c#大数据循环的优化
>数据准备for循环和foreach循环对比大数据循环优化循环次数(多线程)——推荐单次循环耗时避免在循环中访问数据库、读写文件——推荐避免在循环中使用Count方法——必要避免在循环中使用FirstOrDefault方法避免使用Where过滤大数据避免操作大数据量的IEnumerable接口对象——推荐优化总结
整理一下C#大数据循环的优化
数据准备
public class UserModel { public long Id { get; set; } public string Name { get; set; } = null!; public string? School { get; set; } public string? TelNumber { get; set; } public string? Email { get; set; } public DateTime BirthDate { get; set; } public DateTime CreateTime { get; set; } public bool? IsStudent { get; set; } public int? FamilyMember { get; set; } public IEnumerable<Address> Addresss { get; set; } } public class Address { public string Country { get; set; } = null!; public string Province { get; set; } = null!; public string City { get; set; } = null!; public string District { get; set; } = null!; public string? ZipCode { get; set; } public string? PhoneNumber { get; set; } public string? SignName { get; set; } public string? Detail { get; set; } }初始化数据
xxxxxxxxxx public List<UserModel> UserInfos = new List<UserModel>(); /// <summary> /// 数据量 /// </summary> public int DataCount = 10000; /// <summary> /// 模拟耗时 /// </summary> public int DelayTime = 50;
[SetUp] public void Setup() { foreach (var item in Enumerable.Range(0, DataCount)) { UserInfos.Add(new UserModel() { Id = item, Name = MockData.UserInfo.GetFullName(), School = MockData.Word.GetWord(MockData.Number.Get(3, 5)) + "学校", TelNumber = UserInfo.GetTelPhone(), Email = UserInfo.GetEmail(), BirthDate = MockData.Time.GetDateTime(), CreateTime = MockData.Time.GetDateTime(), FamilyMember = 2, IsStudent = false, Addresss = Enumerable.Range(0, MockData.Number.Get(1, 5)).Select(y => new Address { Country = Country.GetCountryCode(), Province = Country.GetProvince(), City = Country.GetCity(), Detail = UserInfo.GetAddress(), ZipCode = UserInfo.GetZipCode(), PhoneNumber = UserInfo.GetPhone(), District = "--", SignName = UserInfo.GetFullName() }).ToList() }); } }for循环和foreach循环对比
我们分别用for循环和foreach循环同样运行一段程序,调整数据量和单次执行时间看看效果如何
xxxxxxxxxx[Test]public void TestForAndForEach(){ var stopWatch = new Stopwatch(); stopWatch.Start(); stopWatch.Stop();
stopWatch.Restart(); for (var i = 0; i < UserInfos.Count; i++) { //强制等待xx毫秒 模拟耗时 if (!string.IsNullOrWhiteSpace(UserInfos[i].Name)) Task.Delay(DelayTime).Wait(); } stopWatch.Stop(); Console.WriteLine($"TestFor 总数{DataCount}、每次等待{DelayTime}ms————预期花费 {DataCount * DelayTime} ms,实际花费 {stopWatch.ElapsedMilliseconds} ms");
stopWatch.Restart(); foreach (var item in UserInfos) { //强制等待xx毫秒 模拟耗时 if (!string.IsNullOrWhiteSpace(item.Name)) Task.Delay(DelayTime).Wait(); } stopWatch.Stop(); Console.WriteLine($"TestForEach 总数{DataCount}、每次等待{DelayTime}ms————预期花费 {DataCount * DelayTime } ms,实际花费 {stopWatch.ElapsedMilliseconds} ms"); }| 预期耗时 | For实际耗时 | 单次耗时 | foreach 实际总耗时 | 单次耗时 | |
|---|---|---|---|---|---|
| 总数100、单次200 ms | 20000 ms | 20415 ms | 204.15 ms | 20373 ms | 204.73 ms |
| 总数100、单次200 ms | 20000 ms | 20538 ms | 206.87 ms | 20526 ms | 205.26 ms |
| 总数100、单次200 ms | 20000 ms | 20449 ms | 204.49 ms | 20435 ms | 204.35 ms |
| 总数10000、单次50 ms | 500000 ms | 628934 ms | 62.89 ms | 628965 ms | 62.89 ms |
| 总数10000、单次50 ms | 500000 ms | 629053 ms | 62.83 ms | 630172 ms | 63.01 ms |
| 总数10000、单次50 ms | 500000 ms | 628312 ms | 62.83 ms | 629134 ms | 62.91 ms |
| 总数10000、单次10 ms | 100000 ms | 158038 ms | 15.80 ms | 157726 ms | 15.77 ms |
| 总数10000、单次10 ms | 100000 ms | 158545 ms | 15.85 ms | 158704 ms | 15.87 ms |
| 总数10000、单次10 ms | 100000 ms | 158426 ms | 15.84 ms | 161325 ms | 16.13 ms |
| 总数1000、单次10 ms | 10000 ms | 16077 ms | 16.07 ms | 15790 ms | 15.79 ms |
| 总数1000、单次10 ms | 10000 ms | 16042 ms | 16.04 ms | 15779 ms | 15.77 ms |
| 总数1000、单次10 ms | 10000 ms | 15725 ms | 15.72 ms | 15632 ms | 15.63 ms |
我们可以发现几点:
- for循环和foreach循环的效率并没有太大差别
- 循环的额外耗时跟循环次数和单次循环耗时成正比。一般情况下,循环次数和单次循环耗时数值越大,循环的额外耗时(实际耗时 - 预期耗时)也越大,但是在优化时,这个数值几乎不用考虑(相对而言太小了)
所以在c#中循环效率优化我们可以从循环次数和单次循环耗时这两方面入手
大数据循环优化
在c#中,循环效率优化我们可以从循环次数和单次循环耗时这两方面入手
如我们现在有一批数据,总数10000,遍历一次单次耗时50 ms。那么全部遍历完,则至少需要耗时 500000 ms(10000 * 50 ms)
xxxxxxxxxx/// <summary>/// 数据量/// </summary>public int DataCount = 10000;/// <summary>/// 模拟耗时/// </summary>public int DelayTime = 50;循环次数(多线程)——推荐
提升指数:⭐⭐⭐⭐
一般情况下,for循环是遍历完一次,才继续往下遍历的,相当于在某个时间点只会处理一条数据。那我们能不能让程序在某个时间点处理两条或者三条甚至更多条数据呢?答案肯定是可以的,我们可以利用多线程完成这个操作
xxxxxxxxxx [Test] public void TestForByTask() { var stopWatch = new Stopwatch(); stopWatch.Start(); // 转换数据 var datas = new ConcurrentQueue<UserModel>(UserInfos); stopWatch.Stop(); Console.WriteLine($"TestForByTask 转换数据 总数{DataCount},耗时 {stopWatch.ElapsedMilliseconds} ms");
stopWatch.Restart(); var tasks = new List<Task>(); var doDatas = new ConcurrentBag<long>(); for (int i = 0; i < 5; i++) // 开启多少个线程 { var task = new Task(() => { while (!datas.IsEmpty) // 循环队列 { if (datas.TryDequeue(out var item)) { //强制等待xx毫秒 模拟耗时 if (!string.IsNullOrWhiteSpace(item.Name)) { Task.Delay(DelayTime).Wait(); doDatas.Add(item.Id); } } } }); task.Start(); tasks.Add(task); }
Task.WaitAll(tasks.ToArray()); stopWatch.Stop(); Console.WriteLine($"TestForByTask 总数{DataCount}、每次等待{DelayTime}ms,已执行总数{doDatas.Distinct().Count()}————预期花费 {DataCount * DelayTime} ms,实际花费 {stopWatch.ElapsedMilliseconds} ms"); }如下图,我们可以看到加入多线程整个程序执行耗时减少了将近5倍(628s => 120s)
上述代码开了5个线程,即程序会在在某个时间点处理5条数据,从而提高循环的效率

使用多线程需要注意:
- 多线程的线程数不是越高越好,具体要看业务场景和机器性能.
- 多线程的线程安全问题(访问、读取线程外的变量)。使用线程安全的对象如ConcurrentBag、ConcurrentQueue等,访问同一变量需要加锁等
单次循环耗时
遍历一次单次耗时 50 ms,那么我们能不能通过程序优化去降低这个耗时呢?答案肯定也是可以,下面列举一下常见的优化方案
避免在循环中访问数据库、读写文件——推荐
提升指数:⭐⭐⭐⭐
如下程序,通过Usre.Id字段查询数据库的用户,对用户进行一系列操作,再将更新后的用户保存到数据库中,大致如下
xxxxxxxxxx [Test] public void TestForUpdate() { var stopWatch = new Stopwatch(); stopWatch.Start(); stopWatch.Stop();
stopWatch.Restart(); foreach (var item in UserInfos) { //强制等待xx毫秒 模拟耗时 if (!string.IsNullOrWhiteSpace(item.Name)) { // var user = _db.GetByUserId(item.Id); Task.Delay(10).Wait(); // 模拟查询数据库耗时 10ms
// user.Name = item.Name; // do something Task.Delay(30).Wait();
// _db.Update(user); Task.Delay(10).Wait(); // 修改数据库耗时 10ms } }
stopWatch.Stop(); Console.WriteLine($"TestForUpdate 总数{DataCount}、每次等待{DelayTime}ms————预期花费 {DataCount * DelayTime} ms,实际花费 {stopWatch.ElapsedMilliseconds} ms"); }整个程序的业务逻辑是没有任何问题,但在开发程序中,我们尽量不要在循环中访问数据库。总循环次数少可能看不出来问题,但是随着循环总数量增多问题就非常明显,整个程序不仅耗时,而且还有可能加大数据库的压力,导致数据库崩溃等问题。所以可以的话我们尽量在for循环外层访问读取数据库,如下
xxxxxxxxxx [Test] public void TestForUpdateByDB() { var stopWatch = new Stopwatch(); stopWatch.Start(); stopWatch.Stop();
stopWatch.Restart(); var updateUsres = new List<UserModel>(); // var allUsers = _db.GetByUserIds(UserInfos.Select(x => x.Id)); Task.Delay(50000).Wait(); // 模拟查询数据库耗时 50s foreach (var item in UserInfos) { //强制等待xx毫秒 模拟耗时 if (!string.IsNullOrWhiteSpace(item.Name)) { // 从内存取出 // var user = allUsers.FirstOrDefault(x => x.Id == item.Id); // user.Name = item.Name; // do something Task.Delay(30).Wait();
// 将更新后的用户存入内存中 // updateUsres.Add(user) } } // _db.BatchUpdate(allUsers); Task.Delay(20000).Wait(); // 模拟修改数据库耗时 50s stopWatch.Stop(); Console.WriteLine($"TestForUpdateByDB 总数{DataCount}、每次等待{DelayTime}ms————预期花费 {DataCount * DelayTime} ms,实际花费 {stopWatch.ElapsedMilliseconds} ms"); }显而易见,第二个程序(TestForUpdateByDB)耗时相对要少一点。由于并发的原因,在循环外处理数据可能会出现数据不同步的情况,要注意处理。

避免在循环中使用Count方法——必要
提升指数:⭐⭐⭐⭐⭐
能使用Any方法或者Count属性的地方尽量不要使用Count方法,通常用于判断判断查是否为空序列(没有任何元素)
xxxxxxxxxx [Test] public void TestForCount() { var stopWatch = new Stopwatch(); stopWatch.Start(); stopWatch.Stop(); var doDatas = new List<long>();
// 判断查询结果是否为空序列(没有任何元素) #region Intersect交集 stopWatch.Restart(); foreach (var item in UserInfos) { if(UserInfos.Where(x=>x.Id % 5 == 0).Count() > 0) { // todo doDatas.Add(item.Id); } } stopWatch.Stop(); Console.WriteLine($"TestForCount——Count方法 总数{DataCount} 匹配总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms");
stopWatch.Restart(); foreach (var item in UserInfos) { if (UserInfos.Any(x => x.Id % 5 == 0)) { // todo doDatas.Add(item.Id); } } stopWatch.Stop(); Console.WriteLine($"TestForCount——Any方法 总数{DataCount} 匹配总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms"); #endregion }Count方法属于计数方法,它会将匹配所有的结果进行计数,而Any只要有一条记录满足匹配条件则返回True,如果我们仅仅是判断是否满足某个条件时,优先考虑使用Any方法

避免在循环中使用FirstOrDefault方法
提升指数:⭐⭐
避免在循环中使用First、FirstOrDefault或者Last、LastOrDefault方法。非得使用的话建议使用FirstOrDefault、LastOrDefault方法,因为First、Last方法匹配不到数据会抛异常
我们可以使用字典(Dictionary)来替代FirstOrDefault或者LastOrDefault的效果,如下
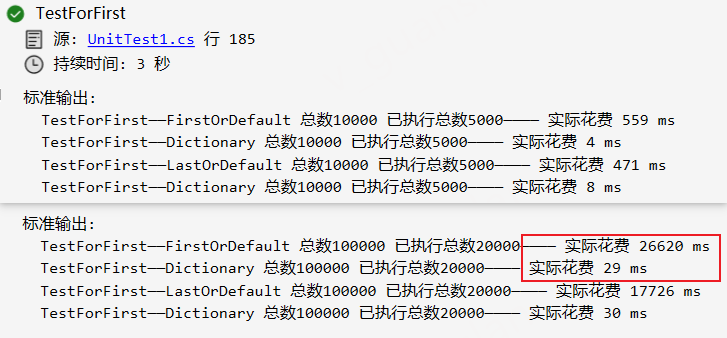
xxxxxxxxxx [Test] public void TestForFirst() { var stopWatch = new Stopwatch(); stopWatch.Start(); stopWatch.Stop(); var doDatas = new List<long>(); var searchDataList = UserInfos.OrderBy(x=>Guid.NewGuid()).Take(5000).Select(x => new { x.Id, x.Name, Email = UserInfo.GetEmail() }).ToList(); // 模拟5000个查询条件 //从集合B中查询单条数据 stopWatch.Restart(); doDatas = new List<long>(); foreach (var item in UserInfos) { if (!string.IsNullOrWhiteSpace(item.Name)) { var userItem = searchDataList.FirstOrDefault(x => x.Id == item.Id && x.Name == item.Name); // LastOrDefault if (userItem == null) continue; item.Email = userItem.Email; doDatas.Add(item.Id); } } stopWatch.Stop(); Console.WriteLine($"TestForFirst——FirstOrDefault 总数{DataCount} 已执行总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms");
stopWatch.Restart(); doDatas = new List<long>(); var searchDataDic = searchDataList.GroupBy(x => new { x.Id, x.Name }).ToDictionary(x => x.Key, x => x.FirstOrDefault()); // LastOrDefault foreach (var item in UserInfos) { if (!string.IsNullOrWhiteSpace(item.Name)) { if (!searchDataDic.TryGetValue(new { item.Id, item.Name }, out var userItem)) continue; item.Email = userItem?.Email; doDatas.Add(item.Id); } } stopWatch.Stop(); Console.WriteLine($"TestForFirst——Dictionary 总数{DataCount} 已执行总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms"); }我们可以看到这个在for循环中,两者的效率相差较大,而且随着循环数量增大或查询条件增大差距越明显。所以循环大数据时使用字典来代替FirstOrDefault或者LastOrDefault是很有必要的,不过字典没有FirstOrDefault那么"直观"
避免使用Where过滤大数据
提升指数:⭐
避免使用Where方法过滤大量的数据(如在10000总数据中查询出2000条数据)更不要在循环中如此操作,我们可以使用集合操作来代替Where效果。
xxxxxxxxxx [Test] public void TestForIntersect() { var stopWatch = new Stopwatch(); stopWatch.Start(); stopWatch.Stop(); var doDatas = new List<long>(); var searchDataList = UserInfos.OrderBy(x => Guid.NewGuid()).Take(5000).Select(x => new { x.Id, x.Name, Email = UserInfo.GetEmail() }).ToList(); // 模拟5000个查询条件
// 找出集合A中包含集合B的数据 [1,2,3,4,5] + [2,3,8] => [2,3] #region Intersect交集 stopWatch.Restart(); var aList = UserInfos.Select(x => x.Id).ToList(); var bList = searchDataList.Select(x => x.Id).ToList(); doDatas = aList.Where(x => bList.Contains(x)).ToList(); stopWatch.Stop(); Console.WriteLine($"TestForIntersect——Where 总数{DataCount} 匹配总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms");
stopWatch.Restart(); aList = UserInfos.Select(x => x.Id).ToList(); bList = searchDataList.Select(x => x.Id).ToList(); doDatas = aList.Intersect(bList).ToList(); stopWatch.Stop(); Console.WriteLine($"TestForIntersect——Intersect 总数{DataCount} 匹配总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms"); #endregion
// 找出集合A中不包含集合B的数据 [1,2,3,4,5] + [2,3,8] => [1,4,5] #region Except差集 stopWatch.Restart(); aList = UserInfos.Select(x => x.Id).ToList(); bList = searchDataList.Select(x => x.Id).ToList(); doDatas = aList.Where(x => bList.Contains(x)).ToList(); stopWatch.Stop(); Console.WriteLine($"TestForIntersect——Where 总数{DataCount} 匹配总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms");
stopWatch.Restart(); aList = UserInfos.Select(x => x.Id).ToList(); bList = searchDataList.Select(x => x.Id).ToList(); doDatas = aList.Except(bList).ToList(); stopWatch.Stop(); Console.WriteLine($"TestForIntersect——Except 总数{DataCount} 匹配总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms"); #endregion }
避免操作大数据量的IEnumerable接口对象——推荐
提升指数:⭐⭐⭐⭐
循环内要避免直接操作大数据量的IEnumerable接口对象,应该在循环外将数据处理成相应的集合类型(ToList、ToDictionary、ToArray)
这也是我为什么会记录这篇文章的原因:一开始,我发现单次循环慢,然后使用字典替代FirstOrDefault查询,用集合操作(Intersect、Except)替代Where查询,执行速度确实有非常明显的提升,我以为是FirstOrDefault和Where的原因,才信心满满来整理,但经过对比才发现真正的主角并不是这俩,而是另有其人,我们先来看看吧。
我们先看一下以下这三个方法的执行顺序
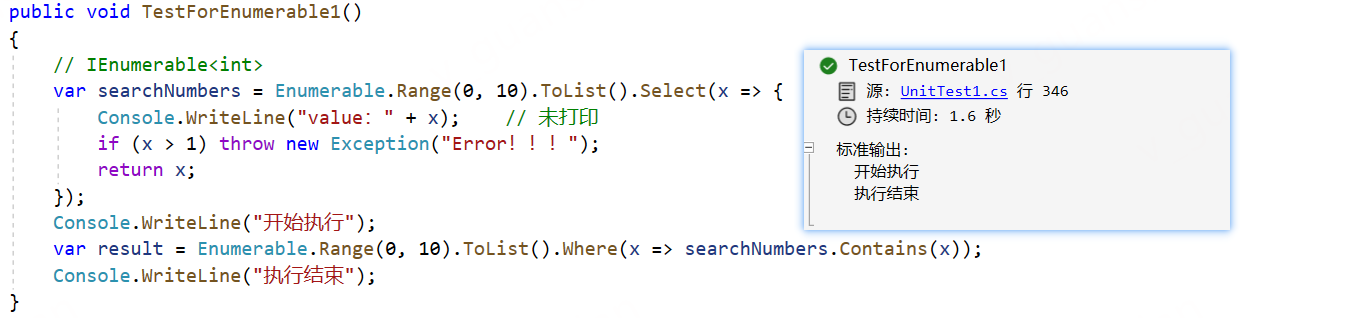
xxxxxxxxxx [Test] public void TestForEnumerable1() { // IEnumerable<int> var searchNumbers = Enumerable.Range(0, 10).ToList().Select(x => { Console.WriteLine("value:" + x); if (x > 1) throw new Exception("Error!!!"); return x; }); Console.WriteLine("开始执行"); var result = Enumerable.Range(0, 10).ToList().Where(x => searchNumbers.Contains(x)); Console.WriteLine("执行结束"); }
[Test] public void TestForEnumerable2() { // IEnumerable<int> var searchNumbers = Enumerable.Range(0, 10).ToList().Select(x => { Console.WriteLine("value:" + x); if (x > 1) throw new Exception("Error!!!"); return x; }); Console.WriteLine("开始执行"); var result = Enumerable.Range(0, 10).ToList().Where(x => searchNumbers.Contains(x)).ToList(); Console.WriteLine("执行结束"); }
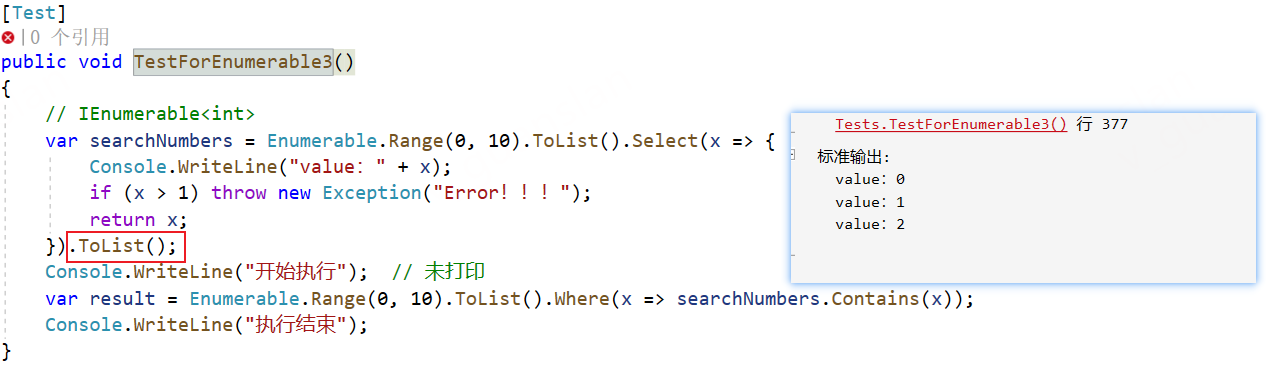
[Test] public void TestForEnumerable3() { // IEnumerable<int> var searchNumbers = Enumerable.Range(0, 10).ToList().Select(x => { Console.WriteLine("value:" + x); if (x > 1) throw new Exception("Error!!!"); return x; }).ToList(); Console.WriteLine("开始执行"); var result = Enumerable.Range(0, 10).ToList().Where(x => searchNumbers.Contains(x)); Console.WriteLine("执行结束"); }TestForEnumerable1方法的searchNumbers逻辑未执行,因为result变量在程序结束的时候都没有引用(使用),IEnumerable对象只有在使用到这个变量的时候才会开始执行相应具体的逻辑,这种方式在处理大型数据集时可以节省内存和计算资源
执行顺序:开始——>结束
TestForEnumerable2方法的result调用ToList方法,此时会执行searchNumbers逻辑。由于searchNumbers逻辑抛异常未处理,所以没有继续往下执行。
执行顺序:开始——>searchNumbers(异常)——>结束

TestForEnumerable3方法的searchNumbers逻辑(调用了ToList方法)会先执行。由于searchNumbers逻辑抛异常未处理,所以没有继续往下执行。
执行顺序:searchNumbers(异常)——>开始——>结束
经过上面三段代码,我们可以发现,IEnumerable对象对于程序的逻辑顺序会有一定的影响。由于IEnumerable对象的惰性加载(只在需要时加载数据),在有些时候确实能帮助我们提高性能和缓解内存压力,但是在大数据循环与查询(For、Where、FirstOrDefault)中,非常建议大家在此之前将IEnumerable对象处理成相应的集合类型(ToList、ToDictionary、ToArray),这个提升真的很大
xxxxxxxxxx [Test] public void TestForEnumerableFirstOrDefault() { var stopWatch = new Stopwatch(); stopWatch.Start(); stopWatch.Stop(); var doDatas = new List<long>(); var searchData = UserInfos.OrderBy(x => Guid.NewGuid()).Take(5000).Select(x => new { x.Id, x.Name, Email = UserInfo.GetEmail() }); // 模拟5000个查询条件
//从集合B中查询单条数据 #region IEnumerable stopWatch.Restart(); doDatas = new List<long>(); foreach (var item in UserInfos) { if (!string.IsNullOrWhiteSpace(item.Name)) { var userItem = searchData.FirstOrDefault(x => x.Id == item.Id && x.Name == item.Name); if (userItem == null) continue; item.Email = userItem.Email; doDatas.Add(item.Id); } } stopWatch.Stop(); Console.WriteLine($"TestForEnumerableFirstOrDefault——IEnumerable 总数{DataCount} 已执行总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms"); #endregion
#region ToList stopWatch.Restart(); doDatas = new List<long>(); var searchDataList = searchData.ToList(); // 提前加载 foreach (var item in UserInfos) { if (!string.IsNullOrWhiteSpace(item.Name)) { var userItem = searchDataList.FirstOrDefault(x => x.Id == item.Id && x.Name == item.Name); if (userItem == null) continue; item.Email = userItem.Email; doDatas.Add(item.Id); } } stopWatch.Stop(); Console.WriteLine($"TestForEnumerableFirstOrDefault——List 总数{DataCount} 已执行总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms"); #endregion }我们先来看看FirstOrDefault,两者执行花费的时间差距很大,而且不知道为什么IEnumerable对象查询出来的结果会少于(List)集合对象查询的结果,按理这两种方式应该都是一样的查询结果的

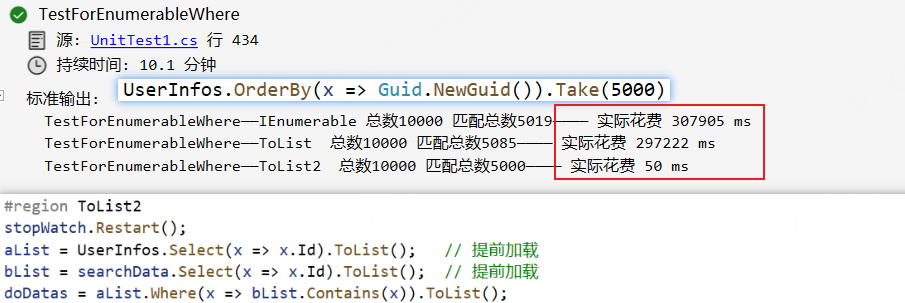
xxxxxxxxxx [Test] public void TestForEnumerableWhere() { var stopWatch = new Stopwatch(); stopWatch.Start(); stopWatch.Stop(); var doDatas = new List<long>(); var searchData = UserInfos.OrderBy(x => Guid.NewGuid()).Take(5000).Select(x => new { x.Id, x.Name, Email = UserInfo.GetEmail() }); // 模拟5000个查询条件
// 找出集合A中包含集合B的数据 #region IEnumerable stopWatch.Restart(); var aList = UserInfos.Select(x => x.Id); var bList = searchData.Select(x => x.Id); doDatas = aList.Where(x => bList.Contains(x)).ToList(); stopWatch.Stop(); Console.WriteLine($"TestForEnumerableWhere——IEnumerable 总数{DataCount} 匹配总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms"); #endregion
#region ToList stopWatch.Restart(); aList = UserInfos.Select(x => x.Id).ToList(); // 提前加载 bList = searchData.Select(x => x.Id); doDatas = aList.Where(x => bList.Contains(x)).ToList(); stopWatch.Stop(); Console.WriteLine($"TestForEnumerableWhere——ToList 总数{DataCount} 匹配总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms"); #endregion
#region ToList2 stopWatch.Restart(); aList = UserInfos.Select(x => x.Id).ToList(); // 提前加载 bList = searchData.Select(x => x.Id).ToList(); // 提前加载 doDatas = aList.Where(x => bList.Contains(x)).ToList(); stopWatch.Stop(); Console.WriteLine($"TestForEnumerableWhere——ToList2 总数{DataCount} 匹配总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms"); #endregion }我们先来看看Where查询,三者执行花费的时间差距很大,同样,不知道为什么IEnumerable对象查询出来的结果会多于(List)集合对象查询的结果,按理这三种方式应该都是一样的查询结果的
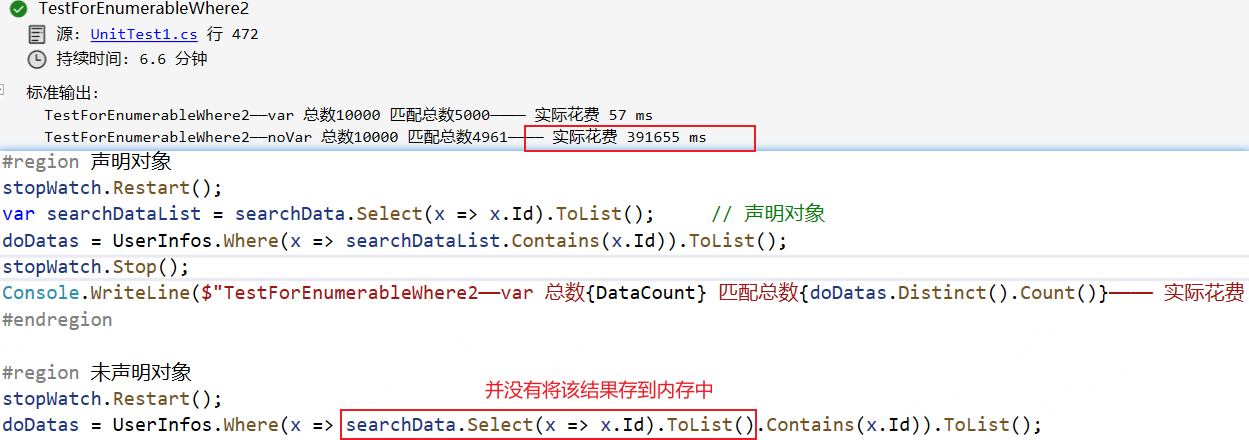
xxxxxxxxxx [Test] public void TestForEnumerableWhere2() { var stopWatch = new Stopwatch(); stopWatch.Start(); stopWatch.Stop(); var doDatas = new List<UserModel>(); var searchData = UserInfos.OrderBy(x => Guid.NewGuid()).Take(5000).Select(x => new { x.Id, x.Name, Email = UserInfo.GetEmail() }); // 模拟5000个查询条件
// 找出集合A中包含集合B的数据 #region 声明对象 stopWatch.Restart(); var searchDataList = searchData.Select(x => x.Id).ToList(); // 声明对象 doDatas = UserInfos.Where(x => searchDataList.Contains(x.Id)).ToList(); stopWatch.Stop(); Console.WriteLine($"TestForEnumerableWhere2——var 总数{DataCount} 匹配总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms"); #endregion
#region 未声明对象 stopWatch.Restart(); doDatas = UserInfos.Where(x => searchData.Select(x => x.Id).ToList().Contains(x.Id)).ToList(); stopWatch.Stop(); Console.WriteLine($"TestForEnumerableWhere2——noVar 总数{DataCount} 匹配总数{doDatas.Distinct().Count()}———— 实际花费 {stopWatch.ElapsedMilliseconds} ms"); #endregion }我们可以看到,查询条件内转为集合类型再查询这种方式是最慢的,因为他每次循环遍历都会执行一次ToList方法。大数据Where查询想要加快查询速度,Where、FirstOrDefault中的查询条件一定要在外部声明变量。
大数据循环加快速度正确的使用方式

千万使用下面的方式

回到前话,有时候循环程序执行速度慢,我们先不用急着替换FirstOrDefault、Where,应该优先考虑将这批数据读取到内存中再进行查询筛选操作,再考虑替换FirstOrDefault、Where方法。
优化总结
c#中关于循环总结几点:
- for循环和foreach循环的效率并没有太大差别
- 大数据循环可以采用多线程的方式,要注意线程安全和机器(cpu)配置。C#常见多线程的实现:Thread、Task、TaskFactory、Parallel并行(有空整理)
- 大数据循环可以通过优化程序逻辑减少单次循环的耗时,比较推荐两个优化点:避免在循环中访问数据库读取磁盘等耗时操作,注意数据同步;大数据循环查询时尽量不要直接操作IEnumerable对象,建议先将其加到内存中,注意机器(内存)配置。
- 当然,可以将两种方式结合
有时候大数据循环程序执行速度慢,建议按以下优先级进行优化
- 多线程——推荐 ⭐⭐⭐⭐
- 避免在循环中访问数据库、读写文件——推荐 ⭐⭐⭐⭐
- 避免操作大数据量的IEnumerable接口对象——推荐 ⭐⭐⭐⭐
- 避免在循环中使用Count方法——必要 ⭐⭐⭐⭐⭐
- 避免在循环中使用FirstOrDefault方法 ⭐⭐
- 避免使用Where方法过滤大数据 ⭐