ElasticSearch 从入门到放弃
>说明查看es相关信息查看es是否启动成功查看集群健康状态_cat/health查看分片信息_cat/shards查看集群节点信息_cat/nodes查看索引信息_cat/indices使用Kibana操作es基本操作索引操作添加修改文档POST/PUT删除文档简单查询高级查询DSL数据准备match_alltermtermsmatchmulti_matchmatch_phraseidsrangeexistboolprefixwildcardfuzzyregexp注意事项分页查询scroll分页查询排序字段指定字段查询高亮查询过滤查询聚合查询聚合查询—指标聚合max、min、sum、avg文档计数_count统计某字段有值的文档数value_count去重后计数cardinalitystats统计extended_stats统计百分位统计percentiles统计值小于等于指定值的文档占比percentile_ranks地理位置坐标点的范围地理位置中心点坐标值聚合查询—桶聚合按照字段项分组聚合terms对满足过滤查询的文档进行聚合计算filter分别对多个过滤条件聚合计算filters数值范围分组聚合range时间范围分组聚合date_range时间直方图(柱状)聚合缺失值的桶聚合地理距离分区聚合
说明
一起来学习ES的使用吧,目前只是分享皮毛,看完这篇应该对ES有个大概认识了,后续会继续更新。
ES 8.0+
kibana 8.0+
查看es相关信息
查看es是否启动成功
安装后访问 127.0.0.1:9200 ,注意端口,出现以下界面便是成功的
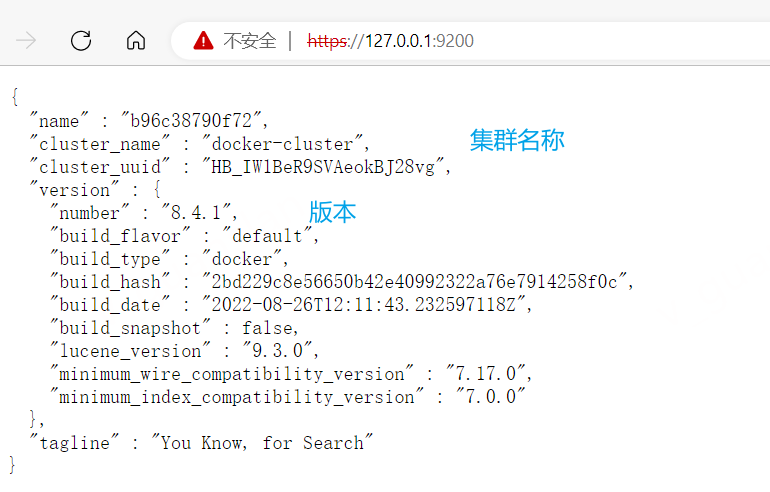
查看集群健康状态_cat/health
访问:https://127.0.0.1:9200/_cat/health?v

- cluster:集群名称
- status:集群状态 green 表示集群一切正常;yellow 表示集群不可靠但可用(单节点状态);red 集群不可用,有故障。
- node.total:节点总数量
- node.data:数据节点的数量
- shards:存活的分片数量
- pri:主分片数量
- relo:迁移中的分片数量
- init:初始化中的分片数量
- unassign:未分配的分片
- pending_tasks:准备中的任务
- max_task_wait_time:任务最长等待时间
- active_shards_percent:激活的分片百分比
查看分片信息_cat/shards
https://127.0.0.1:9200/_cat/shards?v
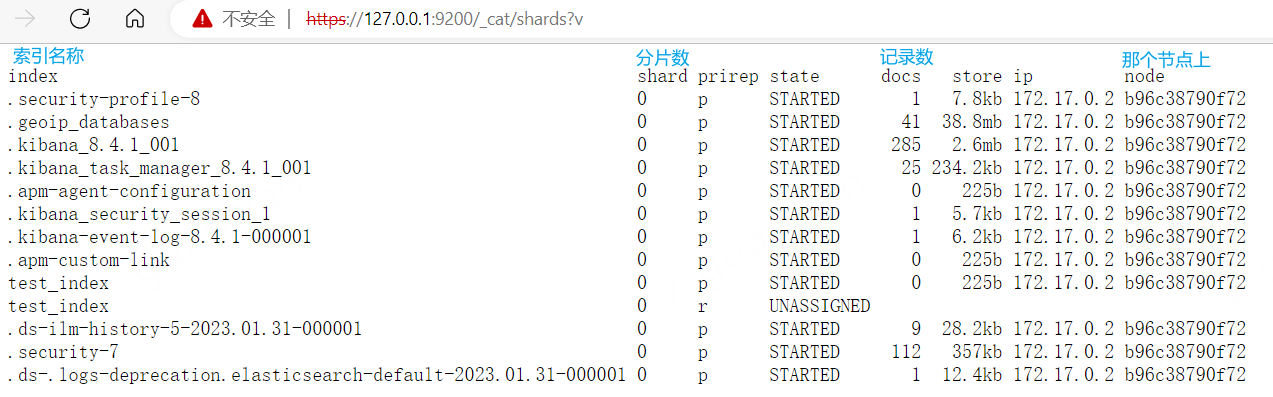
- index:索引名称,通常.开头的是es自带的索引
- shard:分片数
- prirep:分片类型,p为主分片,r为复制分片
- state:分片状态,STARTED为正常
- docs:记录数
- store:存储大小
- ip:节点ip
- node:节点名称,在哪个节点上
查看集群节点信息_cat/nodes
https://127.0.0.1:9200/_cat/nodes?v

- ip:节点ip
- heap.percent:堆内存使用百分比
- ram.percent: 运行内存使用百分比
- cpu:cpu使用百分比
- master:带* 表明该节点是主节点,带-表明该节点是从节点
- name:节点名称
查看索引信息_cat/indices
https://127.0.0.1:9200/_cat/indices?v

- index: 索引名称
- docs.count:文档总数
- docs.deleted:已删除文档数
- store.size: 存储的总容量
- pri.store.size:主分片的存储总容量
使用Kibana操作es
基本操作
带?v表示列出列名
GET _cat# 查看集群健康状态GET _cat/health?v# 查看分片信息GET _cat/shards?v# 查看索引的分片状态GET _cat/shards/index_name?v# 查看索引信息GET _cat/indices?v# 查看集群节点信息GET _cat/nodes?v索引操作
xxxxxxxxxx# 创建索引PUT test_index# 删除索引DELETE test_index# 查看索引的字段及类型GET test_index/_mapping添加修改文档POST/PUT
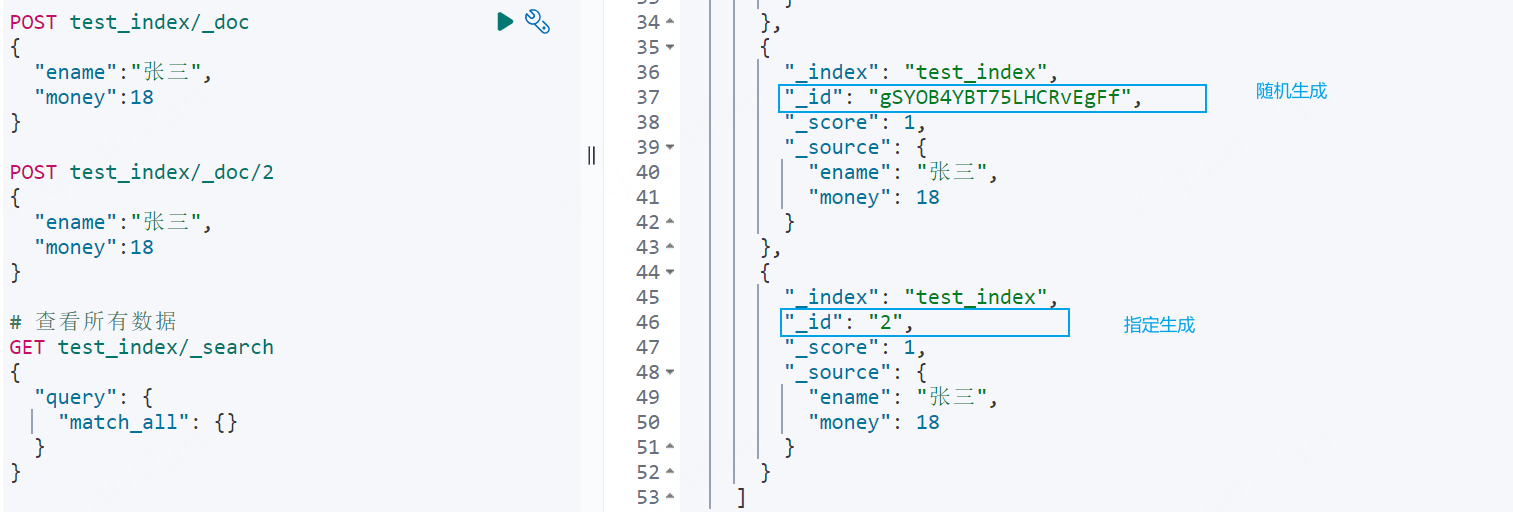
POST indexName/_doc/[id]
xxxxxxxxxx# 添加一条记录POST test_index/_doc{ "ename":"张三", "money":18}POST test_index/_doc/2{ "ename":"张三", "money":18}我们可以看到可以查出两条"张三"数据,其中一条id是随机生成的,另外一条是指定生成的,若下次在指定相同id则会执行update操作,直接覆盖已有的记录
PUT indexName/_doc/id
put操作也可以添加或修改记录,必须指定id,若id不存在则创建该记录,若存在则做更新操作,覆盖已有的记录
xxxxxxxxxx# id 3kil 不存在则创建该记录PUT test_index/_doc/3kil{ "name":"123456"}# id 3kil 已存在则修改该记录PUT test_index/_doc/3kil{ "jiji":"78"}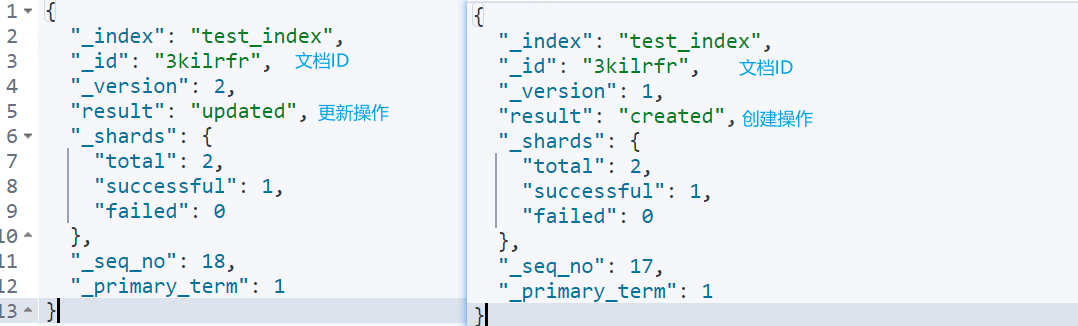
像上述的两种方式更新会直接覆盖原有记录,那有没有办法只修改其中某些字段呢?肯定是有的,我们可以借助 POST indexName/_update/id 来处理,只有POST可以这样操作,PUT不可以
xxxxxxxxxxPOST test_index/_doc/1{ "name":"张三", "age":18, "money":100.56}# 单独更新某些字段、若新增字段直接往doc加就行POST test_index/_update/1{ "doc":{ "age":20, "address":"xxx路" }}# 指定删除某个字段,doc和script不能同时存在POST test_index/_update/1{ "script": { "source": "ctx._source.remove(\"name\")" }}
还可以借助 POST indexName/_update_by_query来批量修改
x# 依次添加三条记录POST test_index/_doc{ "name":"张三", "age":18, "money":100.56}
POST test_index/_doc{ "name":"张四", "age":12, "money":200.56}
POST test_index/_doc{ "name":"张五", "age":22, "money":140.56}# 根据查询结果修改某些字段,只能通过script来进行修改、新增删除字段POST test_index/_update_by_query{ "query": { "range": { "age": { "gte": 18 } } }, "script":{ "source":"ctx._source['age']++;ctx._source['sex']='男';" }}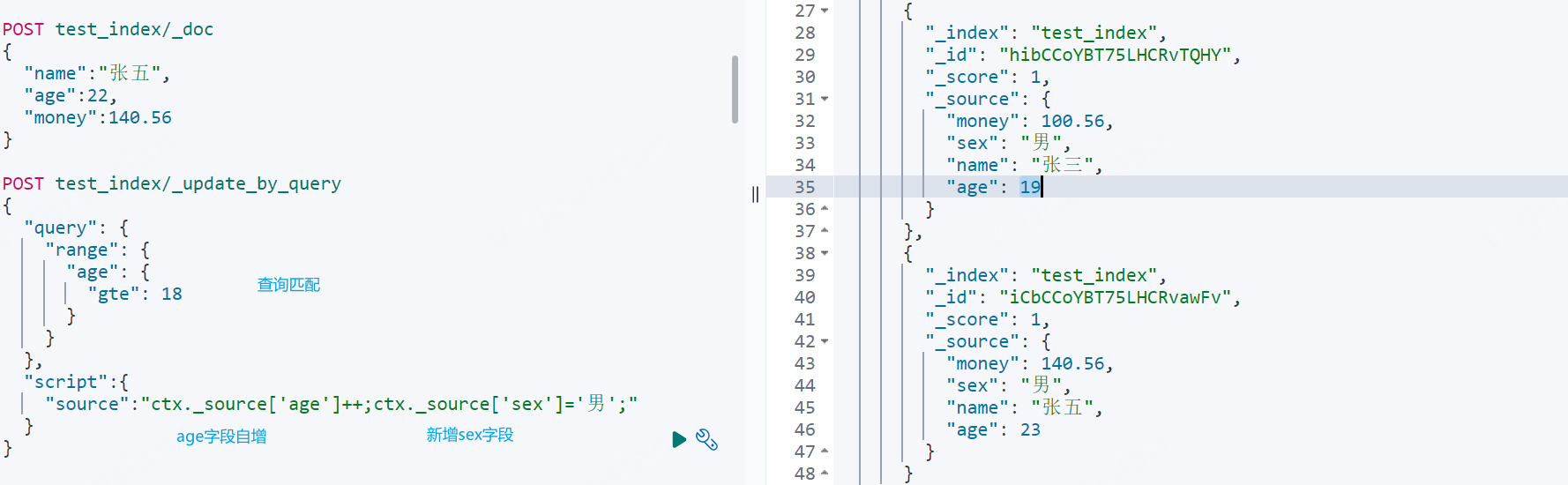
删除文档
可以根据文档id进行删除
xxxxxxxxxx# 根据文档Id进行删除DELETE test_index/_doc/piYYFoYBT75LHCRvdQFk
也可以通过条件进行删除,_delete_by_query
xxxxxxxxxx# 查询age>=18的文档记录POST test_index/_search{ "query": { "range": { "age": { "gte": 18 } } }}
# 删除age>=18的文档记录POST test_index/_delete_by_query{ "query":{ "range":{ "age":{ "gte":18 } } }}
# 多线程并发删除POST test_index/_delete_by_query?slices=auto&conflicts=proceed&wait_for_completion=false{ #}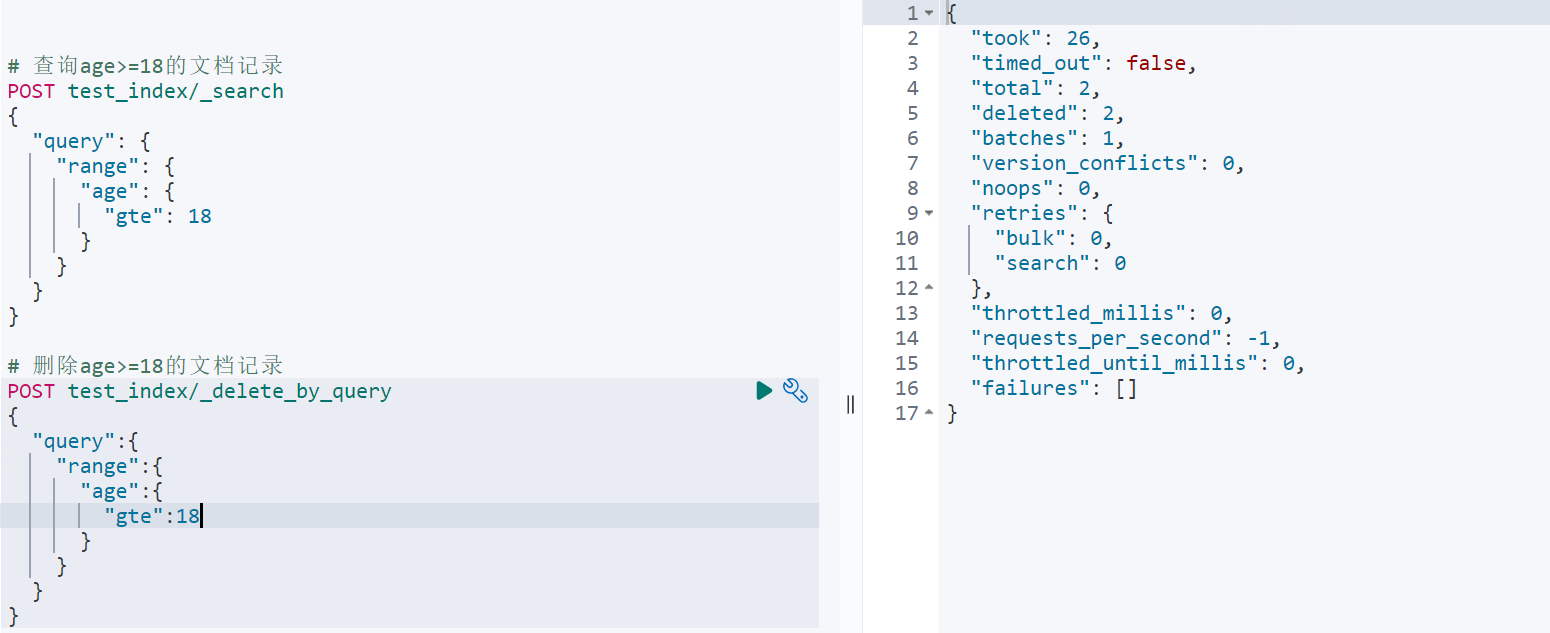
简单查询
在已知文档ID的情况,我们可以根据ID查询数据
xxxxxxxxxxPOST test_index/_doc/1{ "name":"张三", "age":18}# 根据id查询数据GET test_index/_doc/1
我们还可以进行查询、排序、分页,不过这种方式有很大的局限性,而且也不安全(GET请求),不推荐使用
xxxxxxxxxxPOST test_index/_doc{ "name":"张三", "age":18}
POST test_index/_doc{ "name":"李四", "age":88}
# 字符串则是包含查找GET test_index/_search?q=name:三
# 数值则是等于GET test_index/_search?q=age:18
# 数值范围 TO 必须大写,不适用于字符串GET test_index/_search?q=age:[1 TO 20]
# 数值比较GET test_index/_search?q=age:>18
# 排序 正序:asc 倒序descGET test_index/_search?sort=age:desc
# 分页GET test_index/_search?q=age:>=18&from=0&size=1GET test_index/_search?q=age:>=18&from=1&size=1
# 查找全部GET test_index/_search高级查询DSL
数据准备
xxxxxxxxxxDELETE test_indexPUT test_index
POST test_index/_doc{ "name":"张三", "ename":"ZhangSan", "email":"ZhangSan@gmail.com", "age":18, "province":"广东省", "address":"深圳市宝安区xxx路", "tel":"12365478541", "money": 14856324.25, "date":1643685660}
POST test_index/_doc{ "name":"李四", "ename":"LiSi", "email":"LiSi@outlook.com", "age":88, "province":"江苏省", "address":"南京市xx区xxx路", "tel":"19841478541", "money":14854.25, "date":1669864860}
POST test_index/_doc{ "name":"张小五", "ename":"ZhangXiaoWu", "email":"ZhangXiaoWu@qq.com", "age":28, "province":"浙江省", "address":"杭州市xx区xxx路", "tel":"19814528541", "money":14.25, "date":1671592860}
POST test_index/_doc{ "name":"赵六", "ename":"ZhaoLiu", "email":"ZhaoLiu@163.com", "age":8, "province":"广东省", "address":"广州市天河区xxx路", "tel":"19813215541", "money":99914.25, "date":1671556860}
POST test_index/_doc{ "name":"唐小王", "ename":"TangXiaoWang", "email":"TangXiaoWang@gmail.com", "age":48, "province":"广东省", "address":"广州市花都区xxx路", "tel":"12453215541", "money":9914.25, "date":1671815520}match_all
不需要写任何条件
xxxxxxxxxx# 查看所有数据 POST test_index/_search{ "query": { "match_all": {} }}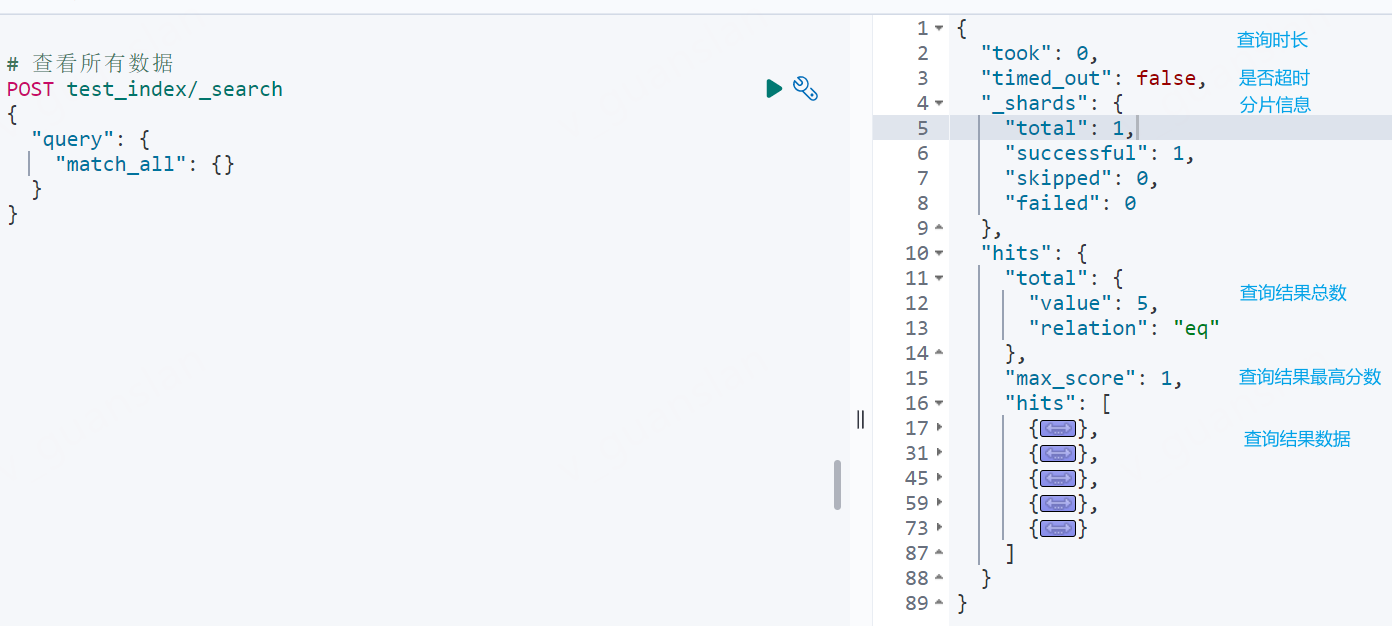
term
term精确值匹配,常用的查询,可以用它处理数字(numbers)、布尔值(Booleans)、日期(dates)以及文本(text)。term作为精确查询不会将搜索词进行分词,直接将整个搜索词与倒排索引的内容进行匹配
xxxxxxxxxxPOST test_index/_search{ "query": { "term": { "age": { "value": 8 } } }}
POST test_index/_search{ "query": { "term": { "name": { "value": "张小五" } } }}
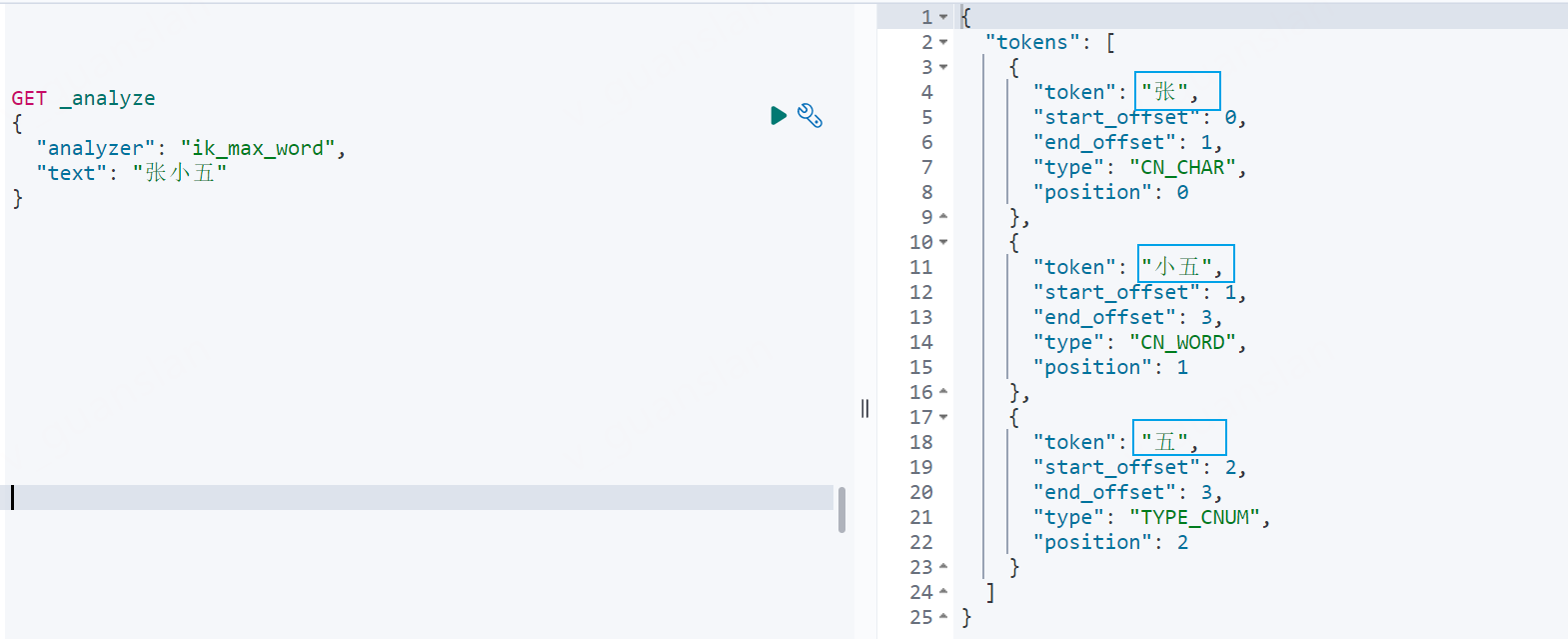
POST test_index/_search{ "query": { "term": { "name": { "value": "五" } } }}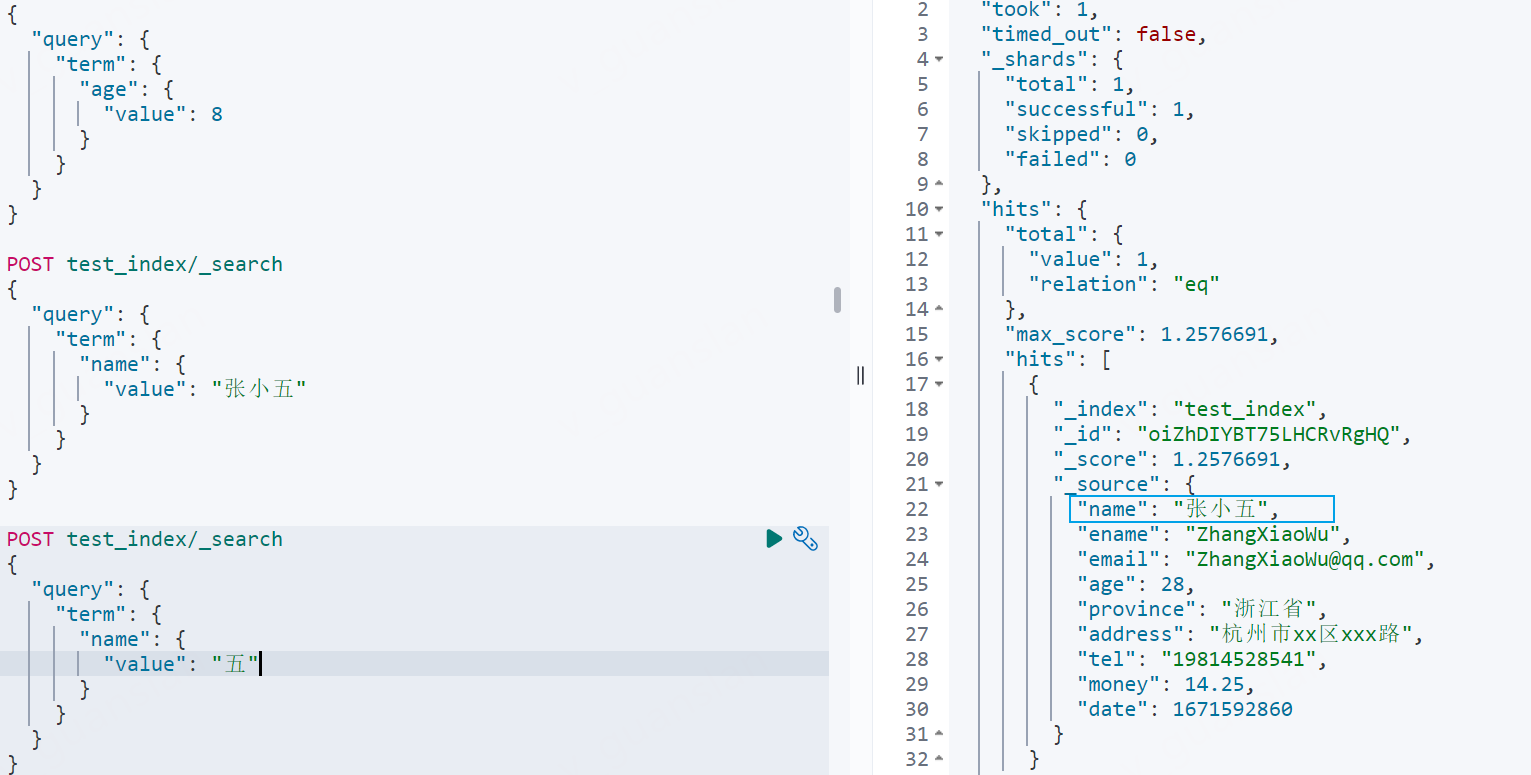
这两个term查询,查询"张小五"的时候,是没有结果的,而查询“五”却可以出现结果。原因是因为name字段没有指定keyword类型时,默认为text类型,当我们插入"张小五",分词器会将这段文本进行分词后插入倒排索引中。如下图"张小五"被分为"张"、"小五"、"五",当我们使用term查询"张小五"时自然查不到,因为term不会将搜索词进行分词。
terms
terms和term类似,支持多个匹配项查询
xxxxxxxxxx# 查询province包含浙、广POST test_index/_search{ "query": { "terms": { "province": [ "浙", "广" ] } }}# 查询age等于8、28、38POST test_index/_search{ "query": { "terms": { "age": [ 8, 28, 38 ] } }}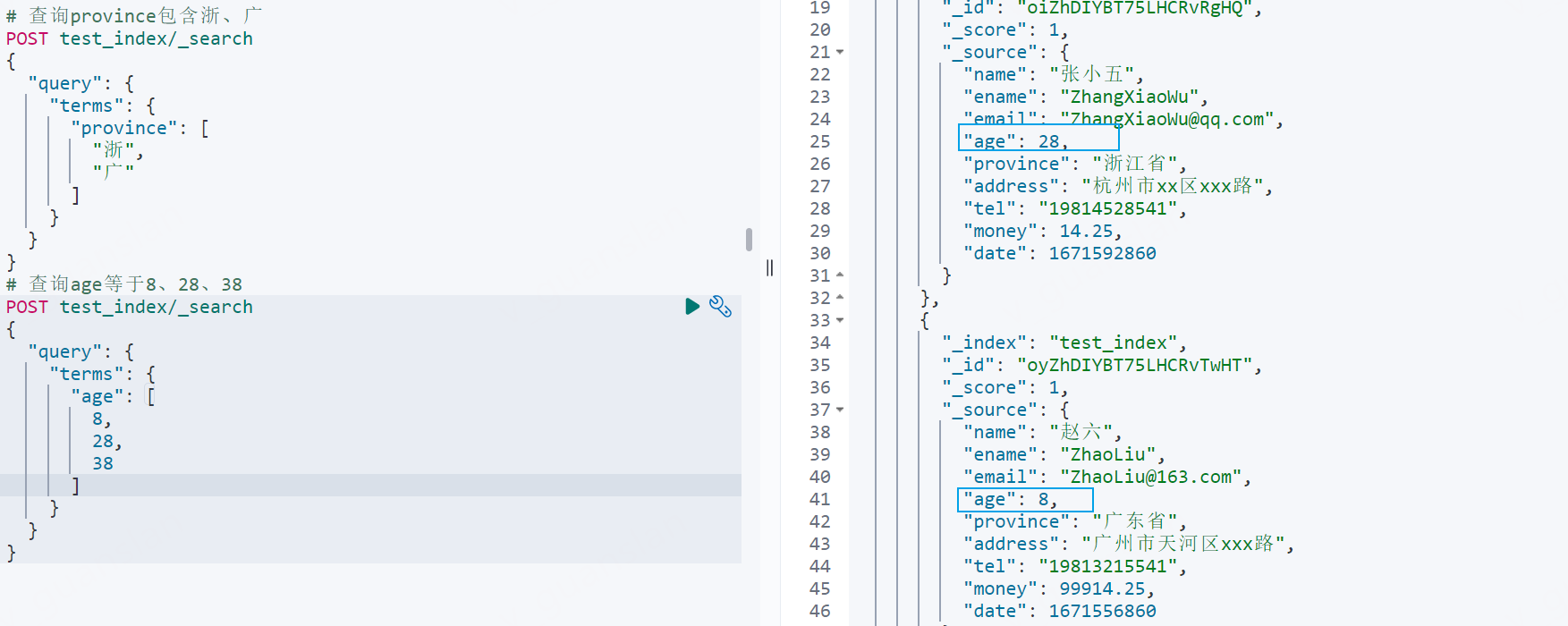
match
match查询比较强大,与term不同的是,如果查询的字段是分词的match查询会把搜索词进行分词后再与索引内容做匹配,如果该字段是不分词的就将查询条件作为整体进行查询
xxxxxxxxxx# 数据中没有广西,但是我们搜索广西也是能出数据的# 先搜索"广"是有数据的,在搜索"西"虽然没有数据,但可以把两次搜索结果结合# 默认类似于 operator的or操作POST test_index/_search{ "query": { "match": { "province": "广西" } }}
# 无法查询到数据,因为要同时满足搜索"广"、"西"都有数据才可以POST test_index/_search{ "query": { "match": { "province": { "query": "广西", "operator": "and" } } }}
POST test_index/_search{ "query": { "match": { "age": 18 } }}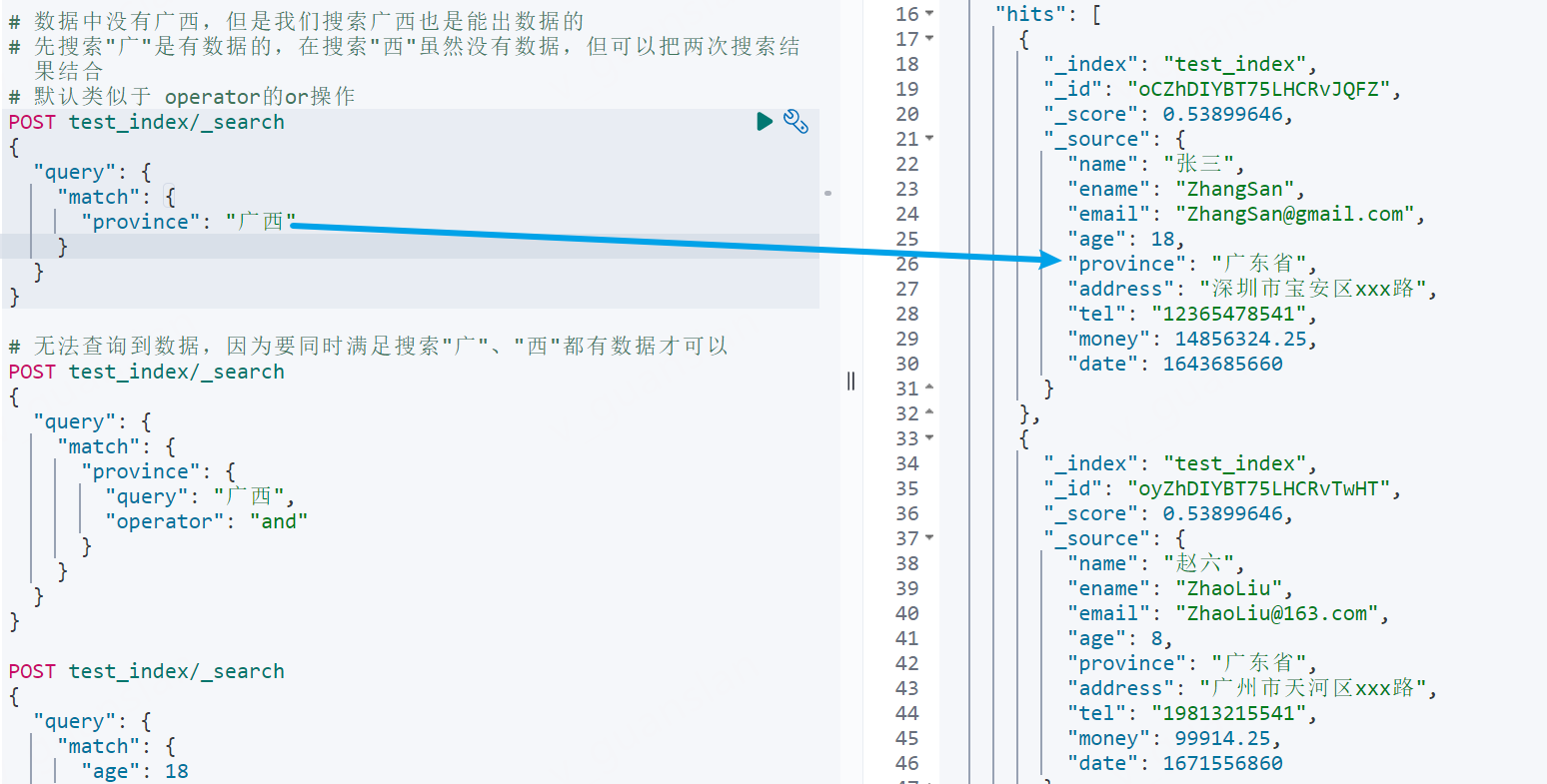
multi_match
与match类似,multi_match可以指定多个字段查询,只要有一个字段匹配搜索条件即可
xxxxxxxxxx# 在province、address字段中查找"江苏深圳"POST test_index/_search{ "query": { "multi_match": { "query": "江苏深圳", "fields": ["province","address"] } }}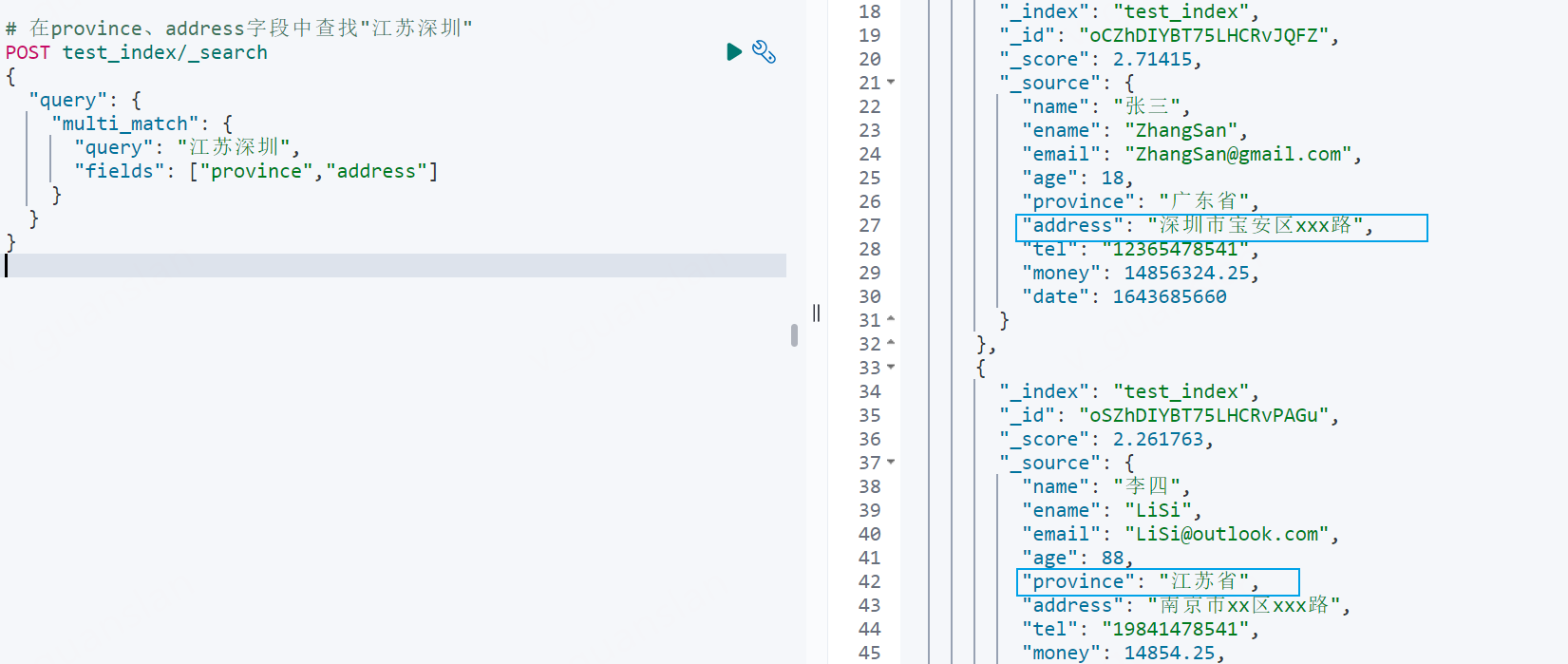
match_phrase
短语匹配,他会将给定的短语(phrase)当成一个完整的查询条件,他不会进行分词,而且要完整匹配查询条件
xxxxxxxxxx# 在address字段中查找"深圳市"这个短语,完整匹配这个短语才会视为搜索结果POST test_index/_search{ "query": { "match_phrase": { "address": "深圳市" } }}
# 在address字段中查找"深圳市",深圳市会被进行分词后才会查找,所以这个会出现很多搜索结果POST test_index/_search{ "query": { "match": { "address": "深圳市" } }}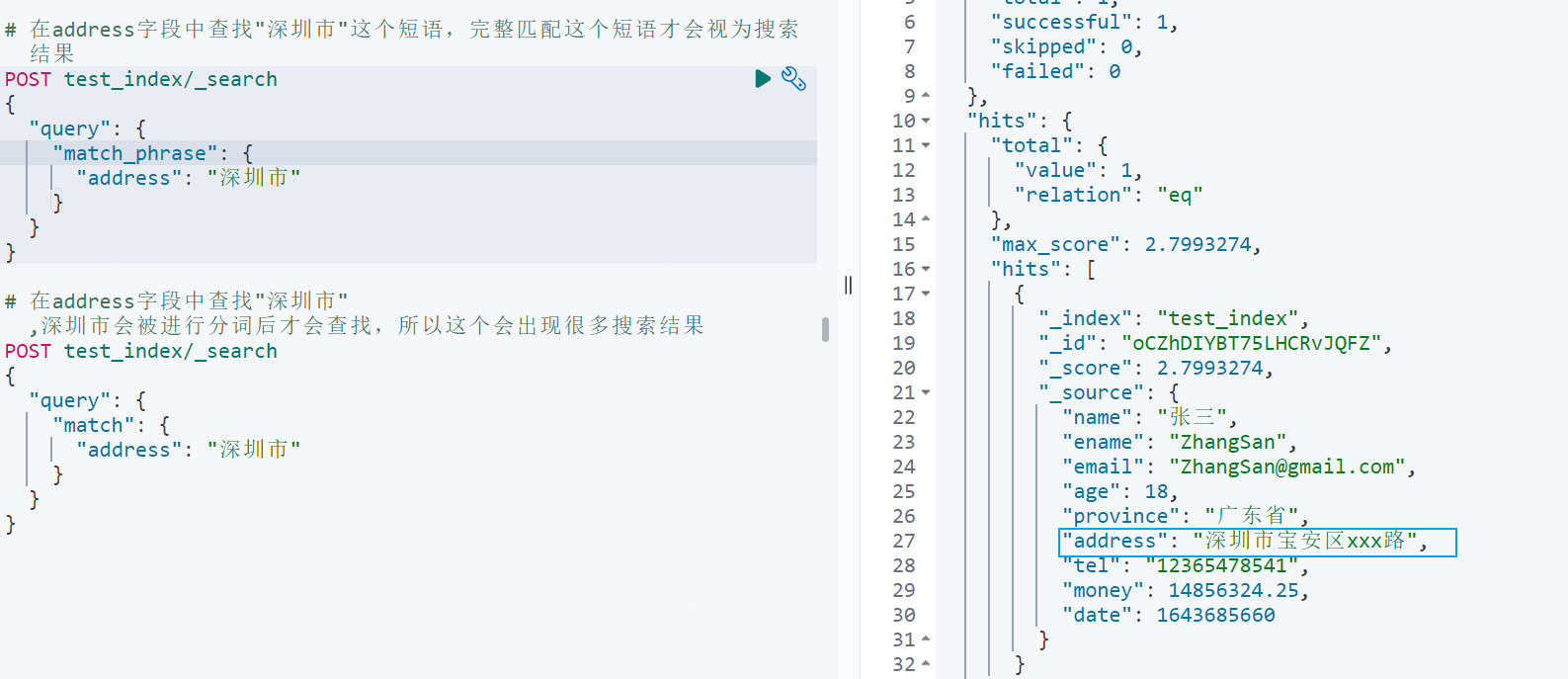
ids
多id查询
xxxxxxxxxx# 根据多个id进行查询POST test_index/_search{ "query": { "ids":{ "values": ["oCZhDIYBT75LHCRvJQFZ","oSZhDIYBT75LHCRvPAGu"] } }}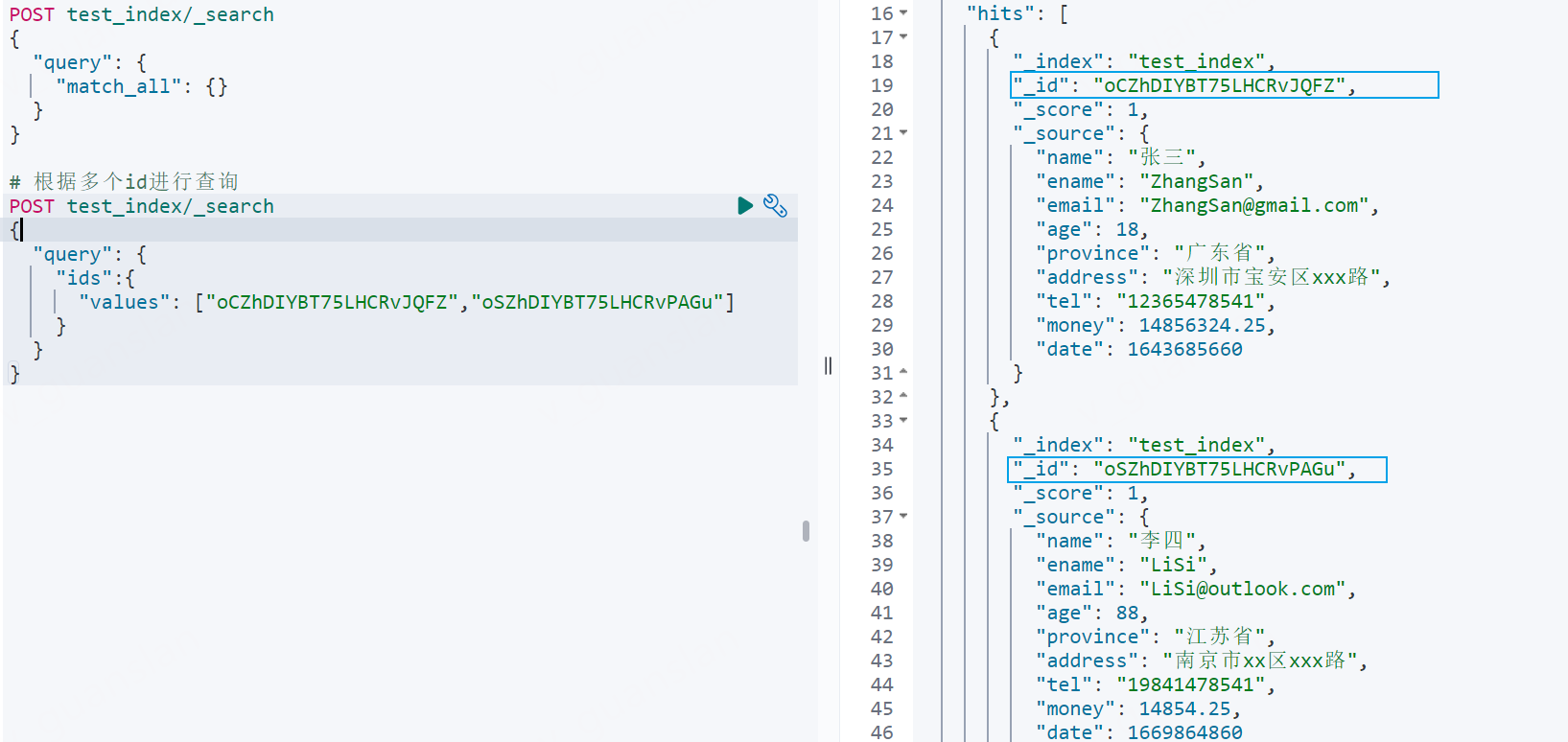
range
范围查询,通常用于查询数值、时间
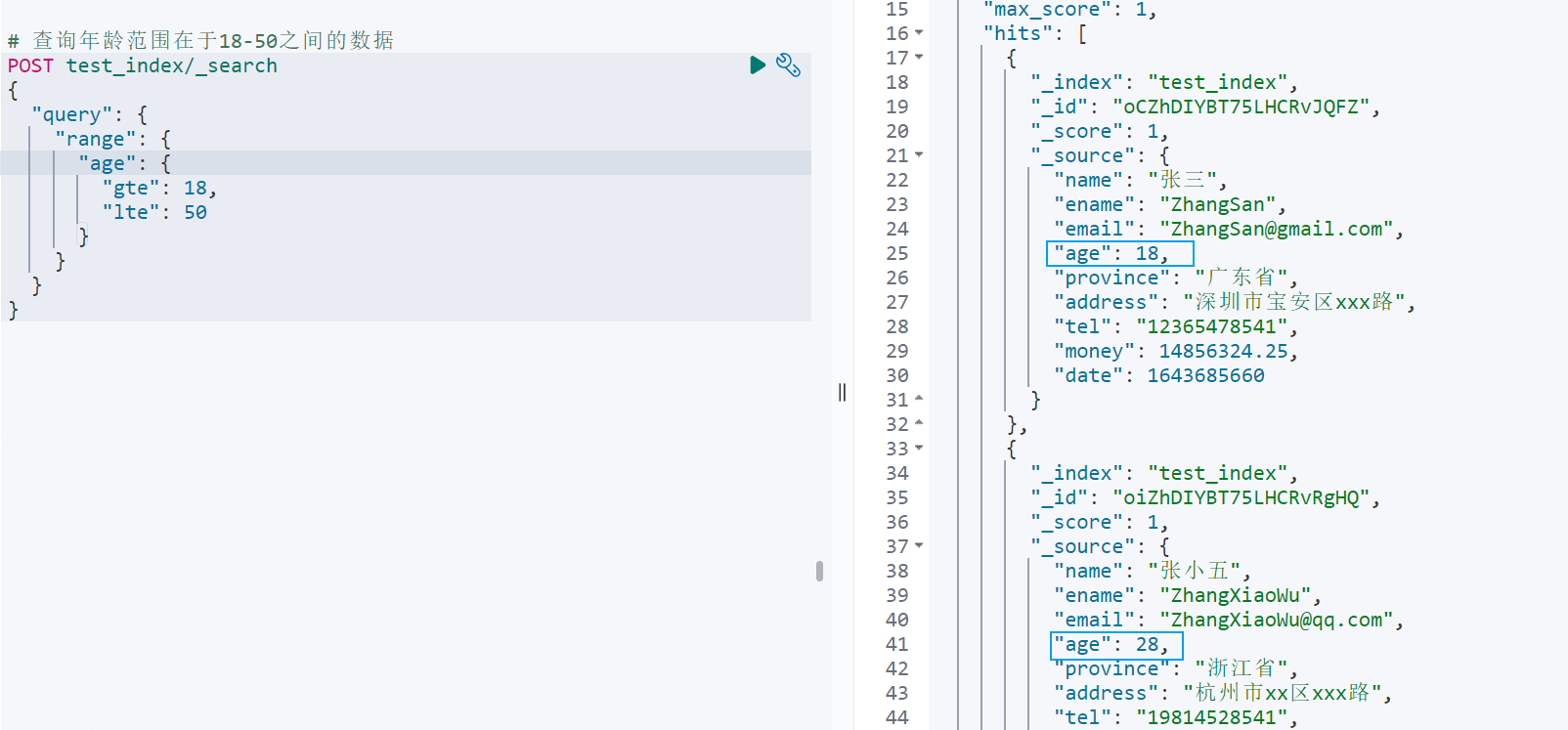
xxxxxxxxxx# 查询年龄范围在于18-50之间的数据POST test_index/_search{ "query": { "range": { "age": { "gte": 18, "lte": 50 } } }}
exist
查看包含某字段的数据
xxxxxxxxxx# 查找包含tel字段的数据POST test_index/_search{ "query": { "exists": { "field": "tel" } }}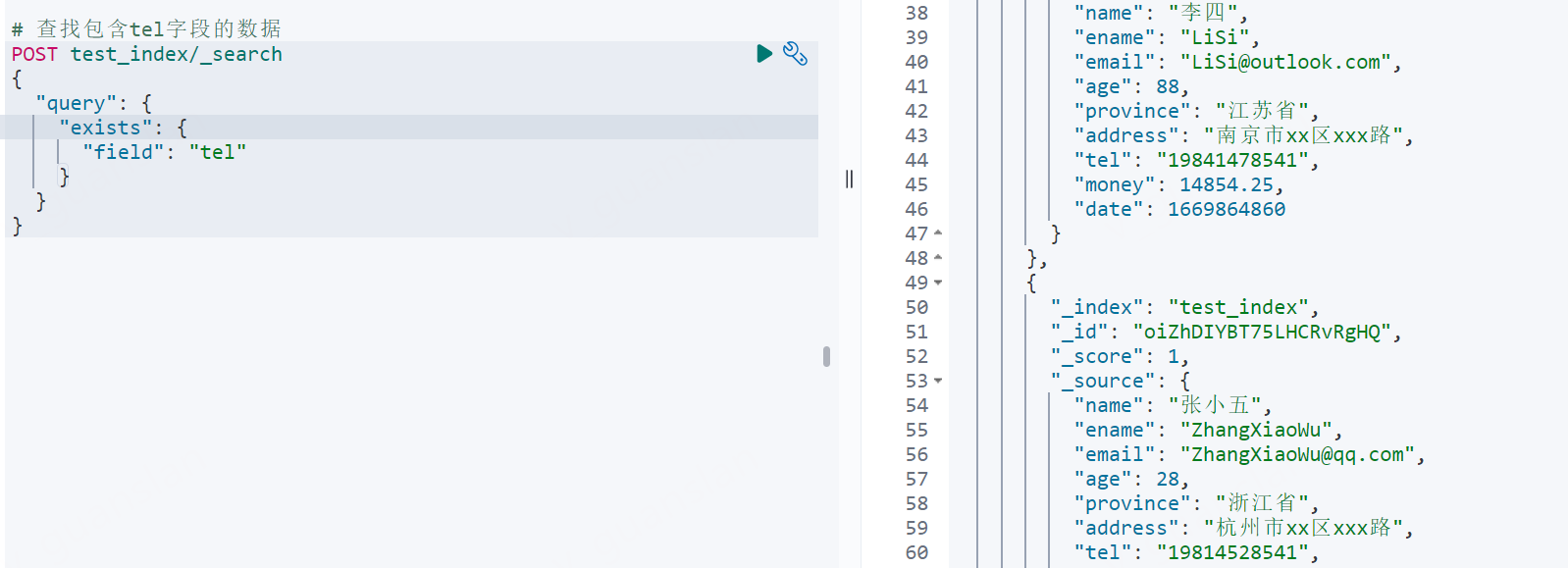
bool
布尔查询,用来组合多个条件实现复杂查询,常与must(且)、should(或)、must_not(非)、filter(过滤)一起出现,而且这些关键词都可以指定多个条件
xxxxxxxxxx# must:年龄大于等于18# should:email包含gmail或者地址包含南京# must_not:不允许money小于等于200且不允许province为广东POST test_index/_search{ "query": { "bool": { "must": [ { "range": { "age": { "gte": 18 } } } ], "should": [ { "term": { "email": { "value": "gmail" } } }, { "match": { "address": "南京" } } ], "must_not": [ { "range": { "money": { "lte": 200 } } }, { "match": { "province": "广东" } } ] } }}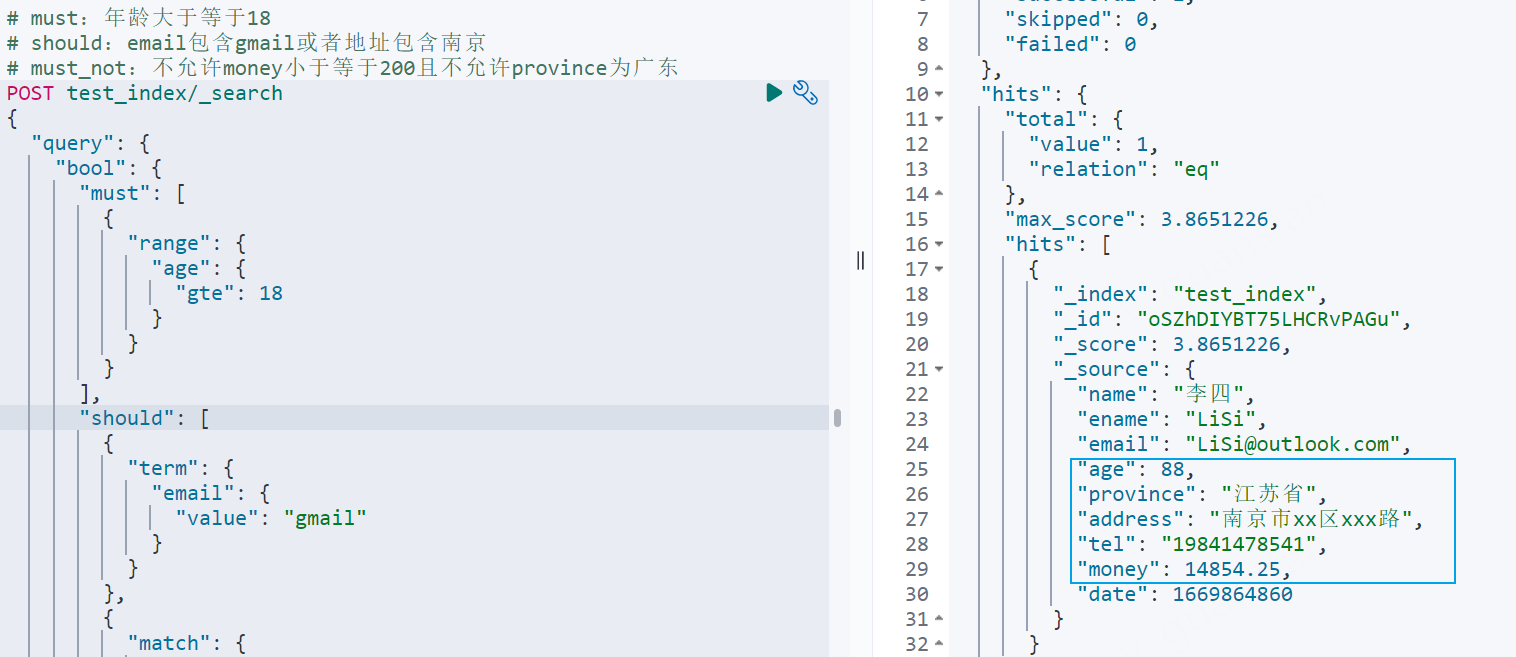
prefix
前缀查询,keyword类型前缀是可以查询得到的,text类型如果搜索词是英文也是可以查询的,如果是中文,单字也是可以查询的,多字就无法查询了
xxxxxxxxxx# text类型查找可以查得到POST test_index/_search{ "query": { "prefix": { "address": { "value": "京" } } }}
# text类型查找中文,不可以查到POST test_index/_search{ "query": { "prefix": { "address": { "value": "南京市" } } }}
# text类型查找英文,可以查得到POST test_index/_search{ "query": { "prefix": { "email": { "value": "outlook" } } }}
# keyword类型查找可以查得到,有些词又找不到POST test_index/_search{ "query": { "prefix": { "address.keyword": { "value": "南京市" } } }}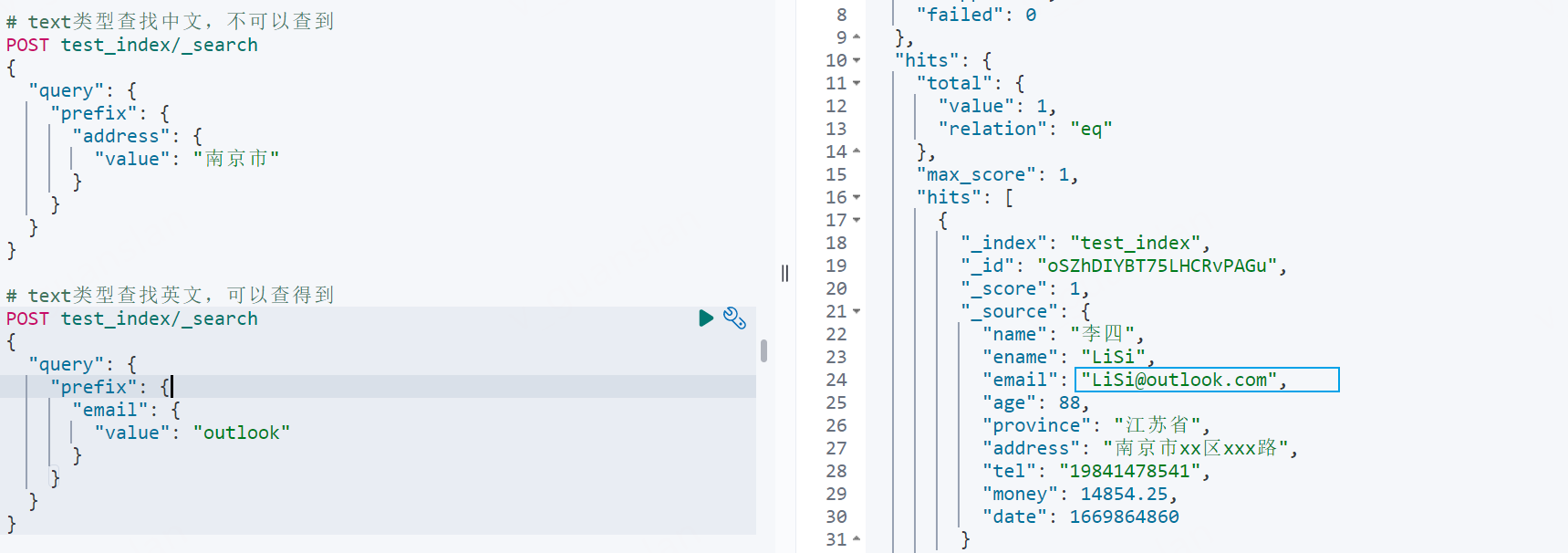
wildcard
通配符查询,?用来匹配任意一个字符,*用来匹配任意多个字符
xxxxxxxxxx# 无法匹配结果,不知道为啥中文匹配一直没有结果,分词器的原因吗POST test_index/_search{ "query": { "wildcard": { "address": { "value": "广?" } } }}
POST test_index/_search{ "query": { "wildcard": { "address": { "value": "南*" } } }}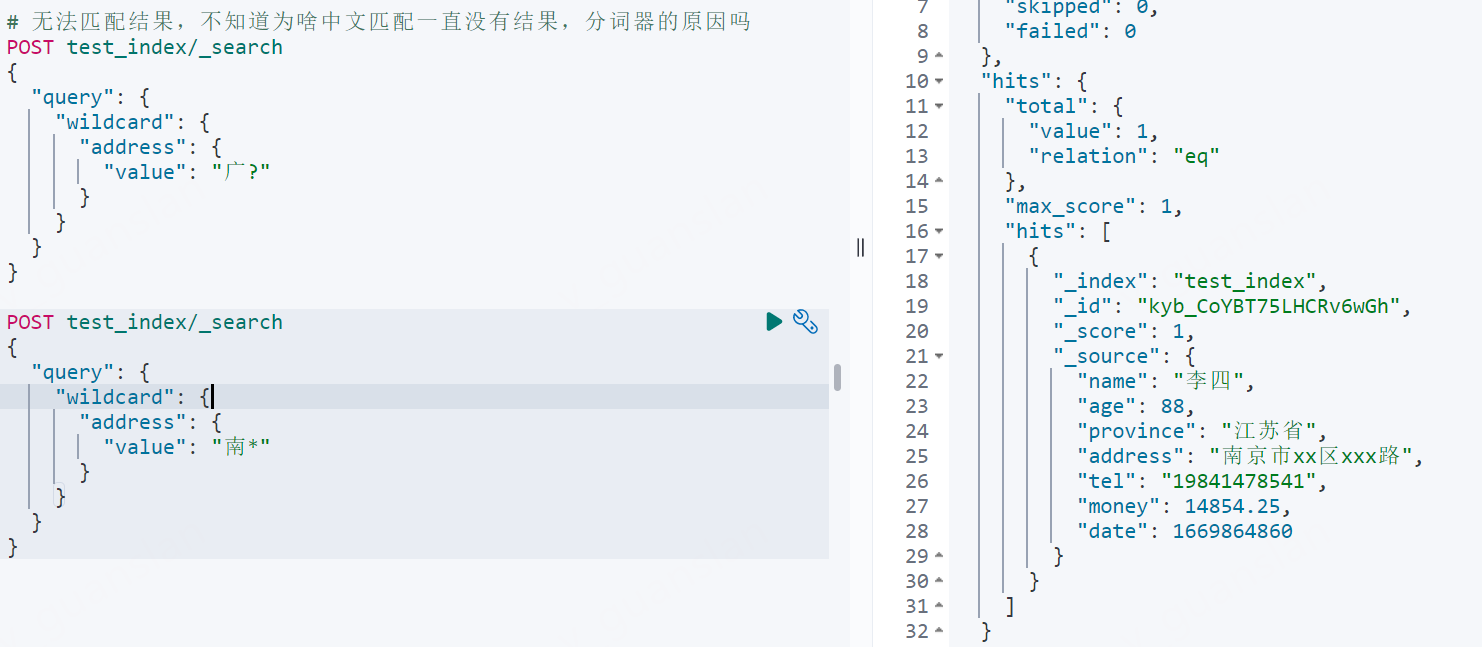
fuzzy
模糊查询,用于模糊查询指定关键词的文档,可容忍搜索词错误,最大模糊必须在0-2之间
- 搜索关键词长度为2不允许存在模糊
- 搜索关键词长度为3~5允许一次模糊
- 搜索关键词长度大于5最大2次模糊
xxxxxxxxxx# 可以模糊查询POST test_index/_search{ "query": { "fuzzy": { "email": "lisa" } }}
# 有些词无法查询POST test_index/_search{ "query": { "fuzzy": { "email": "Lisa" } }}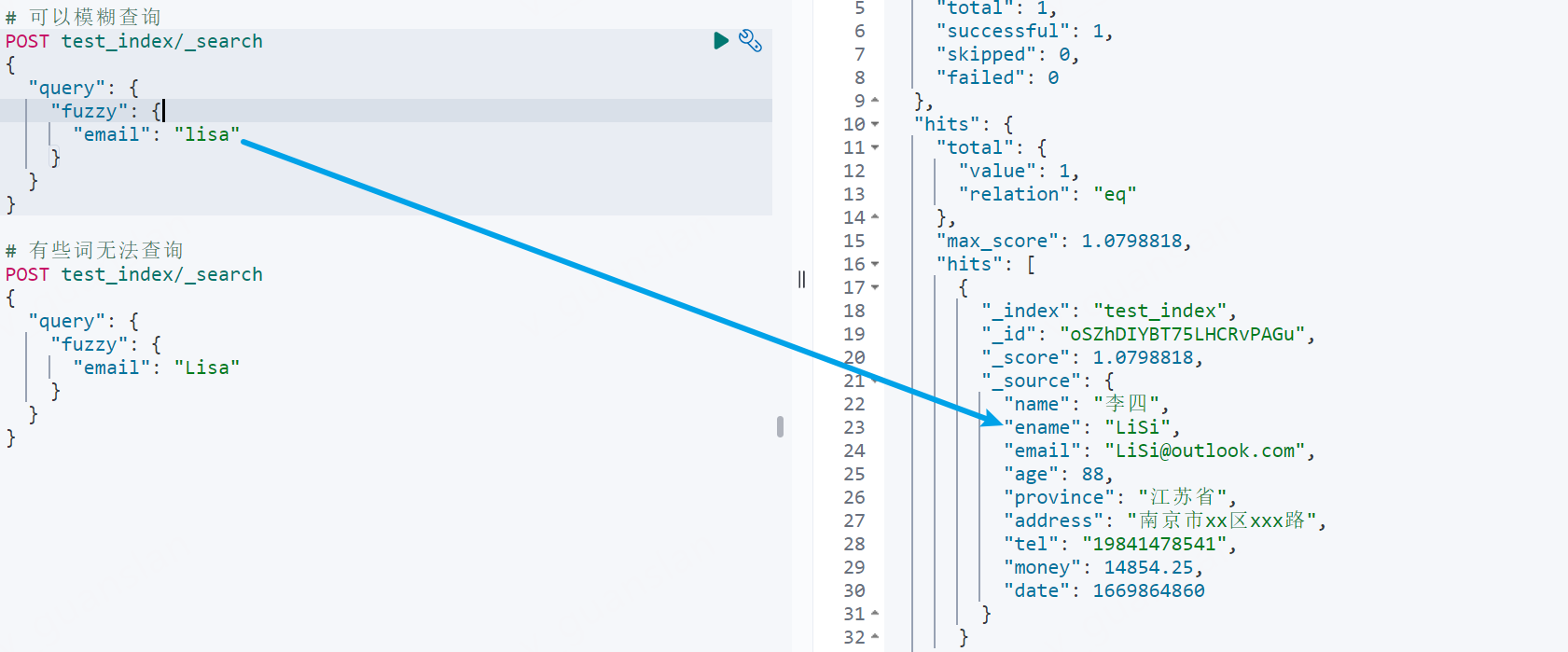
regexp
正则匹配查询,正则应该要能匹配整个文本,查询中文时,要注意分词
xxxxxxxxxx# 无法查询,中文分词没有广东POST test_index/_search{ "query": { "regexp": { "province": "广东.*" } }}# 可以查询POST test_index/_search{ "query": { "regexp": { "province": "[广东].*" } }}# 无法查询,正则应该要能匹配整个文本POST test_index/_search{ "query": { "regexp": { "email": ".*gmail" } }}
# 可以查询POST test_index/_search{ "query": { "regexp": { "email": ".*gmail.*" } }}
注意事项
prefix、wildcard、fuzzy、regexp性能较低,不推荐使用,而且对中文查询时总是会出现意想不到的结果——期望能查询的却总是查不到数据
了解term查询机制,尤其是中文
分页查询
关键词:from、size
xxxxxxxxxx# 第一页、from=(1-1)*size,每页数量:2POST test_index/_search{ "query": { "match_all": {} }, "from": 0, "size": 2}
# 第二页、from=(2-1)*size,每页数量:2POST test_index/_search{ "query": { "match_all": {} }, "from": 2, "size": 2}
# 第三页、from=(3-1)*size,每页数量:2POST test_index/_search{ "query": { "match_all": {} }, "from": 4, "size": 2}
scroll分页查询
ES系列十二、ES的scroll Api及分页实例 - 小人物的奋斗 - 博客园 (cnblogs.com)
分页查询from越大,查询效率就越低,这是我们可以使用scroll分页查询检索体积大量(甚至全部)结果,这与传统数据库中使用游标的方式非常相似
scroll不要用于实时请求,主要用于大数据量的场景
初次请求,指定scroll和size,scroll=1m表示使用scroll查询,并且缓存1分钟,这个时间不用设置太久,每个 scroll 请求都会设置一个新的过期时间。初次请求会得到一个scroll_id,后续会用到
xxxxxxxxxx# 初次scroll请求,获得scroll_idPOST test_index/_search?scroll=1m{ "size": 1, "query": { "match_all": {} }}
根据scroll_id进行请求,获得数据
xxxxxxxxxx# 根据scroll_id获得后续的数据,直至取完POST _search/scroll{ "scroll":"1m", "scroll_id":"FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFnVQc1JlT2l6UUVtQUtVejE0RDk2bUEAAAAAAAOyHhZlRm5kVnN6OFMyYWFDT2xVTzNIZGl3"}
当超过scroll的设置的过期时间,scroll上下文会被自动删除,但是scroll不会删除,所以当我们处理完数据,需要手动删除scroll
xxxxxxxxxx# 根据scroll_id删除scrollDELETE _search/scroll/FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFnVQc1JlT2l6UUVtQUtVejE0RDk2bUEAAAAAAAOyHhZlRm5kVnN6OFMyYWFDT2xVTzNIZGl3
# 根据多个scroll_id删除scrollDELETE _search/scroll/id1,id2
# 删除全部scrollDELETE _search/scroll/_all
排序字段
关键词:sort
正序:asc、倒序:desc,可指定多个字段排序
xxxxxxxxxx# 先按age字段倒序排序age相同则再按money正序排序POST test_index/_search{ "query": { "match_all": {} }, "sort": [ { "age": { "order": "desc" } }, { "money": { "order": "asc" } } ]}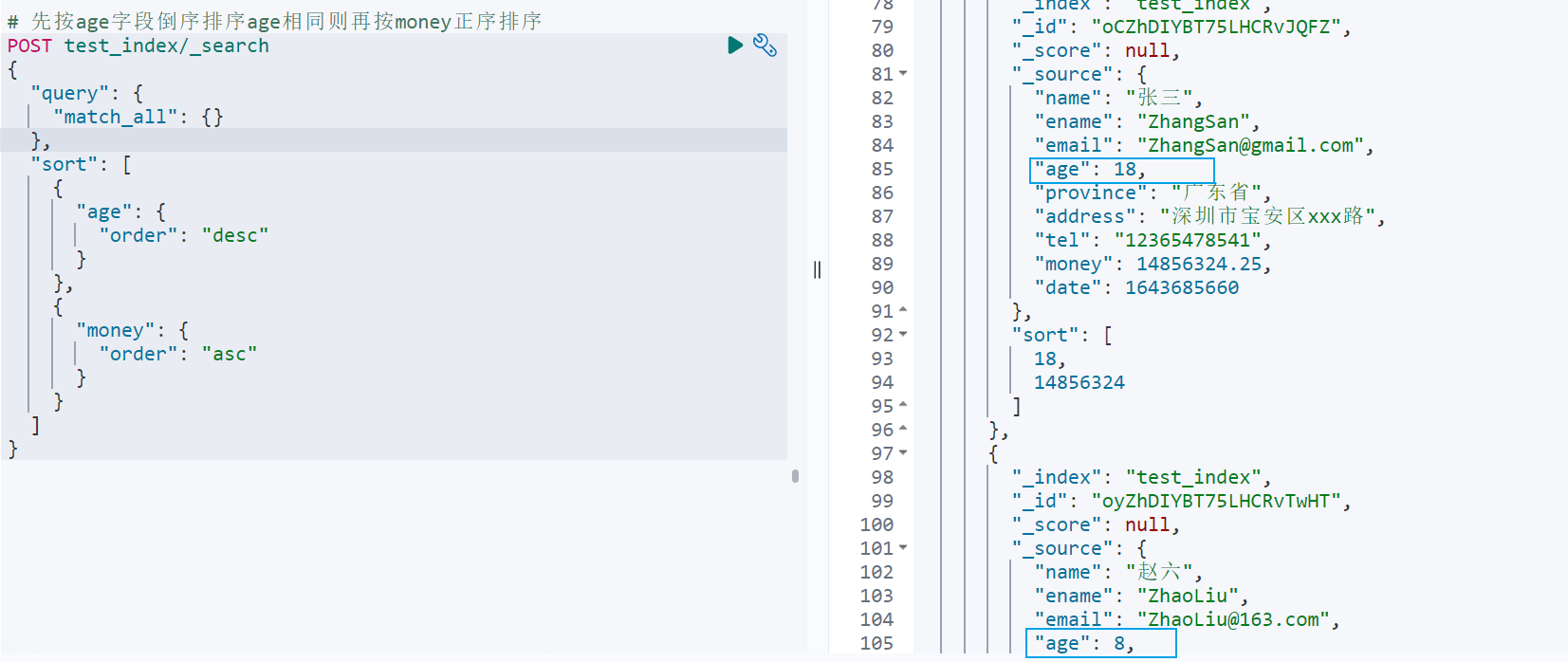
指定字段查询
关键词:_source,可以通过includes来指定查看哪几个字段,也可以通过excludes指定不查看哪几个字段
xxxxxxxxxx# 简写,仅查看name、age字段POST test_index/_search{ "query": { "match_all": {} }, "_source": ["name","age"]}
# includes:仅查看name、age字段POST test_index/_search{ "query": { "match_all": {} }, "_source": { "includes": ["name","age"] }}
# excludes:不查看name、age字段POST test_index/_search{ "query": { "match_all": {} }, "_source": { "excludes": ["name","age"] }}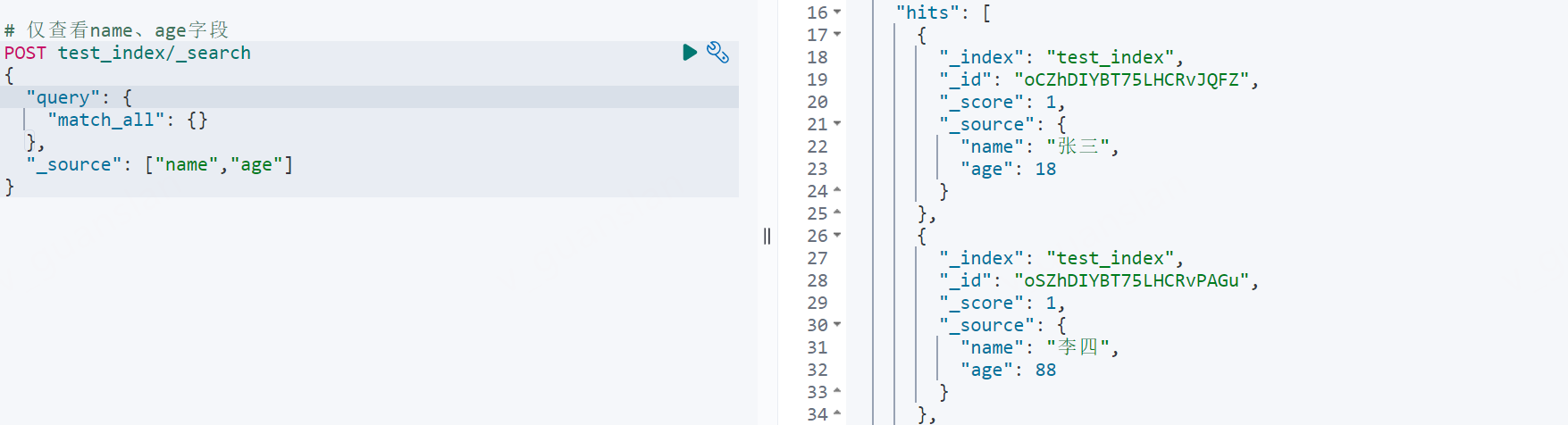
高亮查询
关键词:highlight,通过pre_tags设置前缀,post_tags设置后缀来达成高亮效果
xxxxxxxxxx# 简单高亮查询POST test_index/_search{ "query": { "match": { "name": "张五" } }, "highlight": { "fields": { "name": { "pre_tags": "<span style='color:red;'>", "post_tags": "<span/>" } } }}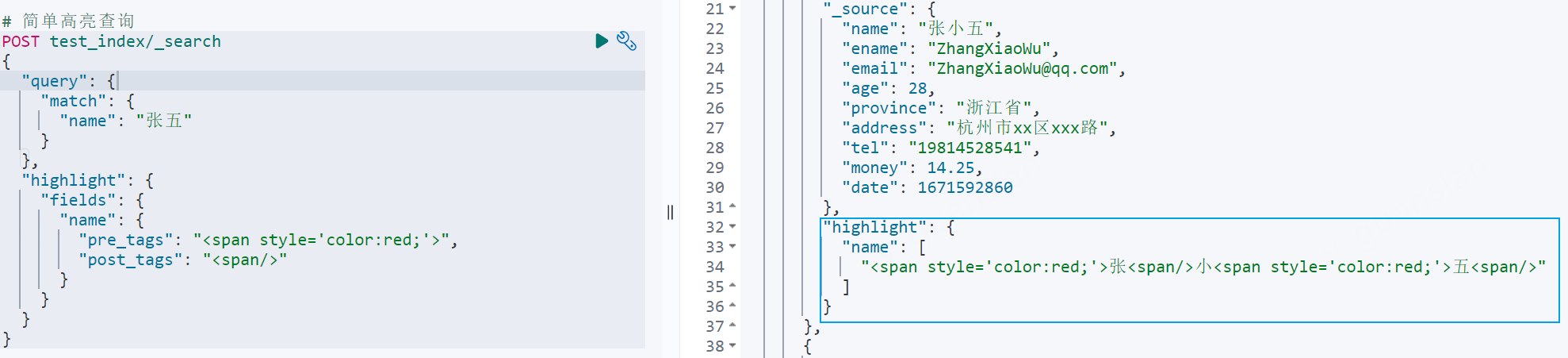
过滤查询
常与布尔查询一起使用,es查询会按匹配程度计算分数,并默认按分数从高到低排序查询结果,而过滤不会计算分数、也不会自动按分数排序只会进行过滤操作而已,而且过滤有一定的缓存效果,在效率上过滤会优于查询,所以建议查询大数据时,可以先进行过滤(filter)再进行查询(query),常见的过滤操作有:term、terms、range、exists、ids
xxxxxxxxxx# 仅过滤,没有分数POST test_index/_search{ "query": { "bool": { "filter": [ { "term": { "province": "东" } } ] } }}
# 过滤后再查询,有分数,filter总是优先执行,无关代码顺序POST test_index/_search{ "query": { "bool": { "must": [ { "match": { "name": "张三" } } ], "filter": [ { "term": { "province": "东" } } ] } }}
聚合查询
以下内容参考:ES系列十四、ES聚合分析(聚合分析简介、指标聚合、桶聚合) - 小人物的奋斗 - 博客园 (cnblogs.com)
类似于sql中的group by,语法
xxxxxxxxxx"query":{ ...},"aggs":{ #固定 "agg_name":{ #自己取名字 "agg_type":{ # 聚合类型 "field":"分组字段", # 指定字段 "script":"_source * 2", # 脚本操作 "missing":"设置缺省值" # 设置缺省值 } }},# 仅返回聚合结果不返回字段"size":0聚合查询—指标聚合
max、min、sum、avg
max、min、sum、avg分别求最大值、最小值、总和值、平均值
xxxxxxxxxx# 求age字段的最大值,并将值乘以2POST test_index/_search{ "size":0, "aggs": { "my_agg": { "max": { "field": "age", "script": { "source": "_value * 2" } } } }}# 求age字段的平均值POST test_index/_search{ "size":0, "aggs": { "my_agg": { "avg": { "field": "age" } } }}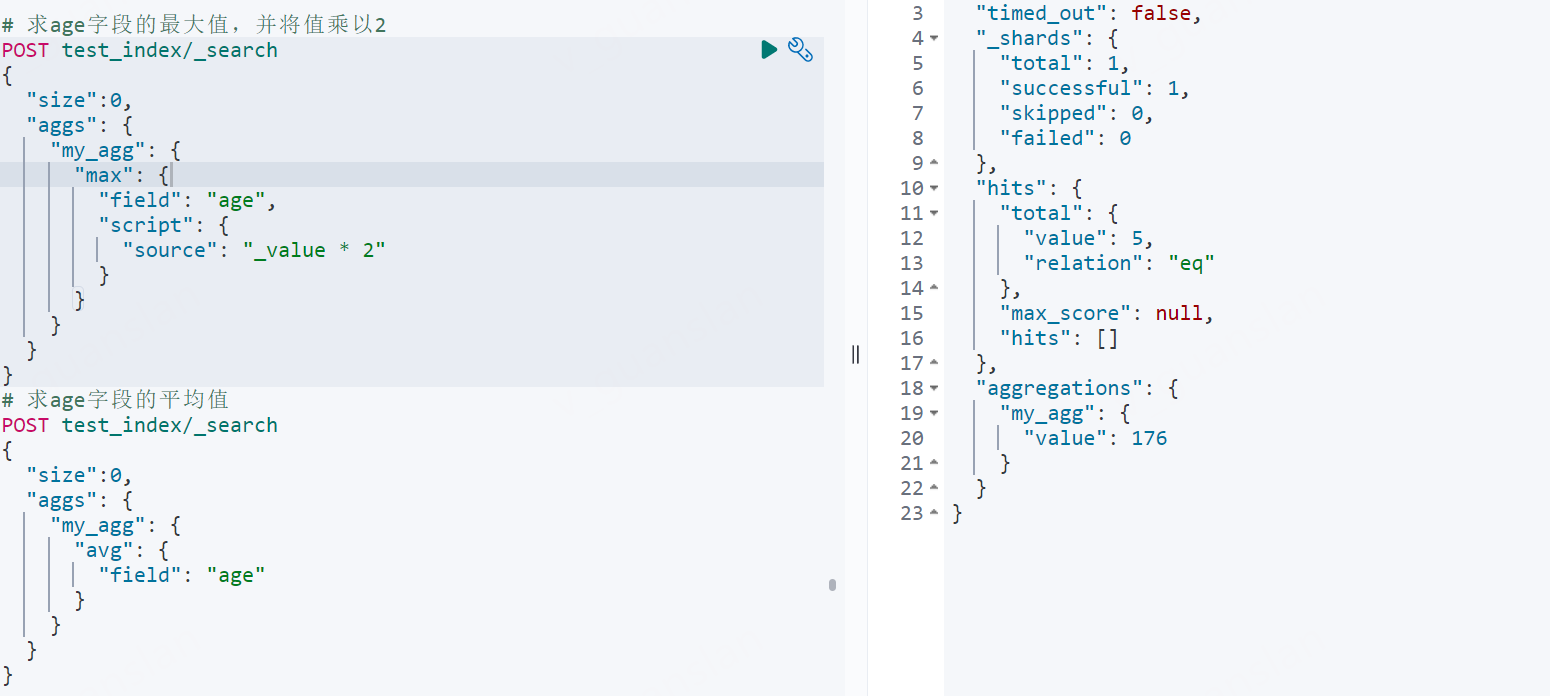
文档计数_count
xxxxxxxxxx# 文档计数POST test_index/_count{ "query": { "match": { "age": 18 } }}
统计某字段有值的文档数value_count
xxxxxxxxxx# 统计含有age字段且age有值的文档数POST test_index/_search{ "size": 0, "aggs": { "my_agg": { "value_count": { "field": "age" } } }}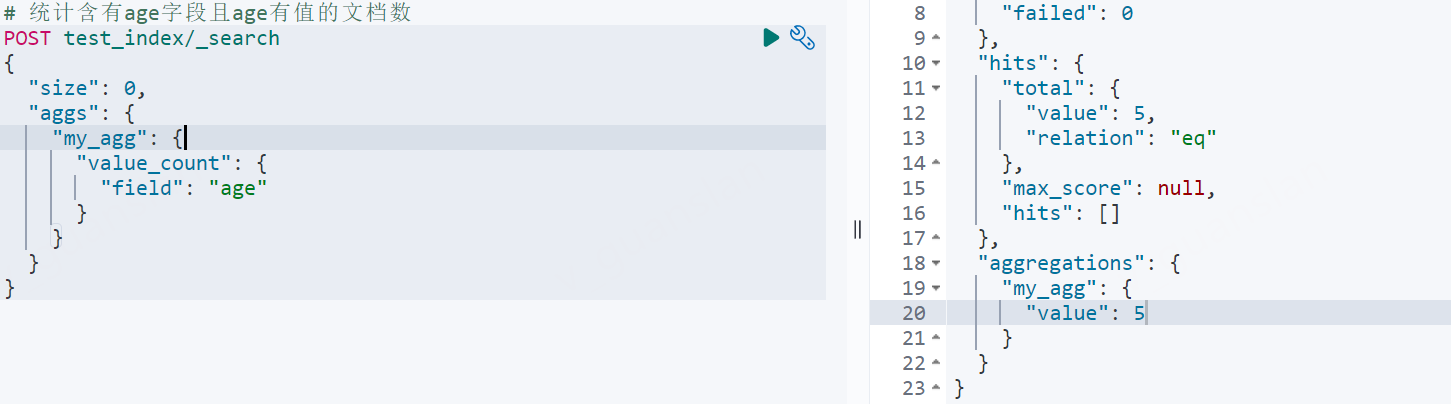
去重后计数cardinality
xxxxxxxxxx# 将age字段的值进行去重后计数POST test_index/_search{ "size": 0, "aggs": { "my_agg": { "cardinality": { "field": "age" } } }}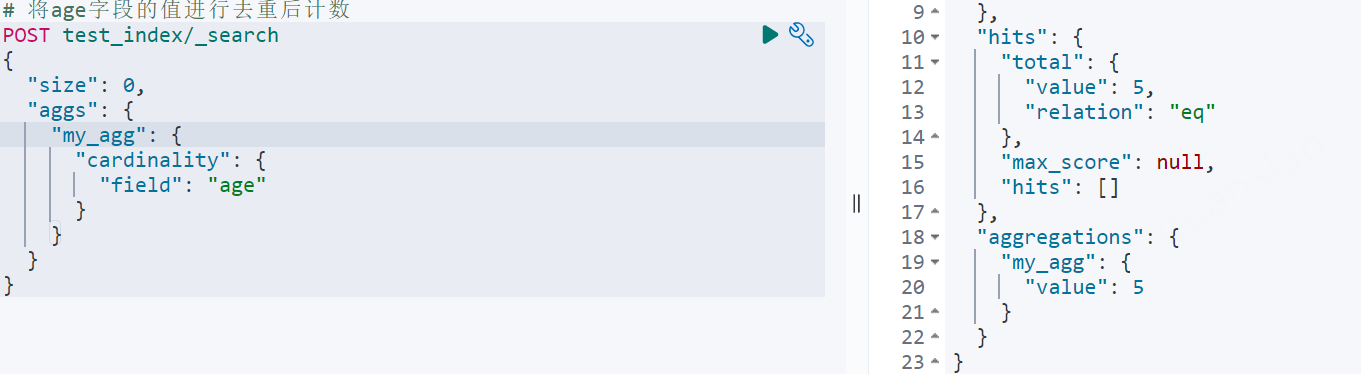
stats统计
一次性统计count、max、min、avg、sum这五个值
xxxxxxxxxx# stats统计count、min、max、avg、sumPOST test_index/_search{ "size": 0, "aggs": { "my_agg": { "stats": { "field": "age" } } }}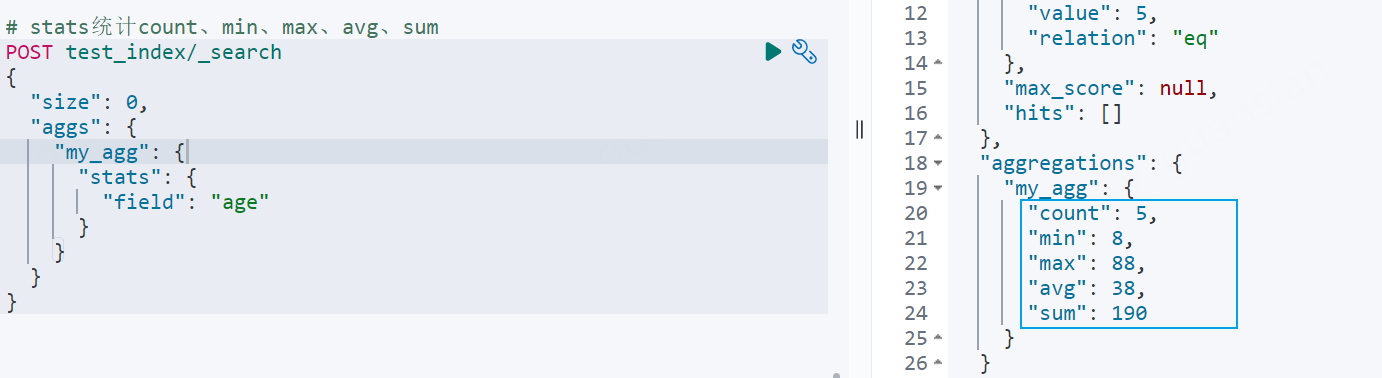
extended_stats统计
比stats额外统计平方和、方差、标准差、平均值加减两个标准差的区间
xxxxxxxxxxPOST test_index/_search{ "size": 0, "aggs": { "my_agg": { "extended_stats": { "field": "age" } } }}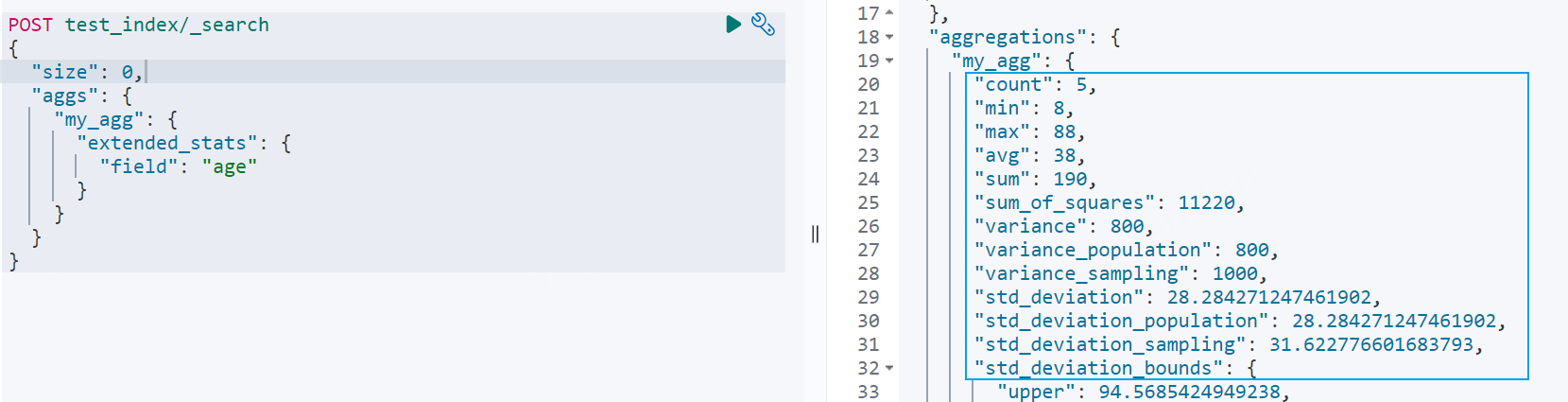
百分位统计percentiles
不知道是什么,不知道怎么个算法
可以自定义percents的值,不指定时默认为[1,5,25,50,75,95,99]
xxxxxxxxxxPOST test_index/_search{ "size": 0, "aggs": { "my_agg": { "percentiles": { "field": "age", "percents": [ 1, 5, 25, 50, 75, 95, 99 ] } } }}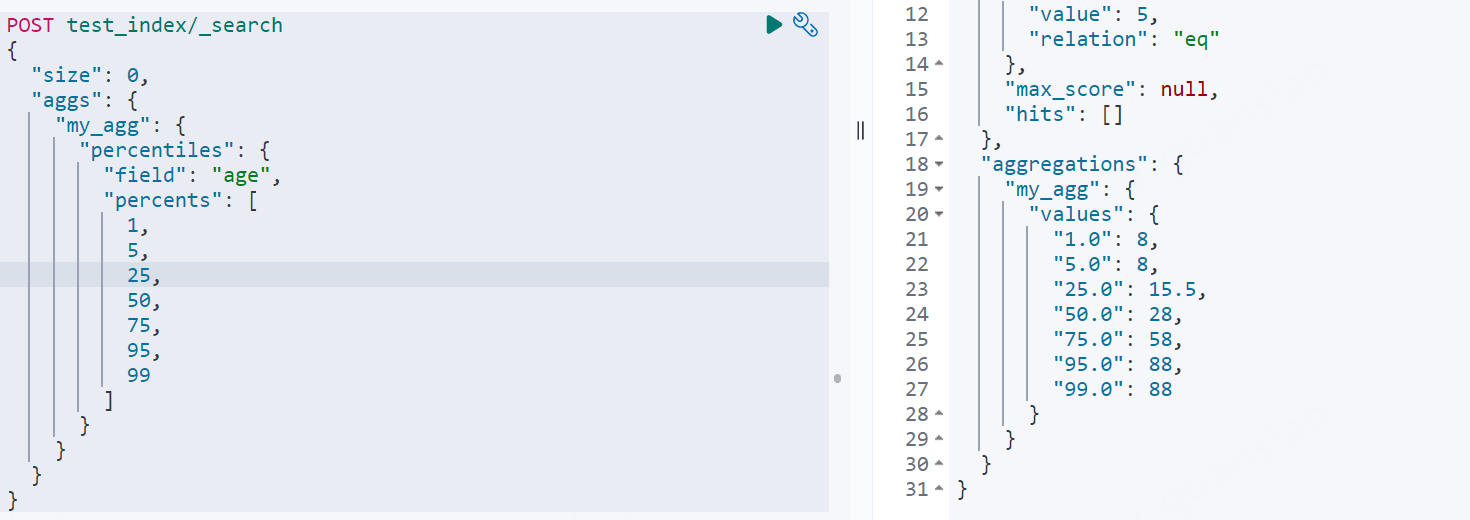
统计值小于等于指定值的文档占比percentile_ranks
不知道怎么个算法
xxxxxxxxxx# 当前年龄有:[8,18,28,48,88]POST test_index/_search{ "size": 0, "aggs": { "my_agg": { "percentile_ranks": { "field": "age", "values": [ 30, 60, 67, 99, 1000 ] } } }}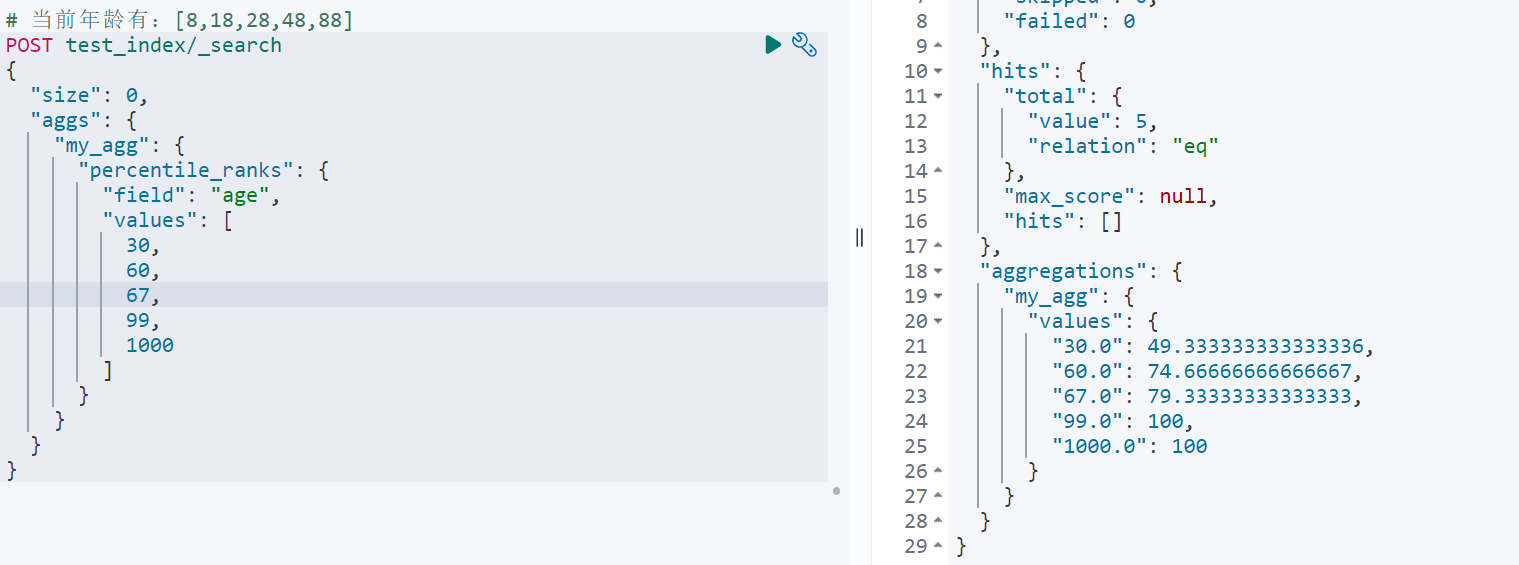
地理位置坐标点的范围
参考官网链接:
地理位置中心点坐标值
参考官网链接:
聚合查询—桶聚合
按照字段项分组聚合terms
field:"" 指定排序的字段
size:5 指定返回多少组数
show_term_doc_count_error:true 每个组上显示偏差值
shard_size:5 指定每个分片上返回多少个分组
order:{"_key":"desc"} 指定按照分组值"_key"倒序排序
order:{"_count":"asc"} 指定按照文档计数值"_count"正序排序
order:{"max_age":"desc"} 指定按照分组指标值倒序排序
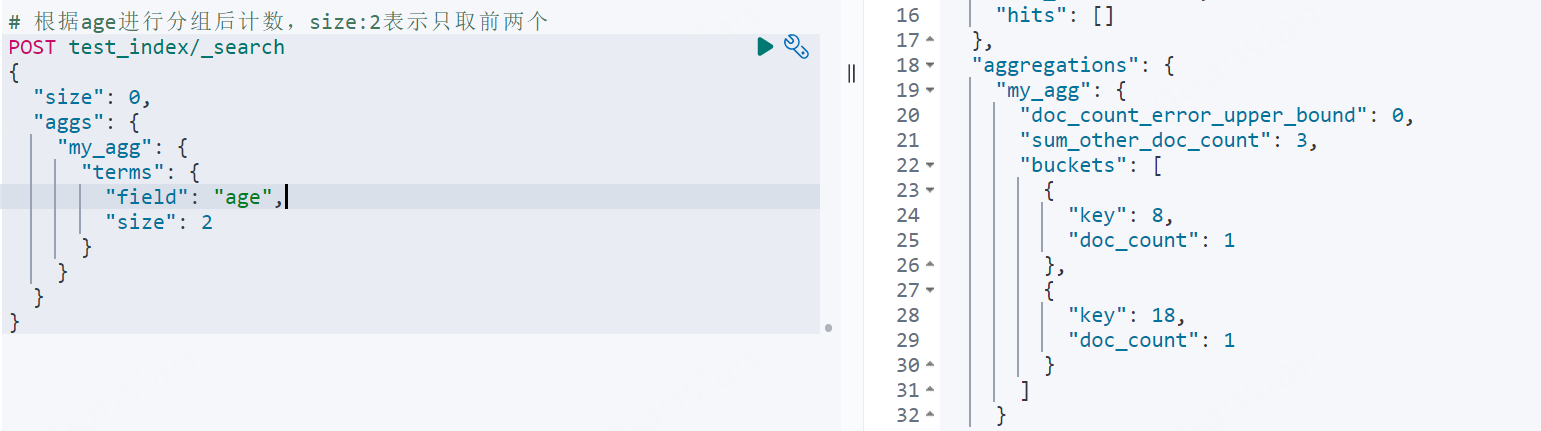
xxxxxxxxxx# 根据age进行分组后计数,size:2表示只取前两个POST test_index/_search{ "size": 0, "aggs": { "my_agg": { "terms": { "field": "age", "size": 2 } } }}"doc_count_error_upper_bound": 0 文档计数的最大偏差值
"sum_other_doc_count": 3 未返回的其他文档数,不在桶里的文档数量
对满足过滤查询的文档进行聚合计算filter
这个不会影响查询结果只会影响聚合结果
xxxxxxxxxx# 过滤province为广东的文档进行聚合POST test_index/_search{ "size": 0, "aggs": { "my_agg": { "filter": { "match":{ "province":"广东" } }, "aggs": { "my_agg": { "terms": { "field": "age" } } } } }}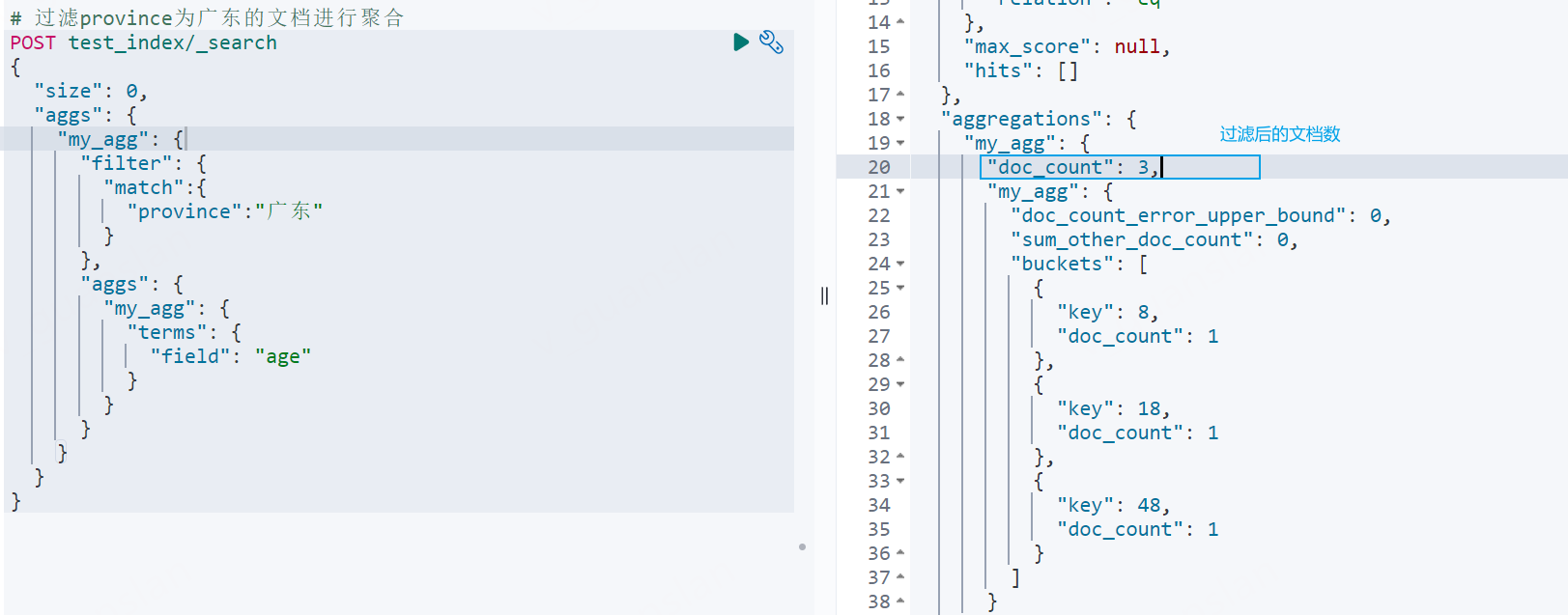
分别对多个过滤条件聚合计算filters
这不是要同时满足多个过滤条件,而是针对过滤条件一聚合一次,过滤条件二又聚合一次
xxxxxxxxxx# 分别对"province":"广东"和age>=18这两个过滤条件进行聚合POST test_index/_search{ "size": 0, "aggs": { "my_agg": { "filters": { "filters": { "filter_1":{ "match":{ "province":"广东" } }, "filter_2":{ "range": { "age": { "gte": 18 } } } } }, "aggs": { "my_agg": { "terms": { "field": "age" } } } } }}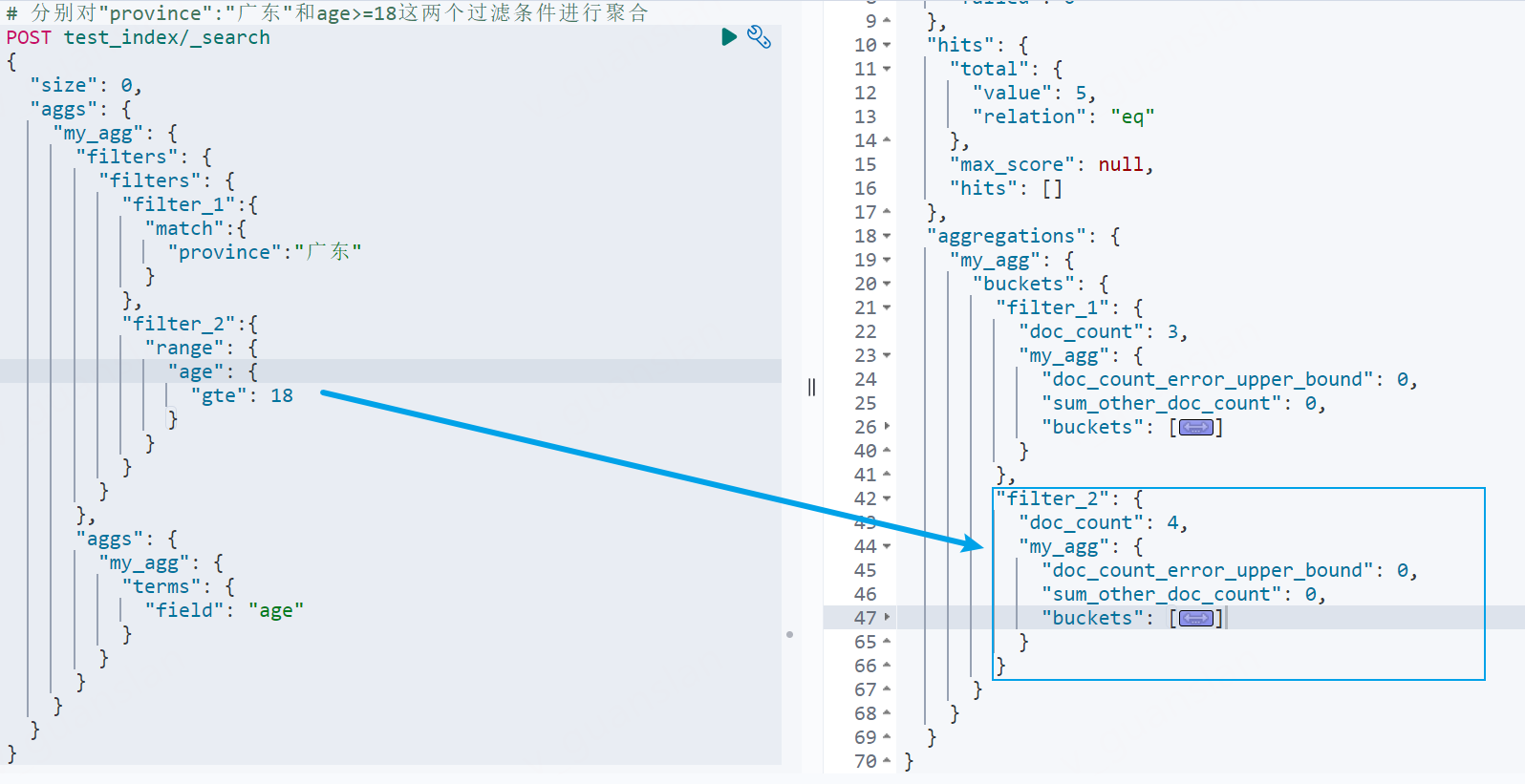
数值范围分组聚合range
xxxxxxxxxx# 当前年龄有:[8,18,28,48,88]# 按年龄分组,分别统计*-18、18-50、50-*各区间的文档数(左闭右开)POST test_index/_search{ "size": 0, "aggs": { "my_agg": { "range": { "field": "age", "keyed": true, "ranges": [ { "to": 18 }, { "from": 18, "to":"50" }, { "from": 50 } ] } } }}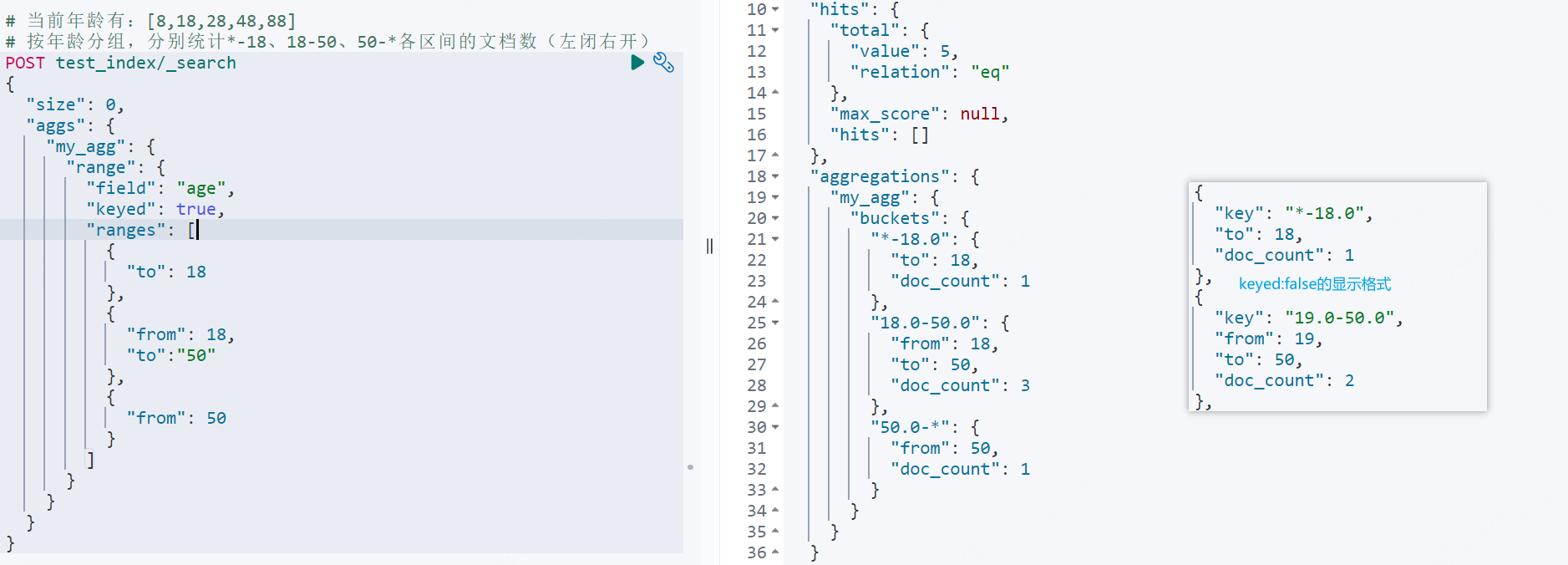
时间范围分组聚合date_range
时间直方图(柱状)聚合
缺失值的桶聚合
地理距离分区聚合
这几个不理解,暂时不记录