c#各大版本重要变更
>说明6.0nameof表达式?.、?[] null传播器字符串内插7.0throw可作为表达式使用元组赋值、析构、比较,弃元本地函数8.0[^]、[...]数组切片??、??= null合并操作符! null包容运算符9.0recordswitch改动init 访问器顶级语句new 优化10.0namespace文件范围的命名空间解除析构赋值的限制const常量内插优化
说明
c#11已经发布了,近些年,c#不断推出新版本,新功能、新语法糖,相信大家在项目中或多或少都能看到其身影。这几天闲着没事整理了一下c#6到c#10项目中常用的新特性、语法糖,希望能够有个印象吧
6.0
nameof表达式
nameof 表达式可生成变量、类型或成员的名称作为字符串常量,当操作数是类型或命名空间时,生成的名称不是完全限定的。nameof在编译中是没有任何意义的。用的比较少吧,最常见的就是定义常量了
x [Test] public void TestNameof() { var myName = "LiHua"; Console.WriteLine(nameof(myName)); // myName Console.WriteLine(nameof(myName.Length)); // Length Console.WriteLine(nameof(Tests)); // Tests Console.WriteLine(nameof(TestNameof)); // TestNameof Console.WriteLine(nameof(List<string>)); // List
//不同于typeOf Console.WriteLine(typeof(List<string>)); // System.Collections.Generic.List`1[System.String]
const string KEY_MAX_AGE = "KEY_MAX_AGE"; const string KEY_MIN_AGE = nameof(KEY_MIN_AGE); }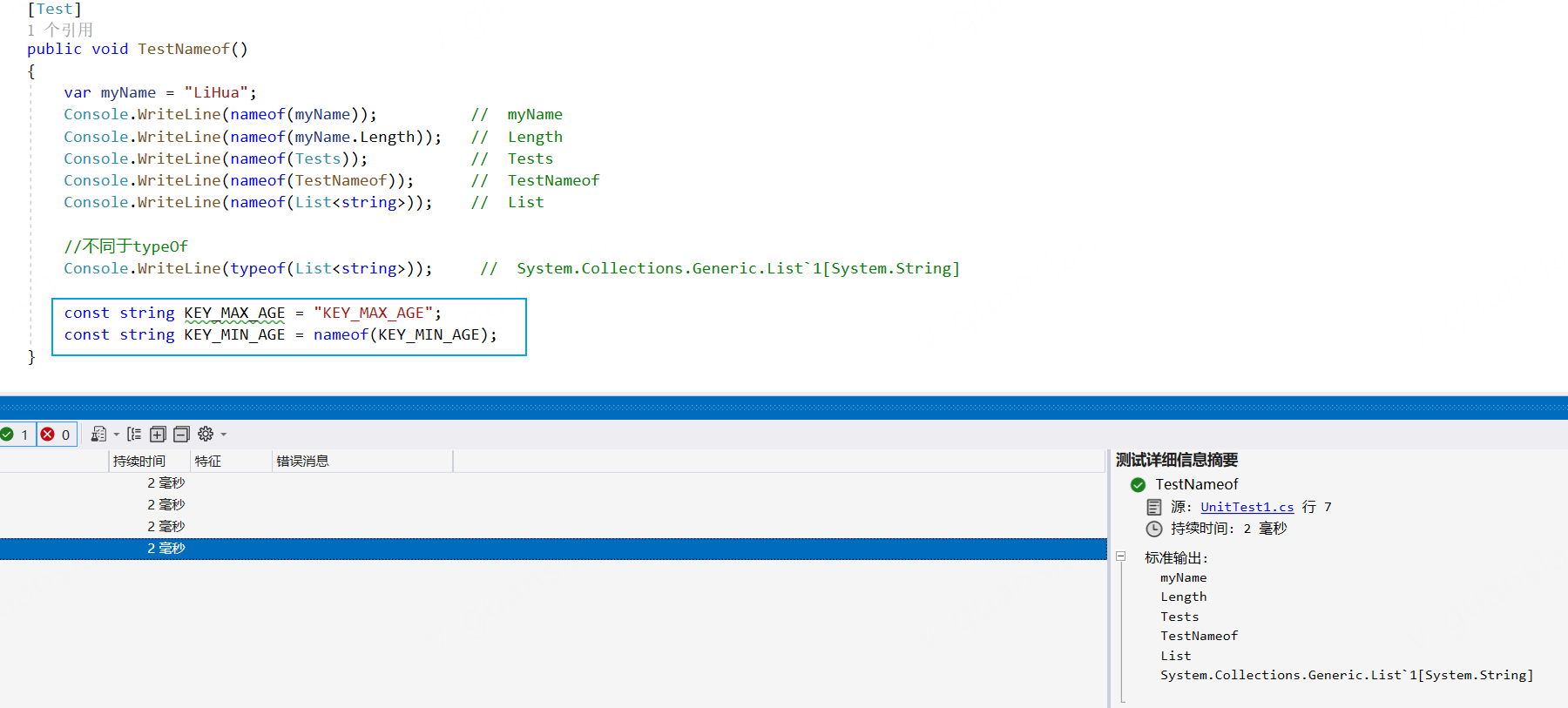
?.、?[] null传播器
通常当一个对象为null时,我们去调用其属性或方法,程序就会报空异常。这时我们就不得不主动捕获异常或者提前检验对象是否为null。null传播器的出现可以让我们减少书写不必要的代码
假设这里有一段程序,我们明眼一看就是有问题的
xxxxxxxxxx [Test] public void NoNullVisit() { string name = GetName(); var newName = name.Insert(0, "New"); Console.WriteLine(newName); }
private string GetName() { return null; }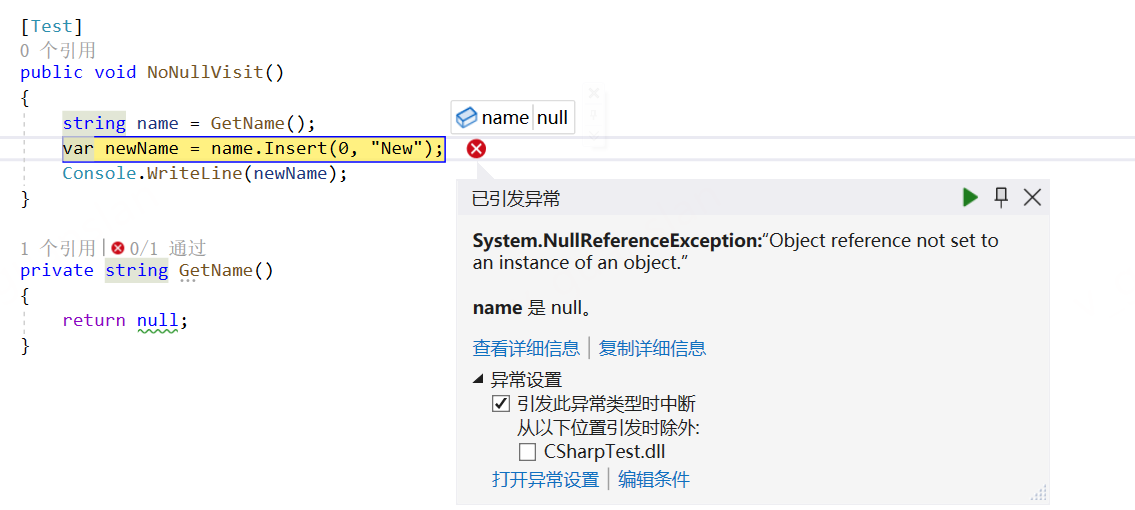
那么我们应该怎么处理呢?处理异常或者做空判断
xxxxxxxxxx [Test] public void NoNullVisitCatch() { try { string name = GetName(); var newName = name.Insert(0, "New"); Console.WriteLine(newName); } catch (Exception ex) { Console.WriteLine("程序出现异常" + ex.Message); } }
[Test] public void NoNullVisitIf() { string name = GetName(); if (name == null) { Console.WriteLine("程序出现异常name为null"); } else { var newName = name.Insert(0, "New"); Console.WriteLine(newName); } }上述方法是可以解决的,而null传播器就是帮助我们简化做空判断的,在一条语句中,如果对象为null则立即返回null,不会继续往下调用。如下我们可以看到null传播器确实可以帮助我们节省很多if判断,?[]还可作用于数组、集合、字典按索引、key取值的情况
xxxxxxxxxx [Test] public void NullVisit() { string name = GetName(); var newName = name?.Insert(0, "New")?.Trim(); //若name为null则返回null,若不为null则往下执行Insert方法,依此类推
// 可作用与数组、集合、字典,若对象为null则返回null,若不为null则会按照索引取值 List<string> nameArr = null; var oneName = nameArr?[0]; // null
Dictionary<string,string> nameDic = new Dictionary<string, string>() { { "aa","LiHua" } }; var twoName = nameDic?["aa"]; // LiHua Console.WriteLine(newName); }
字符串内插
我们常见的字符串链接方式有如下几种:
xxxxxxxxxx [Test] public void StrConcat() { var name = "LiHua"; var age = 18; var word = "我叫" + name + ",我今年" + age + "岁了。"; var word1 = string.Format("我叫{0},我今年{1}岁了。", name, age); // 我叫LiHua,我今年18岁了。 }字符串内插也是字符串连接的一种,使用字符串内插可以让我们的代码看起来更简洁更直观一点,格式:$"xxx{value}xxx"
当文本有{}冲突时,可以使用{}进行转义,有""冲突时,可以使用{{{}}}进行处理
xxxxxxxxxx [Test] public void StrConcatInline() { var name = "LiHua"; var age = 18; var word = $"我叫{name},我今年{age}岁了。"; // 我叫LiHua,我今年18岁了。
////当文本有{}冲突时,可以使用{}进行转义 var word1 = $"我叫{name},我今年{age}岁了。我{{{(age > 18 ? "成年了":"还未成年")}}},我最爱{{读书、写字、运动}}"; // 我叫LiHua,我今年18岁了。我{还未成年},我最爱{读书、写字、运动}
////有""冲突时,可以使用{{{}}}进行处理,但是输出时会保留{},遇到这种情况建议将其单独提出来如下 var str = age > 18 ? "成年了" : "还未成年"; var word2 = $"我叫{name},我今年{age}岁了。我{str},我最爱{{读书、写字、运动}}"; // 我叫LiHua,我今年18岁了。我还未成年,我最爱{读书、写字、运动} }7.0
throw可作为表达式使用
xxxxxxxxxx [Test] public void ThrowTest() { var name = 1 > 5 ? "LiHua" : null; if (name == null) throw new Exception("当前名字为null,无法取值");
//// 可以简写为 var name1 = 1 > 5 ? "LiHua" : throw new Exception("当前名字为null,无法取值"); }元组赋值、析构、比较,弃元
我们先看一下以前的元组Tuple——声明复杂,取值不明确。首先要new Tuple还要指定泛型,取值只能通过Item1、Item2、Item3...
xxxxxxxxxx [Test] public void TupleTest() { var tuple = new Tuple<string, int>("LiHua", 18); var name = tuple.Item1; var age = tuple.Item2; }优化过后,元组声明更简便,取值也可以通过析构、具名等方式让代码看起来更直观易懂。
xxxxxxxxxx [Test] public void TupleTest2() { //// 不再需要new Tuple var tuple = ("LiHua", 18); var name = tuple.Item1; var age = tuple.Item2; //// 析构 var (name1, age1) = tuple;
//// 具名,具名后不可再使用Item1、Item2 var tuple2 = GetNameAge(); var name2 = tuple2.name; var age2 = tuple2.age;
var (name3, age3) = GetNameAge(); }
private (string name,int age) GetNameAge() { return ("LiHua", 18); }同时满足以下两个条件时,两个元组可进行比较:具有相同数量的元素、每个元组位置上的元素类型一致
xxxxxxxxxx [Test] public void TupleTest3() { var tuple = ("LiHua", 18); var tuple2 = ("WangMing", 15); var tuple3 = ("LiHua", 18); Console.WriteLine(tuple == tuple2); // False Console.WriteLine(tuple == tuple3); // True var tuple4 = (15, "WangMing"); //Console.WriteLine(tuple == tuple4); // 编译错误
//// 元组的比较和指定字段没有影响 var tuple5 = (A: "LiHua", B: 18); Console.WriteLine(tuple == tuple5); // True var tuple6 = (B: "LiHua", A: 18); Console.WriteLine(tuple5 == tuple6); // True }元组弃元,指的是在元组析构时我们只需要其中某些元素,而其他元素我们是不需要的,这时候就可以使用弃元了,如下我们只需要其中money元素:
xxxxxxxxxx [Test] public void TupleTest4() { var (_, _, money) = GetTuple(); //Console.WriteLine(_); //编译错误,_作为弃元无法直接使用 Console.WriteLine(money); }
private (string name, int age, decimal money) GetTuple() { return ("LiHua", 18, 100); } #endregion本地函数
本地函数即函数内的函数,本地函数内可以共享函数外的变量,通常用于处理一系列操作,若其他地方也有类似操作,则建议提取为公共方法。
xxxxxxxxxx [Test] public void InnerMethodTest() { List<string> names = new List<string>() { "WangMing","LiHua","LiMing"}; var newName = GetNewName(); Console.WriteLine(newName);
string GetNewName(){ //todo return names.FirstOrDefault(); } }8.0
[^]、[...]数组切片
通常我们只能通过索引来获取数组的元素,通过Linq进行截取分割数组,如下
xxxxxxxxxx public void SliceArr() { var arr = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; var first = arr[0]; var last = arr[arr.Length - 1];
var newArr = arr.Skip(3).Take(3).ToArray(); }使用索引运算符,可以可以以更少的代码获取到我们想要的结果
^ 运算符指示序列末尾的元素位置,^1即倒数第一个、^2即倒数第2个、^e即倒数第e个,e可以是变量(可转int)也可以是数字、^length即第一个
.. 运算符指定某一索引范围的开头和末尾作为其操作数(左闭右开),可与 ^ 一起使用,.. 两边操作数均可省略。操作数为索引值,前数的索引必须要小于后数的索引。
a..等效于a..^0..b等效于0..b..等效于0..^0
xxxxxxxxxx public void SliceArr2() { var arr = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; var first = arr[0]; // 1 //// ^1 代表倒数第1个,^2倒数第2个...没有^0 var last = arr[^1]; // 9 var xx = arr[^2]; // 8 var first2 = arr[^arr.Length]; // 1
var arr1 = arr[..]; // 1-9 var arr2 = arr[..5]; // 1-5 var arr3 = arr[5..]; // 6-9 var arr4 = arr[0..^6]; // 1-3
// 不能倒着取,前数的索引必须要小于后数的索引 //var arr5 = arr[^1..^6]; //var arr6 = arr[^3..^6];
var arr5 = arr[^6..^1]; // 4-8 var arr6 = arr[^6..^3]; // 4-6 var arr7 = arr[^6..]; // 后6位,4-9 ---2023/11/10补充--- }??、??= null合并操作符
?? 当左边值为null时,取右边值。左右值类型应该可以相互转换,或者右边值可以是异常表达式
如下,以下这两种写法都可以表示当name为null时,赋值空字符串给newName,不为null则将name赋值给newName
xxxxxxxxxx public void NullMergeTest() { string name = null; var newName = name == null ? "" : name;
// 可以简化成 var newName2 = name ?? "";
// var newName3 = name ?? 11; 编译错误,左右值应该可以相互转换,或者右边值可以是异常表达式 var newName3 = name ?? throw new Exception("name为空"); }??= 和??类似,多了一层操作,若左边值为null它会将右边值赋值给左边值,再往下执行相关操作,我们往下看一下?、??、??=区别
xxxxxxxxxx public void NullMergeTest2() { string name = null; string name1 = null; var newName1 = name?.Insert(0,"New1"); // null var newName2 = (name ?? "").Insert(0,"New2"); // New2 var newName3 = (name1 ??= "").Insert(0, "New3"); // New3
Console.WriteLine(name); // null Console.WriteLine(name1); // "" }! null包容运算符
这个唯一的作用就是在查阅代码时起到一个心理作用吧,如果这里使用了!,则表明该变量"不可能"为null,同时可以消除编辑器的null提示。
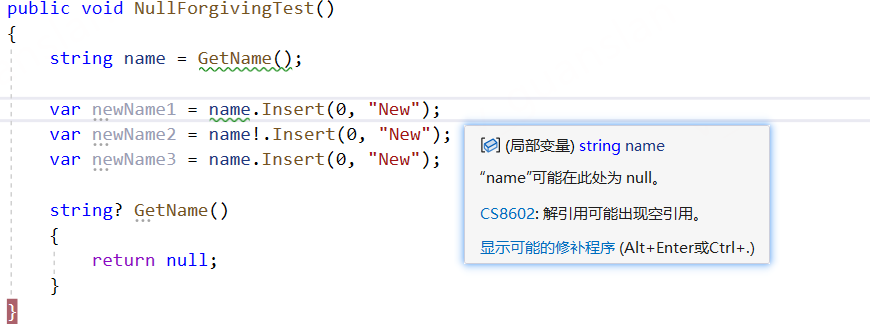
但是如果值真为null,编译还是会报异常的。我个人感觉是没啥用的,但是好多人都在用...
xxxxxxxxxx public void NullForgivingTest() { string name = GetName();
var newName2 = name!.Insert(0, "New"); var newName3 = name.Insert(0, "New");
string? GetName() { return null; } }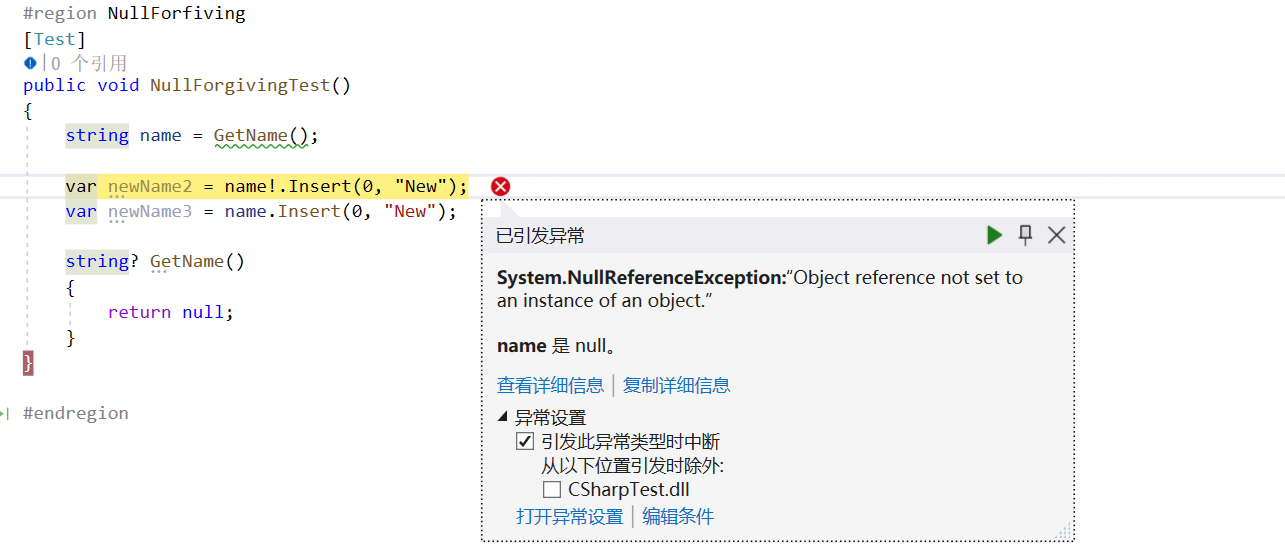
9.0
record
很少用,先不介绍吧
switch改动
c#8、c#9都致力于switch的更新,简单看一下吧,新的switch功能很强大但很少用,总是感觉用着不顺手。我们先看以往的switch,switch...case是一个萝卜一个坑进行匹配,若没找到对应的case就执行default分支了,这样一来除了刚好60、80、90、100的学生,其他学生不论多少分都是不及格的。程序这样处理肯定是不合理的,所以这里只能写成if...else...进行判断处理
xxxxxxxxxx public void SwitchTest() { var score = 60; var txt = ""; switch (score) { case 60: txt = "及格"; break; case 80: txt = "良好"; break; case 90: txt = "优秀"; break; case 100: txt = "满分"; break; default: txt = "不及格"; break; } Console.WriteLine(txt); }最近版本switch也支持进行范围匹配了,我们看下如何处理。大家觉得这样的switch更清晰明了还是if...else...
xxxxxxxxxx public void SwitchTest2() { var myScore = 101; var txt = GetScoreTxt(myScore); Console.WriteLine(txt);
string GetScoreTxt(int score) => score switch { >= 60 and < 80 => "及格", >= 80 and < 90 => "良好", >= 90 and < 100 => "优秀", 100 => "满分", > 100 or < 0 => "异常", _ => "不及格" }; }init 访问器
字段属性原有get、set属性,新增init属性,意为初始化过后不可修改值,可读。
xxxxxxxxxx public class AClass { public int Age { get; set; } public int AgeInit { get; init; } }
[Test] public void InitTest() { var a = new AClass() { Age = 18, AgeInit = 18 }; Console.WriteLine(a.AgeInit); a.Age++; //a.AgeInit++; //编译错误
var aa = new AClass(); //aa.AgeInit = 18; //编译错误 }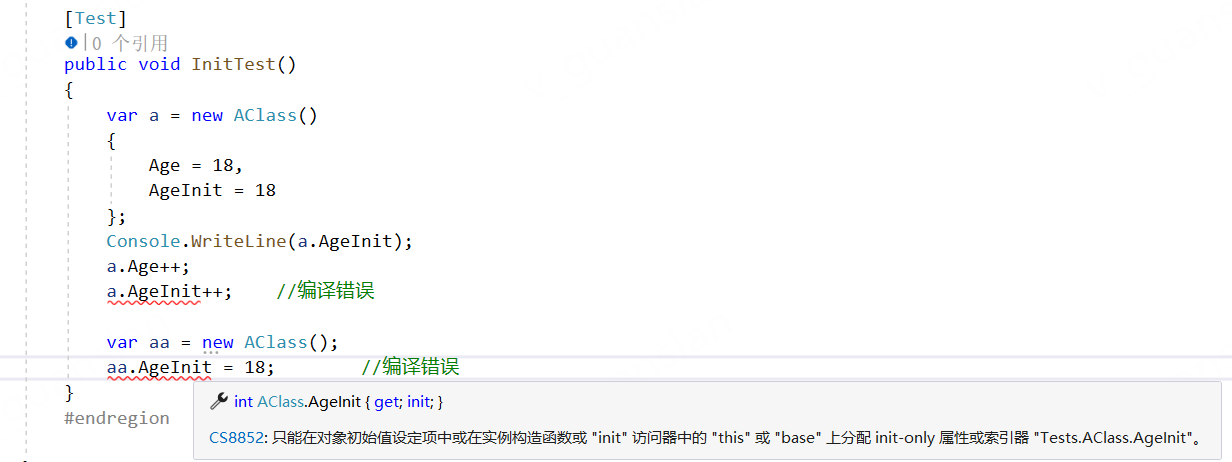
顶级语句
除了新项目自动生成的Program.cs,项目中很少用。
- 一个项目只能存在一个顶级文件
- 顶级文件可以存在多个方法、类、命名空间,但他们都不能有访问修饰符
- 顶级文件要依托于项目存在,单独的一个顶级文件是没有意义,是不能直接运行的(和python不一样)
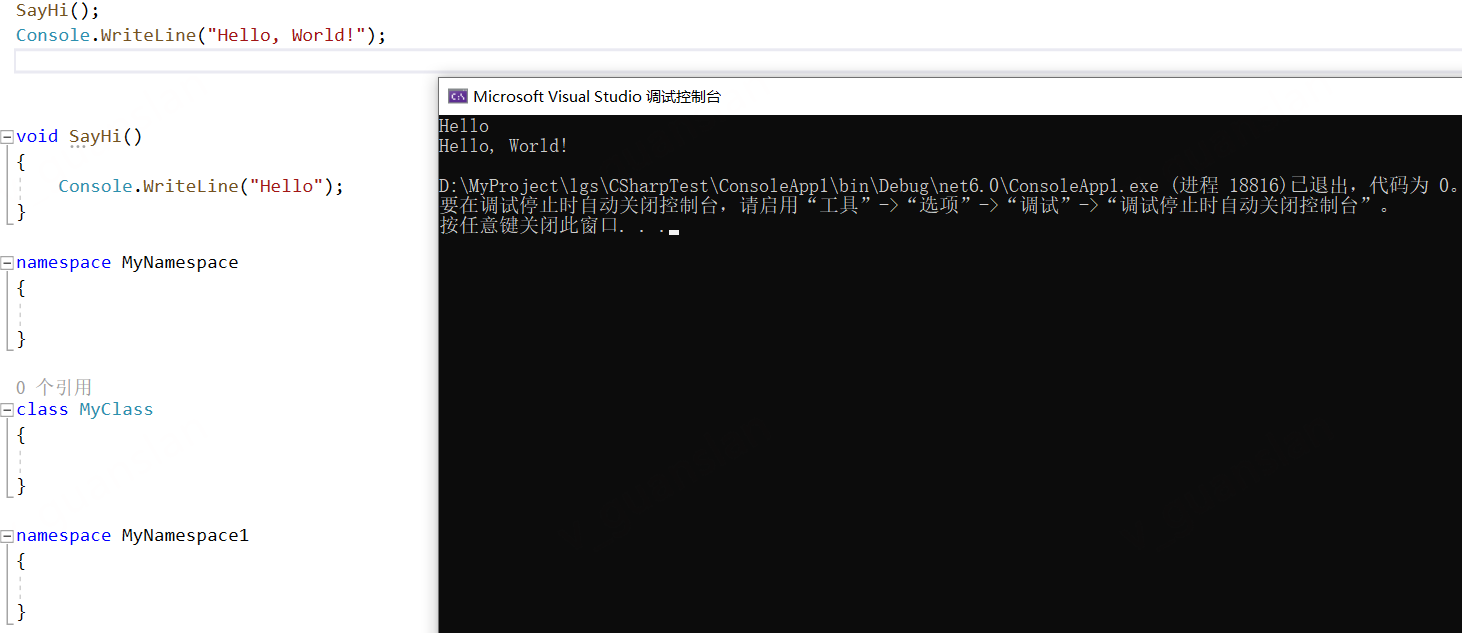
new 优化
当类型已知时,new初始化对象时可以不指定类型,如以下list初始化时,可以有"三种"写法
xxxxxxxxxx public void NewNewTest() { List<int> list = new List<int>(); // 可以简化为,常用 var list1 = new List<int>(); // 可以简化为 List<int> list2 = new(); }正常使用第二种写法就行了啊,而且也比第三种看着顺眼,为啥还要搞出第三种写法。如下我们可以看到,调用某方法时,类型已知,我们便可以简写为new()即可,不过这样用法还是很少
xxxxxxxxxx public void NewNewTest2() { DoSomething(new List<int>()); // 可以简化为 DoSomething(new()); void DoSomething(List<int> list) { // todo } }有一点值得肯定的是,创建数组时可以不用指定数组类型了,如果可以像js那样创建数组就更好了
xxxxxxxxxx public void NewNewTest3() { var c = new int[] { 10, 20, 30 }; // 可以简化成 var cc = new[] { 10, 20, 30 };
var d = new string[] { "10", "20", "30" }; // 可以简化成 var dd = new[] { "10", "20", "30" };
var e = new object[] { "10", "20", "30", 10 }; //var ee = new[] { "10", "20", "30", 10 }; // 编译错误,多个类型就不支持了,哈哈 }10.0
namespace文件范围的命名空间
可以将namespace的大括号去掉,改为分号,这样一来一个文件就只能有一个namespace了,该文件内的成员都是该命名空间的成员。
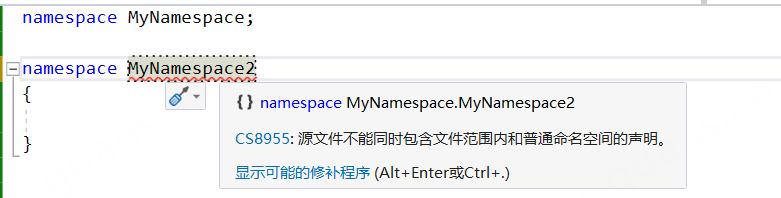
解除析构赋值的限制
解除析构赋值的限制,可先定义再重新赋值
xxxxxxxxxx public void TupleValueTest() { var name = "LiHua"; (name, int age) = ("LiMing", 18);
Console.WriteLine(name + age); // LiMing18 }const常量内插优化
之前const常量是无法进行加减乘除及字符串拼接的,目前支持了,这个挺好的
xxxxxxxxxx public void ConstStrTest() { const string Bank_Name = "xx银行"; const int Bank_Year = 30; const string Bank_Word = $"欢迎来到{Bank_Name}!"; const int Bank_Year_2 = 20 + Bank_Year; const int Bank_Year_5 = 100 / Bank_Year; const double Bank_Year_6 = 100 - Bank_Year; const decimal Bank_Year_7 = 100 * Bank_Year;
//const string Bank_Word2 = $"欢迎来到{Bank_Name}!我们已经有{Bank_Year}历史了"; // 编译错误,Bank_Year为int类型,无法与string一起使用 }