Redis常用命令合集
>说明基础操作链接退出SELECT——切换数据库COPY——复制key*DEL——删除key*EXISTS——判断key是否存在*EXPIRE——指定Key多少秒后超时EXPIREAT——指定Key在某个时间点超时EXPIRETIME——返回key设置的过期时间戳*KEYS——查找KeyMOVE——移动Key到某个库*PERSIST——移除key的过期设置PEXPIRE——指定Key多少毫秒后超时PEXPIREAT——指定Key在某个时间点超时PEXPIRETIME——返回key设置的过期时间戳PTTL——查看Key超时时间RANDOMKEY——随机取一个Key*RENAME——重命名KeyRENAMEEX——重命名Key,若存在则忽略*SACN——增量迭代key*SORT——排序KeySORT_RO——排序key、只读TOUCH——更新key的最后访问时间*TTL——查看Key超时时间*TYPE——查看Key的类型*UNLINK——将Key取消链接,后续删除STRING类型常用操作*APPEND——追加字符串*DECR——递减DECRBY——指定步长递减*GET——获取key的值GETDEL——获取key的值并删除该keyGETEX——获取key的值并设置该key的过期时间GETRANGE——获取某段字符串GETSET——设置key的值并返回旧值*INCR——递增INCRBY——指定步长递增INCRBYFLOAT——指定浮点步长递增*MGET——获取多个key值*MSET——设置多个key值MSETNX——设置多个key值,若该key已存在,则忽略PSETEX——设置key值并指定过期时间ms*SET——设置key值SETEX——设置key值,并指定过期时间sSETNX——设置key值,若该key已存在,则忽略SETRANGE——修改指定区域*STRLEN——获取key值的字符串长度SUBSTR——截取key值LIST类型常用操作BLPOP——删除并返回第一个元素,或阻塞直到第一个元素可用BRPOP——删除并返回最后一个元素,或阻塞直到第一个元素可用LINDEX——获取下标*LINSERT——插入元素*LLEN——获取列表长度LMOVE——从列表a中移除,将其移动到列表b并返回LMPOP——弹出一个或多个元素*LPOP——从左边弹出并返回元素LPOS——返回匹配元素的下标*LPUSH——从左边将元素推入列表LPUSHX——当集合存在时,从左边将元素推入列表*LRANGE——获取指定区间数据*LREM——移除元素*LSET——通过下标设置值LTRIM——截取并保留指定区间数据*RPOP——从右边弹出并返回元素*RPUSH——从右边将元素推入列表*RPUSHX——当集合存在时,从右边将元素推入列表SET无序集合操作*SADD——添加成员*SCARD——返回集合长度*SDIFF——获取差集SDIFFSTORE——获取差集并存储新key中*SINTER——获取交集SINTERCARD——获取交集并返回结果基数SINTERSTORE——获取交集并存储新key中*SISMEMBER——判断成员是否在集合中*SMEMBERS——获取全部成员SMISMEMBER——获取成员与集合的关系SMOVE——移动成员到另一集合*SPOP——弹出成员并返回SRANDMEMBER——随机获取成员*SREM——移除成员SSCAN——增量迭代成员*SUNION——获取并集SUNIONSTORE——获取并集并存储新key中ZSET(Sorted Set)有序集合常用操作BZMPOP——删除并返回成员与分数,或阻塞直到第一个元素可用BZPOPMAX——删除并返回最高分数的成员,或阻塞直到第一个元素可用BZPOPMIN——删除并返回最低分数的成员,或阻塞直到第一个元素可用*ZADD——添加成员更新分数*ZCARD——返回集合长度*ZCOUNT——查看某个分数区间的集合长度*ZDIFF——获取差集ZDIFFSTORE——获取差集并存储新key中*ZINTER——获取差集ZINTERSTORE——获取差集并存储新key中ZINTERCARD——获取差集,并返回结果基数*ZINCRBY——递增某成员的分数ZLEXCOUNT——获取指定成员区间的数量*ZMPOP——删除并返回分数*ZMSORE——获取某成员的分数ZPOPMAX——删除并返回最高分数的成员ZPOPMIN——删除并返回最低分数的成员ZRANDMEMBER——随机获取成员ZRANGE——获取某个区间的成员ZRANGEBYLEX——按字典范围获取某个区间的成员ZRANGEBYSCORE——根据分数获取某个区间的成员ZRANGESTORE——获取某个区间成员并存储新key中ZRANK——根据成员返回索引,从低到高*ZREM——移除成员ZREMRANGEBYLEX——按字典范围移除某个区间的成员*ZREMRANGEBYRANK——根据索引移除某个区间的成员ZREMRANGEBYSCORE——根据分数移除某个区间的成员ZREVRANGE——返回指定区间成员分数从高到低ZREVRANGEBYLEX——根据字典范围返回指定区间成员ZREVRANGEBYSCORE——根据分数返回指定区间成员ZREVRANK——根据成员返回索引,从高到低*ZSCAN——增量迭代集合*ZSCORE——获取成员分数*ZUNION——获取并集ZUNIONSTORE——获取并集并存储新key中HASH类型常用操作*HDEL——删除HASH字段*HEXISTS——判断是否存在某字段*HGET——获取字段值HGETALL——获取全部字段值*HINCRBY——根据步长递增字段*HINCRBYFLOAT——根据小数步长递增字段*HKEYS——获取所有字段*HLEN——获取字段个数HMGET——获取多个字段值HMSET——设置多个字段值HRANDFIELD——随机获取字段*HSCAN——增量迭代hash字段*HSET——设置字段HSETNX——设置字段,当该字段存在则忽略*HSTRLEN——获取字段值的长度HVALS——获取所有字段值
说明
脑子抽了一般,突然去搬文档...总以为跟着文档敲一遍能提升记忆,加深理解,不过好像不太管用,就当个记录吧
基础操作
链接退出
# 本地redis-cli# 指定服务器redis-cli -h host -p port -a password# 退出,quit、exit均可quit
SELECT——切换数据库
一共16个库,默认使用0库
xxxxxxxxxxselect 1
COPY——复制key
xxxxxxxxxxset age 10# 在本库复制不能指定相同的keycopy age new_agekeys *get new_age
也可以在不同的库之间进行复制操作,执行不成功则返回0
xxxxxxxxxxset new_age 20# 将当前库的age复制到1库的age,此时1库并没有age这个key,成功copy age age DB 1select 1get ageselect 0#将当前库的new_age复制到1库的age,此时1库有age这个key,未成功copy new_age age DB 1select 1get ageselect 0#将当前库的new_age复制到1库的age,当存在相同key时则替换,此时1库有age这个key,成功copy new_age age DB 1 REPLACEselect 1get age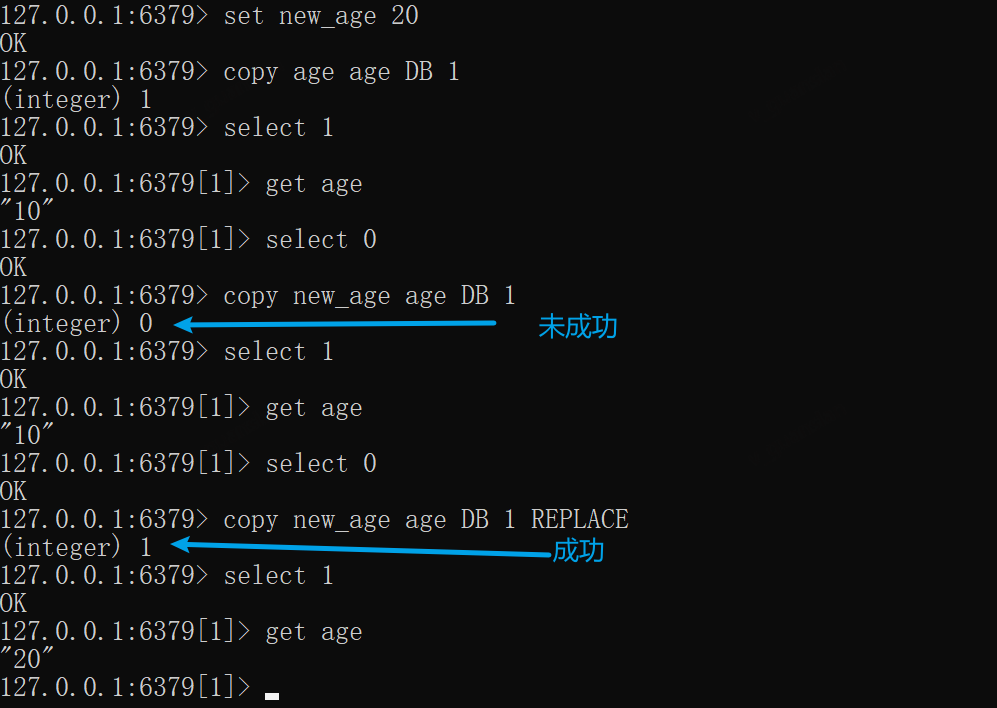
*DEL——删除key
删除成功将会返回已删除条数,未找到key删除则返回0。注意:del无法使用通配符进行删除
xxxxxxxxxxkeys *del *del agedel key1 new_age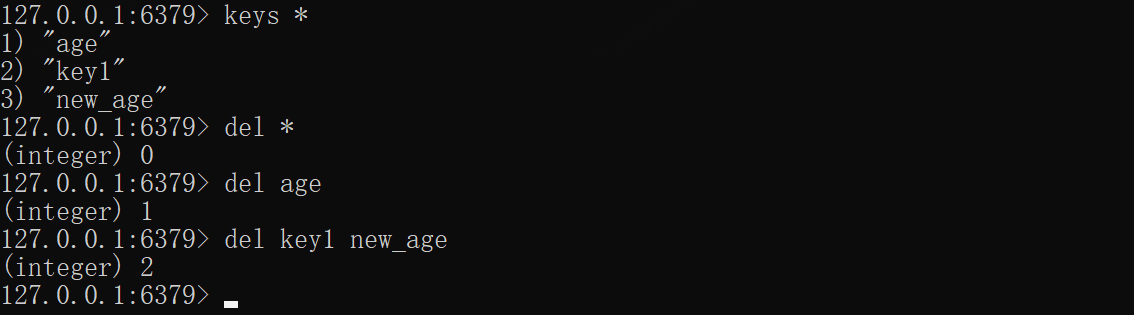
*EXISTS——判断key是否存在
存在返回1,不存在返回0
xxxxxxxxxxkeys *exists ageset age 10exists age
*EXPIRE——指定Key多少秒后超时
设置成功返回1,不成功返回0
EXPIRE key seconds [NX | XX | GT | LT]
- NX -- 仅当Key没有过期时才设置过期
- XX -- 仅当Key已过期时才设置过期
- GT -- 仅在新到期时间大于当前到期时设置到期
- LT -- 仅在新到期时间小于当前到期时设置到期
关于Redis的过期,只有DEL、SET、GETSET、*STORE、PERSIST命令才能清除某个key的过期,其他命令均不可
更多可参考:EXPIRE | Redis
xxxxxxxxxxset age 20# 设置 age 10秒后过期expire age 10# 查看age的过期时间ttl age
EXPIREAT——指定Key在某个时间点超时
和EXPIRE实现一样的效果,只是参数变成了某个点的时间戳(秒)(当前时区)
xxxxxxxxxxset age 20# 设置 age 在2022-10-25 16:29 过期expireat age 1666686540ttl age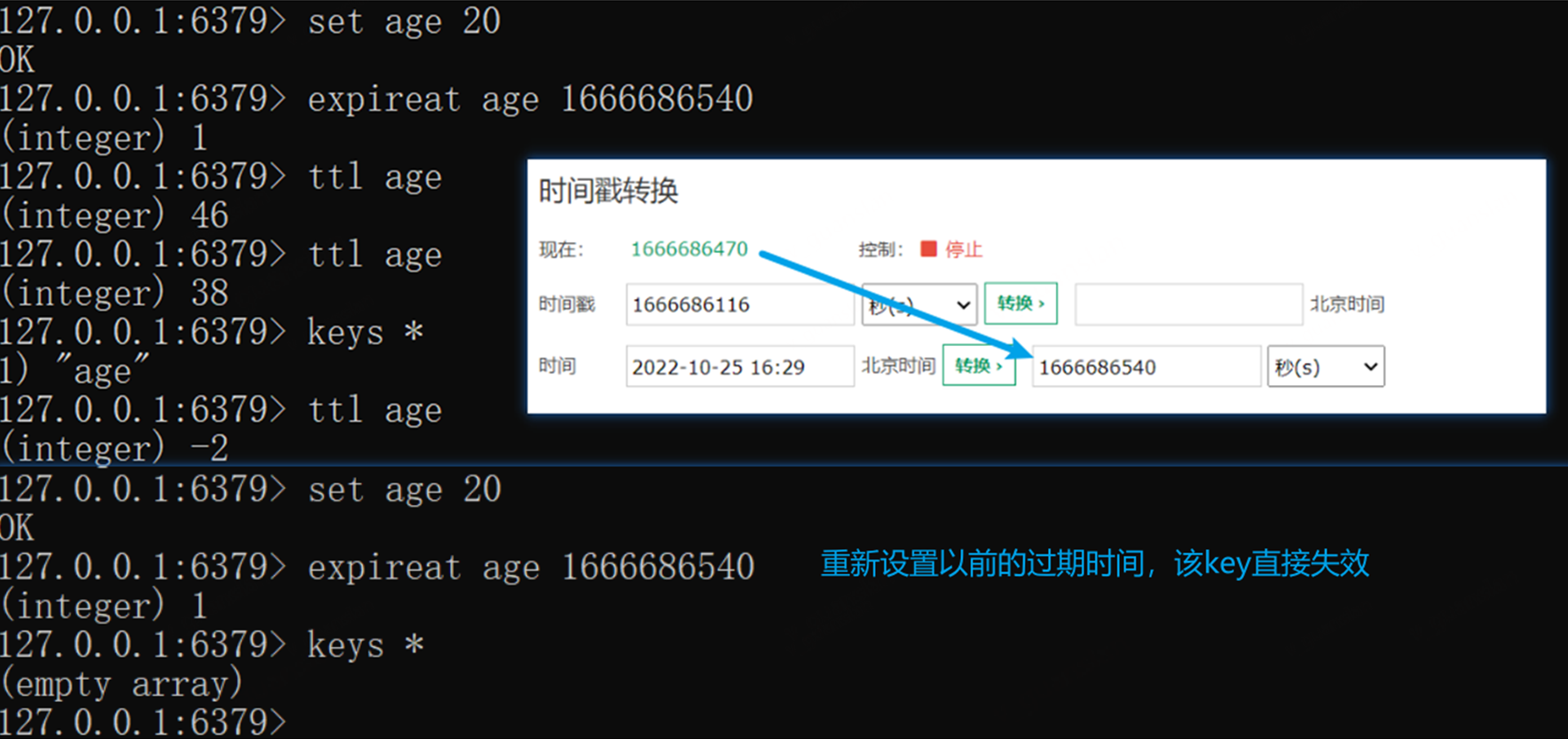
EXPIRETIME——返回key设置的过期时间戳
与TTL用法类似,若该key设置过期,则返回过期时间点的时间戳,未设置则返回-1
xxxxxxxxxxset age 100expireat age 1666690140expiretime age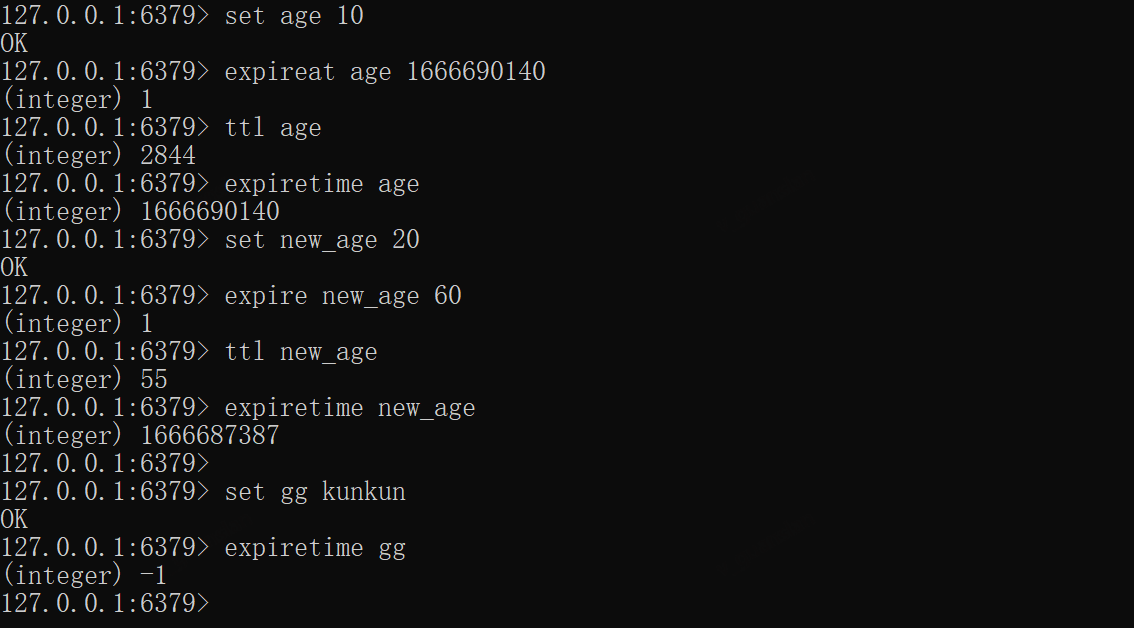
*KEYS——查找Key
查找指定的key值,可使用简单正则进行匹配
xxxxxxxxxx# 查看全部keykeys *keys namekeys name*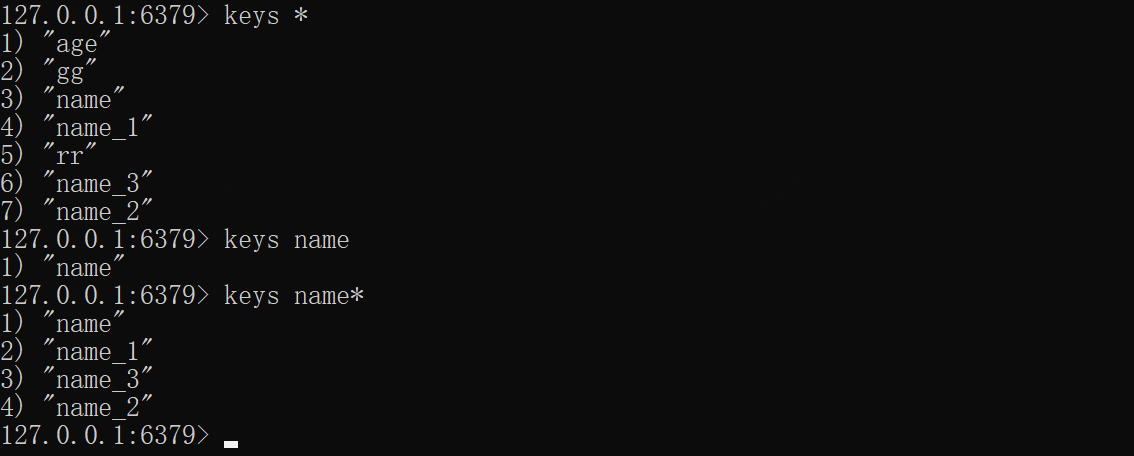
MOVE——移动Key到某个库
成功则返回1,未成功则返回-1,若指定库存在该key,移动不成功
xxxxxxxxxxset age 10# 将age移动到1库move age 1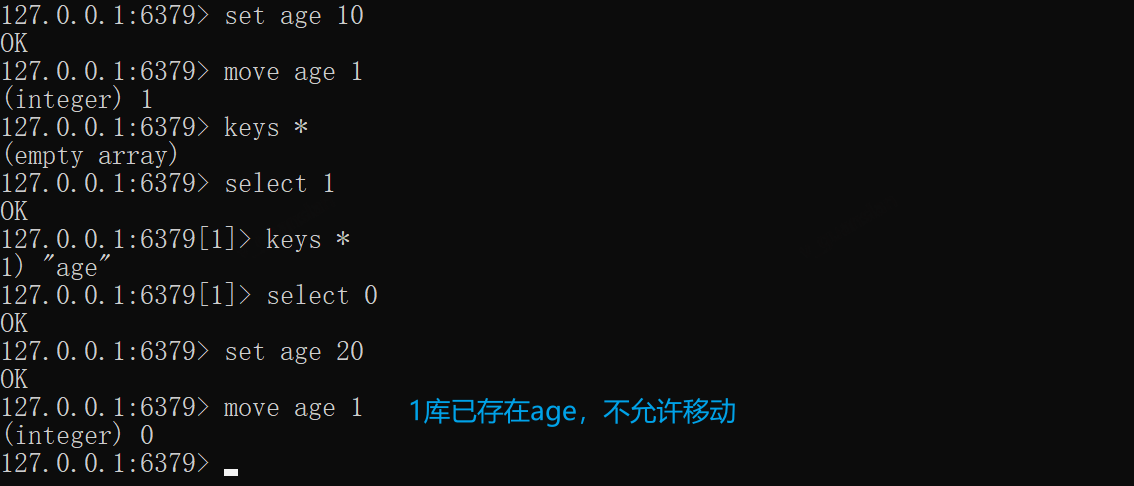
*PERSIST——移除key的过期设置
成功则返回1,key不存在或者未设置过期则返回0
xxxxxxxxxxset age 10expire age 20persist age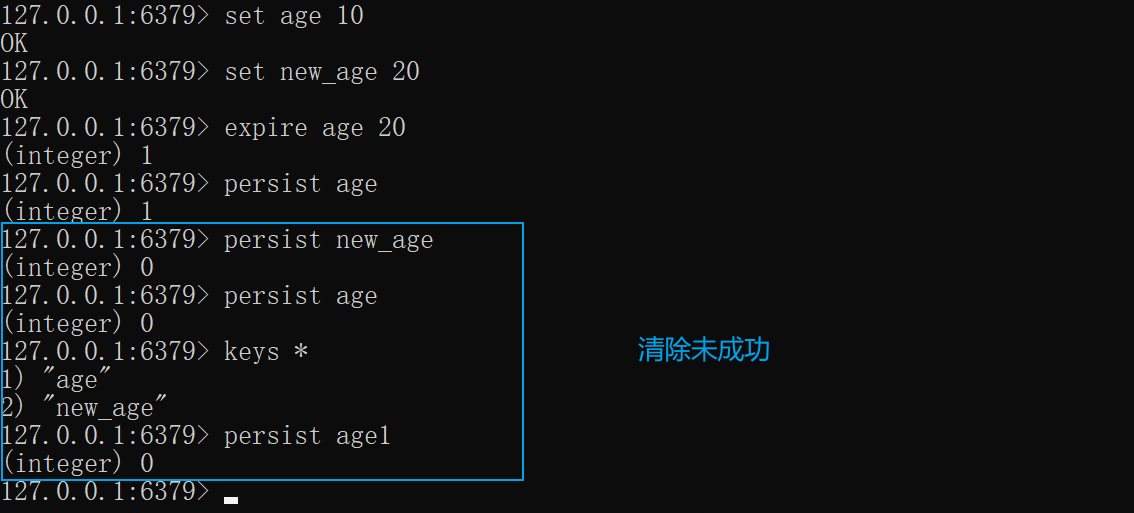
PEXPIRE——指定Key多少毫秒后超时
和EXPIRE用法一致,只是时间单位由秒变成毫秒而已
xxxxxxxxxxset age 10pexpire age 10000
PEXPIREAT——指定Key在某个时间点超时
和EXPIREAT用法一致,只是时间戳单位由秒变成毫秒而已
xxxxxxxxxxset age 20# 设置 age 在2022-10-25 16:29 过期pexpireat age 1666686540ttl agePEXPIRETIME——返回key设置的过期时间戳
和EXPIRETIME用法一致,只是时间戳单位由秒变成毫秒而已
xxxxxxxxxxset age 100expireat age 1666690140expiretime agePTTL——查看Key超时时间
和TTL用法一致,都有查看某个key的超时时间,PTTL返回的时间单位为毫秒
xxxxxxxxxxset age 100expire age 10ttl agepttl age
RANDOMKEY——随机取一个Key
没有任何key时返回nil
x
set age 10set new_age 10randomkey
*RENAME——重命名Key
不管新key是否存在都会直接覆盖,成功则返回Ok,不存在旧key时则报错
xxxxxxxxxxset age 10rename age new_ageset age 100rename age new_age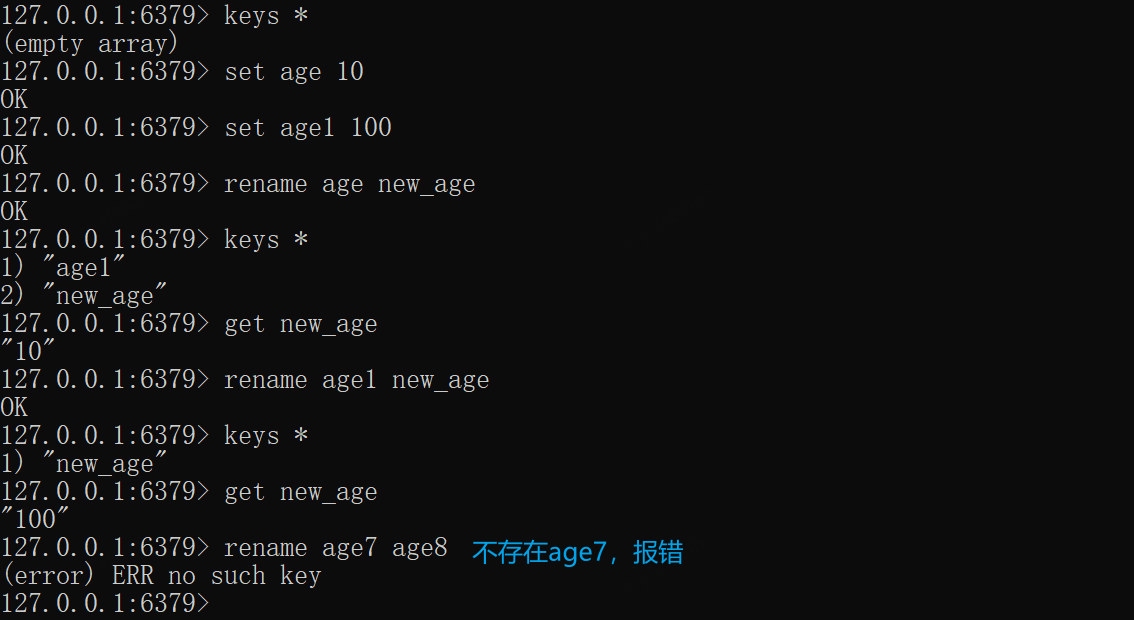
RENAMEEX——重命名Key,若存在则忽略
和RENAME用法一致,当新key存在时,无法直接覆盖
x
set age 10renamenx age new_ageget ageset age 100# 未成功renamenx age new_age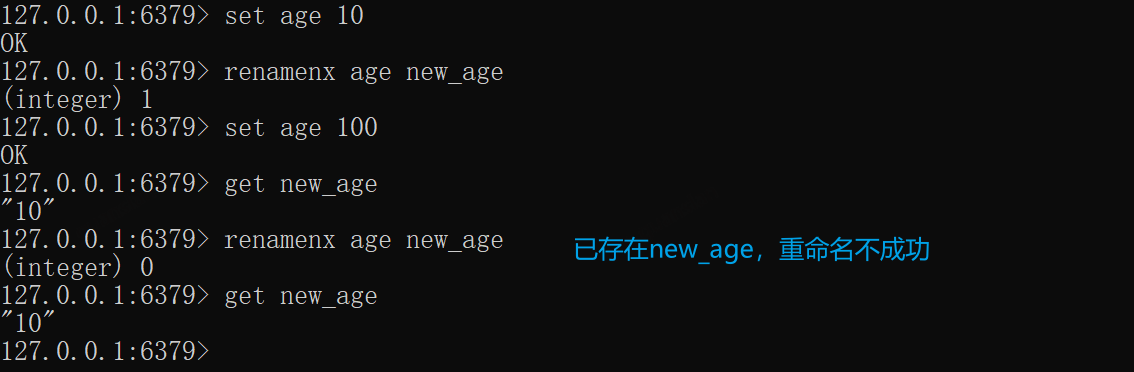
*SACN——增量迭代key
当库中存在大量key时,不建议使用keys *或者smembers来查看key,我们可以使用对应的scan指令查看,scan支持正则、指定数量(不准确)、指定类型,使用语法如下:
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
每次请求都会返回数据和游标,游标供下次查询,默认0为开始游标,若返回的游标是0则说明已经迭代完数据
redis使用scan count 返回数量不准确 - 走看看 (zoukankan.com)
x
keys *scan 0 MATCH age* COUNT 2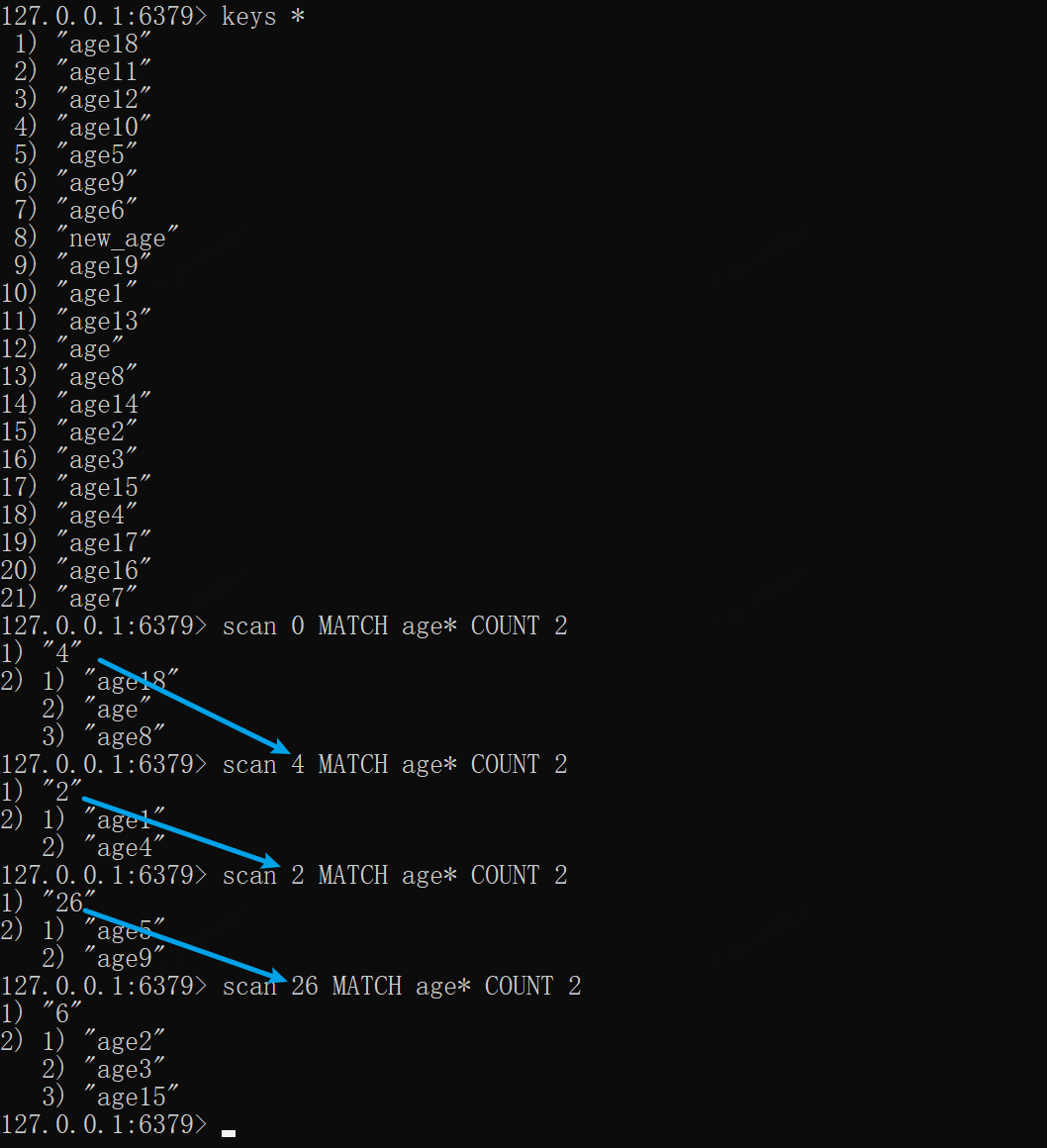
*SORT——排序Key
SORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC | DESC] [ALPHA] [STORE destination]
仅支持对list、set、sorted set(有序集合)操作,此处用set类型来演示
SORT排序,默认会将值统一转换成双精度浮点数(double)再排序,若某个值无法转换则排序报错,默认正排(ASC),可指定DESC实现倒排
x
sadd num_set 10 100 1sort num_setsort num_set DESCsort num_set ASC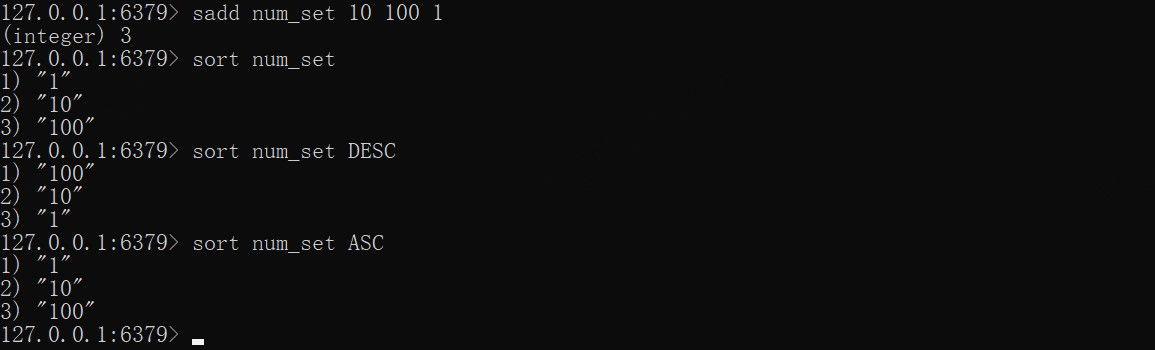
SORT排序,当集合中混杂字符串和数字类型,无法直接进行数值排序,可以指定ALPHA来实现字符串排序
x
sadd str_set 10 100 1 kk# 报错sort str_setsort str_set ALPHAsort str_set ALPHA DESC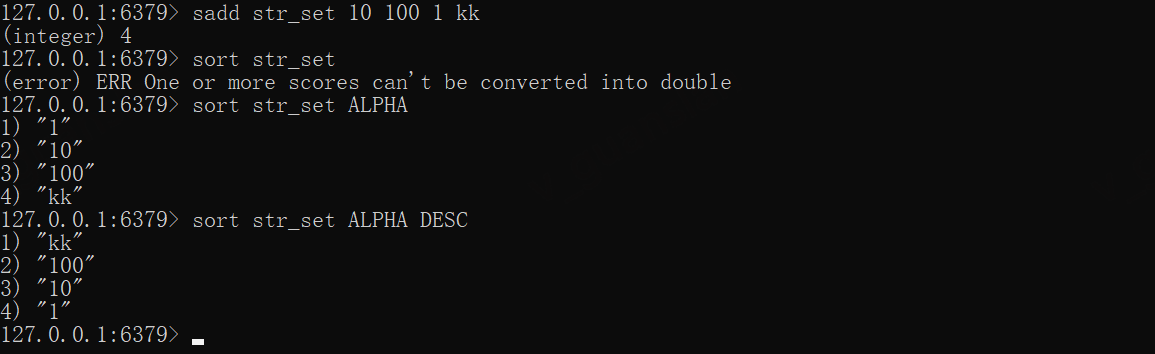
SORT排序,可以依赖外部值作为排序依据,与本集合元素的值无关,做到这一步需要我们有两处数据源:本集合、外部值
通过GET可以获取到外部值GET weight_*和本集合的元素GET #
参考:redis-sort by - 崔好好 - 博客园 (cnblogs.com)
redis的sort命令详解 - 腾讯云开发者社区-腾讯云 (tencent.com)
x
sadd str_set 10 100 1 kk# 准备外部值set weight_10 5set weight_100 1set weight_1 10set weight_kk 2
# weight_* 与上述外部值的格式保持一致sort str_set by weight_*sort str_set by weight_* GET weight_*# 获取到外部值和本集合的元素sort str_set by weight_* GET weight_* GET #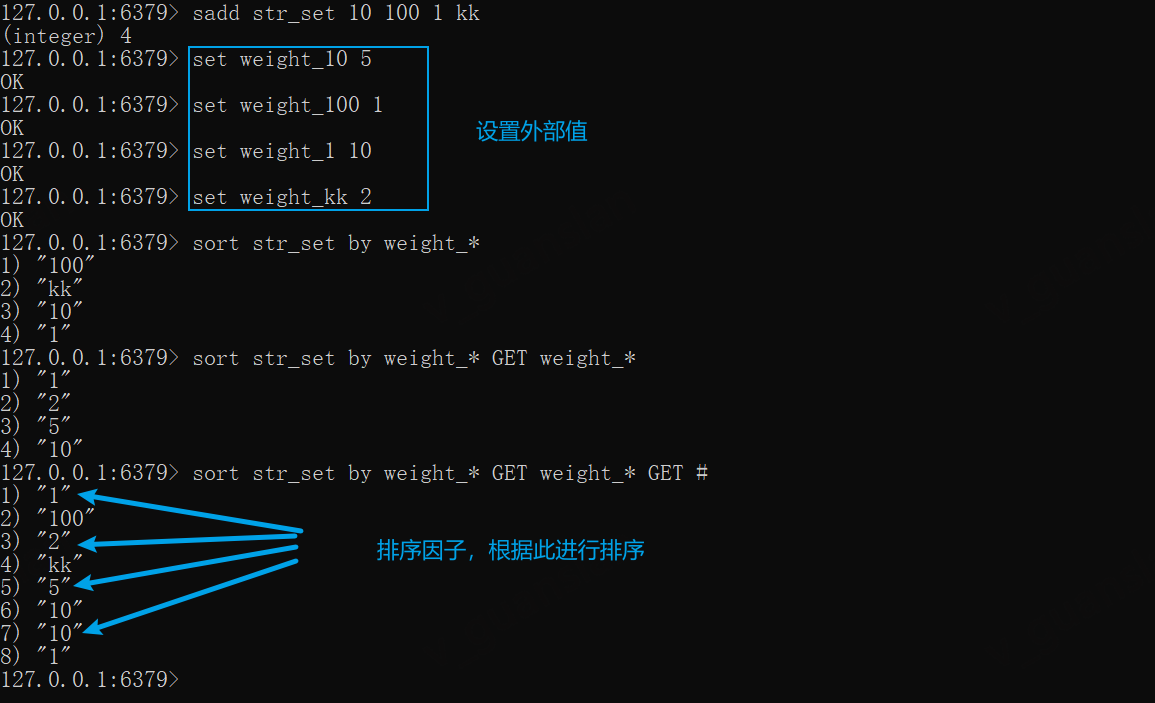
当外部值不足时,未指定外部值的元素将字母排序并排到前面,当外部值都不存在时,则都按字母排序
x
sadd str_set 10 100 1 kk# 准备外部值set weight_10 5set weight_100 1sort str_set by weight_* GET weight_* GET ## 删除所有外部值del weight_10 weight_100sort str_set by weight_* GET weight_* GET #sort str_set by weight_*# 纯数字通过外部值排序,外部值不存在按字母排序sadd num_set 10 100 1 2sort num_set by weight_*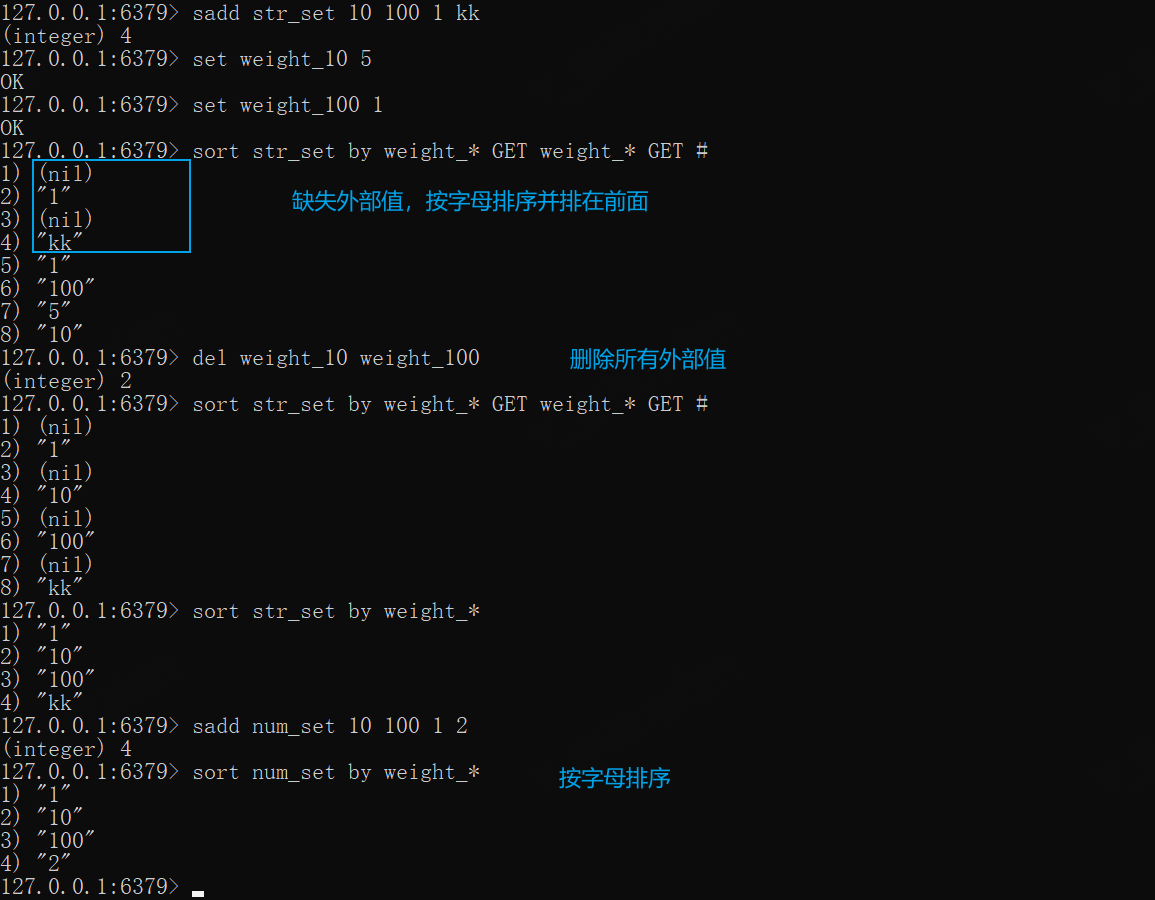
SORT排序,BY还可以指定一个不存在的key跳过排序,避免排序花销(这有什么用?直接查出来不好了吗)
x
sadd str_set 10 100 1 kksort str_set BY no_key
sadd num_set 10 100 1sort num_set BY no_key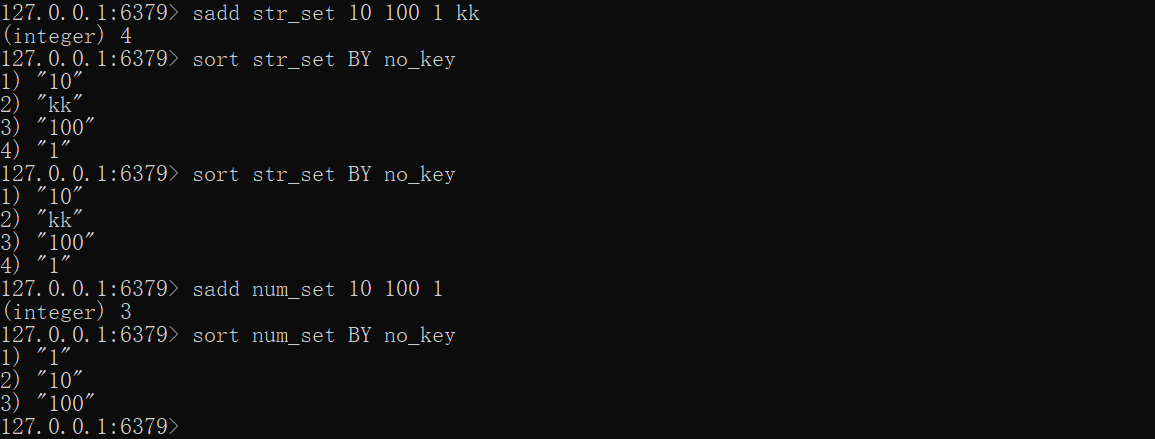
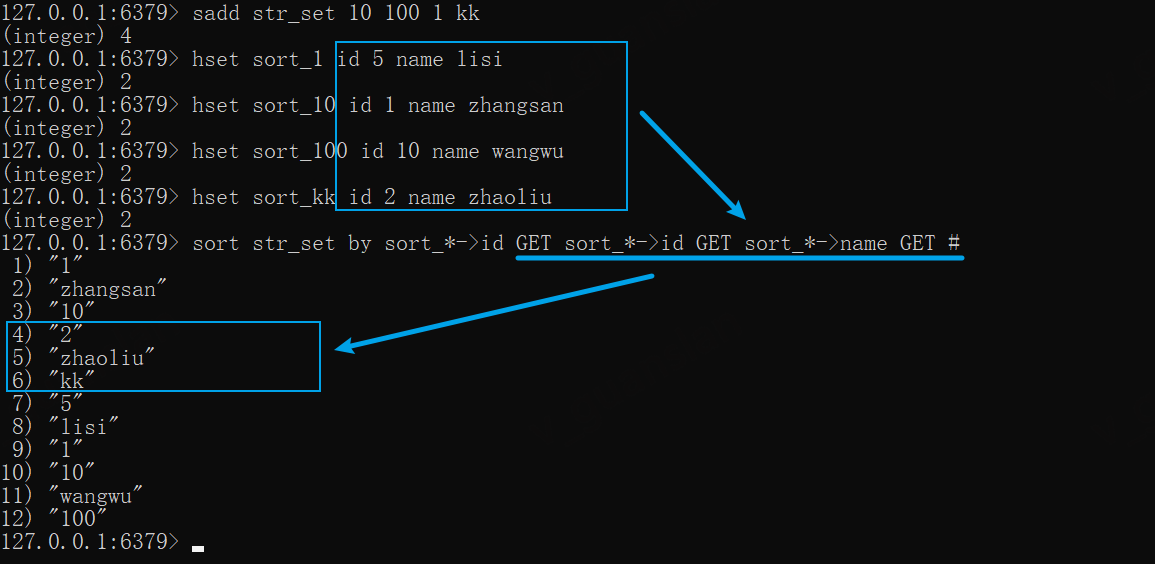
SORT排序,BY、GET在hash中的使用——->
xsadd str_set 10 100 1 kk# 设置外部值,hash类型hset sort_1 id 5 name lisihset sort_10 id 1 name zhangsanhset sort_100 id 10 name wangwuhset sort_kk id 2 name zhaoliu# 根据外部值的id进行排序,并显示外部值的信息sort str_set by sort_*->id GET sort_*->id GET sort_*->name GET #
SORT排序,可以将排序结果存储到另外一个key中,得到的是list类型
xxxxxxxxxxsadd str_set 10 100 1 kksort str_set ALPHA STORE new_set
type new_setlrange new_set 0 -1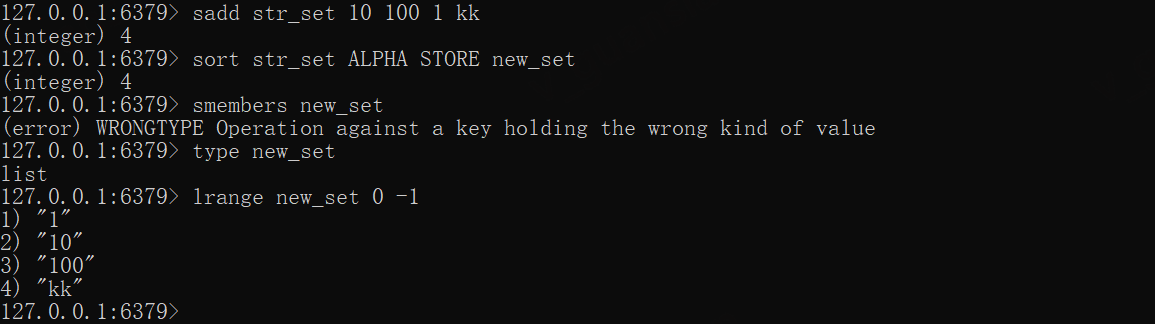
SORT_RO——排序key、只读
SORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC | DESC] [ALPHA]
与sort用法一致,不再赘述。没有STORE选项可以安全地用于只读副本
TOUCH——更新key的最后访问时间
TOUCH key [key ...]
更改密钥的最后访问时间。如果键不存在,则忽略该键。(有什么用?)
x
set name aaset age bbtouch nametouch name age
*TTL——查看Key超时时间
查看某个key的超时时间(秒),成功则返回剩余超时时间,过期、key不存在则返回-2,key未设置过期时间则返回-1
xxxxxxxxxxset age 10expire age 20ttl age
*TYPE——查看Key的类型
Redis常见的类型有:string、list、set、zset、 hash 、stream,注意redis没有数字类型
xxxxxxxxxxset age 10lpush age_arr 10 20 30type agetype age_arr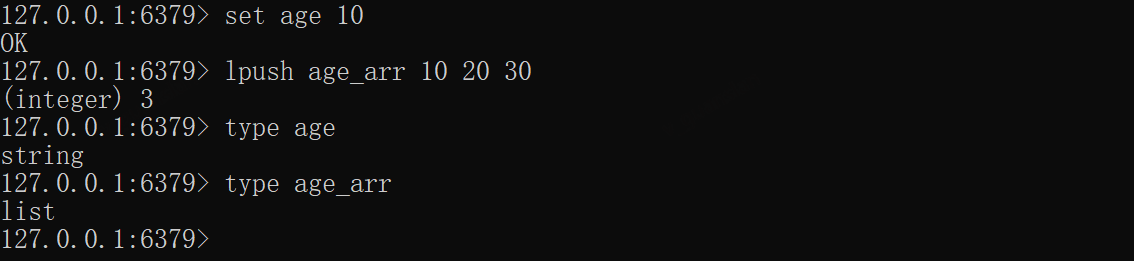
*UNLINK——将Key取消链接,后续删除
该命令与DEL用法类似,非阻塞,执行的时候将key与key空间取消链接,实际的删除将在后续不同的线程异步处理。在删除大key的时候,推荐使用
xxxxxxxxxxset age 10set age1 10unlink age age1
STRING类型常用操作
*APPEND——追加字符串
成功则返回新值的字符串长度
xxxxxxxxxxset name ZhangSanappend name Higet name
*DECR——递减
将某个key值减一,成功则返回递减后的结果,注意只能操作可转为数字的字符串,否则就会报错
xxxxxxxxxxset age 10# 9decr ageget ageset name haha# 报错decr name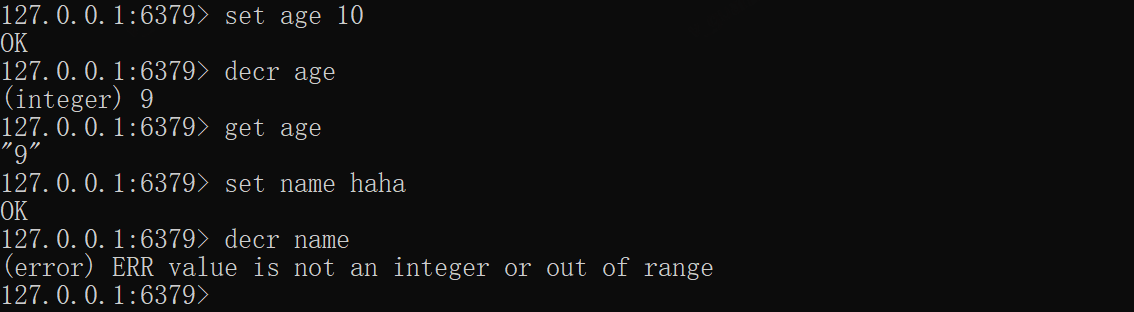
DECRBY——指定步长递减
与decr类似用法,decrby可指定步长,即想减多少都可
xxxxxxxxxxset age 10decrby age 5get age
*GET——获取key的值
最常用的命令之一,根据key中查看相应值,成功则返回值,key不存在则返回nil
xxxxxxxxxxset age 10get ageget new_age
GETDEL——获取key的值并删除该key
成功时返回key值并将该key删除,key不存在则返回nil
xxxxxxxxxxset age 10getdel ageget agegetdel age
GETEX——获取key的值并设置该key的过期时间
GETEX key [EX seconds | PX milliseconds | EXAT unix-time-seconds | PXAT unix-time-milliseconds | PERSIST]
- EX seconds:设置指定的过期时间,以秒为单位。
- PX milliseconds:设置指定的过期时间,以毫秒为单位。
- EXAT timestamp-seconds:设置Key到期的指定 Unix 时间(时间戳),以秒为单位。
- PXAT timestamp-milliseconds :设置Key过期的指定 Unix 时间(时间戳),以毫秒为单位。
- PERSIST:删除与Key关联的过期时间
xxxxxxxxxxset age 10# 获取age,并设置该key在10s后过期getex age EX 10ttl age
GETRANGE——获取某段字符串
根据下标获取某段字符串,下标由0开始,-1表示倒数第一个,依此类推
xxxxxxxxxxset name "Hello World"getrange name 0 2getrange name 5 -1getrange name -3 -1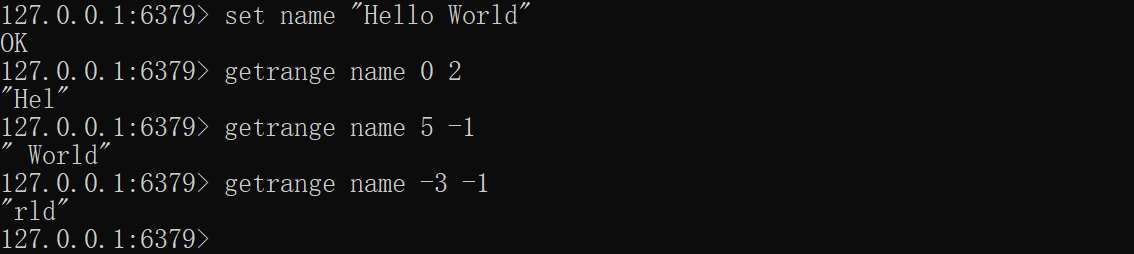
GETSET——设置key的值并返回旧值
成功时返回旧值(key不存在时返回nil)并设置新值
xxxxxxxxxxset name hahagetset name newhahaget namegetset new_name hahaget new_name
*INCR——递增
将某个key值加一,成功则返回递增后的结果,key不存在时默认由0变成1。注意只能操作可转为数字的字符串,否则就会报错
xxxxxxxxxxset age 10incr ageset name haha# 报错incr nameincr new_keyget new_key
INCRBY——指定步长递增
与incr类似用法,incrby可指定步长,即想加多少都可
xxxxxxxxxxset age 10incrby age 5
INCRBYFLOAT——指定浮点步长递增
与INCRBY类似,只是步长支持浮点数而已。注意没有decrbyfloat命令,不过我们可以设置步长为负数来实现
xxxxxxxxxxset money 10incrbyfloat money 2.5# 报错 没有decrbyfloat命令decrbyfloat money 5.0incrbyfloat money -2.5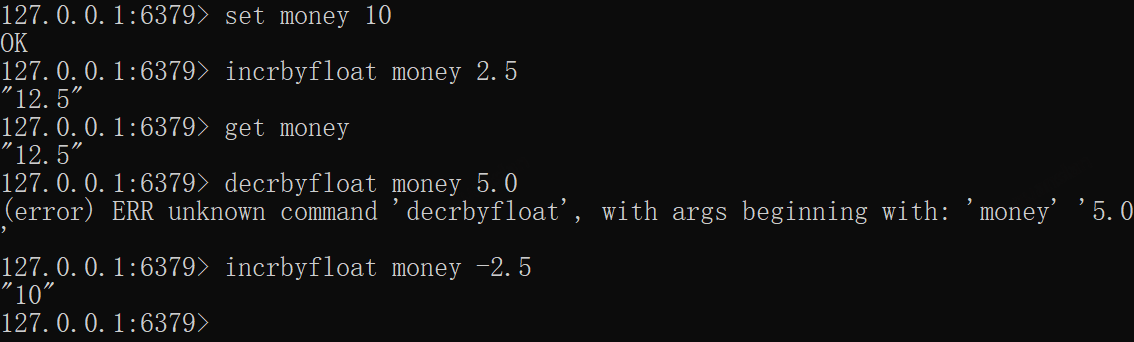
*MGET——获取多个key值
get的变种
xxxxxxxxxxset age 10set age1 100mget age age1 age2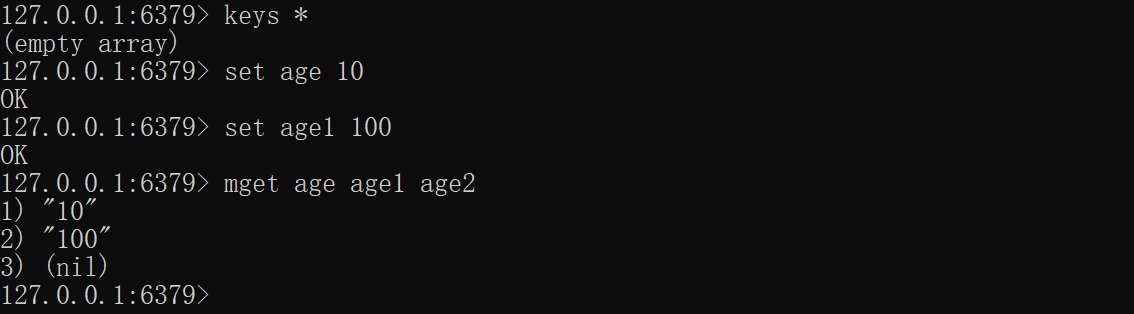
*MSET——设置多个key值
set的变种
xxxxxxxxxxmset age 10 age1 100 age2 50mget age age1 age2
MSETNX——设置多个key值,若该key已存在,则忽略
若已包含某个key,则整条mset命令设置均无效,返回0,设置成功则返回1
xxxxxxxxxxset age 10# 失效msetnx age 100 age1 10# 失效msetnx age1 10 age 100# 成功msetnx age1 10 age2 100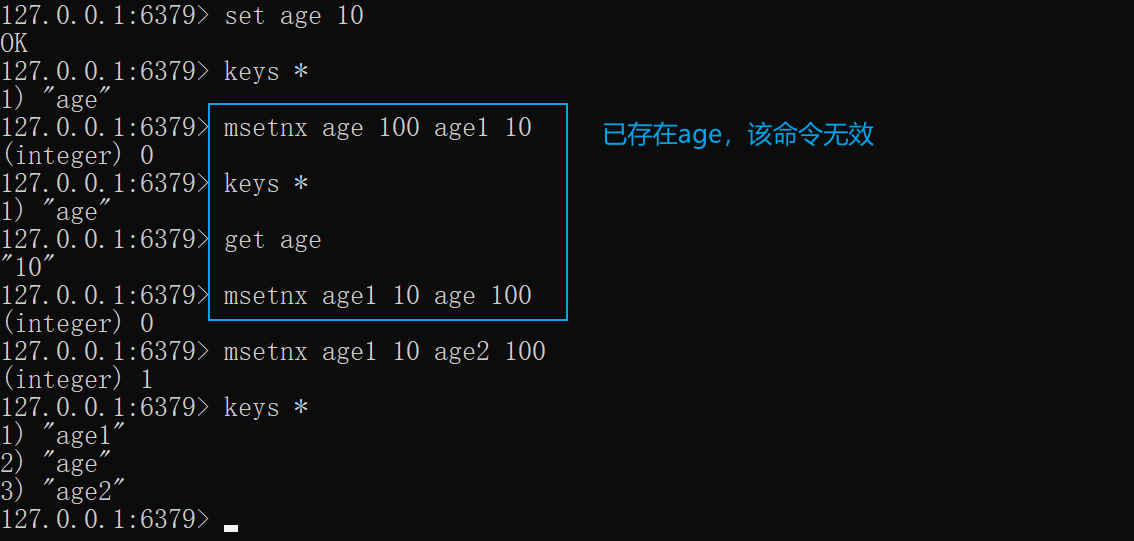
PSETEX——设置key值并指定过期时间ms
与SETEX用法和意思类似,都表示设置key值并指定过期时间,PSETEX的时间单位为ms
PSETEX key milliseconds value
xxxxxxxxxx# 设置age值为10,并在10000ms(10s)后过期psetex age 10000 10
*SET——设置key值
常用命令之一,设置key值,
SET key value [NX | XX] [GET] [EX seconds | PX milliseconds | EXAT unix-time-seconds | PXAT unix-time-milliseconds | KEEPTTL]
- EX seconds:设置指定的过期时间,以秒为单位。
- PX milliseconds :设置指定的过期时间,以毫秒为单位。
- EXAT timestamp-seconds :设置Key到期的指定 Unix 时间(时间戳),以秒为单位。
- PXAT timestamp-milliseconds :设置Key过期的指定 Unix 时间(时间戳),以毫秒为单位。
- NX:仅在密钥不存在时才设置Key。
- XX:仅当Key已存在时才设置它。
- KEEPTTL:保留与Key关联的生存时间。
- GET - 返回存储在 key 中的旧字符串,如果 key 不存在,则返回 nil。如果存储在 key 的值不是字符串,则返回错误并中止 SET
简单字符串可以不用双引号包起来,一长段字符串或者包含空格特殊字符的,必须使用双引号包起来
set的参数项可以替代SETNX、SETEX、PSETEX、GETSET命令,在后续版本中可能会考虑将这些命令移除
xxxxxxxxxxset name ZhangSan# 报错set txt Hello Worldset txt "Hello World"# NXset name LiSi NXget name# EXset age1 20 EX 10ttl age1# GETset name LiSi GETget name
SETEX——设置key值,并指定过期时间s
设置key值并指定过期时间(秒)
SETEX key seconds value
xxxxxxxxxxsetex name 10 hahattl name
SETNX——设置key值,若该key已存在,则忽略
成功返回1,不成功则返回0
xxxxxxxxxxset age 10setnx age 100setnx new_key 100
SETRANGE——修改指定区域
set key offset value
offset为下标,由0开始,value即想要替换的值,只会根据value的长度进行替换,如value长度为2,则只会从offset下标开始替换两个字符
*STRLEN——获取key值的字符串长度
xxxxxxxxxxset name ZhangSanstrlen name
SUBSTR——截取key值
SUBSTR key start end
start、end为下标,由0开始,-1表示倒数第一个,依此类推
xxxxxxxxxxset name ZhangSansubstr name 0 4substr name 5 -1substr name -3 -1
LIST类型常用操作
BLPOP——删除并返回第一个元素,或阻塞直到第一个元素可用
BLPOP key [key ...] timeout
删除并返回最左边的第一个元素,可指定多个key,此时所有key都会阻塞,哪个有值则使用哪个,timeout单位:秒
x
lpush ages 10 20# 仅返回数据blpop no_age ages 10blpop no_age ages 10# 所有元素已经删除完,阻塞超过10s,并返回nil和阻塞时间blpop no_age ages 10# 打开两个窗口,一个窗口执行该命令,然后在另一个窗口往no_age中插入数据,此时该命令返回数据和阻塞时间blpop no_age ages 10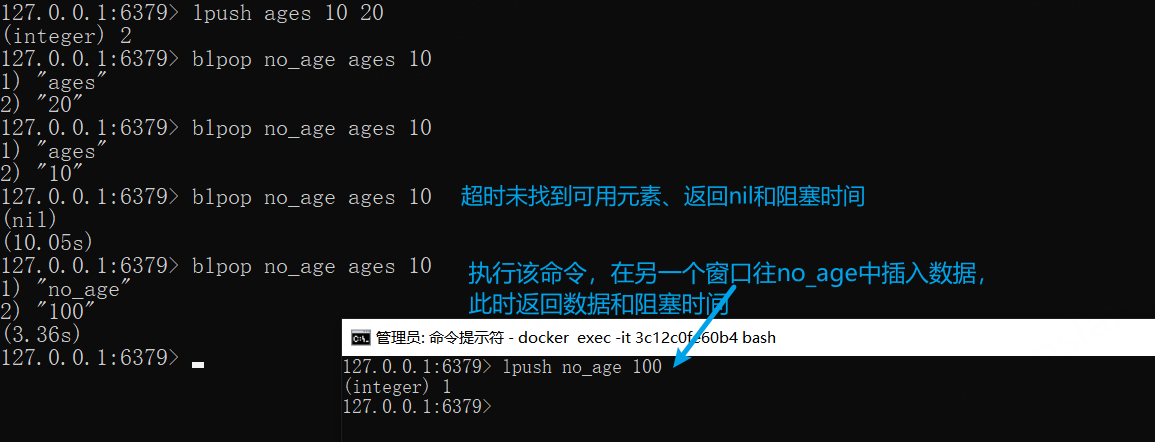
BRPOP——删除并返回最后一个元素,或阻塞直到第一个元素可用
BLPOP key [key ...] timeout
和BLPOP用法类似,不再赘述。删除并返回最右边的最后一个元素,可指定多个key,此时所有key都会阻塞,哪个有值则使用哪个,timeout单位:秒
LINDEX——获取下标
仅支持LIST列表类型,超过下标或key不存在返回nil,下标由0开始,-1表示倒数第一个
xxxxxxxxxxlpush ages 10 20 30lindex ages 0lindex ages -1# nillindex ages 999lindex new_ages 0# 错误set age 10lindex age 0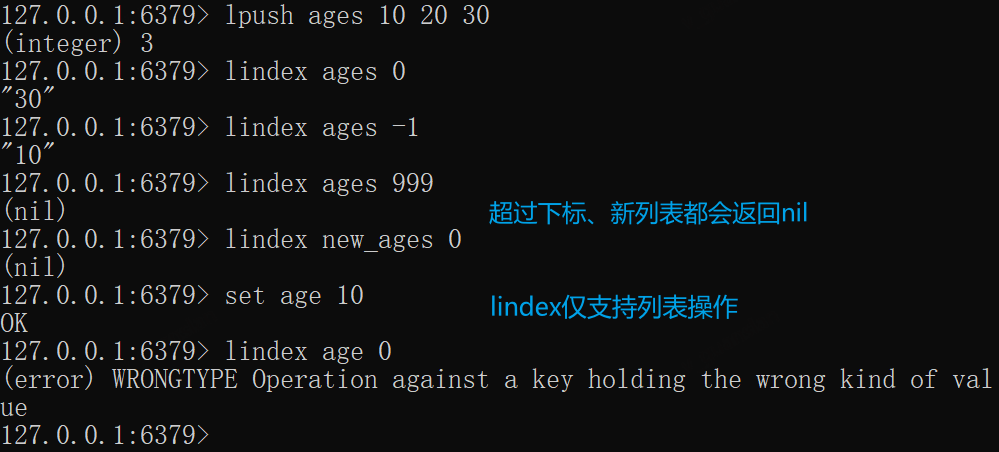
*LINSERT——插入元素
LINSERT key <BEFORE | AFTER> pivot element
根据列表内的某个元素作为参照,将新元素插入到参照元素的前后
成功时返回列表的长度,未找到参照元素则返回-1,未找到key则返回0
xxxxxxxxxxlpush ages 10 20 30# 查看第一个到最后一个元素lrange ages 0 -1# 将新元素25插入到参照元素20之前linsert ages BEFORE 20 25lrange ages 0 -1# 失败linsert ages AFTER 99 100linsert new_ages AFTER 99 100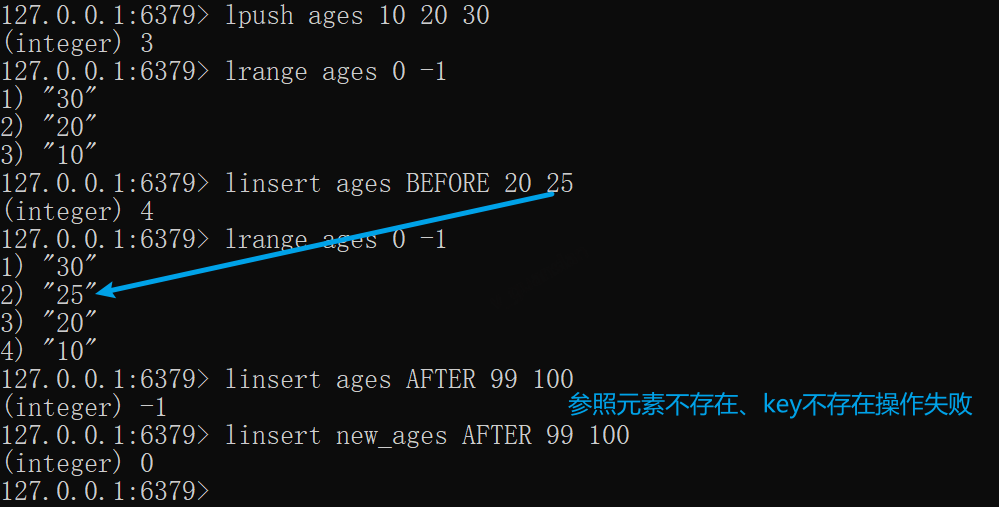
*LLEN——获取列表长度
成功时返回列表的长度,即元素个数,未找到key时返回0,只能操作list列表类型,否则会报错
xxxxxxxxxxlpush ages 10 20 30llen agesllen new_key# 报错set age 10llen age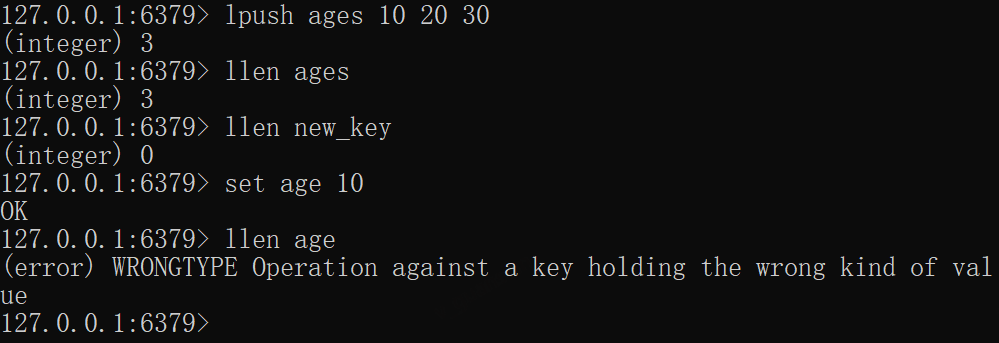
LMOVE——从列表a中移除,将其移动到列表b并返回
LMOVE source destination <LEFT | RIGHT> <LEFT | RIGHT>
这两组LEFT、RIGHT分别表示源列表从哪边开始移除、目标列表从哪边推入数据,支持源列表内操作
成功时返回源列表移除的元素,源列表不存在时返回nil,目标列表不存在时正常执行,自动生成目标列表,RPOPLPUSH已弃用,使用LMOVE RIGHT LEFT可替代
xxxxxxxxxxlpush ages 10 20 30lpush dest_ages 50 60 70lrange ages 0 -1lrange dest_ages 0 -1# 将ages的第一个元素移动到dest_ages的最后一个元素lmove ages dest_ages LEFT RIGHTlrange ages 0 -1lrange dest_ages 0 -1# 将ages的第一个元素移动到最后一个元素lmove ages ages LEFT RIGHT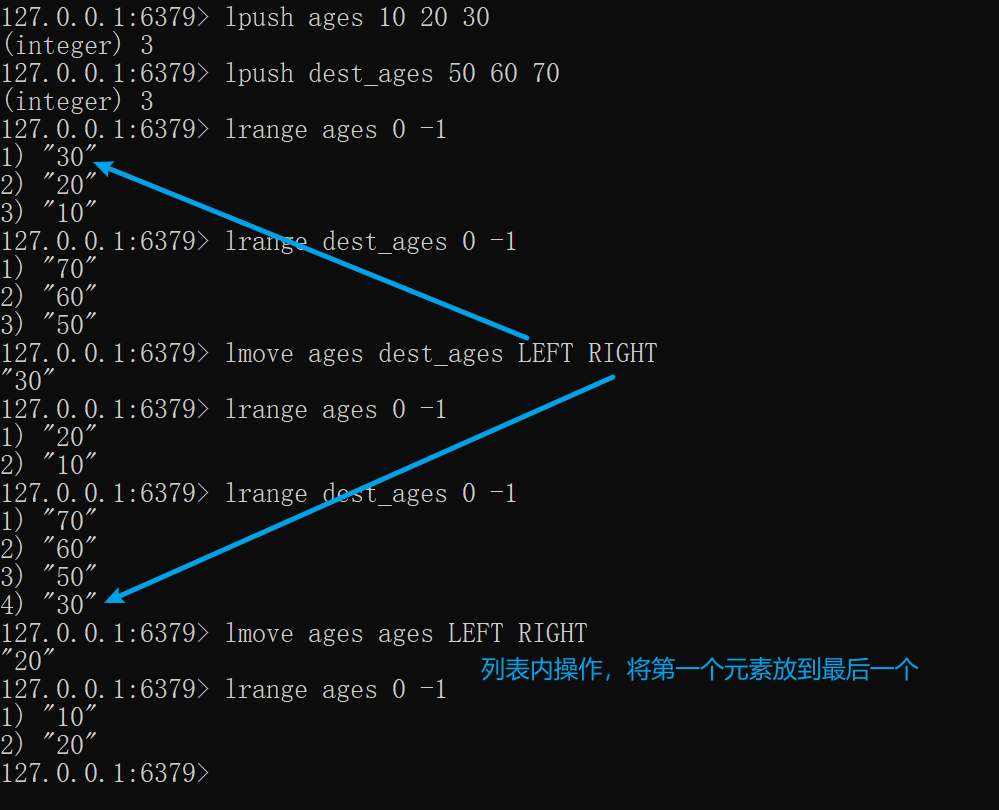
LMPOP——弹出一个或多个元素
LPOP的变种,从一个或多个列表中弹出元素,成功时返回当前操作的key和弹出的元素
LMPOP numkeys key [key ...] <LEFT | RIGHT> [COUNT count]
numkeys:需要查找的key的个数,这里填多少后面就跟多少个key,不然就报错了
xxxxxxxxxxlpush ages 10 20 30lpush ages_1 50 60 70lrange ages_1 0 -1# 从ages_1的右边弹出元素lmpop 1 ages_1 RIGHTlrange ages 0 -1lrange ages_1 0 -1# 从ages,ages_1的左边弹出2个元素,先弹出第一个列表完事后继续第二个列表lmpop 2 ages ages_1 LEFT COUNT 2lmpop 2 ages ages_1 LEFT COUNT 2lmpop 2 ages ages_1 LEFT COUNT 2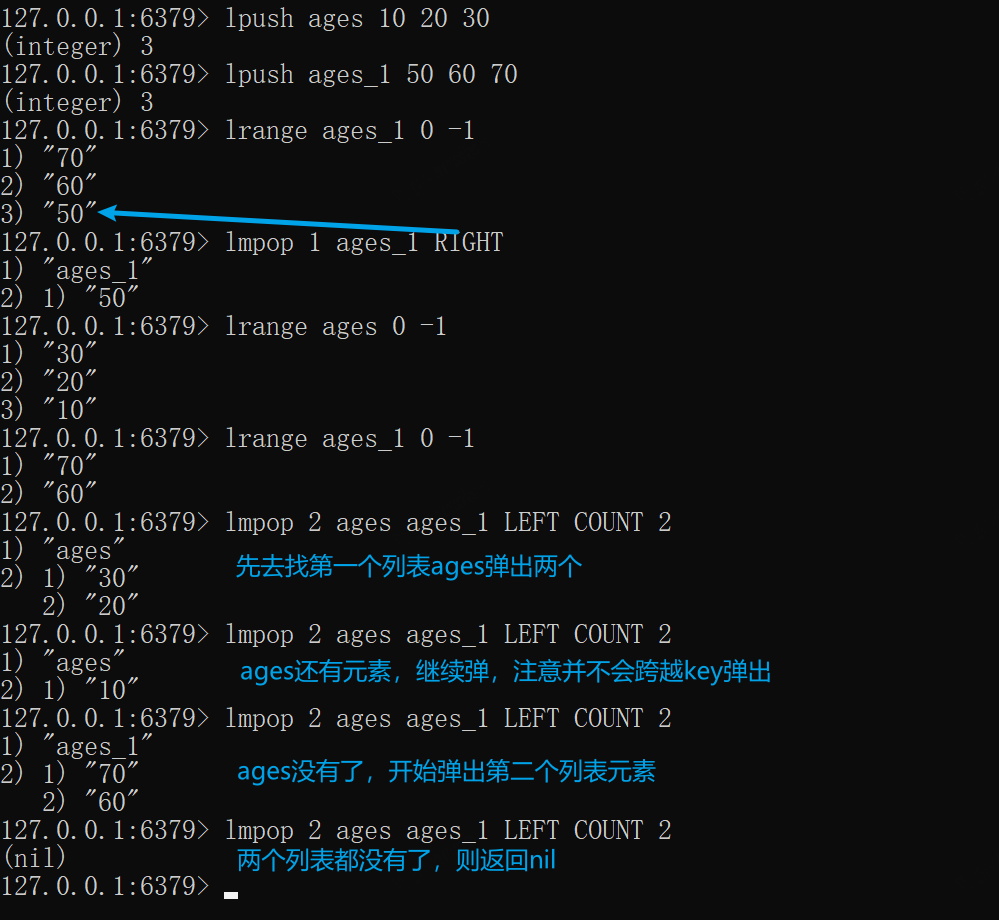
*LPOP——从左边弹出并返回元素
从列表的开头(左边)弹出元素,可指定数量,成功时返回弹出的元素(列表),没有元素、key不存在则返回nil
lpush ages 10 20 30lrange ages 0 -1lpop ageslpop ages 5# nillpop new_keylpop new_key 5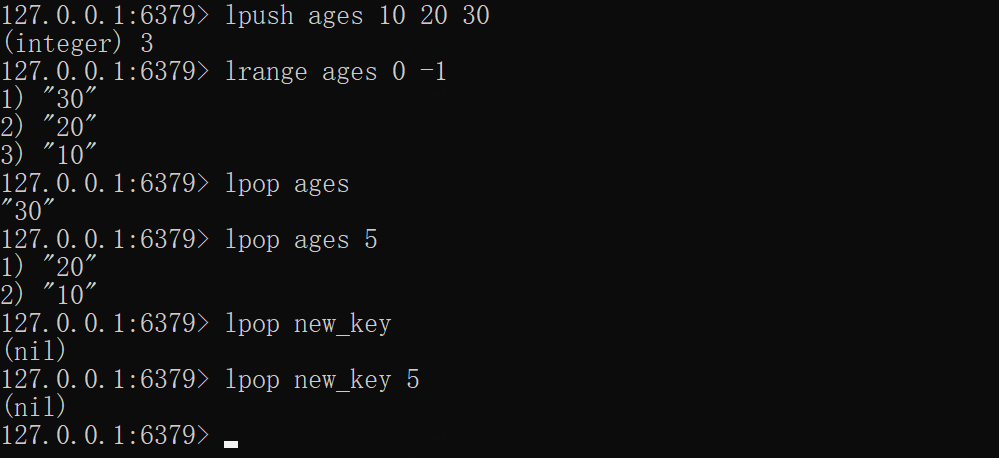
LPOS——返回匹配元素的下标
从头到尾开始扫描,寻找指定元素,并返回索引,若不存在则返回nil
LPOS key element [RANK rank] [COUNT num-matches] [MAXLEN len]
- RANK:表示查找第几个元素的下标,-1表示从尾部到头部开始查找
- COUNT :表示查找几个元素的下标,够个数即停止并返回数组,COUNT 0表示全部查找
- MAXLEN:比较次数,只查找一部分,够次数即停止并返回,MAXLEN 0表示全部比较
x
lpush ages 10 20 30 40 20 10 50 20 30 40# 扫描第一个匹配项lpos ages 10# 扫描第二个匹配项lpos ages 20 RANK 2# 倒着扫描,查找2个匹配项便停止lpos ages 20 RANK -1 COUNT 2lrange ages 0 -1# 倒着扫描第一个匹配项lpos ages 20 RANK -1# 倒着扫描全部匹配项lpos ages 20 RANK -1 COUNT 0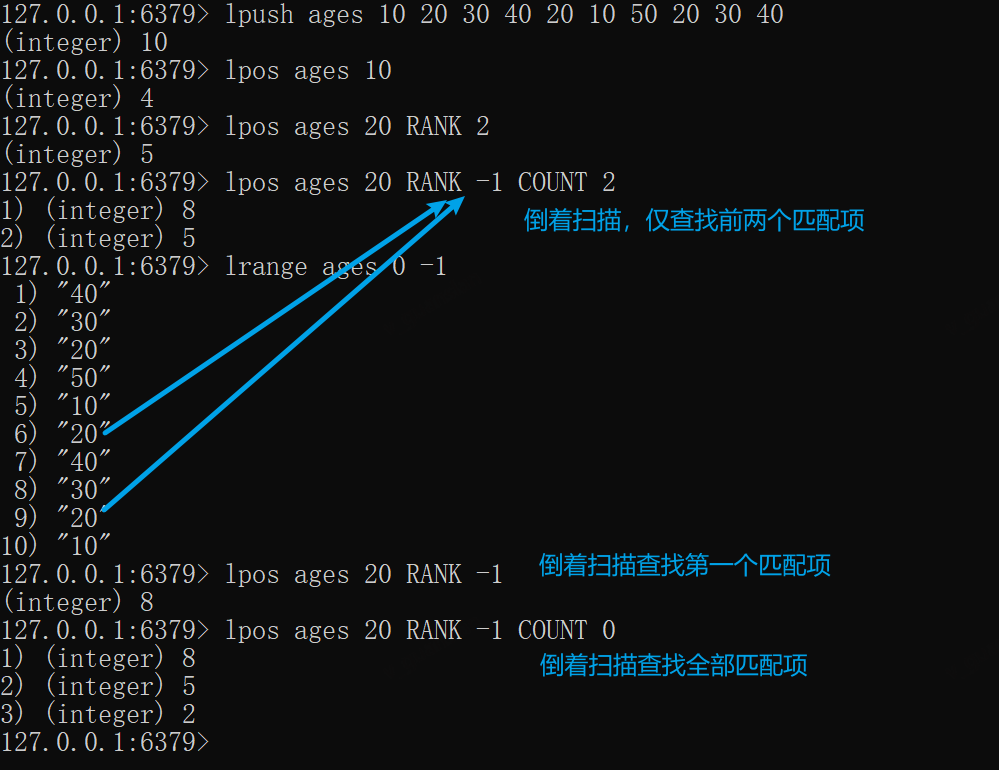
xxxxxxxxxx# 查找匹配项,仅查找1次lpos ages 20 MAXLEN 1lpos ages 20 MAXLEN 5# 查找所有匹配项,仅查找5次lpos ages 20 COUNT 0 MAXLEN 5# 查找所有匹配项lpos ages 20 COUNT 0 MAXLEN 0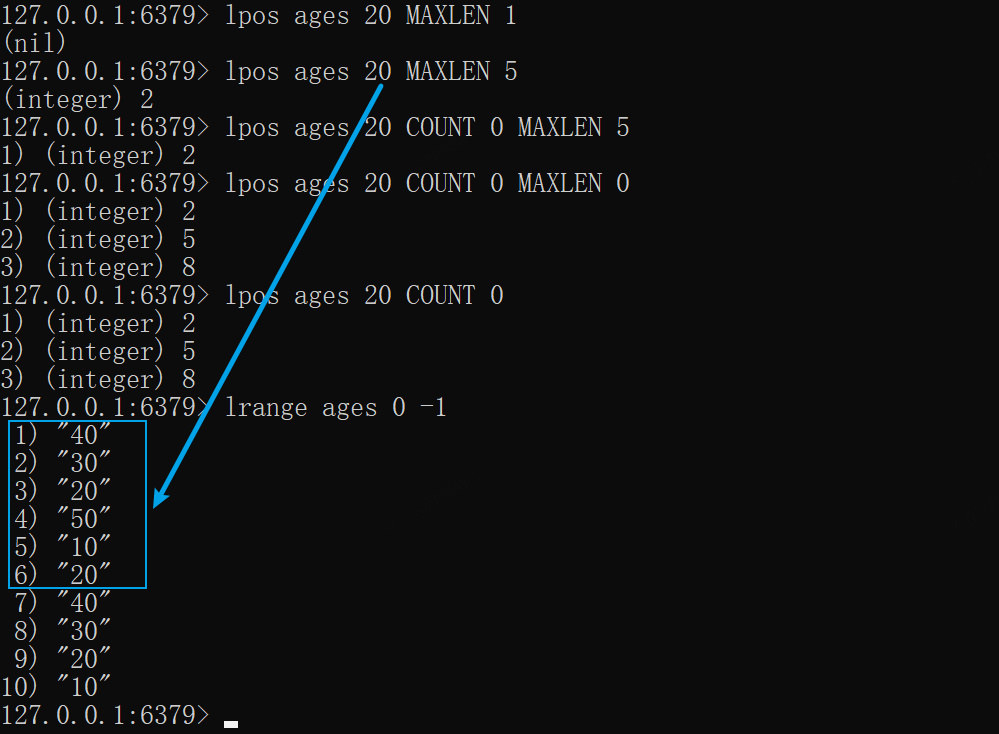
*LPUSH——从左边将元素推入列表
从左边将元素推入列表中,先进后出,最后推入的元素变成列表第一个元素,成功则返回列表长度。顺序有点反常,建议使用RPUSH,看的直观点
xxxxxxxxxxlpush ages 10 20 30lrange ages 0 -1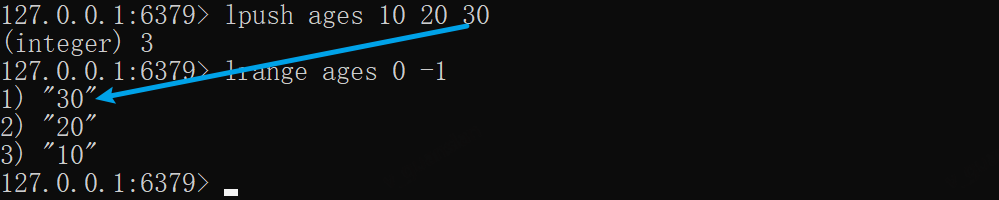
LPUSHX——当集合存在时,从左边将元素推入列表
与LPUSH的用法和意思类似,LPUSHX仅当key存在时推入成功返回列表长度,若不存在不做任何操作则返回0
xxxxxxxxxxlpush ages 10 20 30lpushx ages 20 30# new_key不存在,操作不成功lpushx new_key 20 30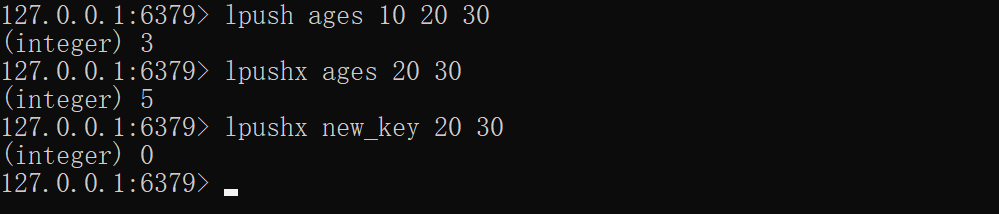
*LRANGE——获取指定区间数据
LRANGE key start stop
start、stop为元素下标,由0开始,-1表示倒数第一个,依此类推
xxxxxxxxxxlpush ages 10 20 30lrange ages 0 1lrange ages 0 -1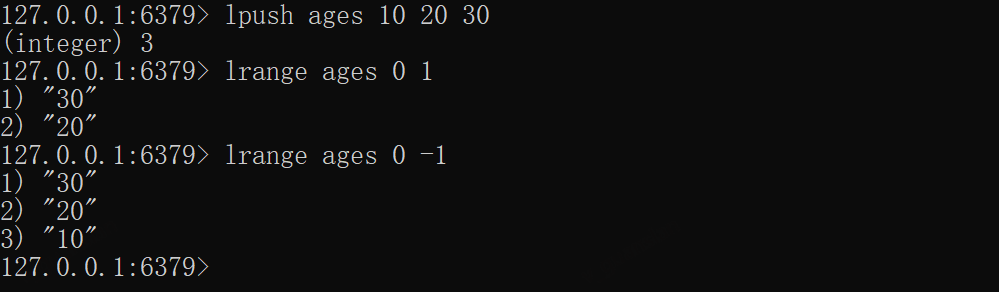
*LREM——移除元素
LREM key count element
count:表示从头到尾几个元素,负数则表示从尾到头几个元素,为0时则表示全部移除匹配元素
成功时返回删掉的元素个数,未成功、key不存在则返回0
xxxxxxxxxxrpush ages 10 20 30 40 50 20 30 20# 从头到尾扫描,删除2个为20的元素lrem ages 2 20lrange ages 0 -1del ages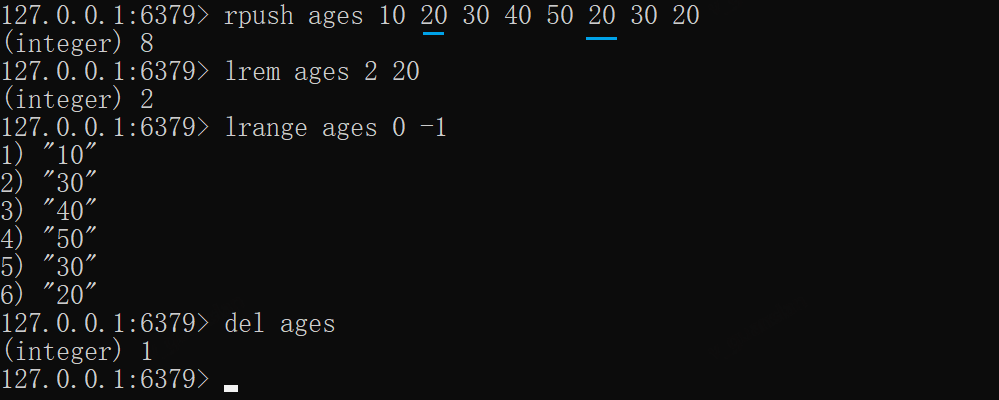
rpush ages 10 20 30 40 50 20 30 20# 从尾到头扫描,删除2个为20的元素lrem ages -2 20lrange ages 0 -1del ages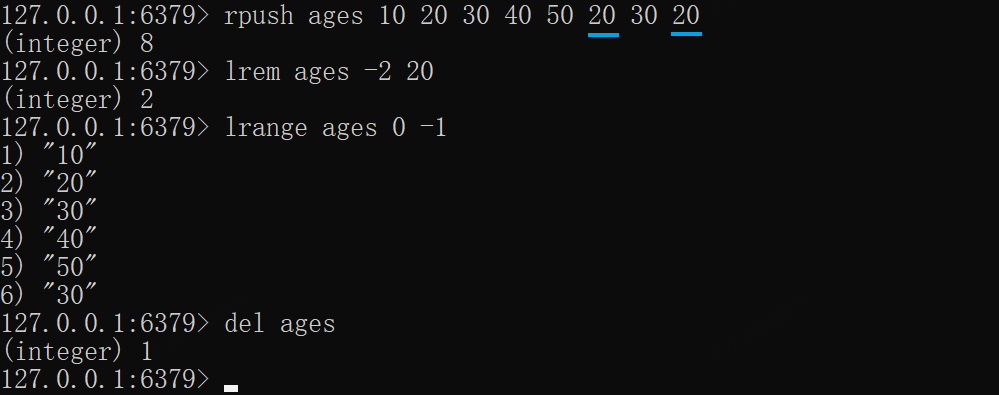
lrange ages 0 -1rpush ages 10 20 30 40 50 20 30 20# 从头到尾扫描,删除所有为20的元素lrem ages 0 20lrange ages 0 -1# 0lrem ages 0 20lrem new_key 0 20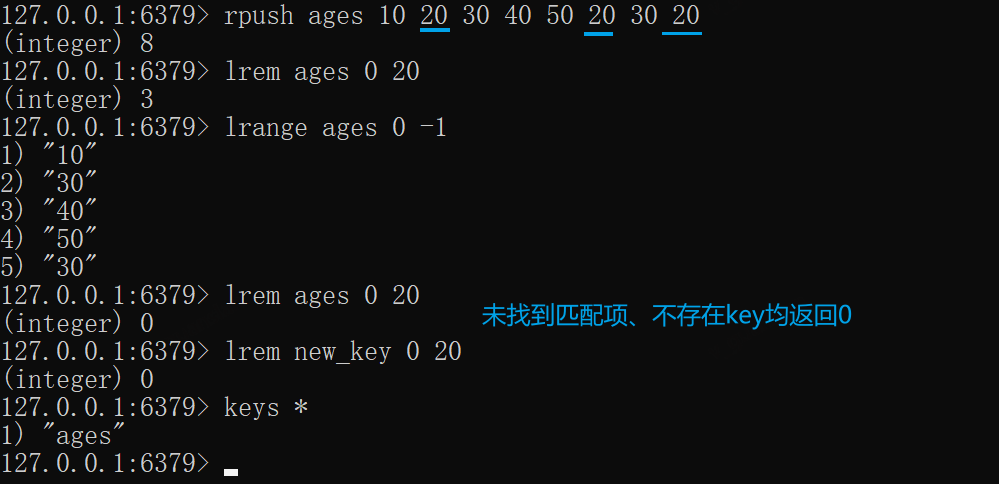
*LSET——通过下标设置值
LSET key index element
index 为列表下标,由0开始,-1表倒数第一个元素,依此类推
xxxxxxxxxxrpush ages 10 20 30lset ages 0 100lset ages -1 300lrange ages 0 -1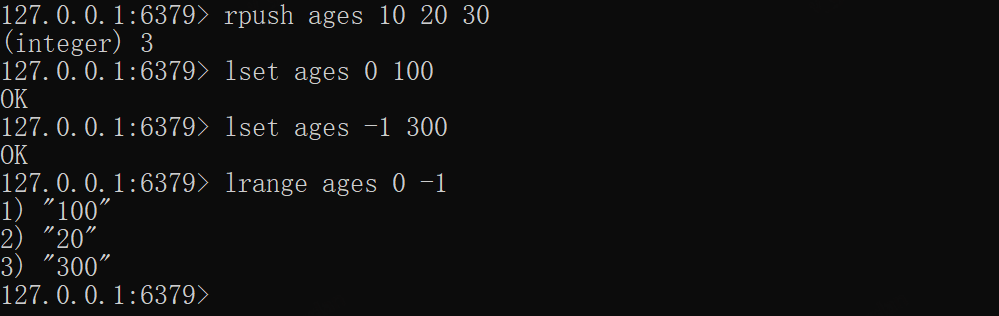
LTRIM——截取并保留指定区间数据
LTRIM key start stop
start、stop为元素下标,由0开始,-1表示倒数第一个,依此类推。注意没有RTRIM
xxxxxxxxxxrpush ages 10 20 30 40 50# 截取掉倒数第一个元素ltrim ages 0 -2lrange ages 0 -1
*RPOP——从右边弹出并返回元素
从列表的结尾(右边)弹出元素,可指定数量,成功时返回弹出的元素(列表),没有元素、key不存在则返回nil
xxxxxxxxxxrpush ages 10 20 30# 从右边弹出2个元素rpop ages 2rpop agesrpop new_key
*RPUSH——从右边将元素推入列表
从列表的结尾(右边)将元素推入列表中,先进先出,最后推入的元素变成列表倒数第一个元素,成功则返回列表长度
xxxxxxxxxxrpush ages 10 20 30lrange ages 0 -1
*RPUSHX——当集合存在时,从右边将元素推入列表
与RPUSH的用法和意思类似,RPUSHX仅当key存在时推入成功返回列表长度,若不存在不做任何操作则返回0
rpush ages 10 20 30rpushx ages 40rpushx new_key 40keys *
SET无序集合操作
*SADD——添加成员
集合内不允许重复成员,如果重复添加,会自动忽略返回0,成功时返回添加的成员个数
x
sadd myset 10 20 50 20 30sadd myset 90# 查看成员smembers myset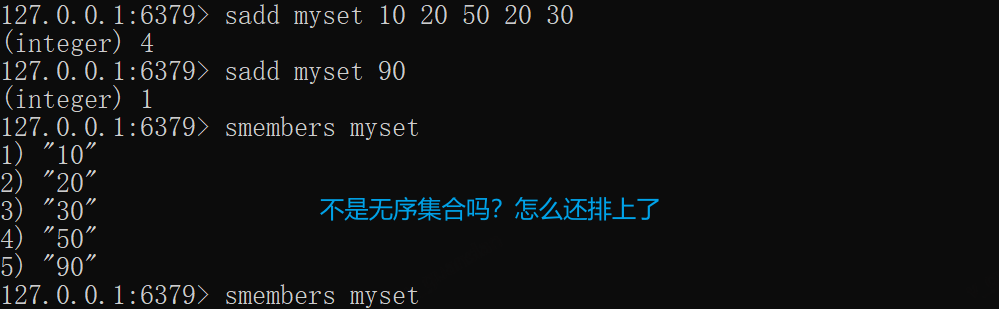
*SCARD——返回集合长度
xxxxxxxxxxsadd myset 10 20 50 20 30scard myset
*SDIFF——获取差集
成功时返回差集数据,若某个key不存在,则将视为空集合,返回相对差集
xxxxxxxxxxsadd myset 10 20 50 20 30sadd yourset 20 30 70# 查找myset相对于yourset的差集sdiff myset yourset# 查找 yourset 相对于 myset 的差集sdiff yourset myset# new_key不存在,差集为yourset本身sdiff yourset new_key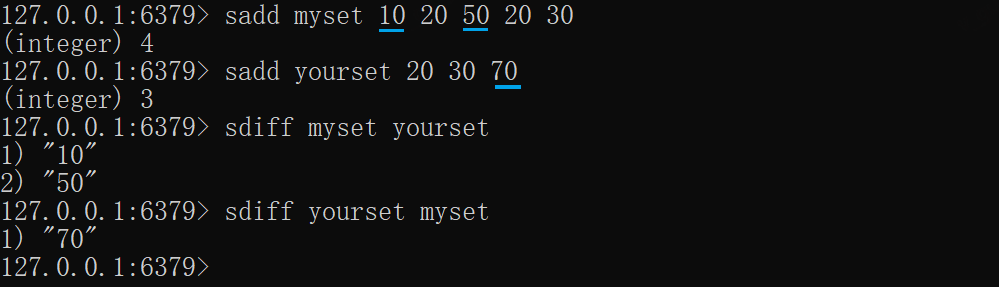
SDIFFSTORE——获取差集并存储新key中
成功时返回差集个数,若某个key不存在,则将视为空集合,返回相对差集的个数
xxxxxxxxxxsadd myset 10 20 50 20 30sadd yourset 20 30 70# 查找myset相对于yourset的差集,并将结果存入set_1sdiffstore set_1 myset yoursetsdiffstore set_2 yourset mysetsmembers set_1smembers set_2del myset yourset set_1 set_2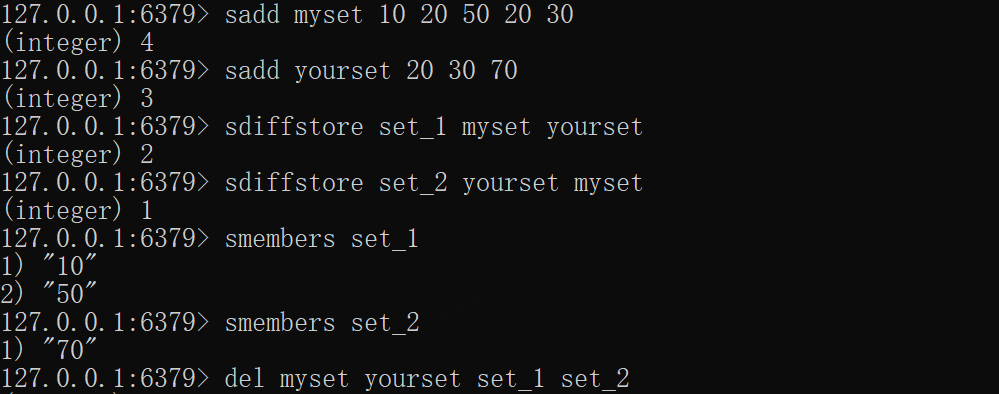
*SINTER——获取交集
成功时返回差集数据,若某个key不存在,则将视为空集合,返回空集合
xxxxxxxxxxsadd myset 10 20 50 20 30sadd yourset 20 30 70# 查找myset与yourset的交集sinter myset yourset# new_key不存在,交集为空集合sinter myset new_key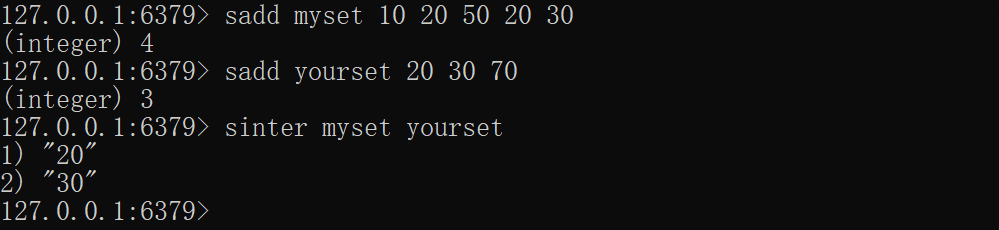
SINTERCARD——获取交集并返回结果基数
SINTERCARD numkeys key [key ...] [LIMIT limit]
查找交集结果的个数,并不会返回交集数据,numkeys 即提供key的个数,有多少填多少,LIMIT即限定个数,LIMIT 0意为全部
xxxxxxxxxxsadd myset 10 20 50 20 30sadd yourset 20 30 70sintercard 2 myset yoursetsintercard 2 myset yourset LIMIT 1
SINTERSTORE——获取交集并存储新key中
xxxxxxxxxxsadd myset 10 20 50 20 30sadd yourset 20 30 70# 查找myset yourset的交集数据并存储set_1sinterstore set_1 myset yoursetsmembers set_1del myset yourset set_1
*SISMEMBER——判断成员是否在集合中
判断集合是否包含某成员,存在则返回1,不存在、key不存在则返回0
xxxxxxxxxxsadd myset 10 20 50 20 30sismember myset 20sismember myset 50# 不存在则返回0sismember myset 99sismember new_key 99
*SMEMBERS——获取全部成员
xxxxxxxxxxsadd myset 10 20 50 20 30smembers myset
SMISMEMBER——获取成员与集合的关系
若集合包含该成员,则返回1,不包含或key不存在则返回0,可一次判断多个成员
xxxxxxxxxxsadd myset 10 20 50 20 30smembers myset#存在返回1smismember myset 10smismember myset 50# 不存在则返回0smismember myset 99smismember new_key 99
SMOVE——移动成员到另一集合
SMOVE source destination member
将源集合的成员移动到目标集合,成功则返回1,若目标集合存在该成员,会将源集合的成员移除,并返回1,若源集合不存在该成员、源集合不存在则无任何操作返回0
xxxxxxxxxxsadd myset 10 20 50 20 30# 将成员20从myset移动到new_keysmove myset new_key 20smembers mysetsmembers new_key# new_key添加成员50sadd new_key 50# 将成员50从myset移动到new_keysmove myset new_key 50smembers new_keysmembers myset# 无任何操作smove myset new_key 99smove myset_1 new_key 99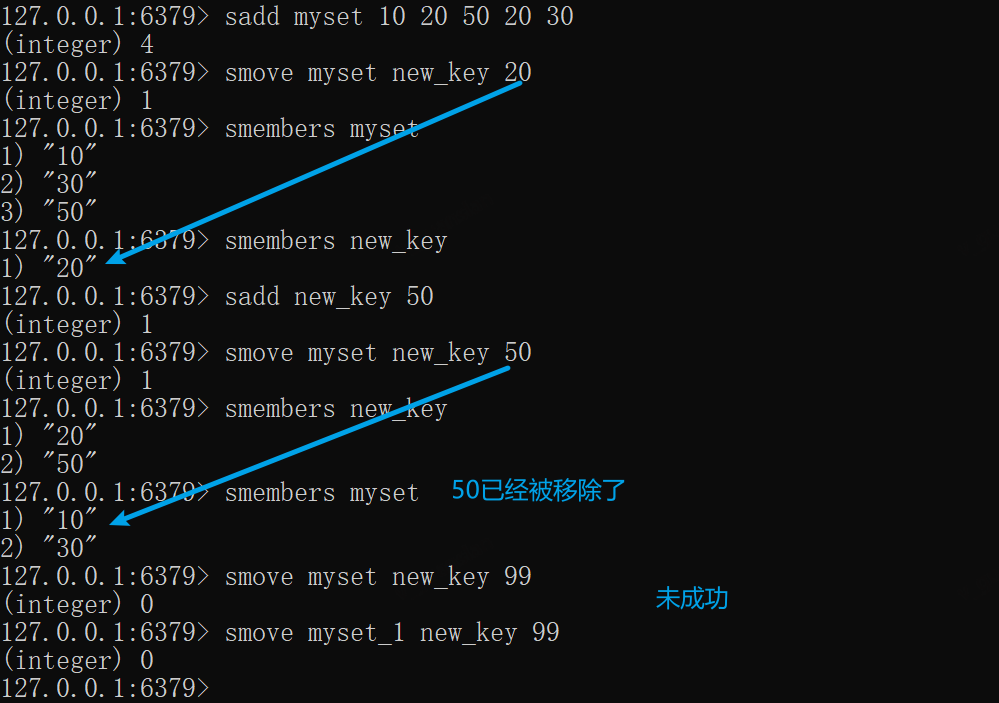
*SPOP——弹出成员并返回
弹出成员并返回(没有顺序),可指定count,成功时返回成员(列表),无成员、不存在key则返回nil或者空集合
xxxxxxxxxxsadd myset 10 20 50spop myset 2spop myset
SRANDMEMBER——随机获取成员
xxxxxxxxxxsadd myset 10 20 50srandmember mysetsrandmember myset 2
*SREM——移除成员
移除指定成员,若成员不存在则忽略,成功时返回移除的个数,key不存在则视为空集合返回0
xxxxxxxxxxsadd myset 10 20 50srem myset 10 20 30srem new_key 10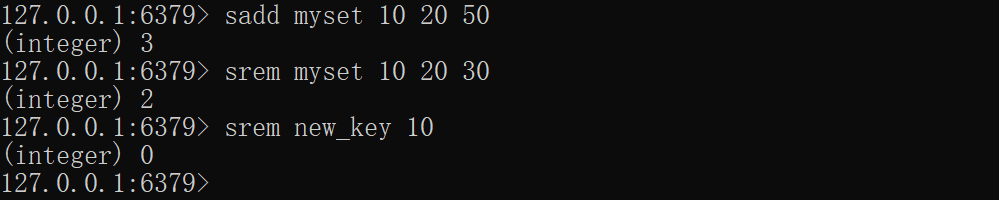
SSCAN——增量迭代成员
和scan用法类似,当key值(集合)很大时,不建议smembers来查看key值,可以使用对应的sscan指令查看,sscan支持正则、指定数量(不准确),使用语法如下:
SSCAN key cursor [MATCH pattern] [COUNT count]
每次请求都会返回数据和游标,游标供下次查询,默认0为开始游标,若返回的游标是0则说明已经迭代完数据
xxxxxxxxxxsadd myset 10 20 50 30 40 60 90 80 70 100 101 102 103 105sscan myset 0 MATCH 10* COUNT 2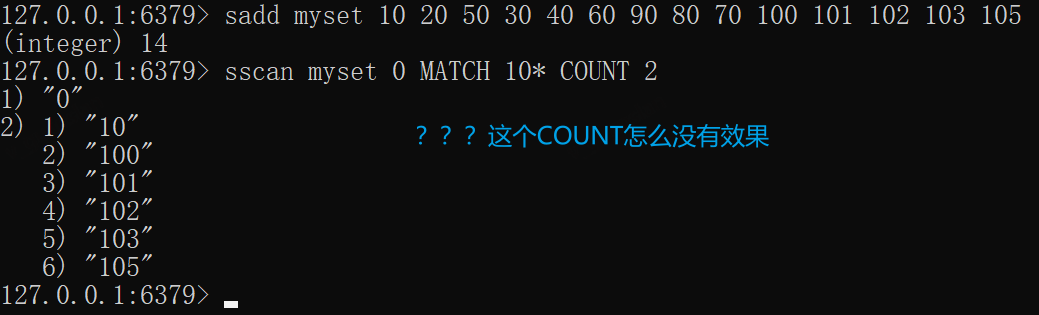
*SUNION——获取并集
xxxxxxxxxxsadd myset 10 20 50 20 30sadd yourset 20 30 70# 获取myset和yourset的并集sunion myset yourset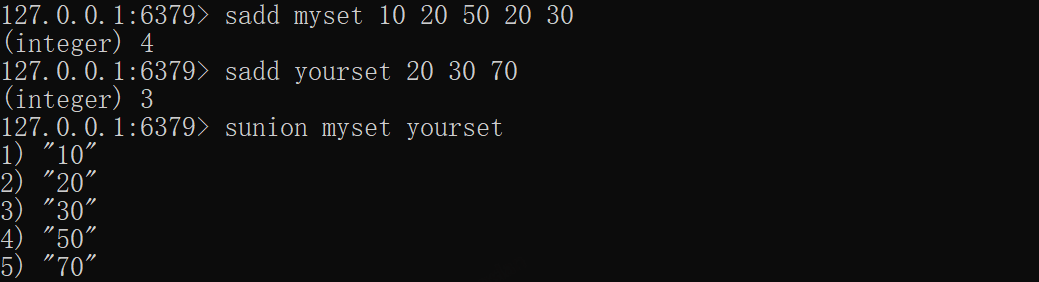
SUNIONSTORE——获取并集并存储新key中
xxxxxxxxxxsadd myset 10 20 50 20 30sadd yourset 20 30 70# 获取myset和yourset的并集并存入集合set_1sunionstore set_1 myset yoursetsmembers set_1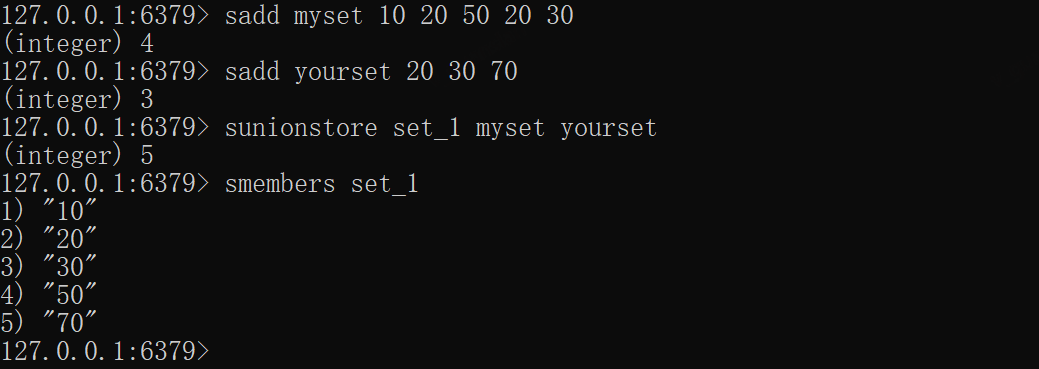
ZSET(Sorted Set)有序集合常用操作
BZMPOP——删除并返回成员与分数,或阻塞直到第一个元素可用
BZMPOP timeout numkeys key [key ...] <MIN | MAX> [COUNT count]
删除并返回成员与分数,timeout 为超时时间单位:秒,numkeys 为比较集合的个数,有多少写多少,MIN、MAX删除标准,最低分还是最高分,COUNT指定个数
x
zadd myzset 1 one 2 two 3 threezadd myzset1 1 one 3 two 5 threeBZMPOP 10 2 myzset myzset1 MIN COUNT 2#看下图...
BZPOPMAX——删除并返回最高分数的成员,或阻塞直到第一个元素可用
BZPOPMAX key [key ...] timeout
用法类似 BZMPOP...MAX,不再赘述
BZPOPMIN——删除并返回最低分数的成员,或阻塞直到第一个元素可用
BZPOPMAX key [key ...] timeout
用法类似 BZMPOP...MIN,不再赘述
*ZADD——添加成员更新分数
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member...]
- XX:只更新已经存在的成员。新成员则忽略。
- NX:只添加新成员。已存在则忽略。
- LT:新成员直接添加,已存在成员当新分数低于当前分数时才会更新
- GT:新成员直接添加,已存在成员当新分数大于当前分数时才会更新
- CH:返回已更改(添加更新)的数量。注意:通常 ZADD 的返回值只计算添加的新成员的数量。
- INCR:指定此选项时,ZADD 的作用类似于 ZINCRBY。在此模式下只能指定一个分数成员对。
- GT、LT、NX参数互斥,只能指定其中一个
有序集合按其分数升序排序。同一个元素只存在一次,不允许有重复的成员。允许存在相同分数,若分数相同则按字典(什么字典?)顺序排序
成功时返回添加的成员数量,若指定CH则返回已更改((添加更新))的数量
x
zadd myzset 1 one 2 two 3 three# 修改two为22,添加four为4,执行XX参数,忽略未存在的成员fourzadd myzset XX CH 22 two 4 fourzadd myzset NX CH 5 five 33 threezrange myzset 0 -1 WITHSCORES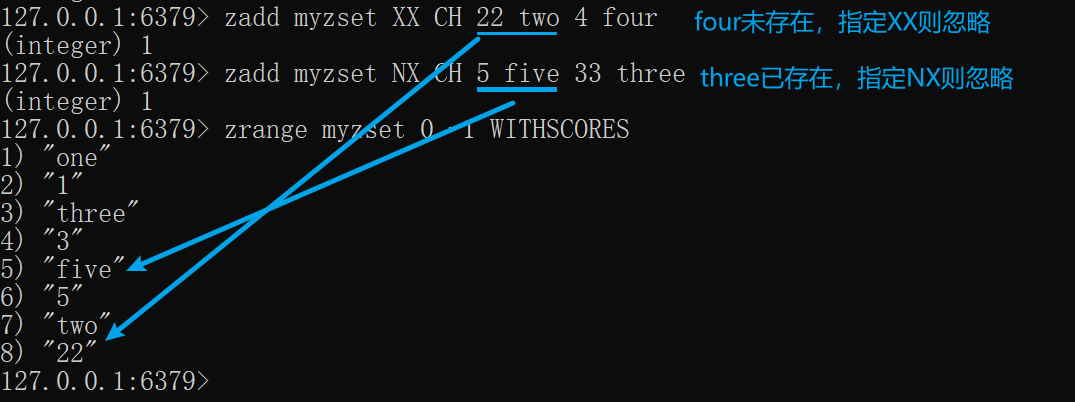
GT参数只会添加新成员、更新新分数大于当前分数的成员,LT与之相反
xxxxxxxxxxzadd myzset 1 one 2 two 3 threezadd myzset GT CH 0 one 22 two 4 fourzrange myzset 0 -1 WITHSCORES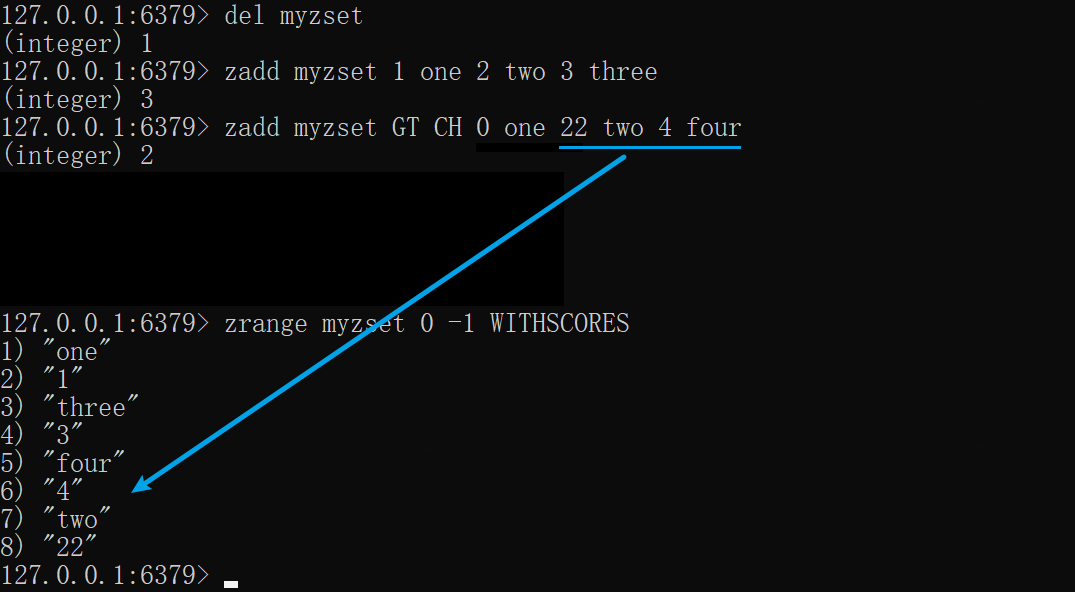
*ZCARD——返回集合长度
xxxxxxxxxxzadd myzset 1 one 2 two 3 threezcard myzset
*ZCOUNT——查看某个分数区间的集合长度
ZCOUNT key min max
min、max表示最低最高分数,默认闭区间,开区间在分数前加上(即可
xxxxxxxxxxzadd myzset 1 one 2 two 3 threezcount myzset 1 2# 开区间zcount myzset 1 (2# 应该是inf最大数吧 类似zcard myzsetzcount myzset -inf inf
*ZDIFF——获取差集
ZDIFF numkeys key [key ...] [WITHSCORES]
获取集合之间的差集,只比较成员,与分数无关,numkeys 为比较集合的个数,有多少写多少
zadd myzset 1 one 2 two 3 threezadd yourzset 1 one 22 two 4 fourzdiff 2 myzset yourzset# 获取myzset相对于yourzset的差集,并显示分数zdiff 2 myzset yourzset WITHSCORESzdiff 2 yourzset myzset WITHSCORES
ZDIFFSTORE——获取差集并存储新key中
ZDIFFSTORE destination numkeys key [key ...]
与ZDIFF意思一样,获取集合之间的差集并存储新集合中,只比较成员,与分数无关,numkeys 为比较集合的个数,有多少写多少
xxxxxxxxxxzadd myzset 1 one 2 two 3 threezadd yourzset 1 one 22 two 4 fourzdiffstore zset_1 2 myzset yourzsetzrange zset_1 0 -1 WITHSCORES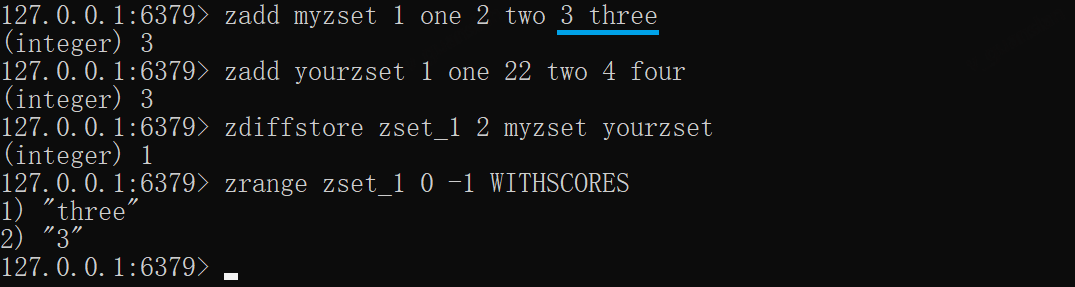
*ZINTER——获取差集
ZINTER numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>] [WITHSCORES]
获取集合之间的交集,只比较成员,分数可以通过AGGREGATE 参数指定,默认相加取总和,numkeys 为比较集合的个数,有多少写多少
- AGGREGATE :指定交集的分数如何处理,默认相加取总和,Min取最小的分数、Max取最大的分数
- WEIGHTS:乘法因子,默认1,在执行AGGREGATE 之前都会将各自分数乘以这个乘法分子,注意有多少个key就要写多少次,一一对应
x
del myzset yourzset zset_1zadd myzset 1 one 2 two 3 threezadd yourzset 1 one 22 two 4 four# 取交集数据,并将myzset和yourzset的成员分数相加,作为交集数据的分数zinter 2 myzset yourzset WITHSCORES# 取交集数据,并将myzset的成员分数乘以3,将yourzset的成员分数乘以2,再比较大小取最大值分数zinter 2 myzset yourzset WEIGHTS 3 2 AGGREGATE MAX WITHSCORES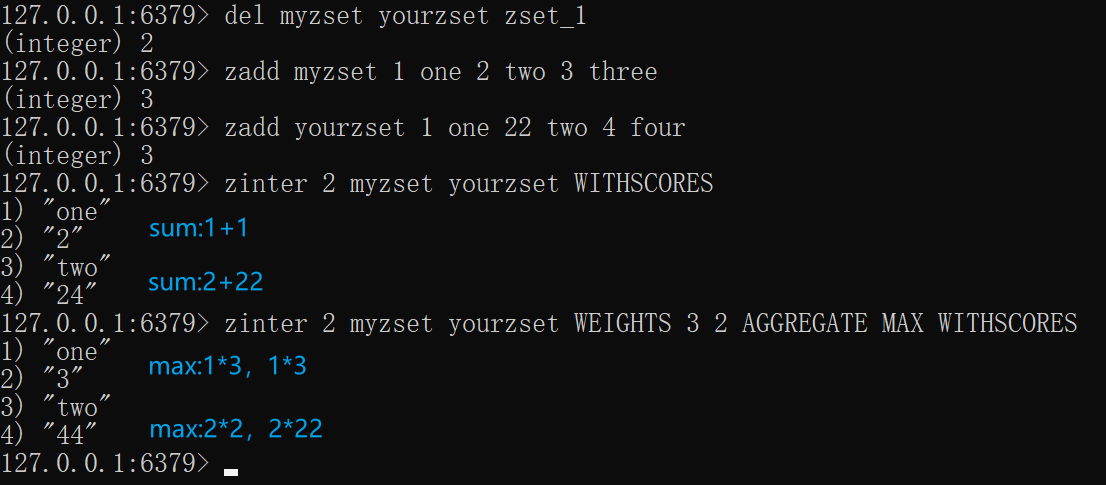
ZINTERSTORE——获取差集并存储新key中
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>]
获取集合之间的交集并存储新集合中,只比较成员,相关参数可查看ZINTER
xxxxxxxxxxdel myzset yourzset zset_1 zset_2zadd myzset 1 one 2 two 3 threezadd yourzset 1 one 22 two 4 fourzinterstore zset_1 2 myzset yourzsetzinterstore zset_2 2 myzset yourzset WEIGHTS 3 2 AGGREGATE MAX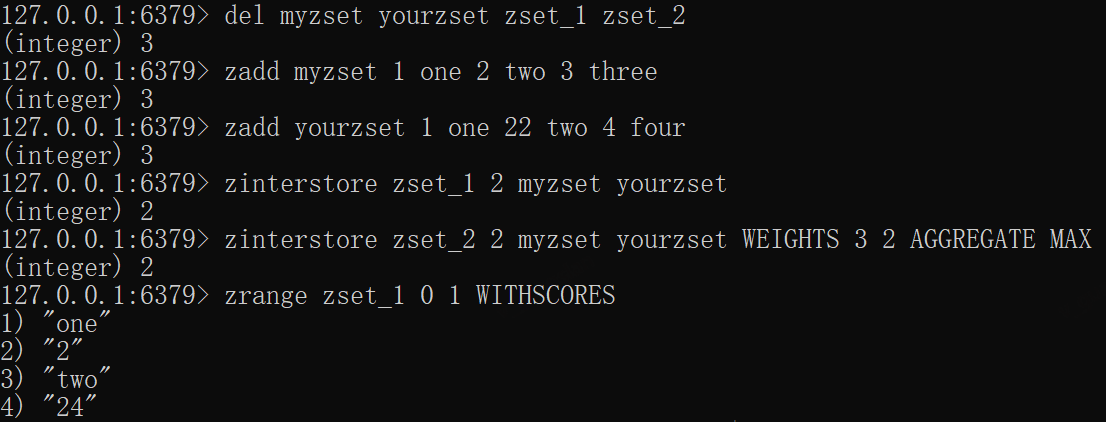
ZINTERCARD——获取差集,并返回结果基数
ZINTERCARD numkeys key [key ...] [LIMIT limit]
获取差集个数,numkeys 为比较集合的个数,有多少写多少,LIMIT仅查看多少个交集,默认为0查看全部
xxxxxxxxxxzadd myzset 1 one 2 two 3 threezadd yourzset 1 one 22 two 4 fourzintercard 2 myzset yourzsetzintercard 2 myzset yourzset LIMIT 1
*ZINCRBY——递增某成员的分数
ZINCRBY key increment member
根据步长(increment )递增某成员的分数,成功时返回递增后分数,key不存在则视为空集合,成员不存在则视为新成员均可执行成功
x
zadd myzset 1 one 2 two 3 three# 2+10zincrby myzset 10 two# four不存在,直接添加zincrby myzset 10 four# 3-3zincrby myzset -3 threezrange myzset 0 -1 WITHSCORES# myzset_1不存在此key,直接生成新集合新成员zincrby myzset_1 -3 three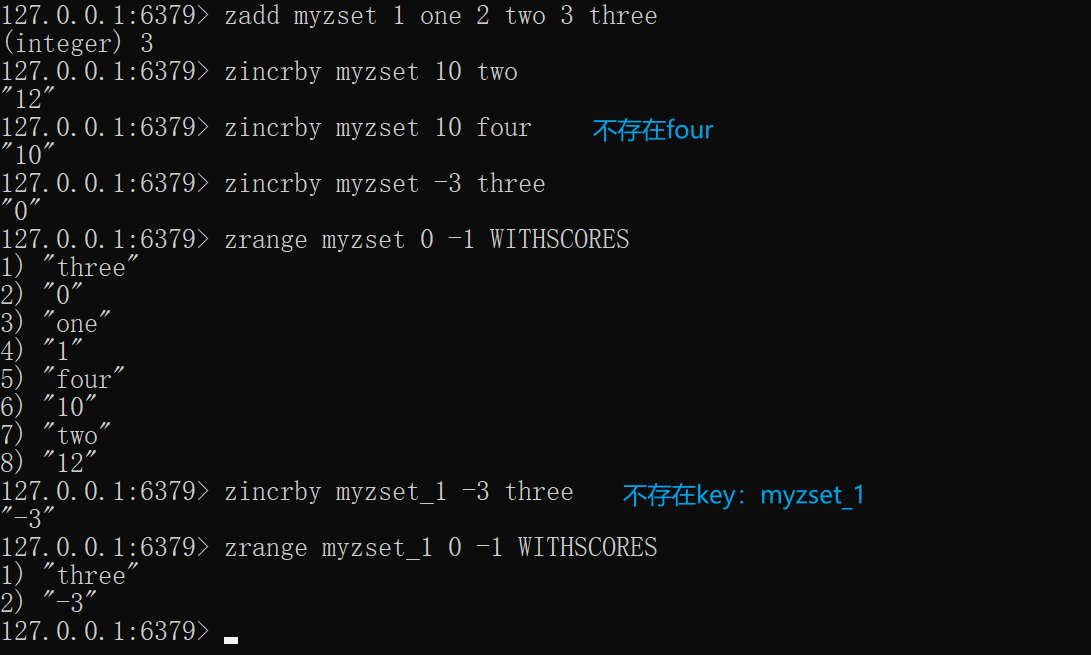
ZLEXCOUNT——获取指定成员区间的数量
ZLEXCOUNT key min max
min、max表示最低最高成员,必须在成员前加上[表示闭区间,开区间在成员前加上(即可
x
zadd myzset 0 a 0 b 0 c 0 d 0 e 1 fzlexcount myzset [c [fzlexcount myzset [c (fzlexcount myzset - +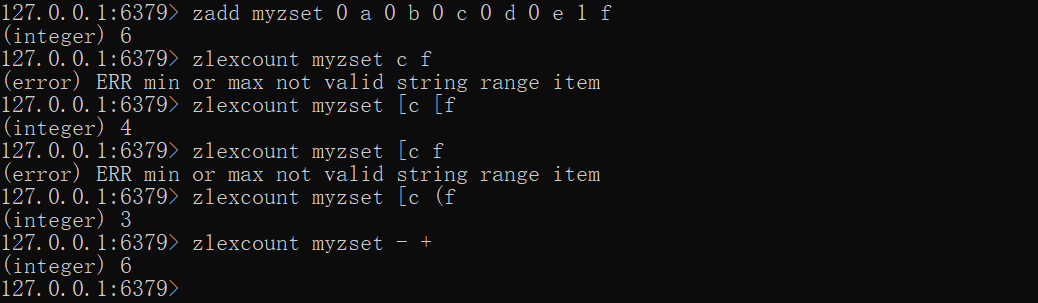
*ZMPOP——删除并返回分数
ZMPOP numkeys key [key ...] <MIN | MAX> [COUNT count]
从提供的键名列表中的第一个非空排序集中弹出一个或多个元素,即成员分数对。numkeys 为比较集合的个数,有多少写多少,count为获取的元素个数
x
DEL myzset myzset1zadd myzset 0 a 0 b zadd myzset1 -1 a 0 b 1 c 2 d 3 e 4 f# 指定移除3个最小成员,但myzset仅存在两个成员,所以只删除并返回两个成员的分数zmpop 2 myzset myzset1 MIN COUNT 3# myzset已经是空集合,所以第一个非空排序集合是myzset1zmpop 2 myzset myzset1 MIN COUNT 3# count默认1zmpop 2 myzset myzset1 MAX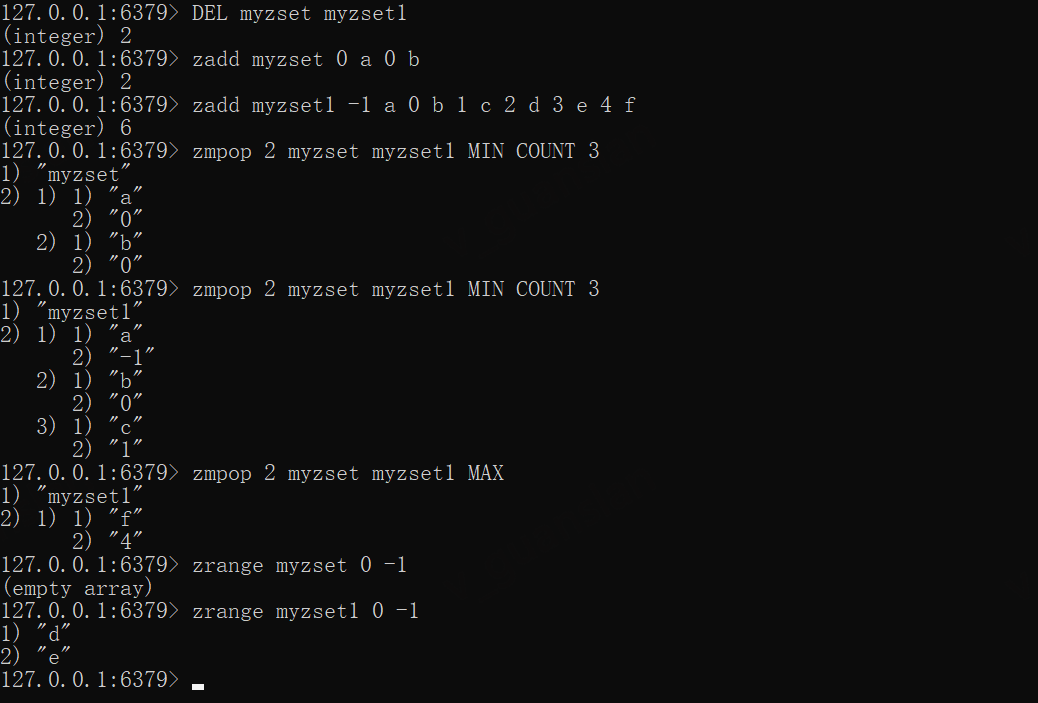
*ZMSORE——获取某成员的分数
获取某些成员的分数,可指定多个成员
x
zadd myzset -1 a 0 b 1 c 2 d 3 e 4 fzmscore myzset a fzmscore myzset a 
ZPOPMAX——删除并返回最高分数的成员
ZPOPMAX key [count]
移除指定数量最高分数的成员,并返回分数,可以视作zmpop的简写
x
zadd myzset 0 a 0 b 1 c 2 d 3 e 3 fzpopmax myzsetzpopmax myzset 3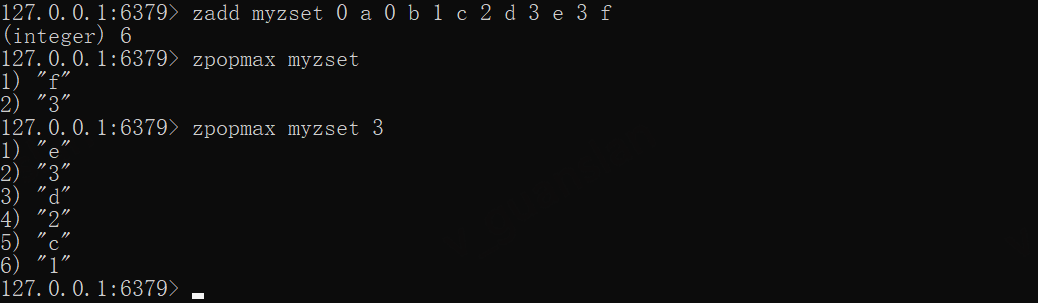
ZPOPMIN——删除并返回最低分数的成员
ZPOPMAX key [count]
移除指定数量最低分数的成员,并返回分数,可以视作zmpop的简写
x
zadd myzset 0 a 0 b 1 c 2 d 3 e 3 fzpopmin myzsetzpopmin myzset 2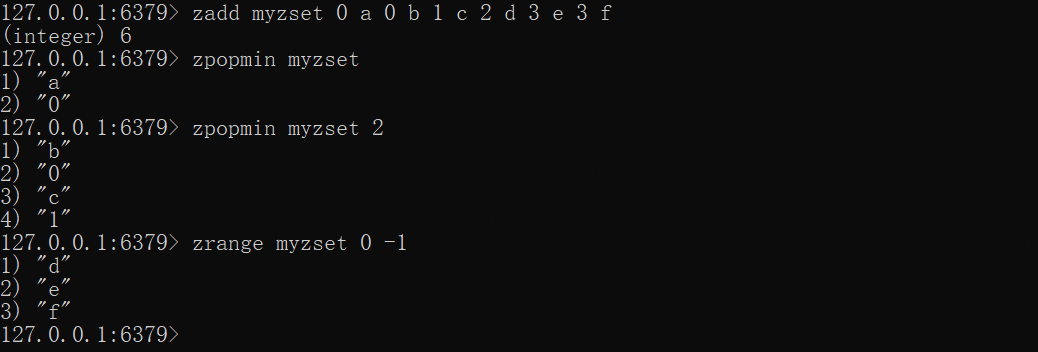
ZRANDMEMBER——随机获取成员
ZRANDMEMBER key [count [WITHSCORES]]
随机回去指定数量的成员及分数,当指定数量时才可以指定分数
x
zadd myzset 0 a 0 b 1 c 2 d 3 e 3 fzrandmember myzsetzrandmember myzset 2zrandmember myzset 1 WITHSCORES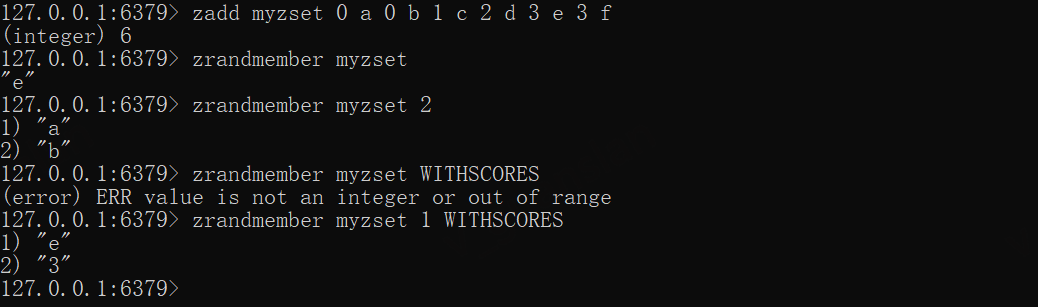
ZRANGE——获取某个区间的成员
ZRANGE key start stop [BYSCORE | BYLEX] [REV] [LIMIT offset count] [WITHSCORES]
获取有序集合中指定范围的成员,顺序是从最低分到最高分。具有相同分数的元素按字典顺序排列。
可以根据索引(默认)、分数(BYSCORE )、成员(BYLEX)排序,也可以指定反排(REV)即从高到低,默认从低到高
指定BYSCORE和REV时,及分数从高到低,要注意start和stop的值,若默认排序则不用考虑
x
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 f# 根据索引默认取前三个zrange myzset 0 2# 根据分数排序,取前三个分数的所有成员(>=3)zrange myzset 0 2 BYSCOREzrange myzset 0 2 BYSCORE REV# 根据分数倒排,此时start >= stop才有可能查出来数据zrange myzset 2 0 BYSCORE REVzrange myzset 2 0 REV# 根据索引倒排,此时会从右往左计算索引值,所以start <= stopzrange myzset 0 2 REV# 常用:获取所有成员,和成绩zrange myzset 0 -1 WITHSCORES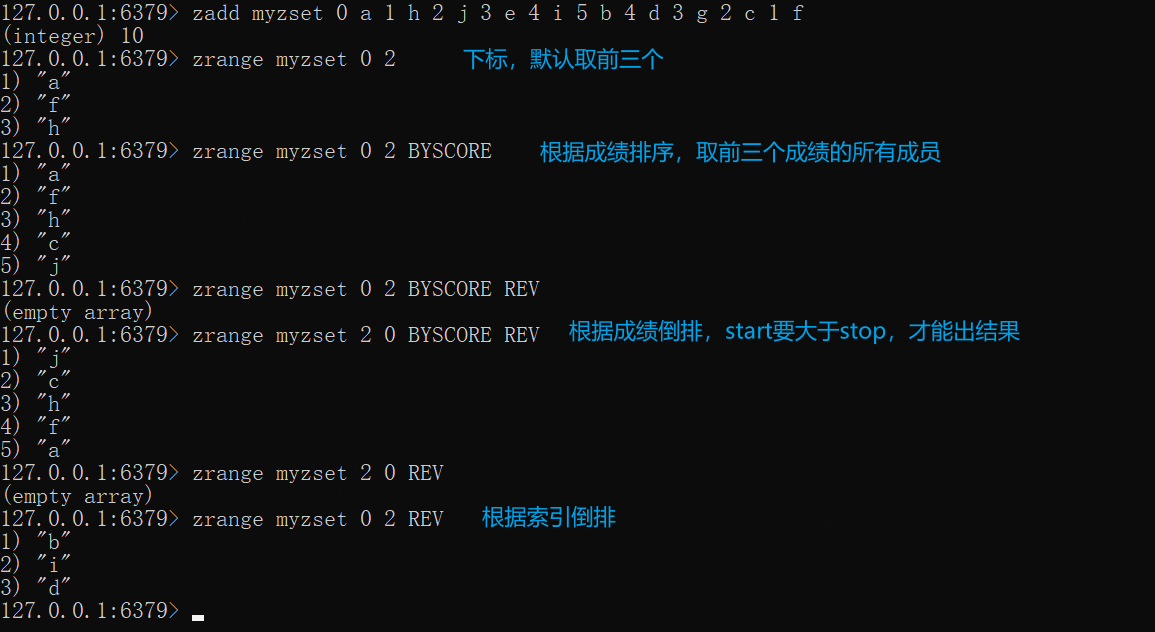
指定BYLEX时,集合内的成员分数必须是一样的,否则获取出来的结果和我们预期就不一致了,BYLEX不能和WITHSCORES一起使用
start、stop都是字典值,必须指定开区间——(,闭区间——[
xxxxxxxxxxzadd myzset1 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 f# 当前集合的成员分数不一致,得到的结果达不到预期zrange myzset1 [a (d BYLEX
zadd myzset 0 a 0 h 0 j 0 e 0 i 0 b 0 d 0 g 0 c 0 fzrange myzset [a (c BYLEX# 无法与WITHSCORES一起使用,因为当前集合的成员分数都是一致的zrange myzset [a (c BYLEX WITHSCORESzrange myzset [a (c BYLEX REV# 倒排时,需要调整start、stop值zrange myzset [c (a BYLEX REV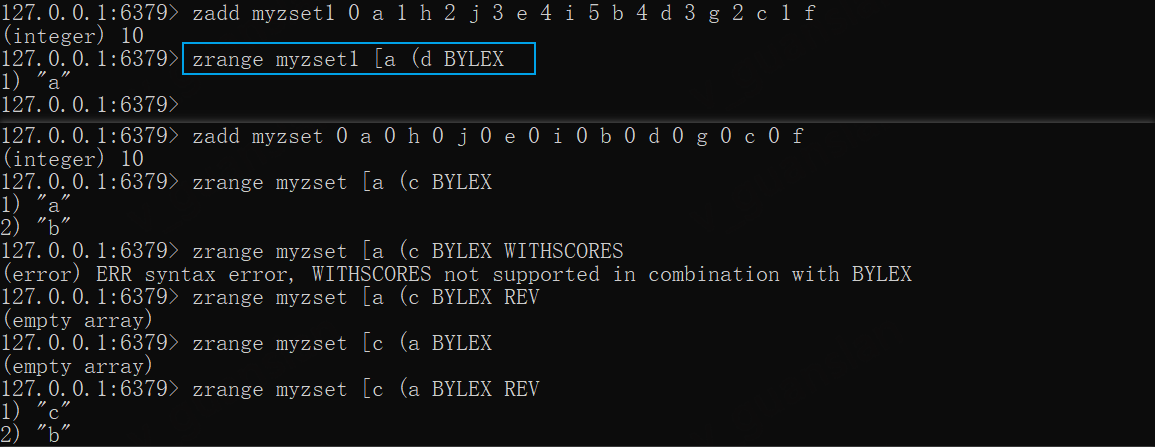
可以通过LIMIT进一步筛选数据,必须和BYSCORE、BYLEX一起使用
x
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 f# 不可单独使用zrange myzset 0 -1 LIMIT 0 5# 0、-1、+、-不表示索引范围zrange myzset 0 -1 BYSCORE LIMIT 0 5zrange myzset 0 + BYSCORE LIMIT 0 5# 分页获取,offset为偏移量,跳过多少条就写多少条zrange myzset 0 5 BYSCORE LIMIT 0 4zrange myzset 0 5 BYSCORE LIMIT 4 4zrange myzset 0 5 BYSCORE LIMIT 8 4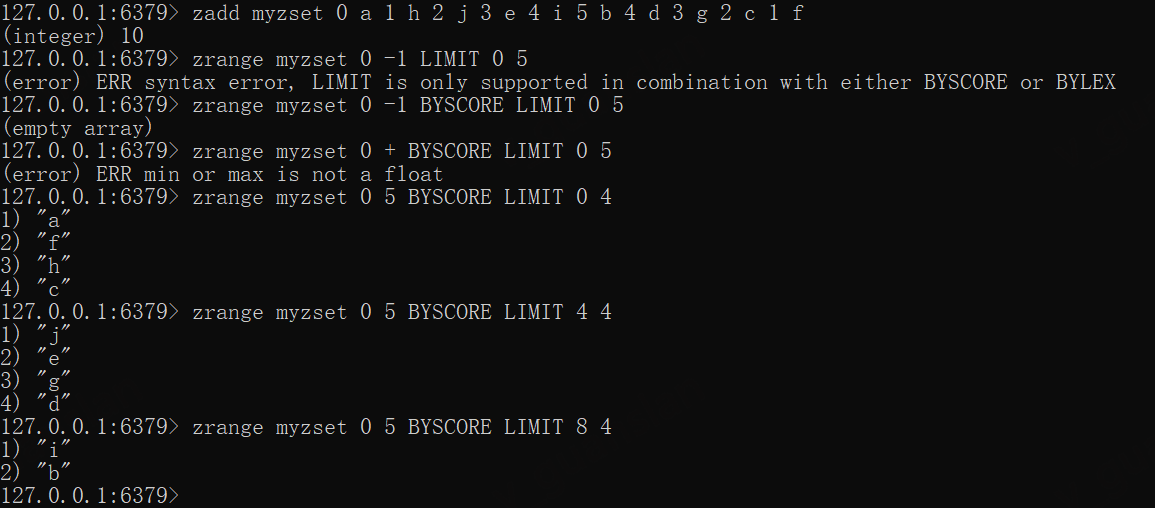
ZRANGEBYLEX——按字典范围获取某个区间的成员
ZRANGEBYLEX key min max [LIMIT offset count]
弃用,用法和意义类似于zrang...BYLEX,集合内的成员分数必须是一样的,否则获取出来的结果和我们预期就不一致了
start、stop都是字典值,必须指定开区间——(,闭区间——[
zadd myzset 0 a 0 h 0 j 0 e 0 i 0 b 0 d 0 g 0 c 0 f# 必须指定开闭区间zrangebylex myzset a d# 不包含a、包含bzrangebylex myzset (a [dzrangebylex myzset (a (j LIMIT 0 4zrangebylex myzset (a (j LIMIT 4 4zrangebylex myzset (a (j LIMIT 8 4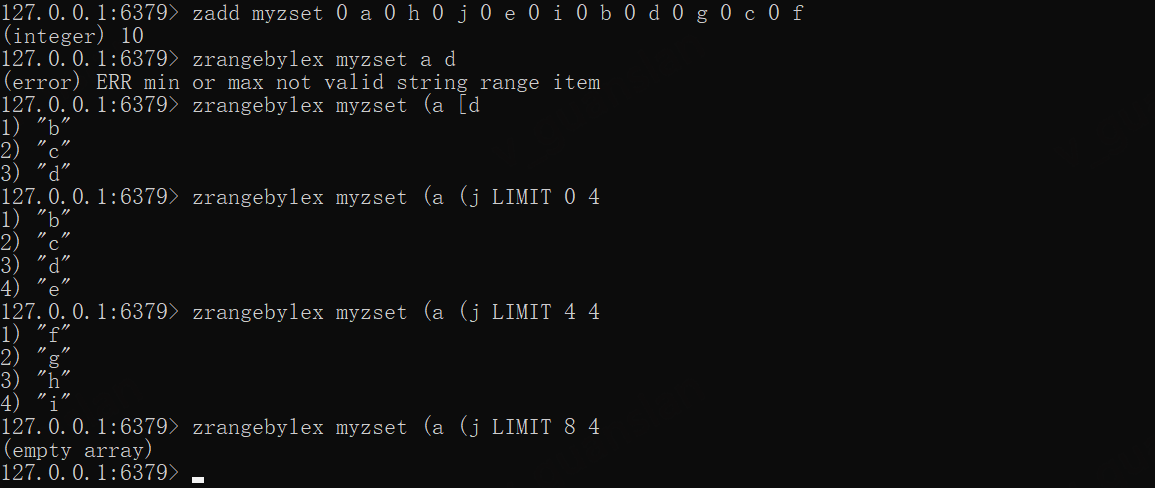
ZRANGEBYSCORE——根据分数获取某个区间的成员
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
弃用、用法和意义类似于zrang...BYSCORE,获取有序集合中指定分数范围的所有成员,顺序默认从低到高。具有相同分数的元素按字典顺序排列
min、max仅代表分数,0、-1只是普通分数,+、-不表示分数范围使用时报错,-inf +inf表示最小最大分数
xxxxxxxxxxzadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 fzrangebyscore myzset 0 1 WITHSCORES
zrangebyscore myzset 0 1 LIMIT 0 1zrangebyscore myzset 0 1 LIMIT 1 1zrangebyscore myzset 0 1 LIMIT 2 1zrangebyscore myzset 0 1 LIMIT 3 1
#普通查询zrangebyscore myzset 0 -1#报错zrangebyscore myzset - +#全部查询zrangebyscore myzset -inf +inf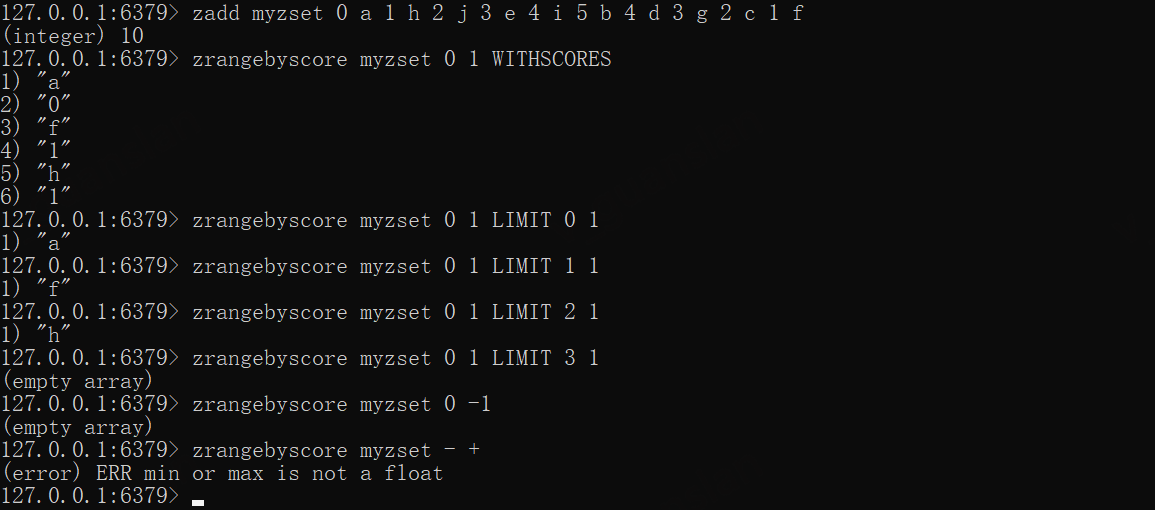
ZRANGESTORE——获取某个区间成员并存储新key中
ZRANGESTORE dst src min max [BYSCORE | BYLEX] [REV] [LIMIT offset count]
ZRANGESTORE的各项参数与ZRANGE雷同,不在赘述,dst为存储的key,若dst的成员已存在,则会覆盖更新分数,若不存在成员则添加成员及分数,若不存在dst,则自动创建
x
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 fzadd newzset 1 azrangestore newzset myzset 0 1 BYSCOREzrange newzset 0 -1 WITHSCORES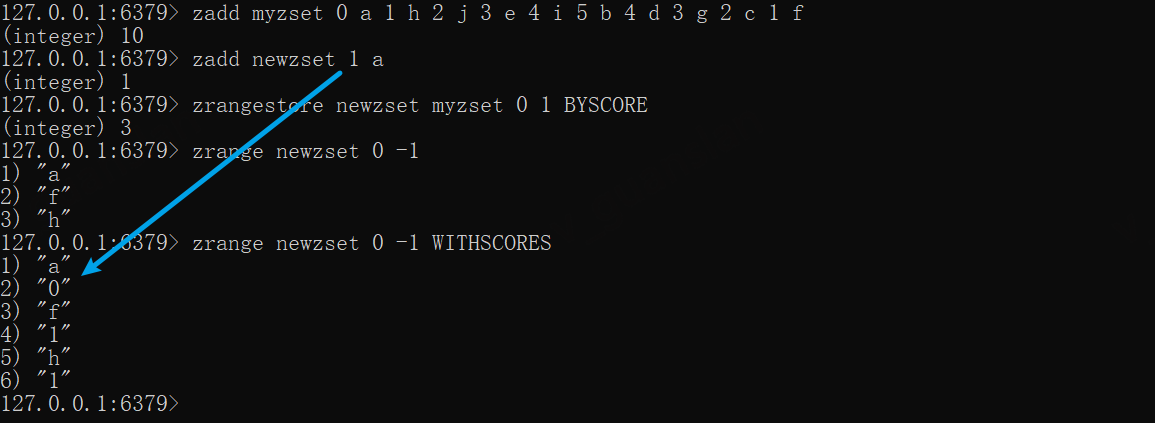
ZRANK——根据成员返回索引,从低到高
ZRANK key member
判断是否存在某成员并返回该成员的索引位置,从低到高,不存在成员、不存在key均返回nil
x
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 fzrank myzset azrank myzset bzrange myzset 0 -1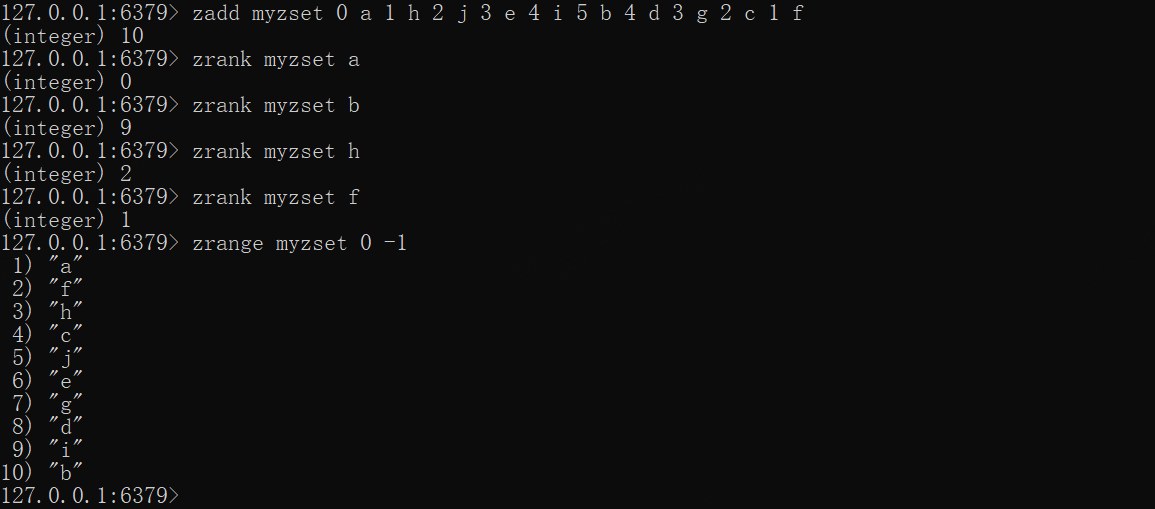
*ZREM——移除成员
ZREM key member [member ...]
移除成员并返回成功个数,可移除多个,不存在成员、不存在key均返回0
x
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 fzrem myzset a b b czrem myzset azrem myzset2 a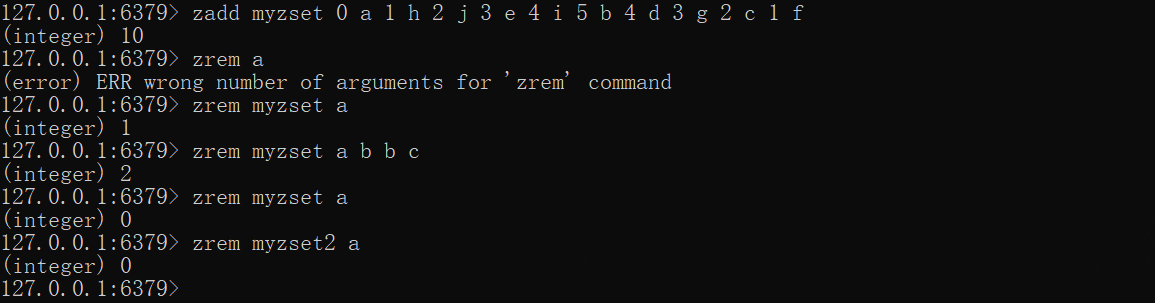
ZREMRANGEBYLEX——按字典范围移除某个区间的成员
ZREMRANGEBYLEX key min max
按字典范围移除某个区间的成员,集合内的分数应保持一致,否则执行结果将达不到预期,字典范围min、max必须指定开区间—(、闭区间—[,更多可以参考ZRANGEBYLEX,基本上ZRANGEBYLEX能查出来的,就能通过ZREMRANGEBYLEX来进行移除
执行成功会返回移除的个数,当范围匹配或key不存在,均返回0
x
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 f# myzset内的成员分数不一致,bylex的结果不及预期zrangebylex myzset [a [d
zadd myzset1 0 a 0 h 0 j 0 e 0 i 0 b 0 d 0 g 0 c 0 fzrangebylex myzset1 [a [dzremrangebylex myzset1 [a [dzrange myzset1 0 -1
zremrangebylex myzset2 [a [d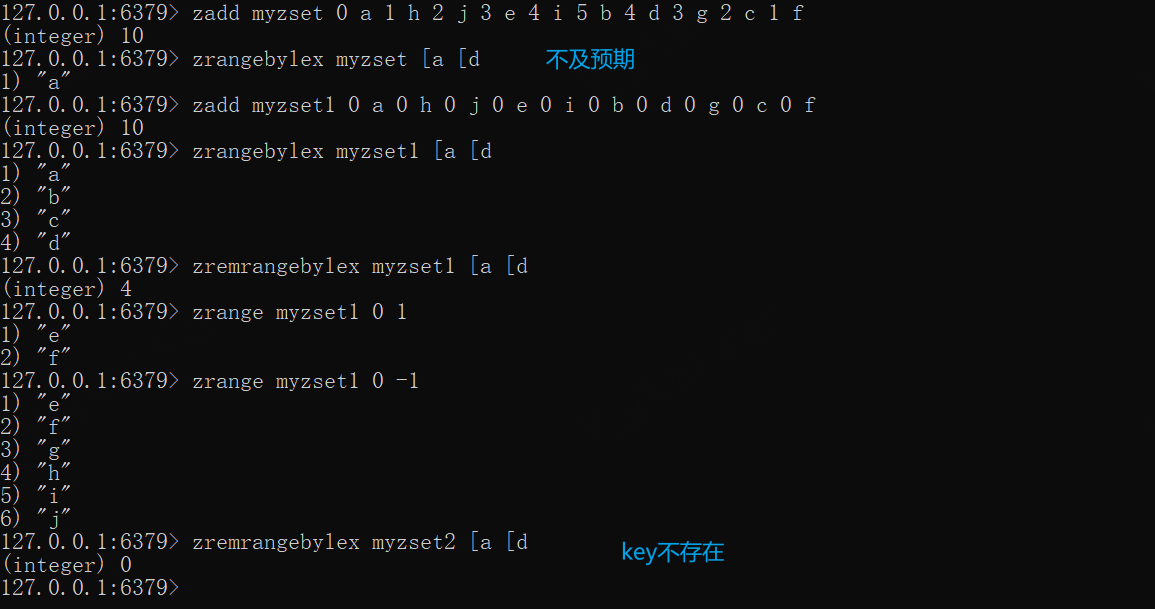
*ZREMRANGEBYRANK——根据索引移除某个区间的成员
ZREMRANGEBYRANK key start stop
按索引范围移除某个区间的成员,start stop为索引范围,索引范围0 是得分最低的元素,依次类推,-1是得分最高的元素,-2则是第二高,依此类推,更多可以参考ZRANGE,基本上ZRANGE能查出来的,就能通过ZREMRANGEBYRANK来进行移除
执行成功会返回移除的个数,当范围匹配或key不存在,均返回0
x
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 fzrange myzset 0 2zremrangebyrank myzset 0 2# 删除全部zremrangebyrank myzset 0 -1zrange myzset 0 -1
#错误写法zremrangebyrank myzset -inf +inf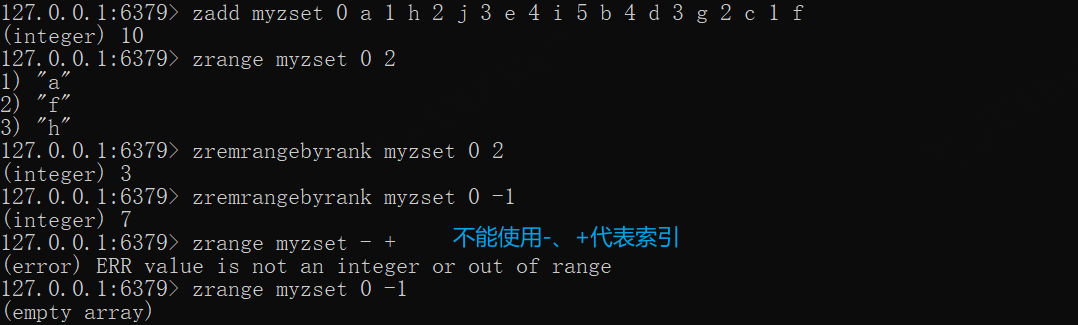
ZREMRANGEBYSCORE——根据分数移除某个区间的成员
ZREMRANGEBYSCORE key min max
按分数范围移除某个区间的成员,min max为分数范围,仅代表分数,默认闭区间,可以在分数前加上(表示开区间,不能加[表示闭区间,更多可以参考ZRANGEBYSCORE,基本上ZRANGEBYSCORE能查出来的,就能通过ZREMRANGEBYSCORE来进行移除
执行成功会返回移除的个数,当范围匹配或key不存在,均返回0
x
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 fzrangebyscore myzset 0 2 WITHSCORESzremrangebyscore myzset 0 2zrange myzset 0 -1
zremrangebyscore myzset 0 2zremrangebyscore myzset1 0 2#指定开区间zremrangebyscore myzset 2 (3zremrangebyscore myzset 2 3
#删除全部zremrangebyscore myzset -inf +inf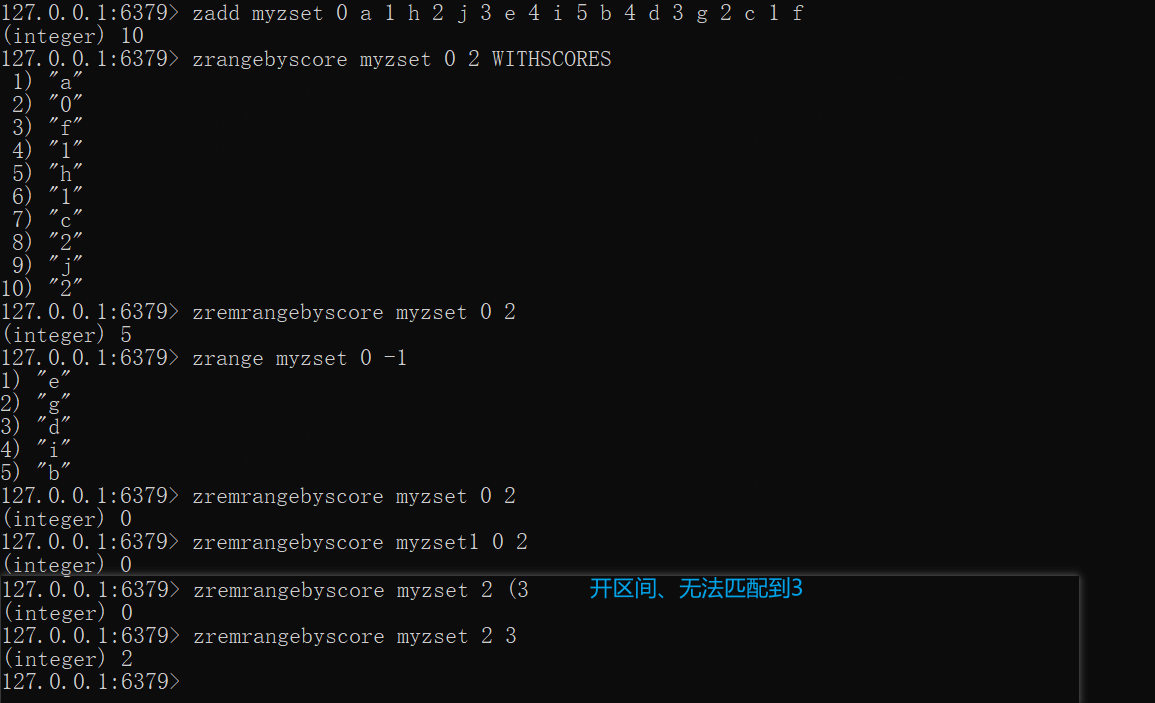
ZREVRANGE——返回指定区间成员分数从高到低
ZREVRANGE key start stop [WITHSCORES]
弃用,用法和意义类似于zrang... REV
start stop为索引范围,索引范围0 是得分最低的元素,依次类推,-1是得分最高的元素,-2则是第二高,依此类推,更多可以参考ZRANGE
x
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 fzrange myzset 2 4 REV WITHSCORESzrevrange myzset 2 4 WITHSCORES# 获取所有成员,并将分数由高到低排序zrevrange myzset 0 -1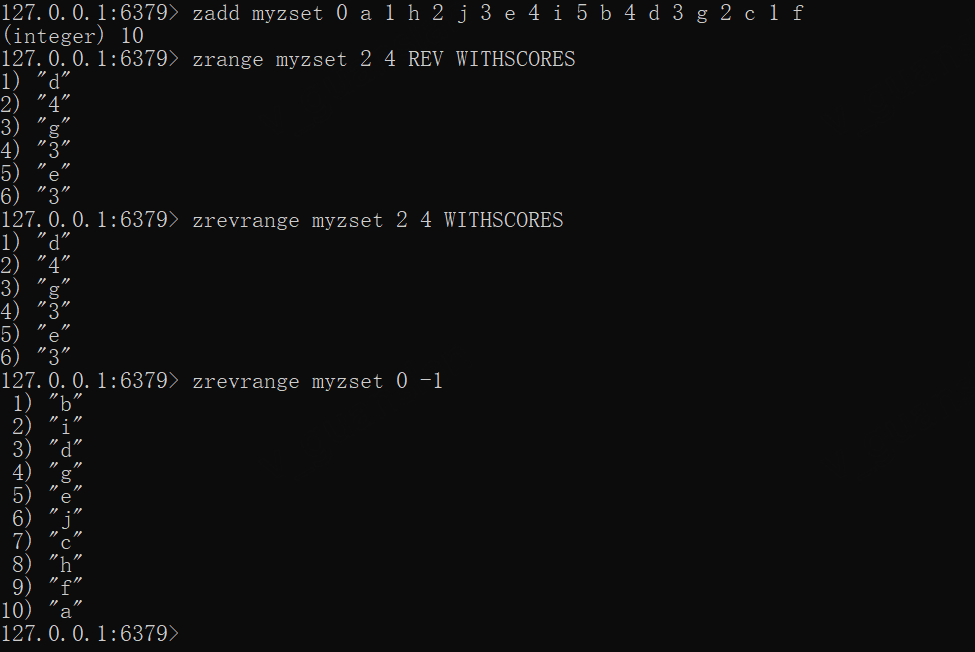
ZREVRANGEBYLEX——根据字典范围返回指定区间成员
ZREVRANGEBYLEX key max min [LIMIT offset count]
弃用,用法和意义类似于zrang...BYLEX REV,集合内的成员分数必须是一样的,否则获取出来的结果和我们预期就不一致了
max min都是字典值,必须指定开区间——(,闭区间——[,可以通过LIMIT进一步筛选数据条目,不能与WITHSCORES一起使用
x
zadd myzset 0 a 0 h 0 j 0 e 0 i 0 b 0 d 0 g 0 c 0 fzrange myzset [d (a BYLEX REVzrevrangebylex myzset [d (a
zrevrangebylex myzset [d (a LIMIT 0 1zrevrangebylex myzset [d (a LIMIT 3 1# 错误用法,bylex不能和WITHSCORES参数一起出现zrevrangebylex myzset [d (a WITHSCORES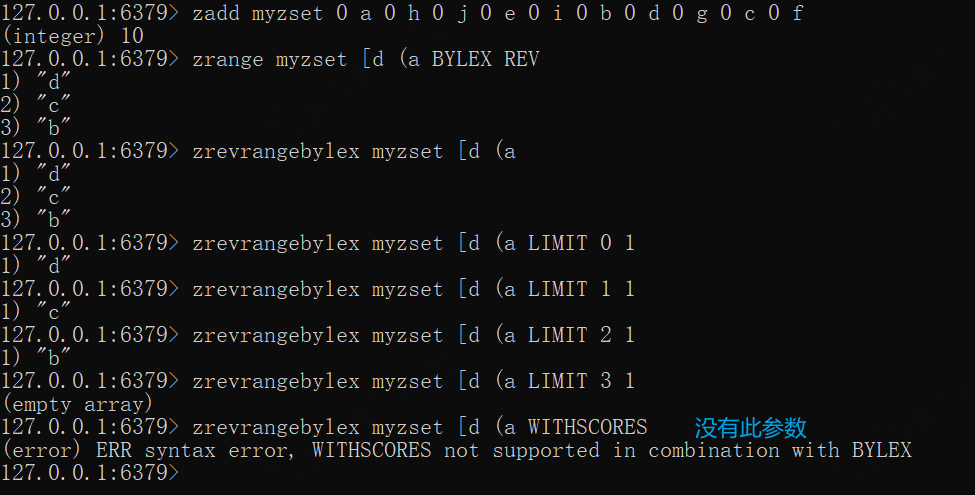
ZREVRANGEBYSCORE——根据分数返回指定区间成员
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
弃用、用法和意义类似于zrang...BYSCORE REV,获取有序集合中指定分数范围的所有成员,顺序从高到低。具有相同分数的元素按字典顺序排列
max min仅代表分数,0、-1只是普通分数,+、-不表示分数范围使用时报错,-inf、+inf表示最小最大分数
x
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 fzrange myzset 2 0 BYSCORE REVzrevrangebyscore myzset 2 0zrevrangebyscore myzset 0 -1#获取全部,并倒排分数zrevrangebyscore myzset +inf -inf#报错zrevrangebyscore myzset + -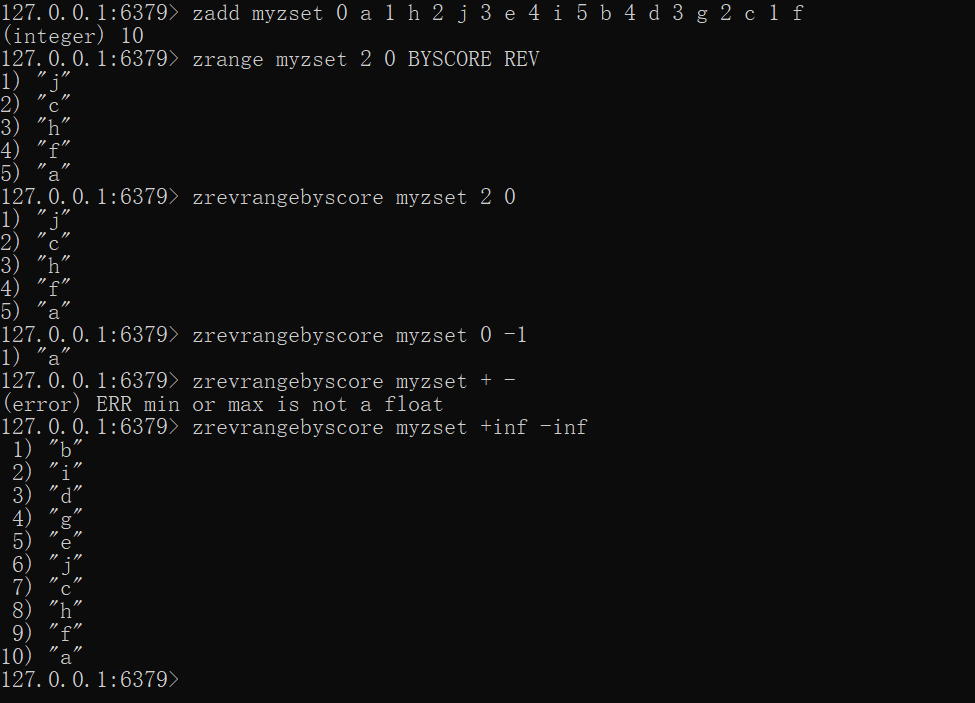
ZREVRANK——根据成员返回索引,从高到低
判断是否存在某成员并返回该成员的索引位置,从高到低,不存在成员、不存在key均返回nil
x
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 fzrevrank myzset a# zrevrank与zrank相对应zrank myzset azrevrank myzset aaazrevrank myzset1 aaa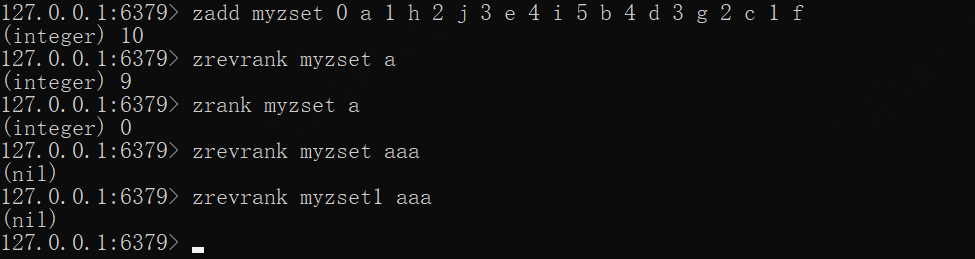
*ZSCAN——增量迭代集合
和scan用法类似,当key值(集合)很大时,可以使用对应的ZSCAN指令查看,ZSCAN支持正则、指定数量(不准确),使用语法如下:
ZSCAN key cursor [MATCH pattern] [COUNT count]
每次请求都会返回数据和游标,游标供下次查询,默认0为开始游标,若返回的游标是0则说明已经迭代完数据
x
zadd myzset 0 a 1 h 2 j 3 e 4 ia 5 bh 4 dj 3 ga 2 ch 1 fjzscan myzset 0 MATCH *a COUNT 1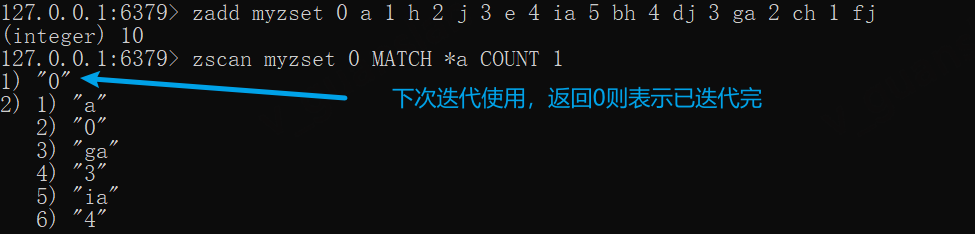
*ZSCORE——获取成员分数
ZSCORE key member
获取成员分数,若成员不存在或key不存在则返回nil
zadd myzset 0 a 1 h 2 j 3 e 4 i 5 b 4 d 3 g 2 c 1 fzscore myzset azscore myzset b# 成员、key不存在则返回nilzscore myzset bbzscore myzset1 bb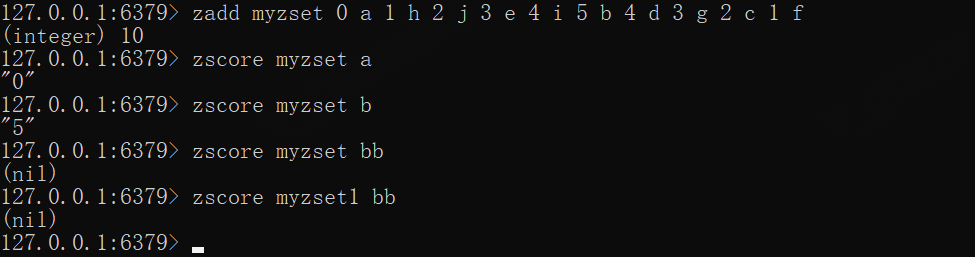
*ZUNION——获取并集
ZUNION numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>] [WITHSCORES]
获取集合之间的并集,只比较成员,分数可以通过AGGREGATE 参数指定,默认相加取总和,numkeys 为比较集合的个数,有多少写多少
- AGGREGATE :指定交集的分数如何处理,默认相加取总和,Min取最小的分数、Max取最大的分数
- WEIGHTS:乘法因子,默认1,在执行AGGREGATE 之前都会将各自分数乘以这个乘法分子,注意有多少个key就要写多少次,一一对应
x
del myzset yourzset zset_1zadd myzset 1 one 2 two 3 threezadd yourzset 1 one 22 two 4 four
# 并集,默认相同的成员将分数合并zunion 2 myzset yourzset WITHSCORES#并集,myzset所有成员分数乘2,yourzset所有成员分数乘1,两个集合相同的成员取分数大的zunion 2 myzset yourzset WEIGHTS 2 1 AGGREGATE MAX WITHSCORES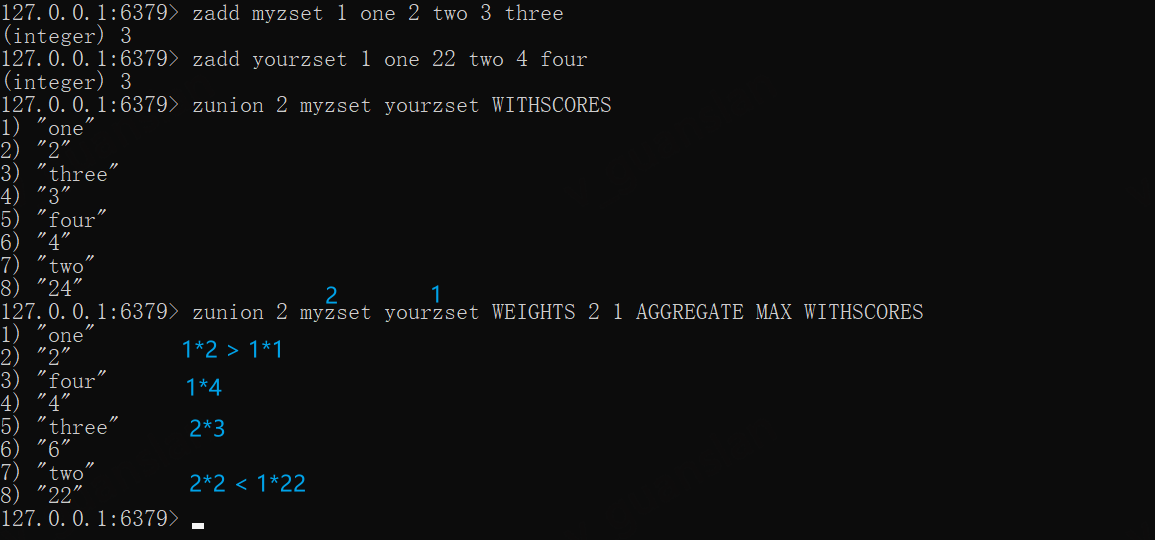
ZUNIONSTORE——获取并集并存储新key中
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>]
与ZUNION用法类似,只是ZUNIONSTORE将并集结果存储至新key而已,若key已存在则会覆盖里面的全部成员
x
del myzset yourzset zset_1 rzsetzadd myzset 1 one 2 two 3 threezadd yourzset 1 one 22 two 4 fourzadd rzset 1 one 11 aa
zunionstore rzset 2 myzset yourzsetzrange rzset 0 -1 WITHSCORES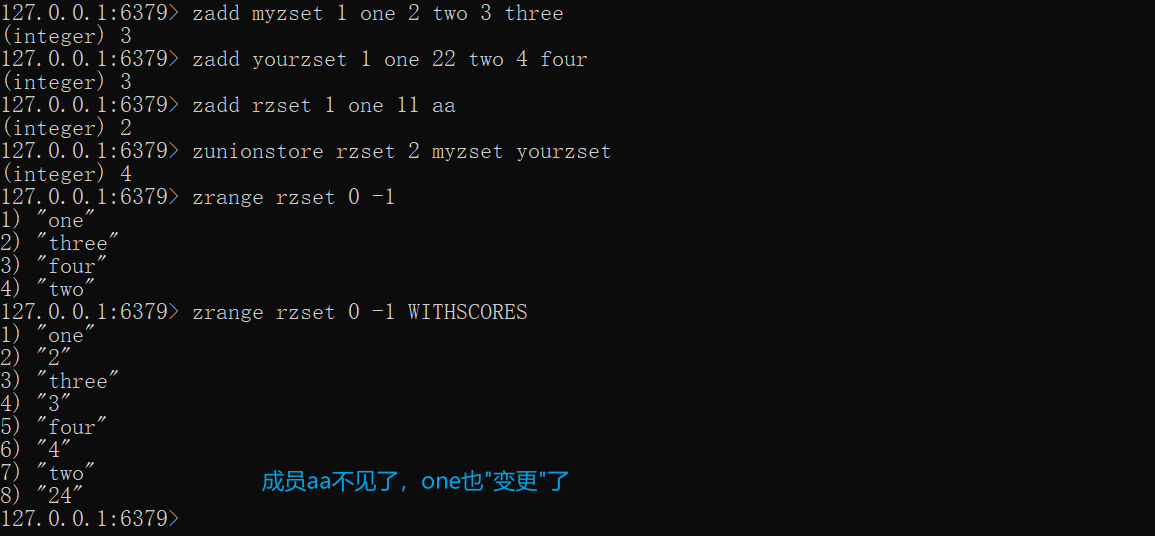
HASH类型常用操作
*HDEL——删除HASH字段
HDEL key field [field ...]
删除hash字段,可指定多个,成功则返回删除的条数,字段或key不存在则返回0
hset myhash a 1 b 22 c 333hdel myhash ahdel myhash b c# 字段或key不存在则返回0hdel myhash ahdel myhash1 a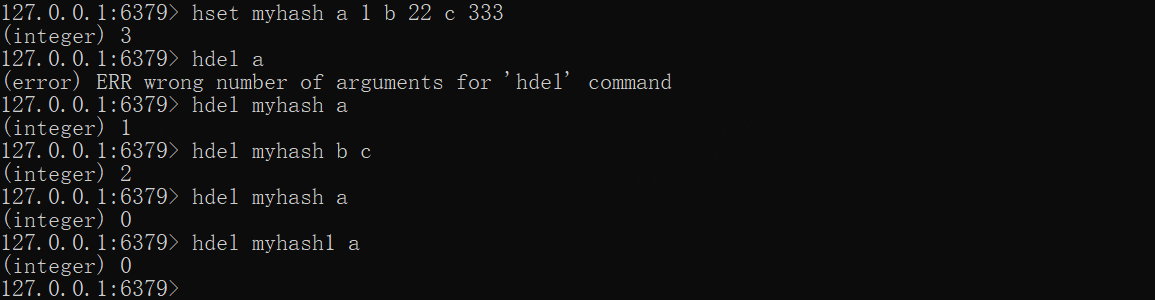
*HEXISTS——判断是否存在某字段
HEXISTS key field
判断是否存在某字段,若存在则返回1,不存在字段或key不存在则返回0
x
hset myhash a 1 b 22 c 33hexists myhash a
hexists myhash aahexists myhash1 aa
*HGET——获取字段值
HGET key field
获取某字段的值,若字段或key不存在则返回nil
x
hset myhash a 1 b 22 c 33hget myhash a# 字段或key不存在则返回nilhget myhash cchget myhash1 cc
HGETALL——获取全部字段值
HGETALL key
x
hset myhash a 1 b 22 c 33hgetall myhash
*HINCRBY——根据步长递增字段
HINCRBY key field increment
根据步长递增某字段,返回递增后的结果。若key不存在,则自动创建key,若字段不存在,则添加该字段并赋值为步长,注意步长不可省略,若要递减,则指定步长为负数即可
x
hset myhash a 1 b 22 c 33hincrby myhash a 100hincrby myhash a -20
# key或字段不存在,则添加该字段并赋值为步长hincrby myhash aa 100hincrby myhash1 aa 100hgetall myhash1
*HINCRBYFLOAT——根据小数步长递增字段
HINCRBYFLOAT key field increment
和HINCRBY用法类似,请参考。HINCRBYFLOAT支持浮点数类型,整型
x
hset myhash a 1 b 22 c 33hincrbyfloat myhash a 100hincrbyfloat myhash a -20.20# 报错,hincrby仅支持整型hincrby myhash a -20.20
*HKEYS——获取所有字段
HKEYS key
获取所有字段,key不存在则返回empty array
x
hset myhash a 1 b 22 c 33hkeys myhash11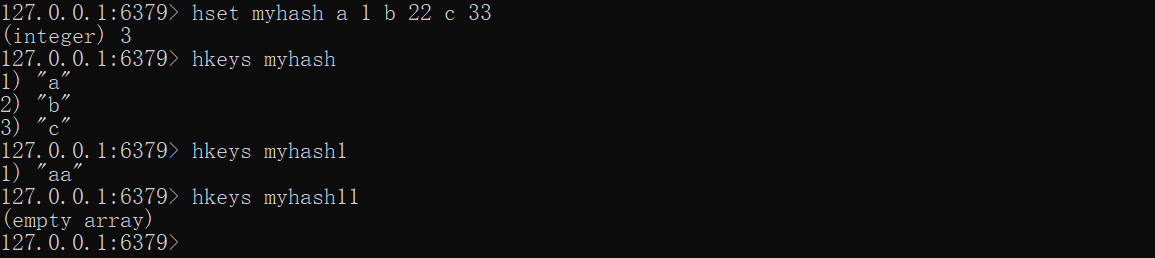
*HLEN——获取字段个数
HLEN key
获取key内字段长度,key不存在则返回0
x
hset myhash a 1 b 22 c 33hlen myhashhlen myhash11
HMGET——获取多个字段值
HMGET key field [field ...]
可同时获取多个字段值,字段或key不存在则返回nil
hset myhash a 1 b 22 c 33hmget myhash a b cc# 字段或key不存在则返回nilhmget myhash cchmget myhash1 cc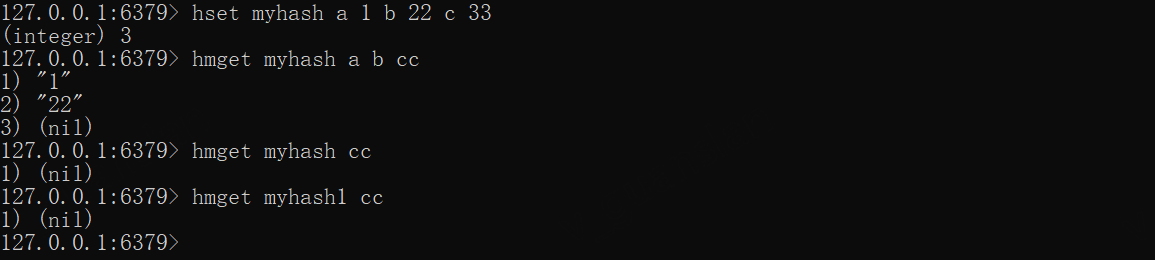
HMSET——设置多个字段值
HMSET key field value [field value ...]
弃用,设置多个字段值,若key中已存在某字段,则直接覆盖更新
x
hset myhash a 1 b 22 c 33hmset myhash a 111 b 222 d 44hgetall myhash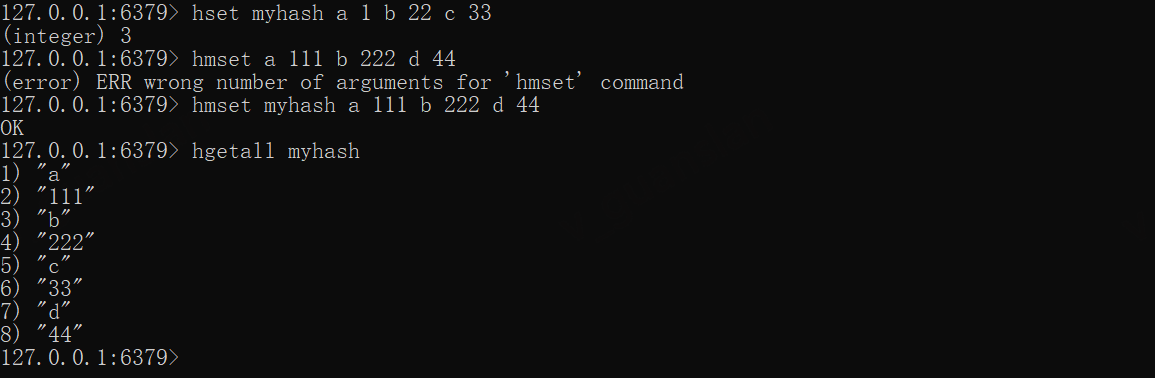
HRANDFIELD——随机获取字段
HRANDFIELD key [count [WITHVALUES]]
随机获取指定数量的字段,count可正可负,负数时允许多次返回相同的字段,当指定count时,可以指定WITHVALUES参数
x
hset myhash a 1 b 22 c 33hrandfield myhashhrandfield myhash# 会出现重复字段,并返回指定|count|数量hrandfield myhash -5# 不会出现重复字段,返回的数量小于等于count数量hrandfield myhash 5hrandfield myhash 5 WITHVALUES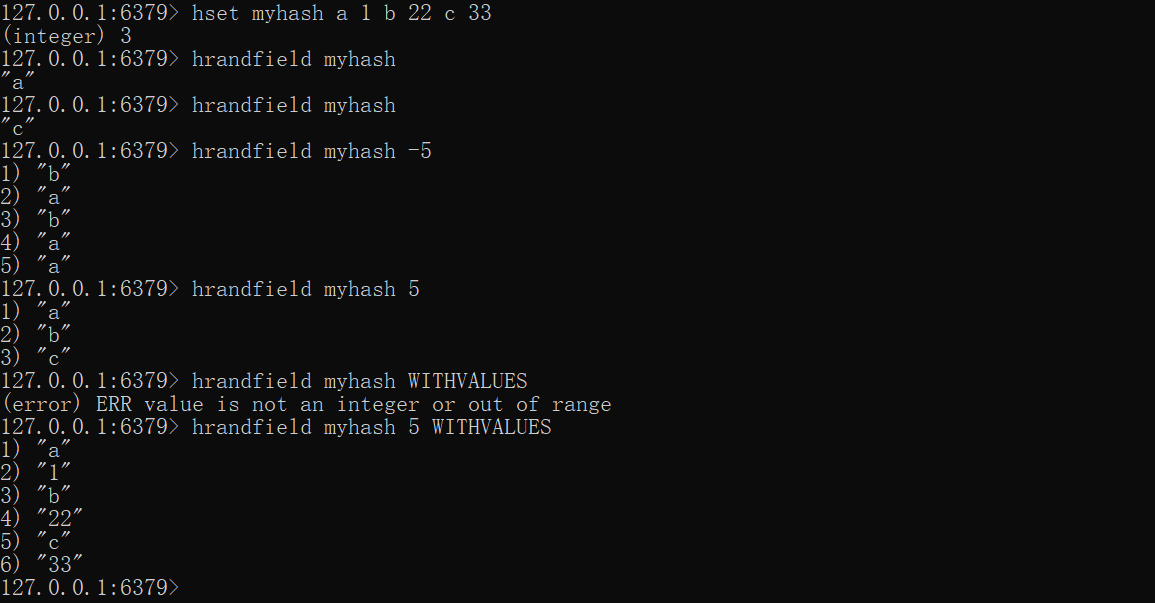
*HSCAN——增量迭代hash字段
HSCAN key cursor [MATCH pattern] [COUNT count]
和scan用法类似,当key值(集合)很大时,可以使用对应的HSCAN 指令查看,HSCAN 支持正则、指定数量(不准确)
每次请求都会返回数据和游标,游标供下次查询,默认0为开始游标,若返回的游标是0则说明已经迭代完数据
x
hset myhash a 1 b 22 c 33 aa 11 aab 112 aac 113 aaaa 1111hscan myhash 0 MATCH a* COUNT 2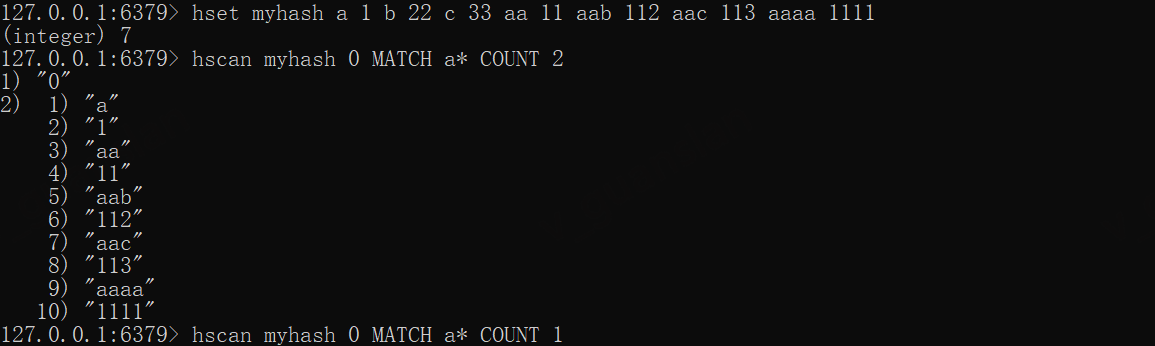
*HSET——设置字段
HSET key field value [field value ...]
设置字段值并返回插入的字段条数,可指定多个。若key中已存在某字段,则直接覆盖更新
x
hset myhash a 1# 插入两条、更新一条hset myhash a 11 b 22 c 33hgetall myhash
HSETNX——设置字段,当该字段存在则忽略
HSETNX key field value
设置字段值并返回插入的字段条数,若字段已存在则忽略,并返回0
x
hset myhash a 1hsetnx myhash a 100hsetnx myhash aa 100hgetall myhash
*HSTRLEN——获取字段值的长度
HSTRLEN key field
获取字段值的长度,若字段或key不存在则返回0
x
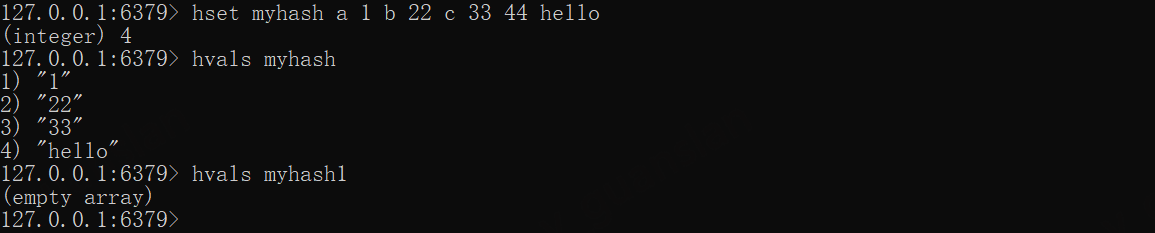
hset myhash a 1 b 22 c 33 44 hellohstrlen myhash ahstrlen myhash 44# 字段或key不存在则返回0hstrlen myhash aahstrlen myhash1 aa
HVALS——获取所有字段值
HVALS key
获取所有字段值,key不存在则返回empty array
xxxxxxxxxxhset myhash a 1 b 22 c 33 44 hellohvals myhashhvals myhash1