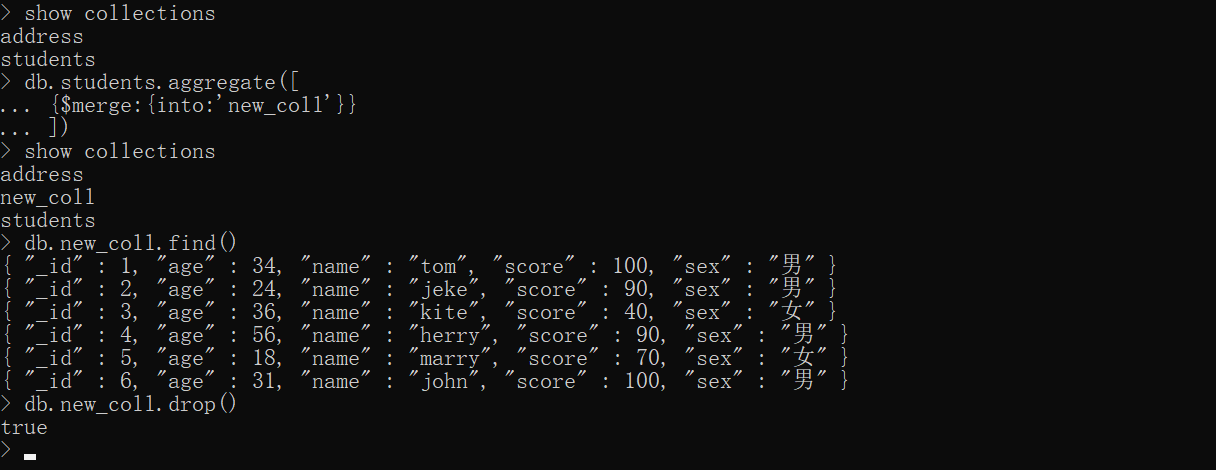
再来看一下指定字段的。指定 _id 字段 其实和不指定on一样的效果
xxxxxxxxxxshow collectionsdb.students.aggregate([ { $merge:{ into:'new_coll', on:['_id'], } }])show collectionsdb.new_coll.find()db.new_coll.drop()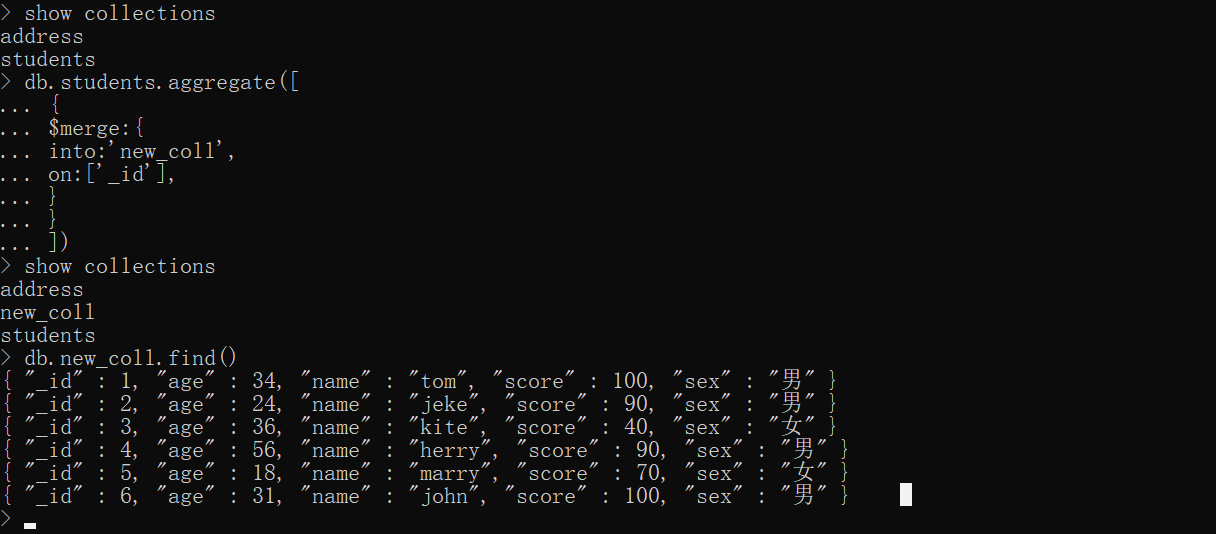
指定多字段。
1.要先对这些字段建索引,无关顺序
2.一定要加上 {$project:{_id:0}} _id 排除将否则会报错:
PlanExecutor error during aggregation :: caused by :: $merge failed to update the matching document, did you attempt to modify the id or the shard key? :: caused by :: Performing an update on the path 'id' would modify the immutable field '_id'
xxxxxxxxxx
db.new_coll.createIndex({age:1,name:1},{unique:true})db.new_coll.insertMany([ {_id:1, age: 34, name:'tom', }, {_id:2, age: 24, name:"jeke",teacher: 'lao wang' }, {_id:3, age: 36, name:'kite',teacher: 'lao wang',year:'2022'},])db.students.find()db.students.aggregate([ {$project:{_id:0}}, { $merge:{ into:'new_coll', on:['age','name'], } }])db.new_coll.find()原先我们 new_coll 集合中只有 1、2、3三条记录,students集合中有 1、2、3、4、5、6 六条记录,根据两张表的age、name字段作比较,刚好 students 的 1、2、3 记录能匹配上 new_coll 的 1、2、3 记录,那么程序会将不存在于 new_coll 集合的字段合并到 new_coll 相应记录中。而 4,5,6 记录未能匹配,则程序会将这些记录插入到 new_coll 中,由于这些是没有 _id 的,所以 mongodb 会自动创建一个 _id 字段。
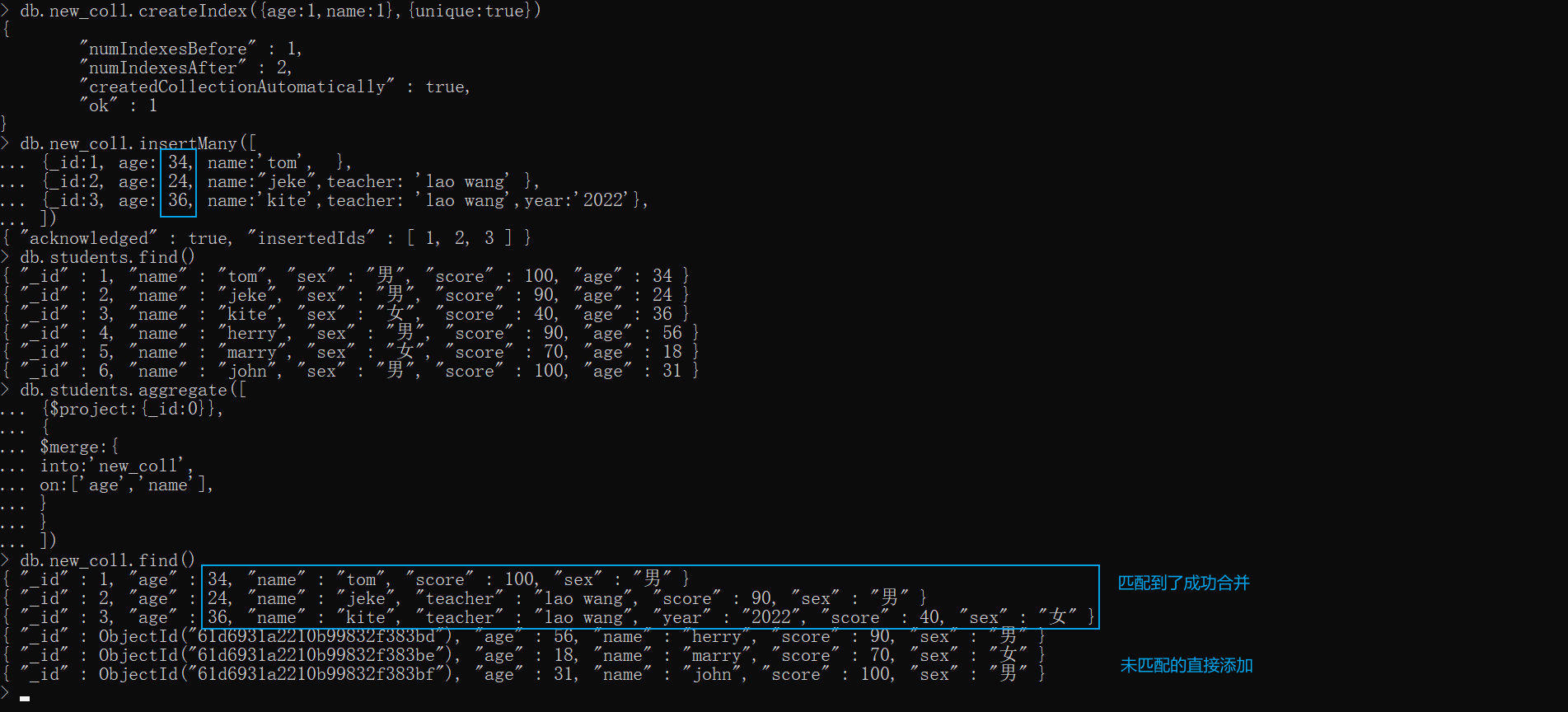
$out——* 将聚合管道的结果文档写入集合,它必须是管道中的最后一个阶段
v4.4+——可以输出到指定数据库的某个集合
语法:
xxxxxxxxxx{ $out:{ db:'', # 数据库名称 coll:'' # 集合名称 }}# 如果输出到本数据库,也可以这样简写{ $out:'' # 集合名称}简单例子
xxxxxxxxxxshow collectionsdb.students.aggregate([ {$out:'new_coll'}])show collectionsdb.new_coll.find()
$planCacheStats——返回集合的计划缓存信息。
v4.2+ 可用
xxxxxxxxxxdb.students.aggregate([ {$planCacheStats:{}}])# 刚开始执行是没有任何信息的,因为students是一个新集合,我们都没有通过他的索引查询信息,自然不会有什么结果 使劲查id索引也是不行的,必须得建其他字段的索引# 建两个索引db.students.createIndex({age:1,name:1})db.students.createIndex({age:1,sex:1})# 根据索引查询db.students.find({age:{$gt:30},name:/i/})db.students.find({age:{$gt:30},sex:'男'})#再次执行 planCacheStats 就有结果出来了db.students.aggregate([ {$planCacheStats:{}}])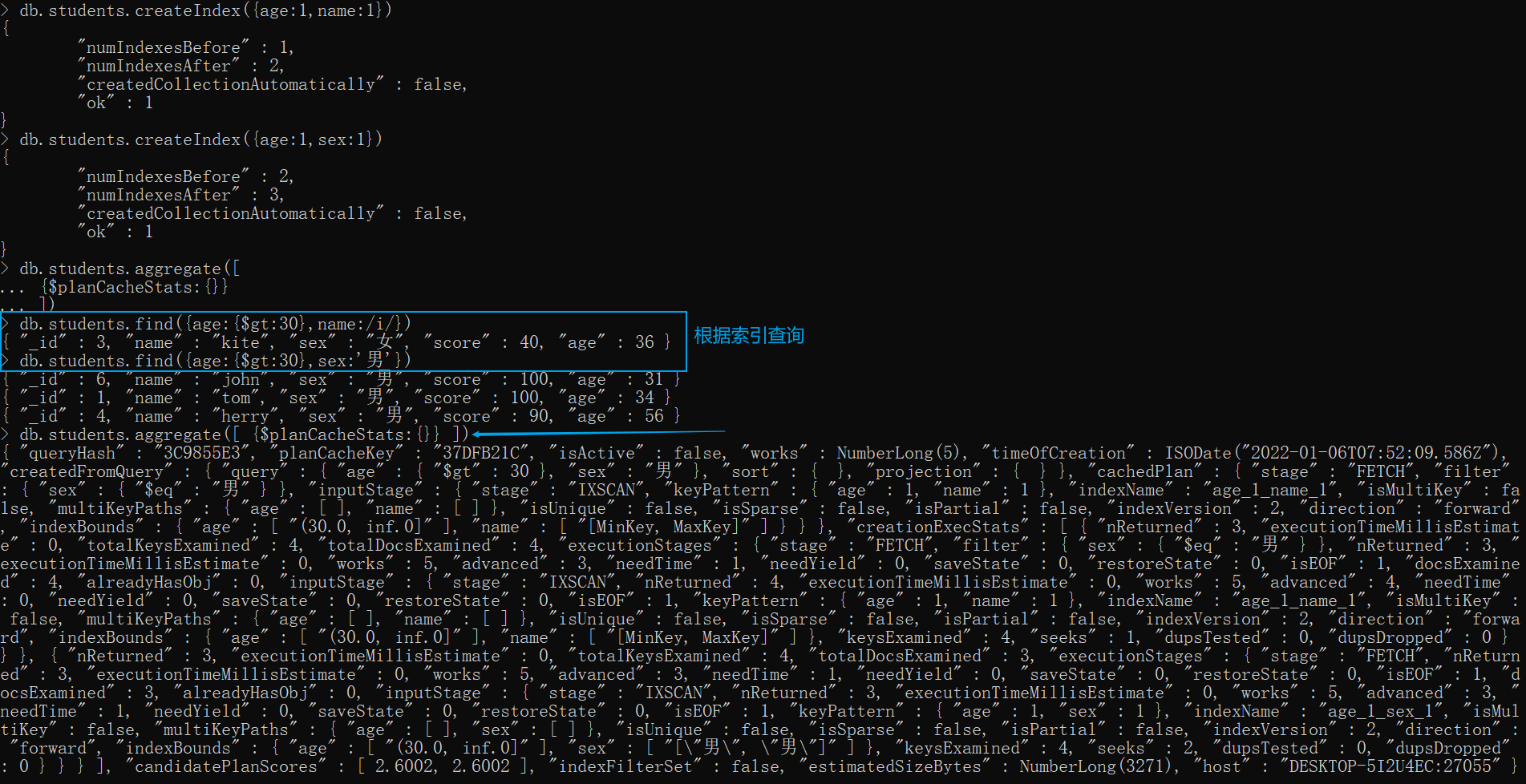
$project——* 数据投影,主要用于重命名,增加,删除字段
语法:
xxxxxxxxxx{ $project:{}}简单示例,如果不对 _id 进行设置的话,默认出现,如不希望 _id 出现,应该将值设为0
xxxxxxxxxxdb.students.aggregate([ {$project:{age:1,name:1}}])
添加字段 time 、重命名字段 sex_sex
xxxxxxxxxxdb.students.aggregate([ { $project:{ age:1, name:1, sex_sex:'$sex', time:'$$NOW' } }])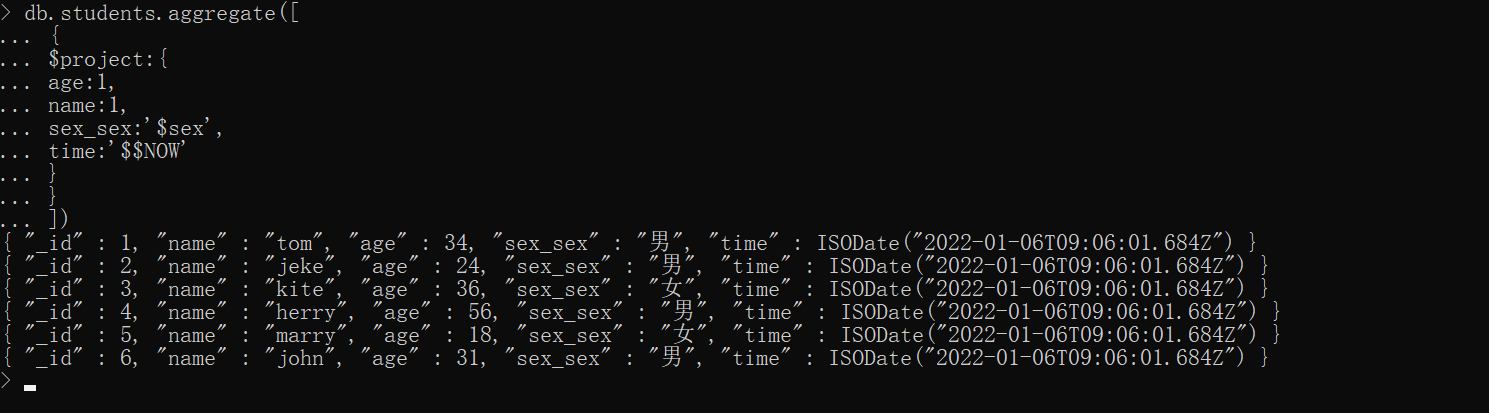
还可以指定 pipeline 做判断。如下我们可以通过计算方法来得出 age、score 这两个字段的平均值,也可以通过判断如果年龄小于 30 ,则不显示 sex 字段
xxxxxxxxxxdb.students.aggregate([ { $project:{ avg_val:{$avg:['$age','$score']}, age:1, sex:{ $cond:{ if:{$lt:['$age',30]}, then:'$$REMOVE', else:'$sex' } } } }])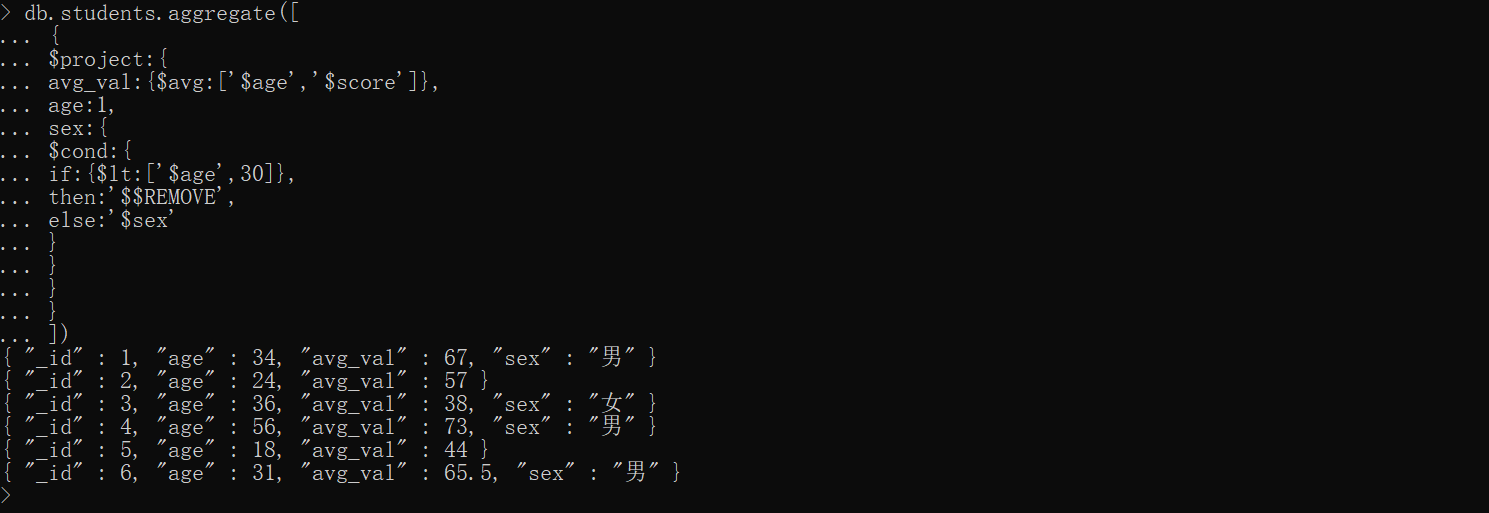
$redact——通过基于文档本身中存储的信息来重塑流中的每个文档。
合并$project和$match的功能, $redact 常与 $cond 一起使用,相关变量功能:$$DESCEND 不包括嵌套对象、$$PRUNE——排除该字段、$$KEEP——保留该字段
语法:
xxxxxxxxxx{$redact:{}}数据准备 new_coll
xxxxxxxxxxdb.new_coll.drop()db.students.find()db.students.aggregate([ {$out:'new_coll'}])db.new_coll.updateMany( {_id:{$in:[1,3,6]}}, {$set:{teacher:{name:'lao wang',age:66}}})db.new_coll.find()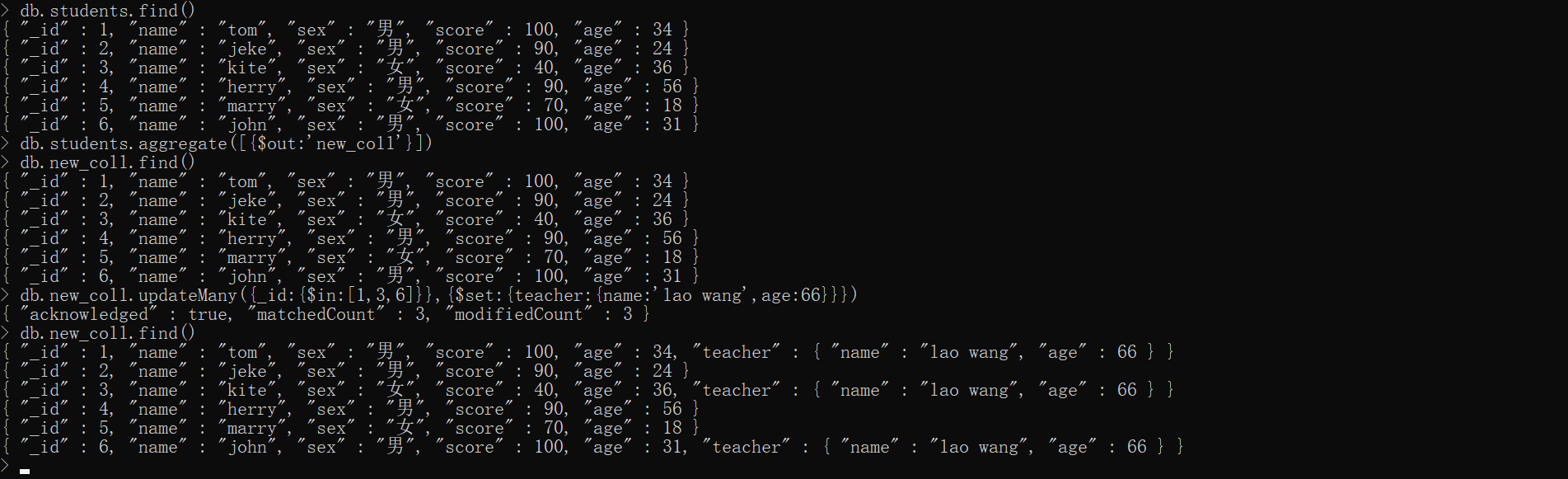
简单示例,含有教师信息的学生记录
xxxxxxxxxxdb.new_coll.aggregate([ { $redact:{ $cond:{ if:{$eq:['男','$sex']}, then:'$$DESCEND', else:'$$PRUNE' } } }])
db.new_coll.aggregate([ { $redact:{ $cond:{ if:{$eq:['男','$sex']}, then:'$$KEEP', else:'$$PRUNE' } } }])我们可以看到 $$PRUNE 直接将 sex != '男' 记录排除了,而第一条命令用 $$DESCEND 并没有把 teacher 展示出来,第二条命令在一样的条件下使用 $$KEEP 是可以把 teacher 字段展示出来的
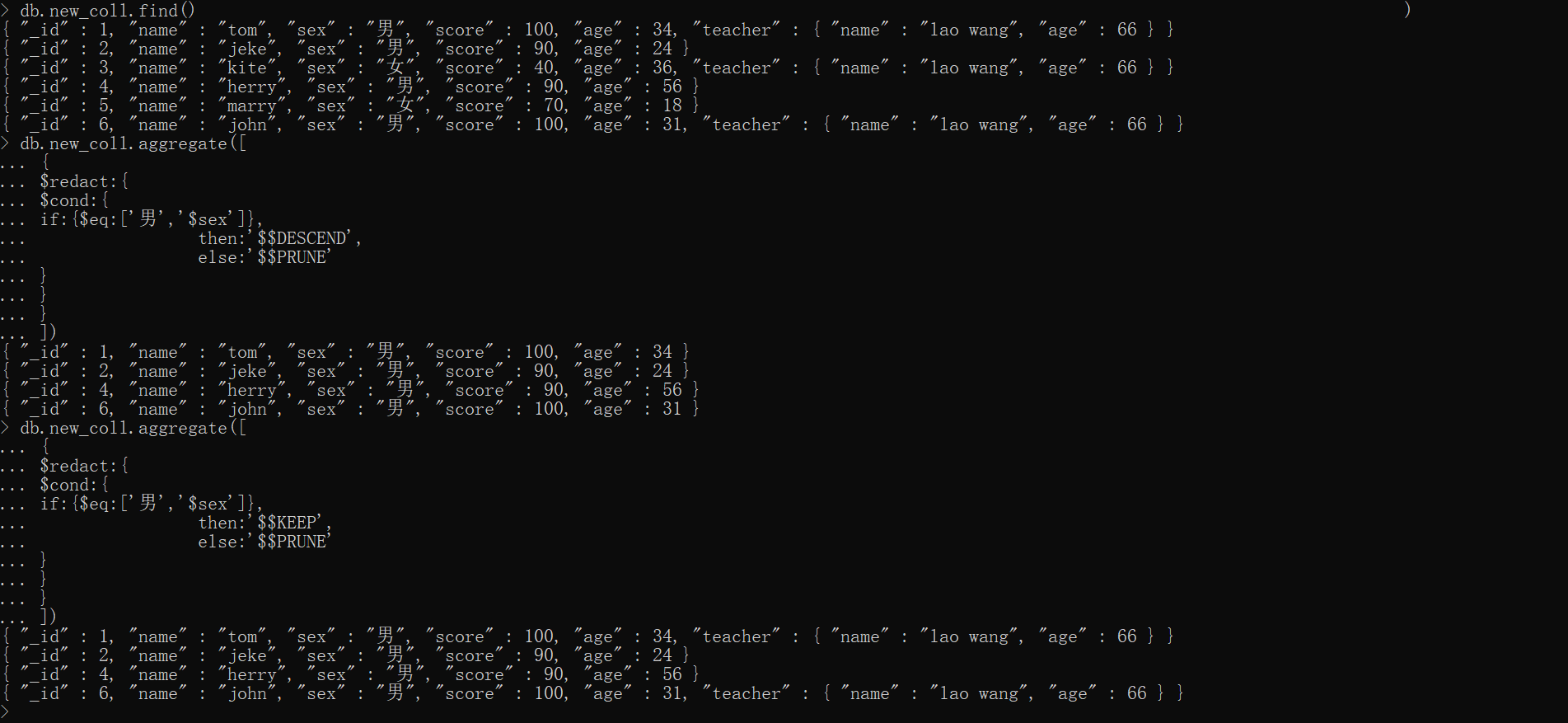
$replaceRoot——用指定的嵌入文档替换文档
v3.4+ 可用
语法:
xxxxxxxxxx{ $replaceRoot: { newRoot: <replacementDocument> } }简单示例,有点像 $project 的感觉
xxxxxxxxxxdb.students.aggregate([ {$replaceRoot: { newRoot: {info:'$age'} } }])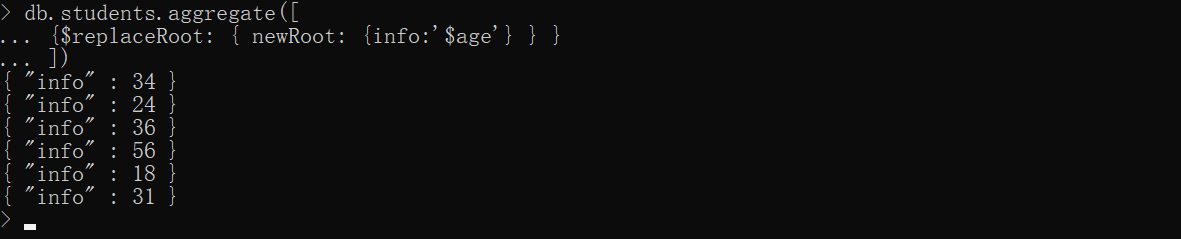
更复杂的,如输出学生信息和成绩
xxxxxxxxxxdb.students.aggregate([ { $replaceRoot:{ newRoot:{ info:{ $concat:['$name',',性别','$sex'] }, score:'$score' } } }])
与 $mergeObjects 配合使用,查询 new_coll 集合中的教师信息,若没有则默认补上"无"
xxxxxxxxxx# 准备数据 new_fulldb.new_coll.drop()db.students.find()db.students.aggregate([ {$out:'new_coll'}])db.new_coll.updateMany( {_id:{$in:[1,3,6]}}, {$set:{teacher:{name:'lao wang',age:66}}})db.new_coll.find()
# 开始执行测试db.new_coll.aggregate([ { $replaceRoot:{ newRoot:{ $mergeObjects:[ {name:'无',age:'无'}, '$teacher' ] } } }])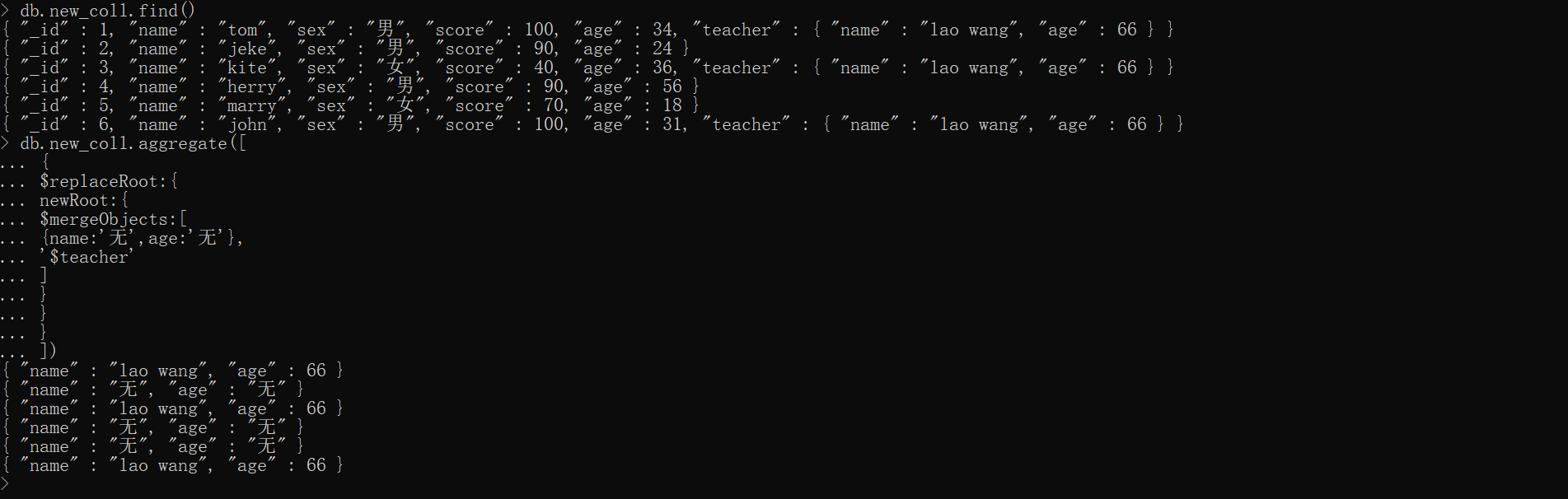
$replaceWith——* 用指定的嵌入文档替换文档
v4.2+ 可用, $replaceRoot 能用的 $replaceWith 基本也可以用,只是语法少了 newRoot 属性
语法:
xxxxxxxxxx{ $replaceWith: <replacementDocument> }简单使用
xxxxxxxxxxdb.students.aggregate([ {$replaceWith: {info:'$age'}} ])
更复杂的,如输出学生信息和成绩
xxxxxxxxxxdb.students.aggregate([ { $replaceWith:{ info:{ $concat:['$name',',性别','$sex'] }, score:'$score' } }])
与 $mergeObjects 配合使用,查询 new_coll 集合中的教师信息,若没有则默认补上"无"
xxxxxxxxxx# 准备数据 new_fulldb.new_coll.drop()db.students.find()db.students.aggregate([ {$out:'new_coll'}])db.new_coll.updateMany( {_id:{$in:[1,3,6]}}, {$set:{teacher:{name:'lao wang',age:66}}})db.new_coll.find()
# 开始执行测试db.new_coll.aggregate([ { $replaceWith:{ $mergeObjects:[ {name:'无',age:'无'},'$teacher' ] } }])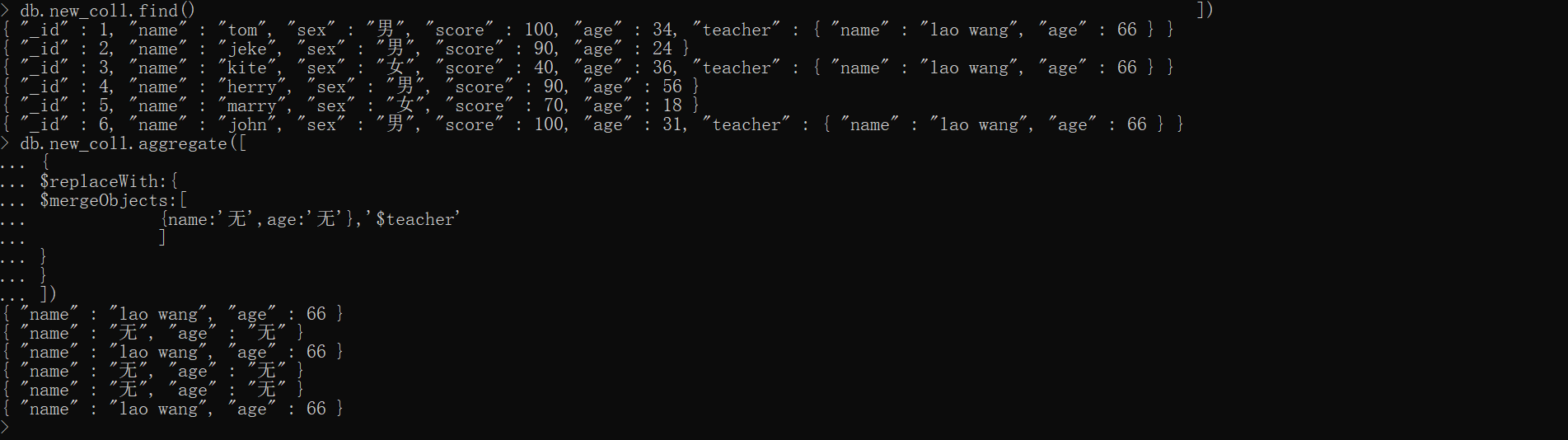
$sample——* 从输入中随机选择指定数量的文档。
v3.2+ 可用
语法:
xxxxxxxxxx{ $sample:{size:<int>}}简单示例,随便取出3条记录
xxxxxxxxxxdb.students.aggregate([ {$sample:{size:3}}])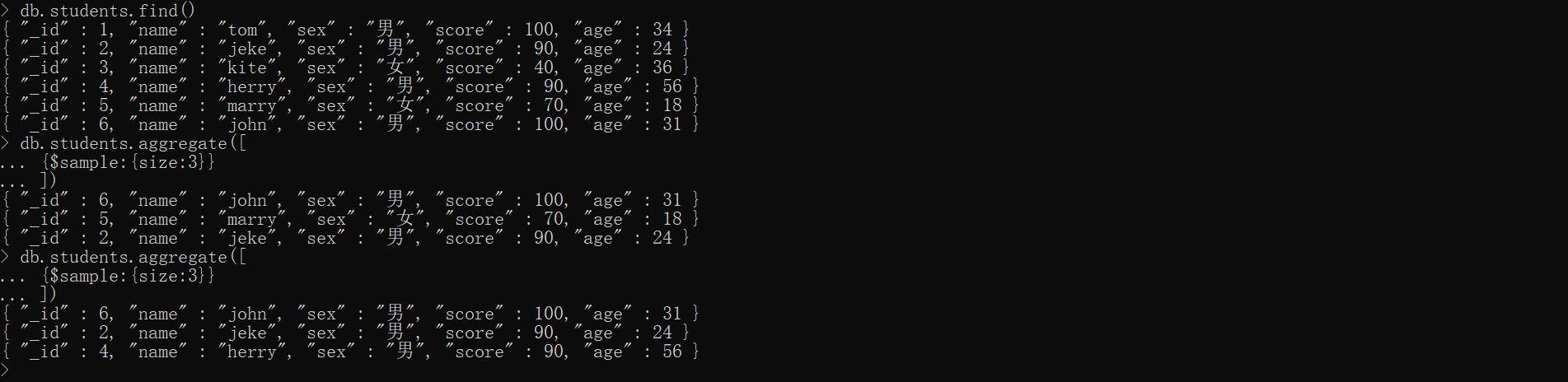
$set——* 向文档添加新字段。
v4.2+可用,与$project 类似,$set会重新塑造流中的每个文档。$set是$addFields阶段的别名。
语法:
xxxxxxxxxx{ $set:{'name':expression} }简单示例,查询时加一个 age、score 字段的平均值
xxxxxxxxxxdb.students.aggregate([ { $set:{ avg_score:{$avg:['$age','$score']} } }])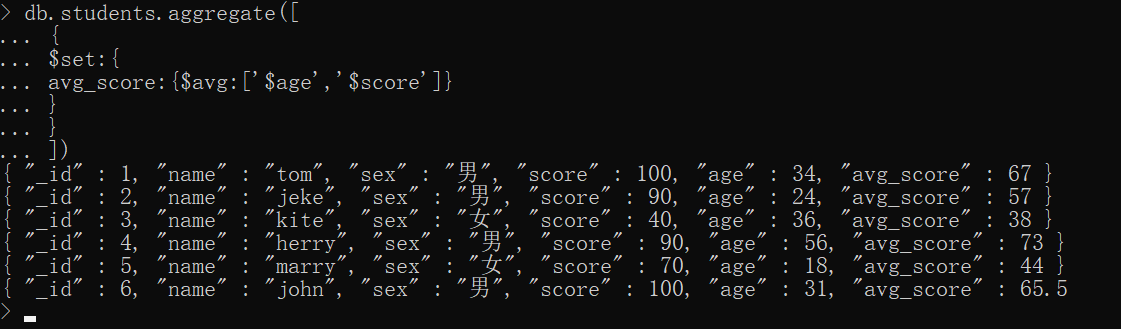
处理数组
xxxxxxxxxx# 准备数据 new_fulldb.new_coll.drop()db.new_coll.insertOne( {arr:[1,2,3]})db.new_coll.find()
# 开始执行测试db.new_coll.aggregate([ { $set:{ arr:{ $concatArrays:['$arr',[4,5,6]] } } }])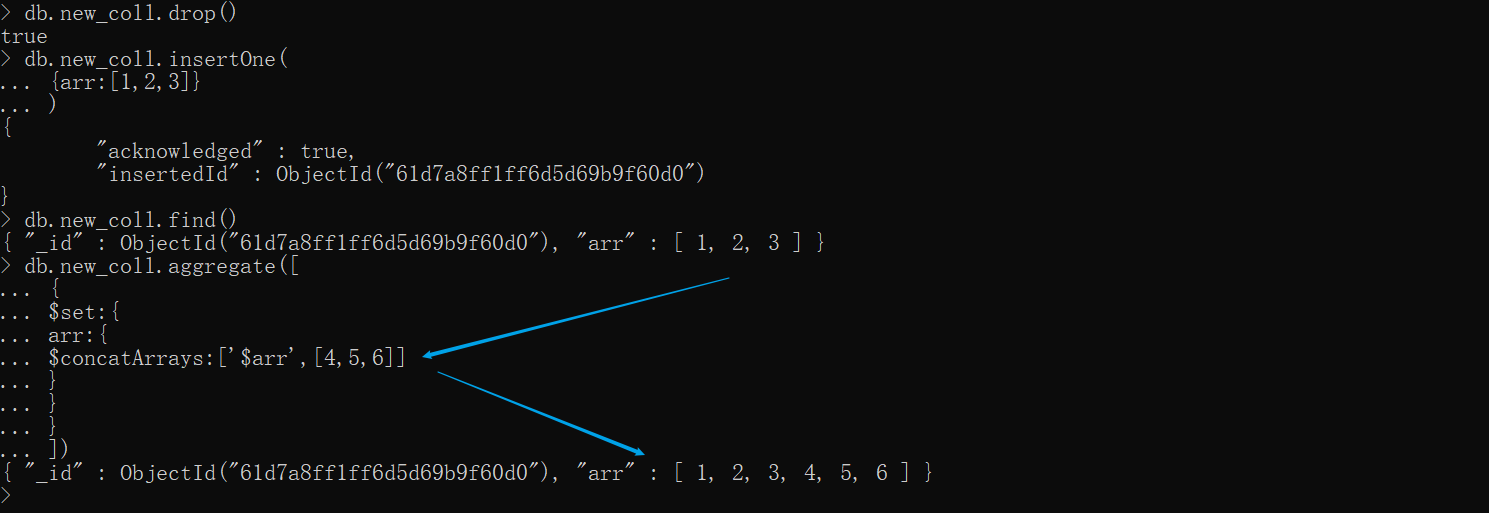
$skip——* 待操作集合处理前跳过部分文档
简单示例
xxxxxxxxxxdb.students.aggregate([ {$skip:2}])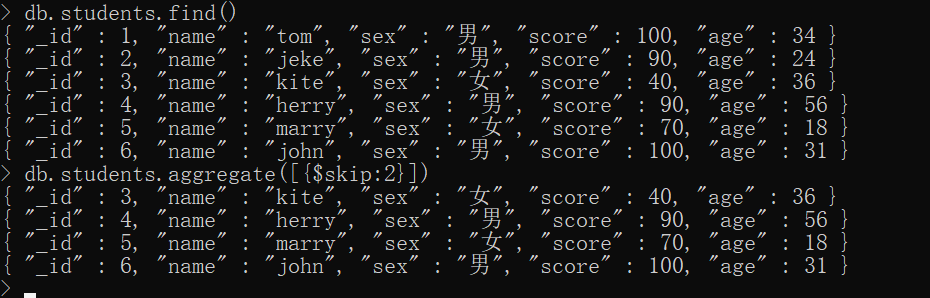
$sort——* 按指定的排序键重新排序文档
xxxxxxxxxxdb.students.find()# 正序db.students.aggregate([{$sort:{age:1}}])# 倒序db.students.aggregate([{$sort:{age:-1}}])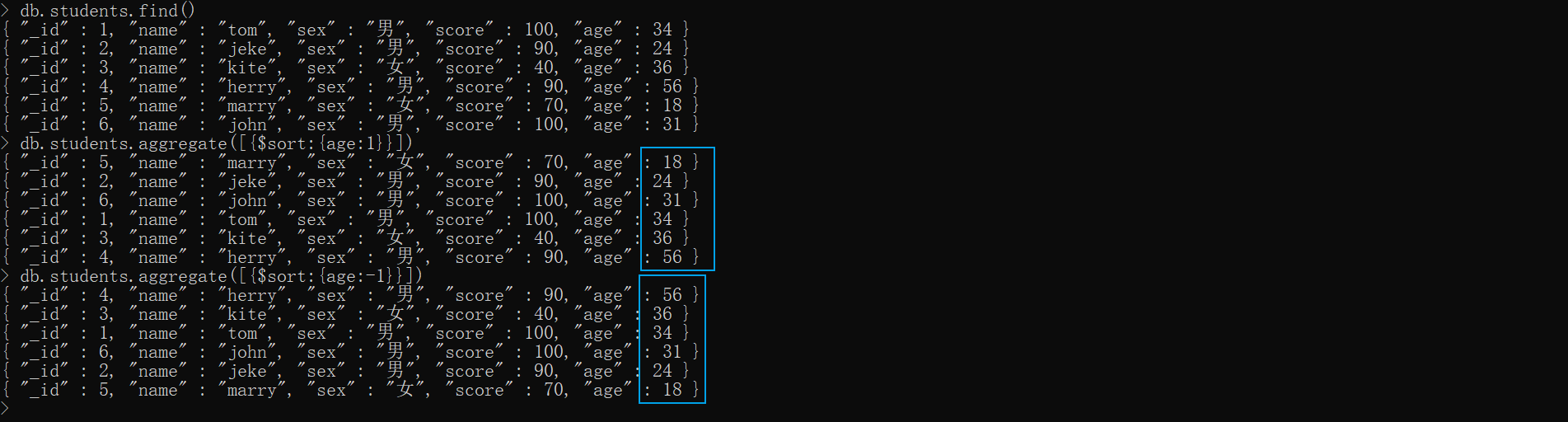
$sortByCount——根据某字段分组,然后计算每个不同组中的文档计数
v3.4+ 可用
简单示例,按照学生成绩分组,并根据数量倒排
xxxxxxxxxxdb.students.aggregate([ {$sortByCount:'$score'}])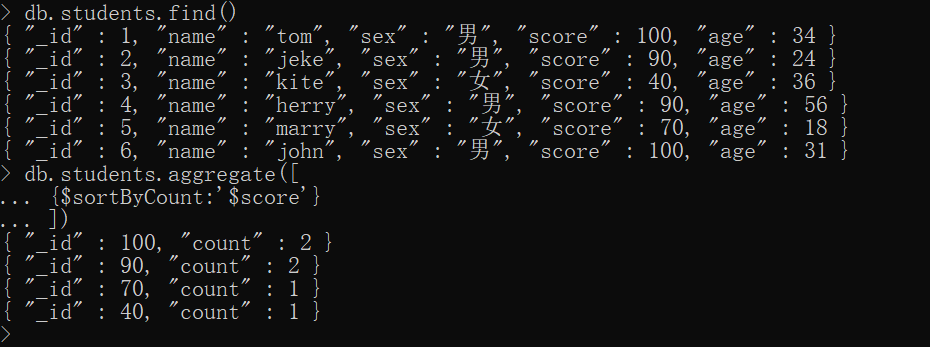
$unionWith——* 执行两个集合的并集
v4.4+ 可用
xxxxxxxxxx{ $unionWith:{ coll:'', pipeline:{}, # 不可包含$out、$merge,仅支持处理coll集合 }}简单示例
xxxxxxxxxxdb.students.aggregate([ { $unionWith:{ coll:'address', pipeline:[{$match:{student_id:{$gt:2}}}] } }])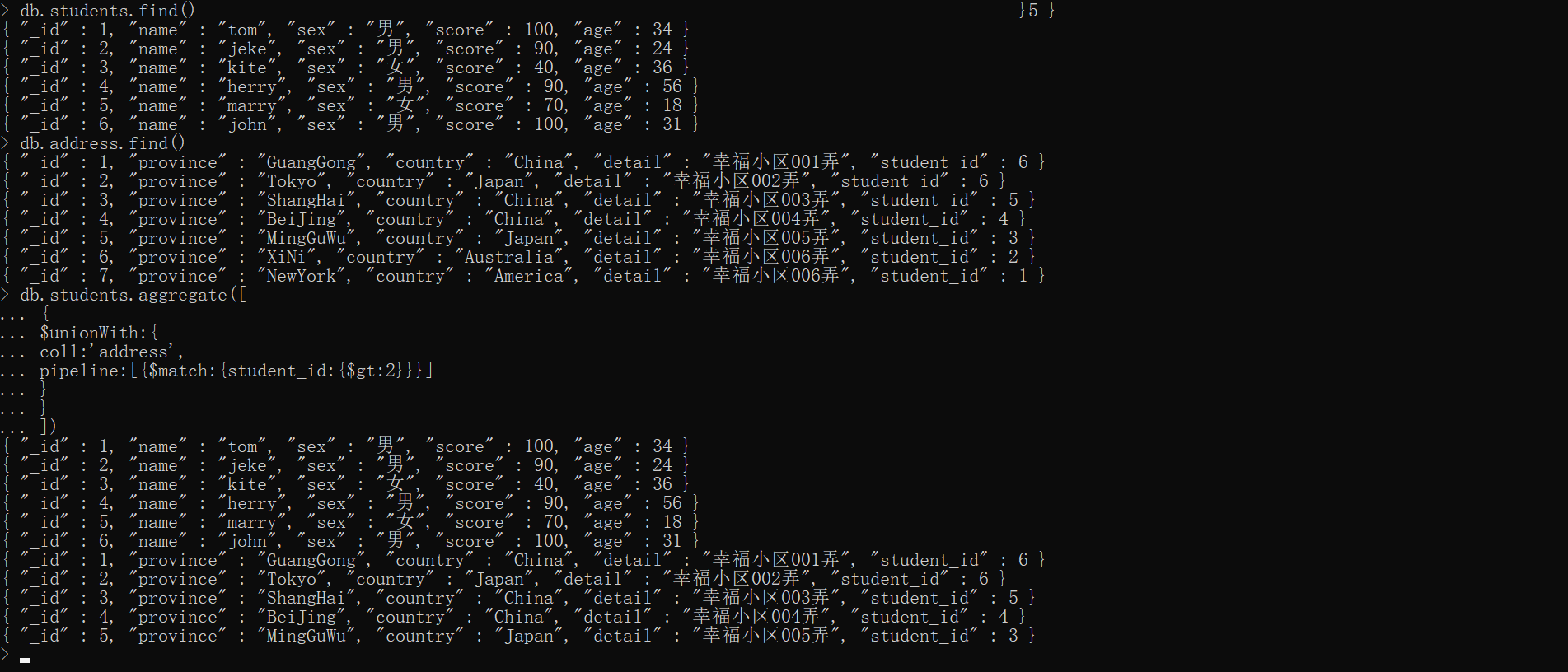
$unset——* 从文档中移除/排除字段
v4.2 可用
xxxxxxxxxx{ $unset:"" 或 [], }简单示例
xxxxxxxxxxdb.students.aggregate([ {$unset:'sex'}])db.students.aggregate([ {$unset:['sex','age','score']}])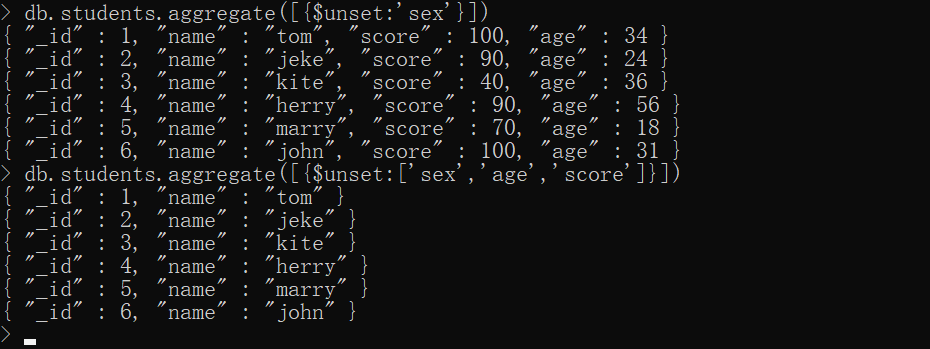
$unwind——解析输入文档中的数组字段,为每个元素输出一个文档
v3.2+ 可用
语法:
xxxxxxxxxx{ $unwind: { path: <field path>, includeArrayIndex: <string>, # 下标值 preserveNullAndEmptyArrays: <boolean> # 若为false,且path为空、缺失或空数组,则 $unwind 不会输出文档,默认为false }}简单示例
xxxxxxxxxx# 准备数据 new_fulldb.new_coll.drop()db.new_coll.insertOne( {arr:[1,2,3]})db.new_coll.find()
db.new_coll.aggregate([ {$unwind:{ path:'$arr' }},])# 也可以这样写db.new_coll.aggregate([ {$unwind:'$arr'},])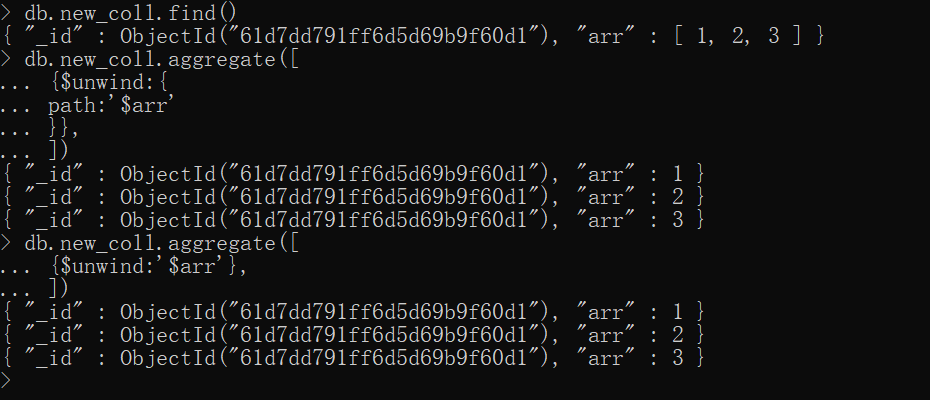
查看下标
xxxxxxxxxxdb.new_coll.aggregate([ {$unwind:{ path:'$arr', includeArrayIndex:'index' }},])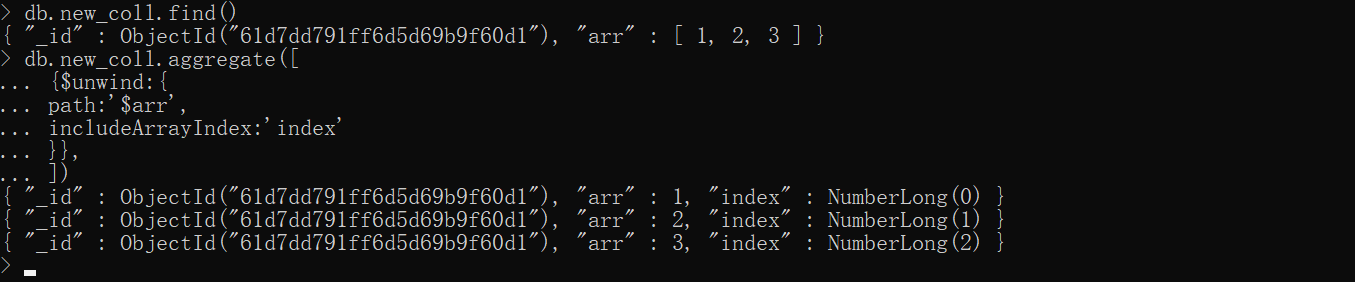
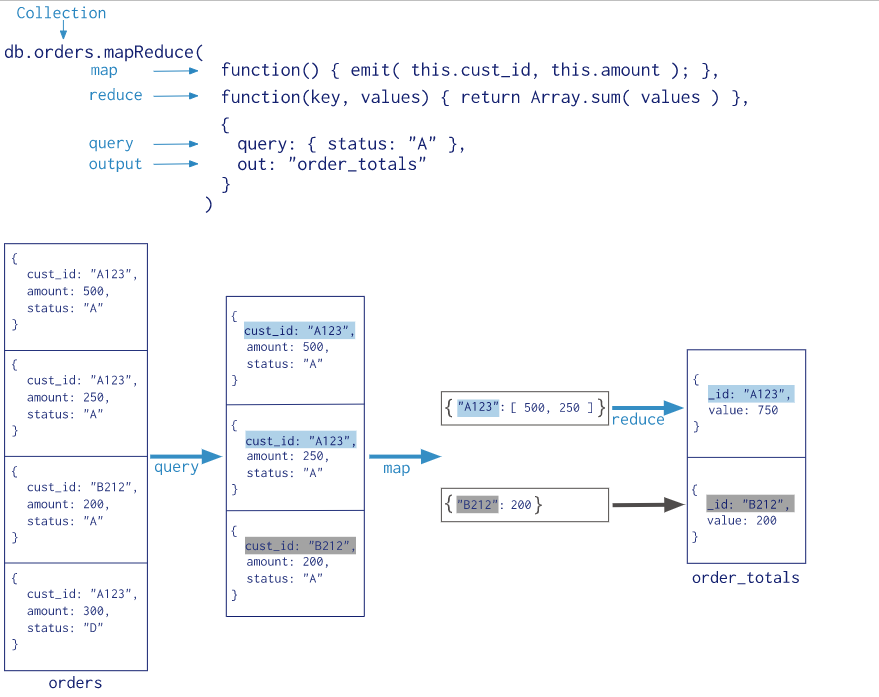
Map-Reduce
流程:先筛选一层(query),通过cust_id进行分组(map),获取分组后每一组的数量(reduce),再进行输出(output)
简单示例
xxxxxxxxxxshow collectionsdb.students.mapReduce( function(){emit(this.sex, this);}, function(key_sex,value_student){return value_student}, { query:{age:{$gte:30}}, out:'student_group' })show collectionsdb.student_group.find()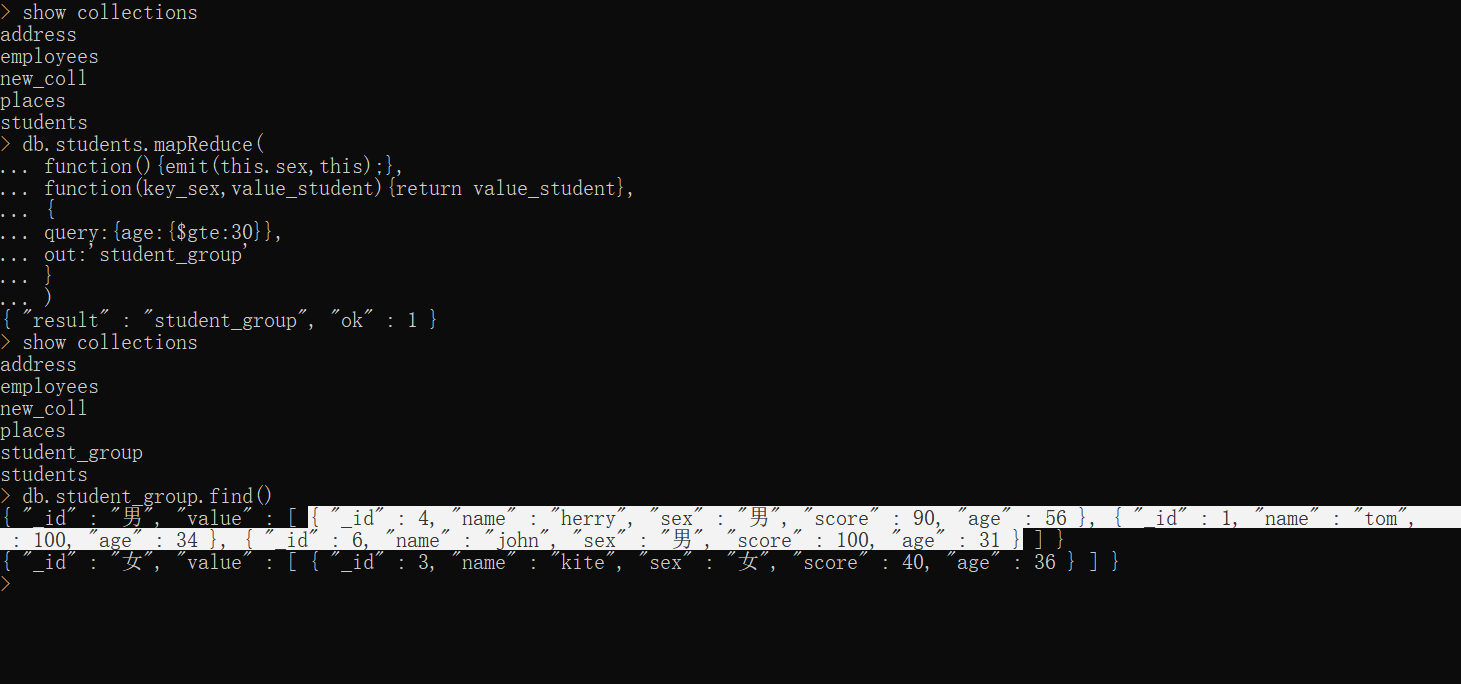
emit一定是要两个参数,如果你想输出整个对象直接指定this即可,如果你只想输出一个属性,如name,应该这样写:emit(this.sex, this.name),如果你像输出特定(两个以上)的属性,如name、age,我们可以这样写:emit(this.sex,{name:this.name,age:this.age}),千万不要这样写:emit(this.sex,{name,age})
这个out是覆盖写入的
x
db.students.mapReduce( function(){emit(this.sex,{name:this.name,age:this.age})}, function(key_sex,value_student){return value_student}, { query:{age:{$gte:30}}, out:'student_group' })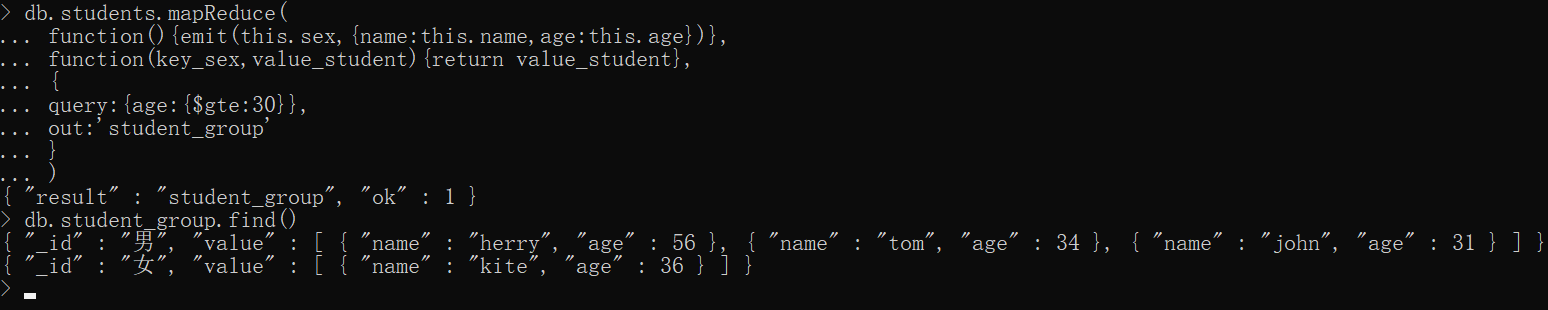
使用aggregate来替换MapReduce
xxxxxxxxxxdb.students.aggregate([ {$match:{age:{$gte:30}}}, {$group:{'_id':'$sex','value':{$push:{name:'$name',age:'$age'}}}}, {$out:'student_group'}])
单用聚合操作
estimatedDocumentCount
v4.0.3+ 可用,计算集合总数
xxxxxxxxxxdb.students.estimatedDocumentCount({})
对于搜索无效

count
计算集合总数,可搜索、可过滤、可提取、可设置读关注、可设置超时时间
语法:
xxxxxxxxxx{ query:{} # 查询条件},{ limit:int, # 提取n条 skip:int, # 跳过n条 hint:'' or {}, # 指定索引 maxTimes:int, # 超时时间、毫秒 readConcern:'', # 读关注,默认local collation:{}}简单示例
xxxxxxxxxxdb.students.count()db.students.count({sex:'男'})db.students.count({sex:'男'},{limit:1})db.students.count({sex:'男'},{skip:1})db.students.count({_id:{$lt:5}},{hint:'_id_'})db.students.count({_id:{$lt:5}},{hint:{_id:1}})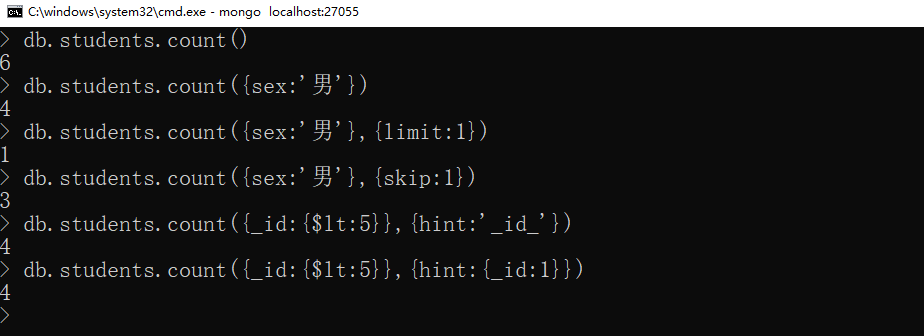
distinct
按照字段筛选重复项
语法:
xxxxxxxxxx( fidld:'', # 字段名称 query:{}, # 筛选条件 collation:{})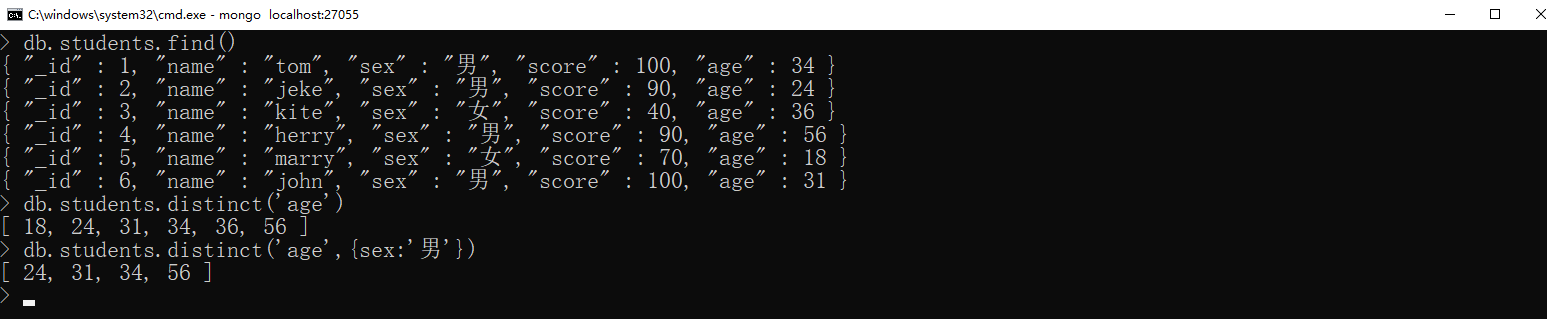
其他
本来是不打算记录的,因为文档上该有的都有,例子也很鲜明通俗易懂,但看着看着总觉得还得自个抄一下,才能更深刻一点。aggregate 是个很实用得东西,对复杂查询、查询速度这两个操作比直接find效率要高很多,我们要学的不是语法,而是要学会将各个阶段得命令结合起来,更快查询到我们想要的东西。
含 * 的可能是平常比较常见、用得比较多命令吧。(该叫它命令呢?还是阶段?)
下一篇找时间整理一下mongodb得常见函数。