SQL Server数据库的连接操作整理与优化
>说明连接方式笛卡尔连接(CARTESIAN JOIN)自然连接(NATURAL JOIN)内连接(INNER JOIN)左外连接(LEFT OUTER JOIN)右外连接(RIGHT OUTER JOIN)全外连接(FULL OUTER JOIN)自连接Join优化Join连接的索引join连接的顺序join连接的字段优化总结其他join 连接的条件join连接执行顺序
说明
简单整理了一下SqlServer数据库的连接操作。基于SqlServer,绝大部分内容也适用于其他数据库,大差不差,有特殊的地方也标出来了
准备数据可参考:借助 Mock.js 快速生成数据库虚拟数据 (logerlink.github.io)
连接方式
笛卡尔连接(CARTESIAN JOIN)
SQL – 连接(笛卡尔连接和自连接)|极客教程 (geek-docs.com)
笛卡尔连接又称为交叉链接。一个表的每一行与另一个表的每一行都有一个连接,支持多个表连接,连接查询结果集的行数是所有连接表行数的乘积(如三张表每张表有两行数据,那么笛卡尔连接后则会有(2 x 2 x 2=)8条数据)
xSELECT u.UserId,u.UserName,a.AddressId,p.ProductId from test.dbo.TK_User uCROSS JOIN test.dbo.TK_Address aCROSS JOIN test.dbo.TK_Product pwhere a.AddressId in ('ADDR0000000001','ADDR0000000002') -- 两条and u.UserId in ('UU00000001','UU00000002') -- 两条and p.ProductId in ('PO00000001','PO00000002') -- 两条order by u.UserId
-- 也可以写成SELECT u.UserId,u.UserName,a.AddressId,p.ProductId from test.dbo.TK_User u,test.dbo.TK_Address a,test.dbo.TK_Product p...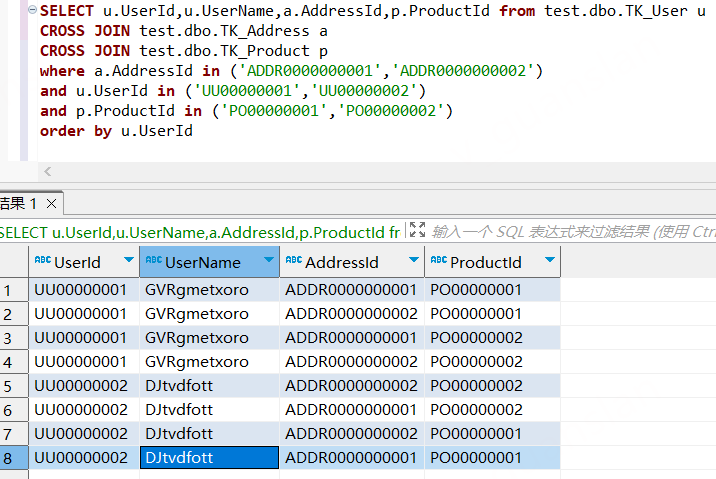
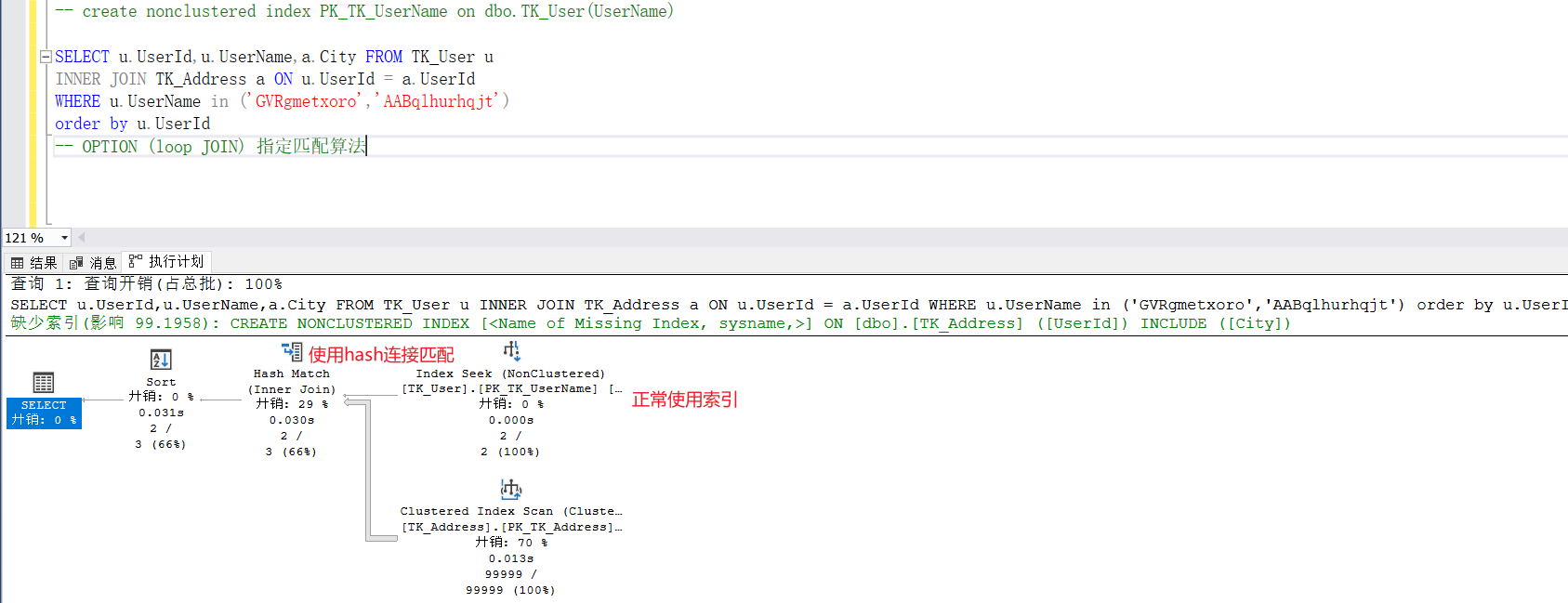
如下图,我们可以看到笛卡尔连接使用条件查询时可以正常走索引,预期结果集行数 = 表1行数 * 表2行数 *表3行数...
多表连接时,结果集可能会非常庞大,建议加上限制条件(where、分页)不然很可能会超时
自然连接(NATURAL JOIN)
进行自然连接操作的表必须要有相同列名的列,并以该字段作为匹配条件,自然连接的步骤是将第一张表的第一条记录和第二张表的每一条记录匹配,如果符合条件就将这两行组成一条记录,然后第一张表的第二条记录再和第二张表的每一条记录匹配,依次匹配,直到第一张表遍历完成
- 找到两个或多个表之间具有相同列名的列。这些列被称为自然连接的条件列。
- 将具有相同值的条件列的行组合在一起,形成结果集。
- 结果集中只包含一次的列,即自然连接的条件列只出现一次。
xxxxxxxxxx-- 在Mysql中可以直接使用 NATURAL JOINSELECT * FROM TK_User u NATURAL JOIN TK_Address;
-- SQL Server没有NATURAL JOIN,可以借助inner join...on实现NATURAL JOIN效果SELECT u.UserId,u.UserName,a.City FROM TK_User uINNER JOIN TK_Address a ON u.UserId = a.UserIdWHERE u.UserId in ('UU00000001','UU00000002')order by u.UserId;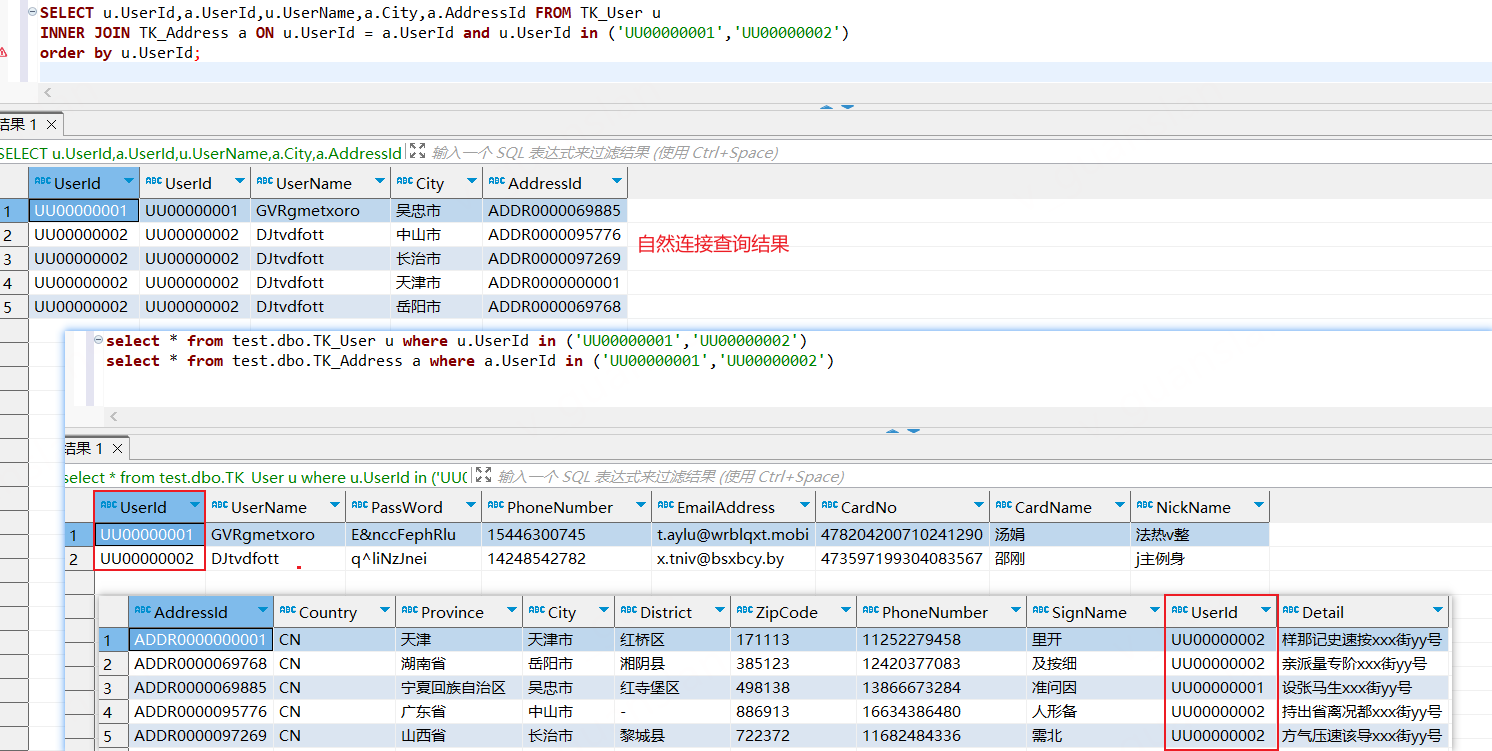
如下图,我们可以看到自然连接使用条件查询时可以正常走索引,预期结果集行数 = 表1和表2匹配的行数
SQL – 连接(内连接,左连接,右连接和全连接)|极客教程 (geek-docs.com)
内连接(INNER JOIN)
内连接的结果和自然连接的结果是一样的。(在Mysql中两者)显示的属性不一样,内连接会将两张表的重复属性都分别列出来。
INNER JOIN 用于连接两个表,而 ON 子句用于指定了连接的条件。这样,只有匹配ON子句才会被连接起来形成结果集。内连接返回的结果集只包含匹配的行,如果两个表中的行在连接条件上没有匹配,那么这些行将被忽略。可以使用 INNER JOIN 来连接多个表
xxxxxxxxxxSELECT u.UserId,u.UserName,a.City,a.AddressId FROM TK_User uINNER JOIN TK_Address a ON u.UserId = a.UserIdWHERE u.UserId in ('UU00000001','UU00000002')order by u.UserId;
-- 也可以写成SELECT u.UserId,a.UserId,u.UserName,a.City,a.AddressId FROM TK_User uINNER JOIN TK_Address a ON u.UserId = a.UserId and u.UserId in ('UU00000001','UU00000002')order by u.UserId;
左外连接(LEFT OUTER JOIN)
左外连接,它会返回左表中的所有行,以及与右表中匹配的行。如果右表中没有匹配的行,则返回 NULL 值
xxxxxxxxxxSELECT u.UserId,u.UserName,a.UserId,a.City,a.AddressId FROM TK_User uLEFT JOIN TK_Address a ON u.UserId = a.UserId where u.UserId in ('UU00000001','UU00000002','UU00000003')order by u.UserId;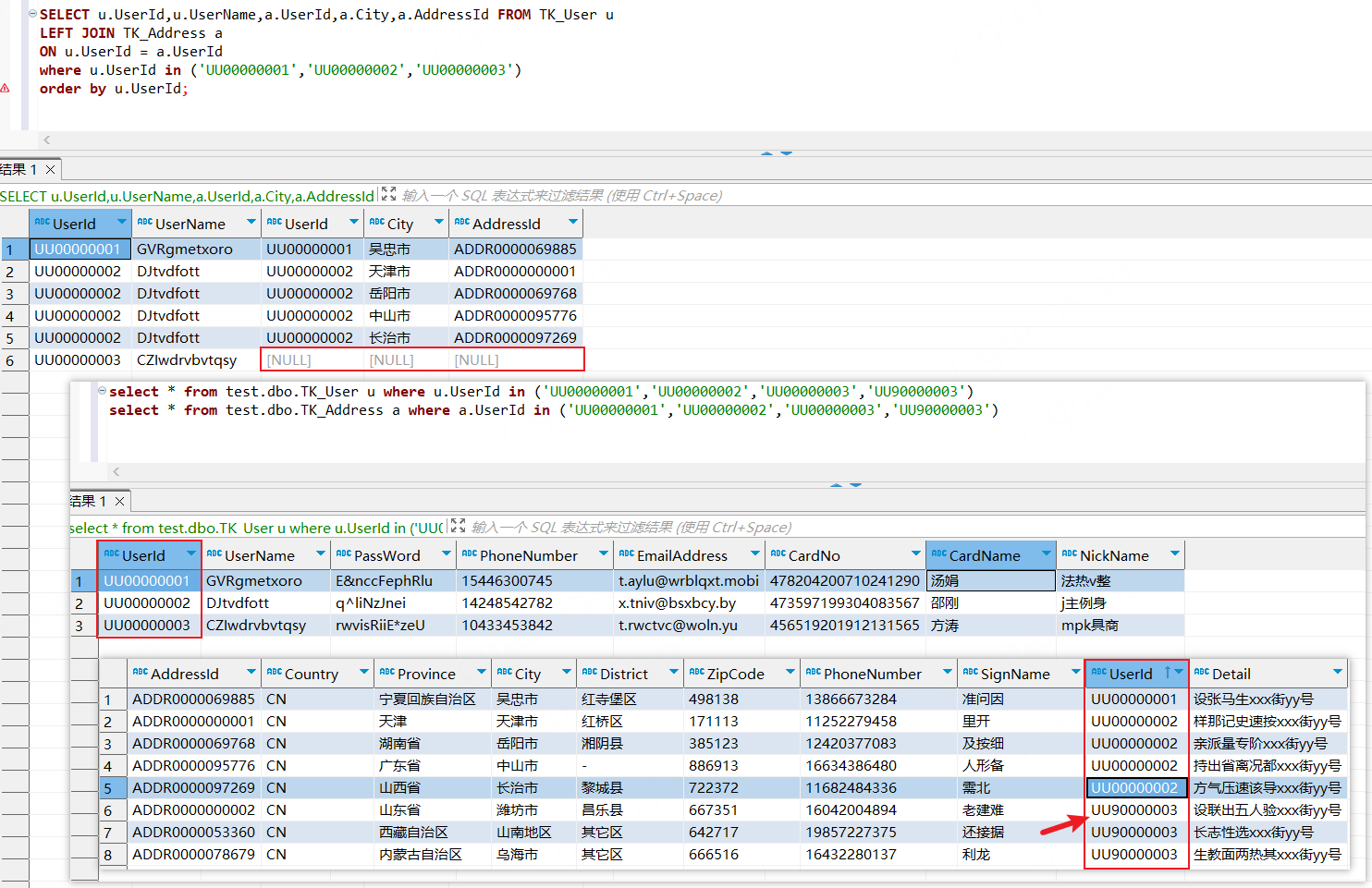
左外连接如果想根据左表或右表的某个条件进行过滤,应该使用where条件查询而不是直接在on后面追加条件
如下,使用where条件查询可以对查询结果根据UserId进行过滤,而在on后面追加条件则不会根据UserId进行过滤。因为左外连接会将左表的全部列出,从而导致查询结果不准确、查询效率不高(如果数据量大的话,会查询很久)等问题
xxxxxxxxxxSELECT u.UserId,u.UserName,a.UserId,a.City,a.AddressId FROM TK_User uLEFT JOIN TK_Address a ON u.UserId = a.UserId and u.UserId in ('UU00000001','UU00000002','UU00000003')order by u.UserId;
右外连接(RIGHT OUTER JOIN)
右外连接,它会返回右表中的所有行,以及与左表中匹配的行。如果左表中没有匹配的行,则返回 NULL 值。
xxxxxxxxxxSELECT u.UserId,u.UserName,a.UserId,a.City,a.AddressId FROM TK_User uRIGHT JOIN TK_Address a ON u.UserId = a.UserId where a.UserId in ('UU00000001','UU00000002','UU90000003')order by u.UserId;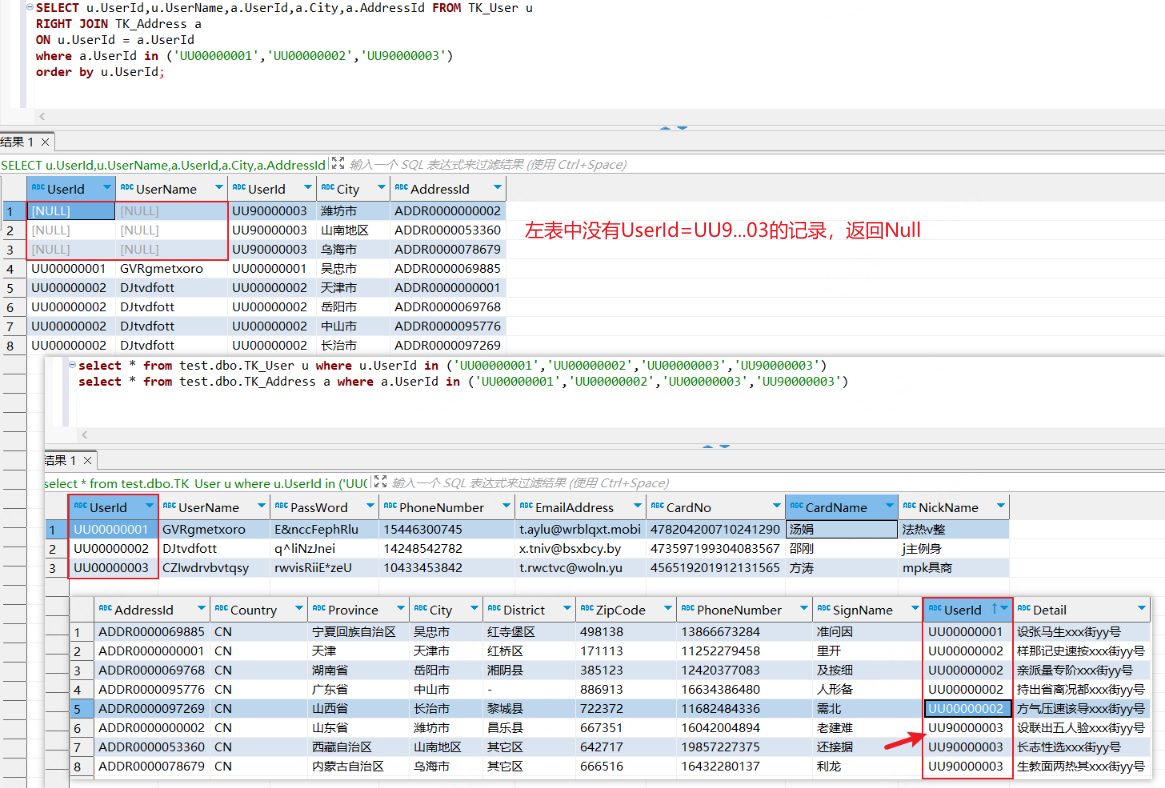
右外连接如果想根据左表或右表的某个条件进行过滤,应该使用where条件查询而不是直接在on后面追加条件
如下,使用where条件查询可以对查询结果根据UserId进行过滤,而在on后面追加条件则不会根据UserId进行过滤。右外连接会将右表的数据全部列出,从而导致查询结果不准确、查询效率不高(如果数据量大的话,会查询很久)等问题
xxxxxxxxxxSELECT u.UserId,u.UserName,a.UserId,a.City,a.AddressId FROM TK_User uRIGHT JOIN TK_Address a ON u.UserId = a.UserId and a.UserId in ('UU00000001','UU00000002','UU90000003')order by a.UserId;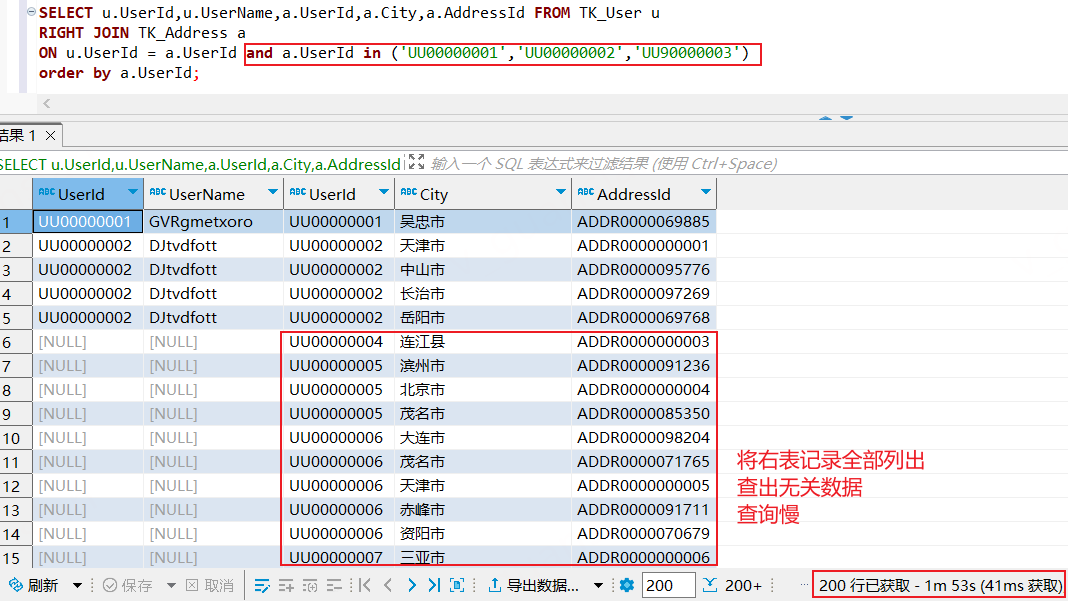
全外连接(FULL OUTER JOIN)
全外连接,它会返回左表和右表中的所有行,并将它们进行合并。如果左表或右表中没有匹配的行,则对应的列将被填充为 NULL 值
xxxxxxxxxxSELECT u.UserId,u.UserName,a.UserId,a.City,a.AddressId FROM TK_User uFULL JOIN TK_Address a ON u.UserId = a.UserIdwhere u.UserId in ('UU00000001','UU00000002','UU00000003','UU90000003') or a.UserId in ('UU00000001','UU00000002','UU00000003','UU90000003')order by u.UserId;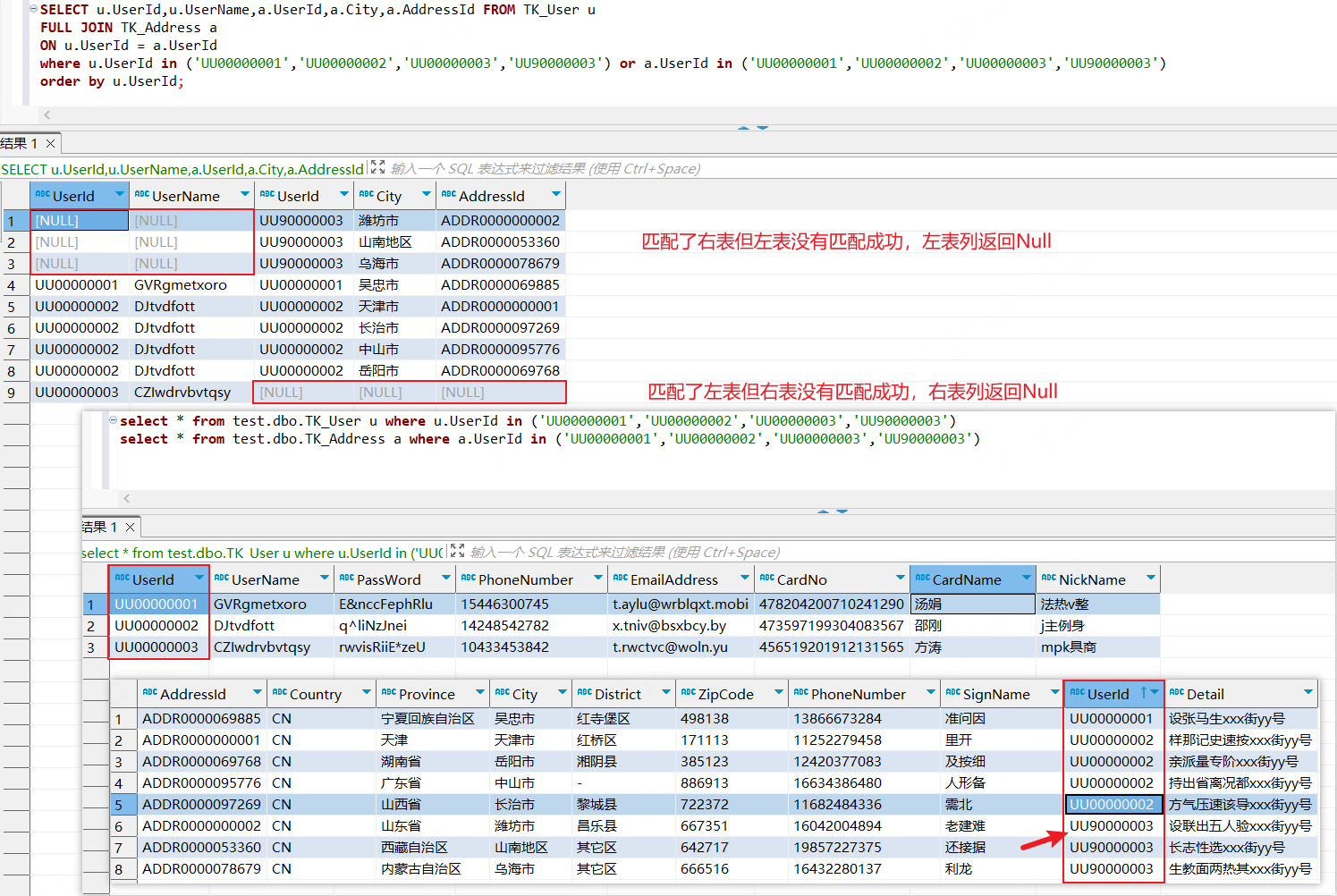
全外连接如果想根据左表或右表的某个条件进行过滤,应该使用where条件查询而不是直接在on后面追加条件
如下,使用where条件查询可以对查询结果根据UserId进行过滤,而在on后面追加条件则不会根据UserId进行过滤。全外连接会将左表、右表的记录全部列出,从而导致查询结果不准确、查询效率不高(如果数据量大的话,会查询很久)等问题
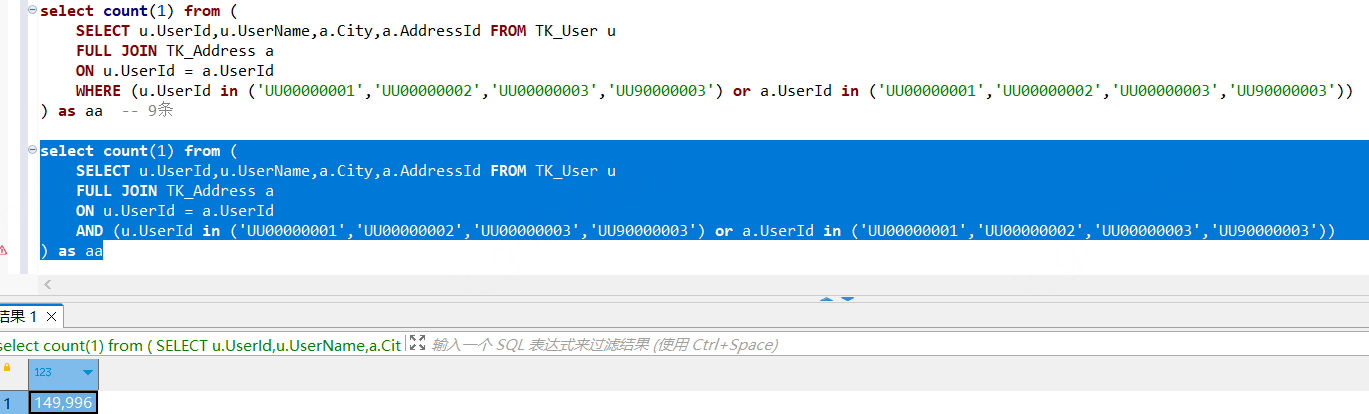
自连接
值得一提,实现自连接也是通过JOIN来实现。自连接在处理具有层次结构的数据时非常有用,但需要小心避免形成循环连接或性能问题(From AI.)
xxxxxxxxxx-- 查询权限及子权限select r1.*,r2.* from DataRight r1left join DataRight r2on r1.ParentId = r2.IdJoin优化
Join连接的索引
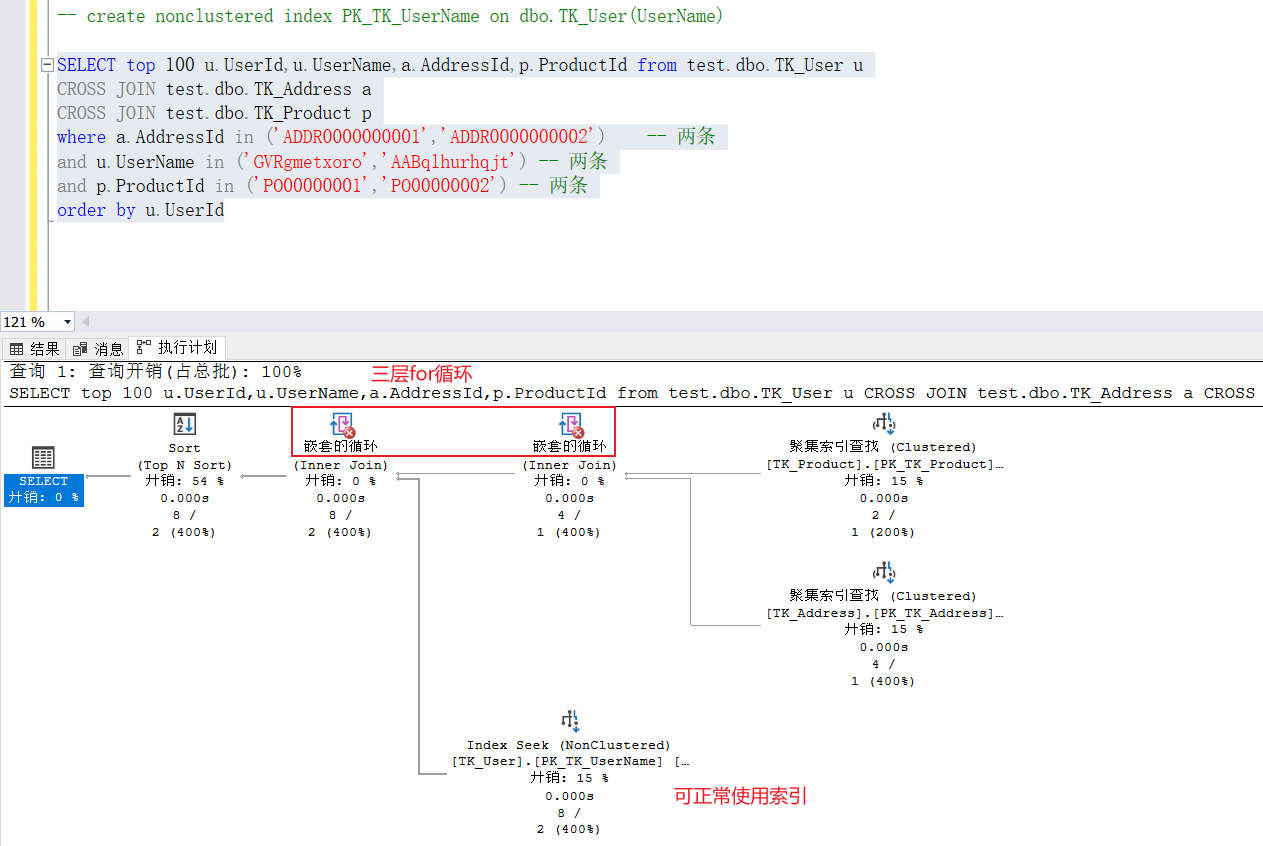
内连接、外连接使用条件查询时都可以正常走索引。所以如果数据量大的话,join连接的优化方式通常是给where条件的字段加索引,或者给被驱动表(表2、表3)的连接字段加索引。
当被驱动表的连接字段没有建立索引时,被驱动表会使用最优的方案进行检索(有聚集索引则使用聚集索引,没有聚集索引则使用全表扫描)此时被驱动表读取的行数为驱动表的总数。
当我们给连接字段建立索引时,此时被驱动表会使用该索引进行检索,此时被驱动表读取的行数会小于驱动表的总数,这样就可以减少两张表的比较次数,从而提高查询效率。
xxxxxxxxxx-- drop index Index_TK_Order_UserId on dbo.TK_Order -- 删除索引-- create nonclustered index Index_TK_Order_UserId on dbo.TK_Order(UserId) -- 创建TK_Address表UserId列索引
SELECT u.UserId,u.UserName,o.OrderId FROM TK_User uINNER JOIN TK_Order o ON u.UserId = o.UserIdwhere u.UserName like 'F%'order by u.UserId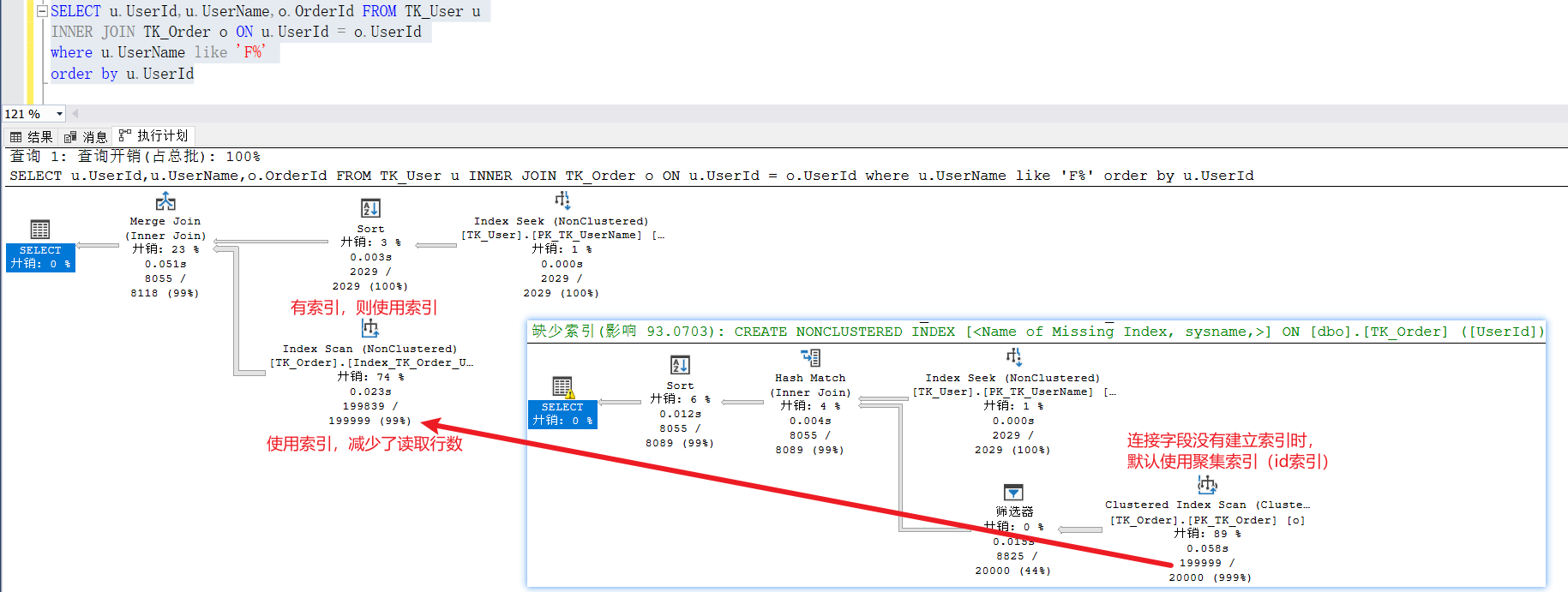
数据量太小,上图几乎没有看出区别,我们使用下面链接再比较试试
xxxxxxxxxx-- drop index Index_TK_Order_UserId on dbo.TK_Order -- 删除索引
-- create nonclustered index Index_TK_Order_UserId on dbo.TK_Order(UserId) -- 创建TK_Address表UserId列索引
SELECT top 10000 u.UserId,u.UserName,o.OrderId FROM TK_User uINNER JOIN TK_Order o ON u.UserId = o.UserIdorder by u.UserId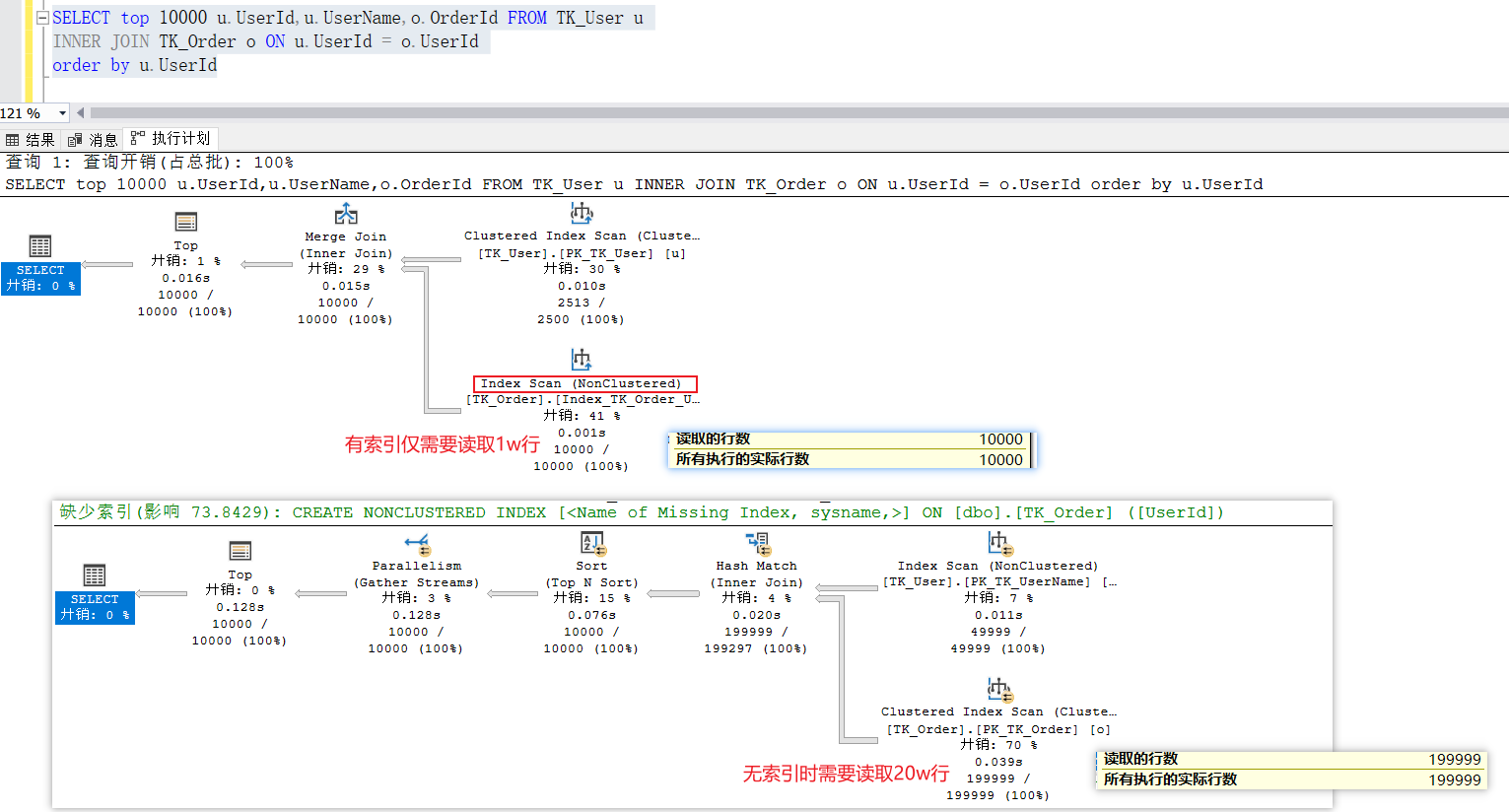
join连接的顺序
数据表(条件查询后)的行数越少,尽量越靠前,用小表驱动大表。正常顺序:表1行数 < 表2行数 < 表3行数...
不知道是不是我看的是Mysql宝典的原因,在SqlServer中无论怎么重试,都达不到预期效果(小表越靠前查询效率越快)。不管怎么更换表顺序或者更换连接方式查询效率基本都是一致,如下图

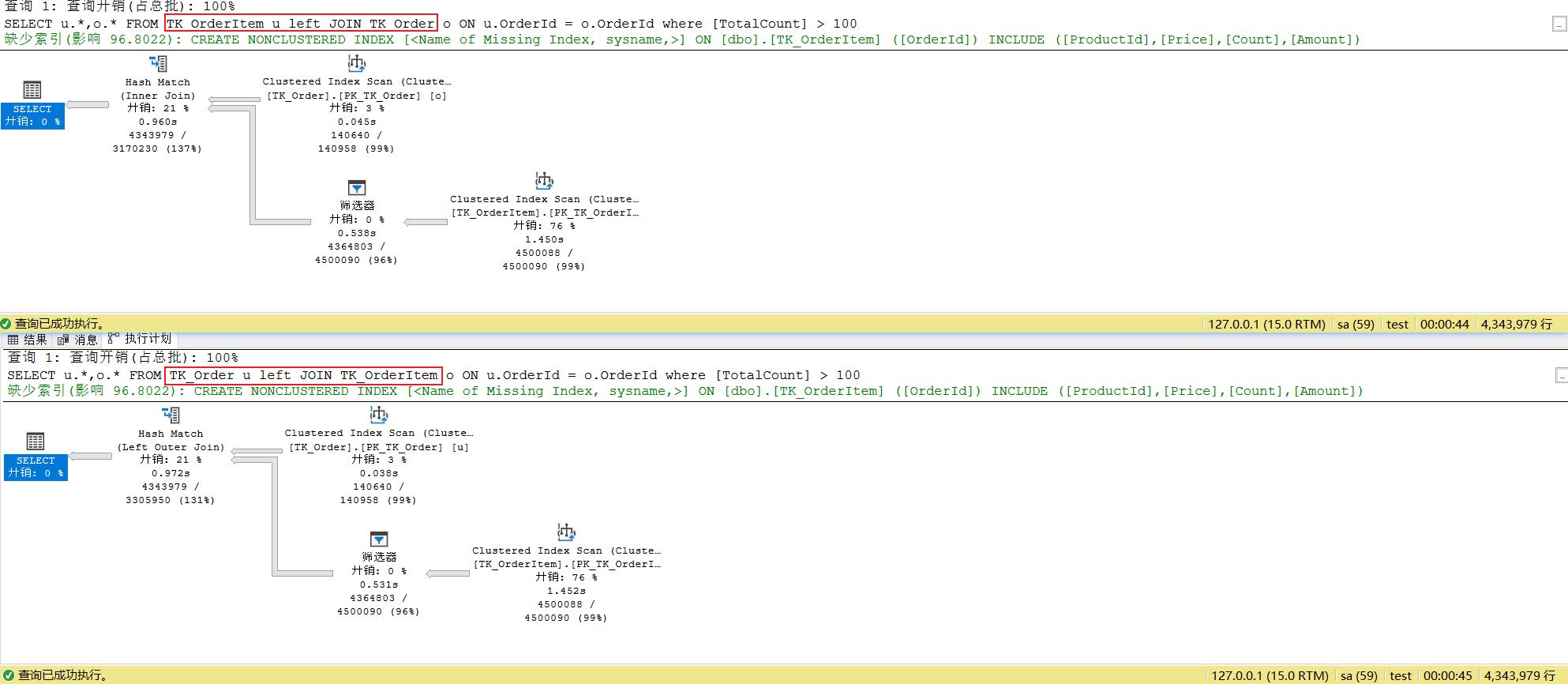
百思不得其解,还是查一查吧。原来在SqlServer中使用连接查询,表的顺序不会影响查询效率。因为在执行过程中,SqlServer查询优化器总是能够基于统计信息(where查询后)来决定那张表作为驱动表——使用最小表作为物理联接运算符的外表
参考:Join的表顺序 - Woodytu - 博客园 (cnblogs.com)
join连接的字段
如果可以的话,尽可能的返回指定字段,字段越少效率越快。如下这两条Sql语句,同样的条件,查询效率相差了近两倍
xxxxxxxxxx-- 12sSELECT u.*,o.* FROM TK_Order uinner JOIN TK_OrderItem o ON u.OrderId = o.OrderIdwhere [TotalCount] < 1000
-- 7sSELECT u.OrderId,u.TotalAmount,u.TotalCount,o.Amount,o.[Count] FROM TK_Order uinner JOIN TK_OrderItem o ON u.OrderId = o.OrderIdwhere [TotalCount] < 1000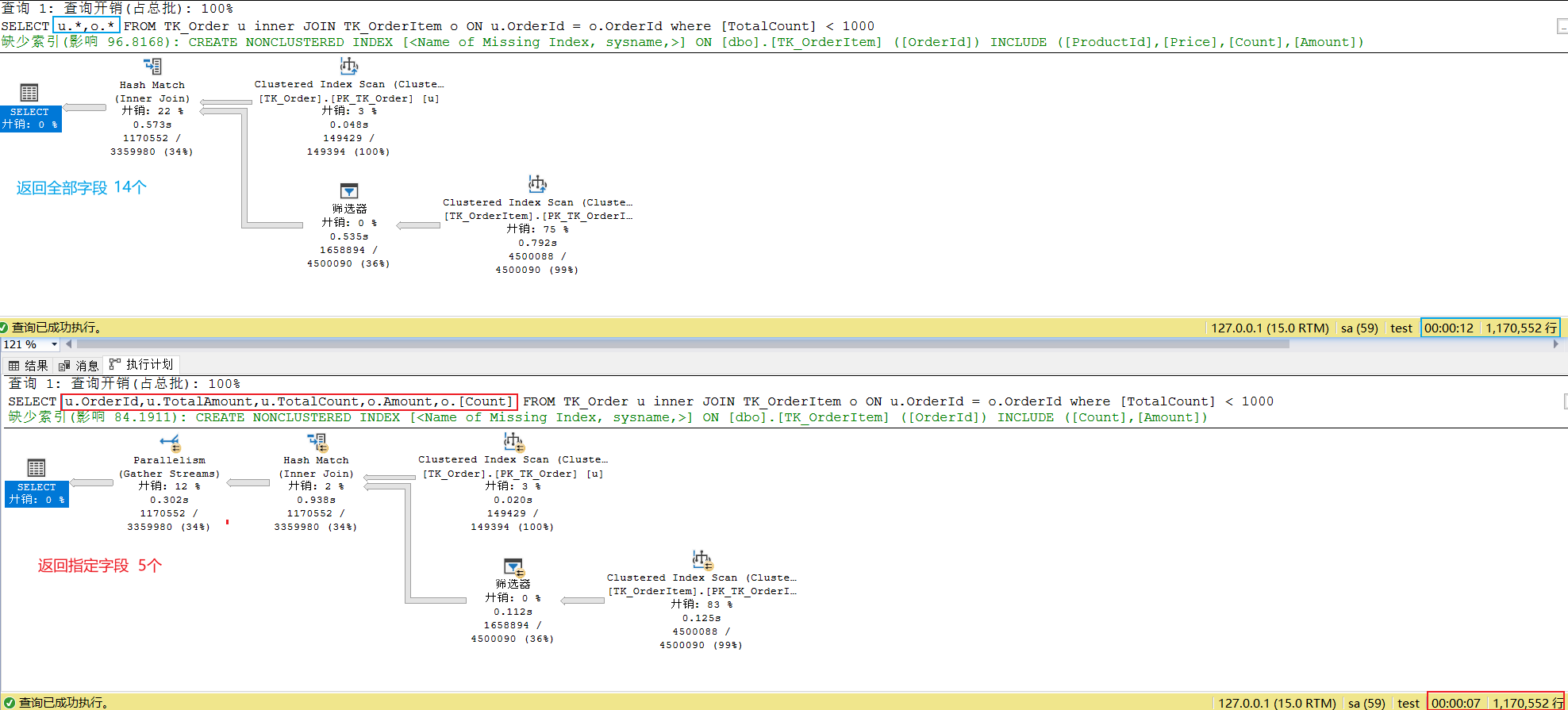
优化总结
xxxxxxxxxxSELECT u.TotalAmount,u.TotalCount,o.Amount,o.[Count] FROM TK_Order uleft JOIN TK_OrderItem o ON u.OrderId = o.OrderIdwhere o.[Count] > 80如上代码,在SqlServer中join优化可以从这几方面入手:
- 尽可能把查询条件放在Where中,给关联表的相关查询字段创建索引,使用索引查询——给表TK_OrderItem字段[Count]创建索引
- 给被驱动表的关联字段创建索引——给表TK_OrderItem字段OrderId创建索引
- 避免使用select *,尽可能的返回指定字段——SELECT u.TotalAmount,u.TotalCount...
- 建议关联查询连接不超过三张表(效率低、可读性差、难维护)——复杂逻辑一定要查询多张表的话可以利用代码来实现,而不是一味的join
- 业务不要求排序则尽量不排序
- 增加join_buffer_size缓存区——仅针对Mysql
- 小表驱动大表——仅针对Mysql
其他
join 连接的条件
join 连接的条件应该怎么放?下面讲一下left join on 加条件和where加条件的区别
on和where都可以进行数据筛选,建议将查询条件放在Where中,on仅处理关联条件,其他条件由Where处理。
- 原因一:将条件放在Where中,可以适当利用关联表的索引提高查询效率
一般情况下,on关联后会将关联后的数据放到一张临时表中,然后在临时表中执行Where查询。
在某些情况下,数据库优化器会选择在内存中进行连接操作,而不是创建临时表,此时会尝试利用关联表的索引来加速查询。这种方式可以避免额外的磁盘 I/O 操作和临时表的创建,从而提高查询效率。(From AI.)
- 原因二:在外连接中,将条件放在on中可能会影响查询结果
参考:LEFT JOIN关联表中ON,WHERE后面跟条件的区别_left join on 加条件和where加条件的区别-CSDN博客
在inner join关联查询中,因为左右两张表一定会匹配数据,所以条件放在where和on结果都是一样的。
在左(右、全)外连接中不管on条件是否为真都会返回左(右边、左右两张表)的全部数据,此时数据可能不准确,如下图。
xxxxxxxxxxSELECT u.TotalAmount,u.TotalCount,o.Amount,o.[Count] FROM TK_Order uleft JOIN TK_OrderItem o ON u.OrderId = o.OrderId and [Count] > 80order by [Count] desc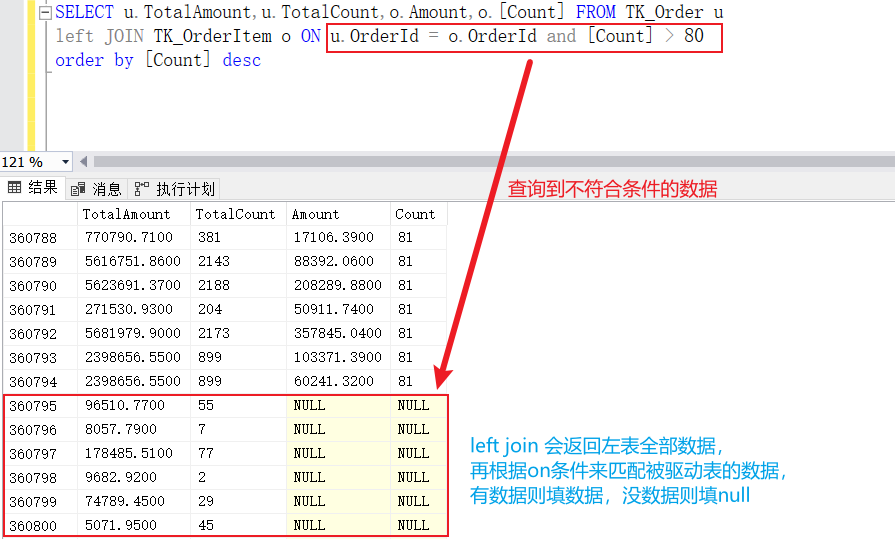
原来left join 会返回左表全部数据,再根据on条件来匹配被驱动表的数据,如果条件匹配则填充数据,不匹配则保留null。相当于on仅仅用来作为匹配右表的条件,但是不能筛选数据表的数据,此时我们需要通过Where再次查询才能得到想要的结果,那为什么不直接把条件放在Where呢?如下图
xxxxxxxxxxSELECT u.TotalAmount,u.TotalCount,o.Amount,o.[Count] FROM TK_Order uleft JOIN TK_OrderItem o ON u.OrderId = o.OrderId and [Count] > 80where [Count] > 80order by [Count] desc
SELECT u.TotalAmount,u.TotalCount,o.Amount,o.[Count] FROM TK_Order uleft JOIN TK_OrderItem o ON u.OrderId = o.OrderIdwhere [Count] > 80order by [Count] desc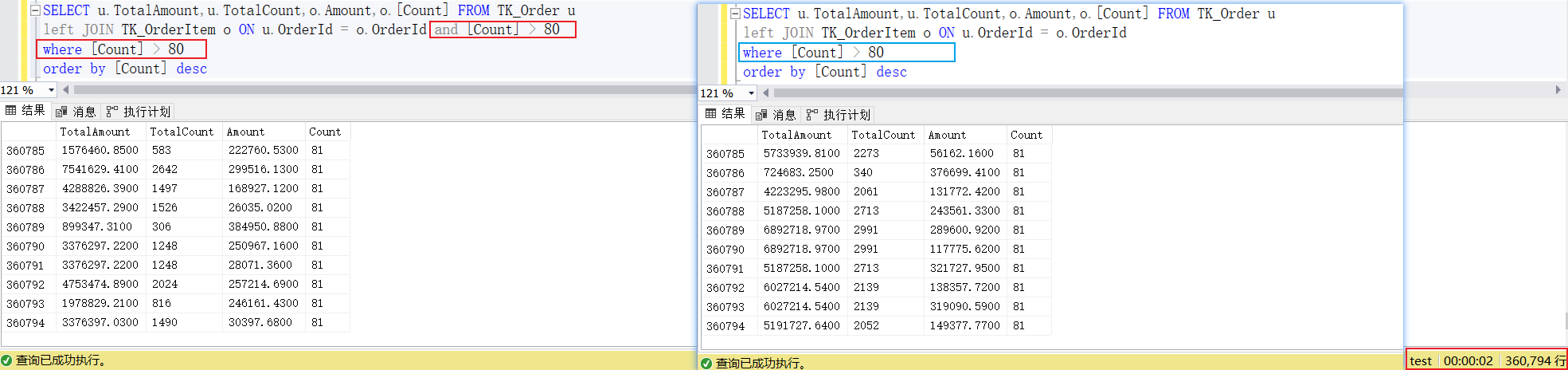
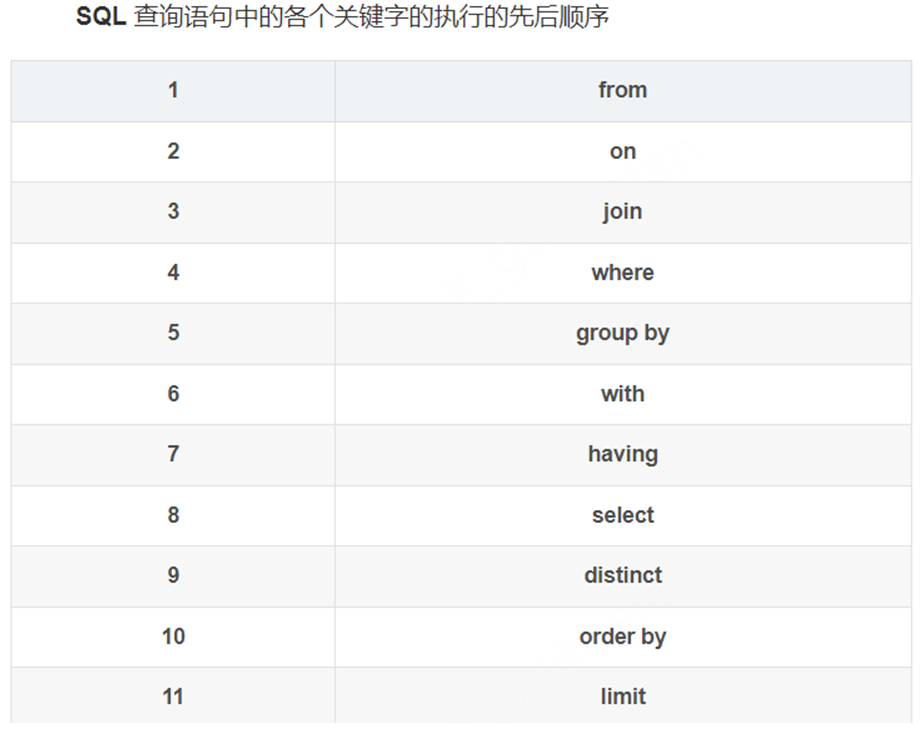
join连接执行顺序
Sql查询语句的各个关键词执行的先后顺序(mysql版,其他数据库也大差不差)
From、On、Join、Where、Group by、With、Having、Select、Distinct、Order by、Limit(Top)