redis整理03——redis数据持久化、主从模式、主从模式+哨兵机制以及分片集群
>说明单点redis的问题redis持久化redis配置文件RDBAOF主从模式—Replica主从模式图解配置文件redis.conf7001——主节点7002——从节点7003——从节点主从演示c#代码演示故障演示一键部署主从模式哨兵机制—Sentinel哨兵机制图解哨兵三大功能配置文件sentinel.confs1-7005s2-7006s3-7007哨兵及故障演示更多哨兵常用命令c#代码演示常见问题一键启动哨兵一键关闭哨兵分片集群—Cluster分片集群图解配置文件cluster.conf一键部署关闭集群创建集群分片集群演示故障演示c#代码演示redis集群常见命令——cluster插槽相关节点相关故障转移redis集群常见命令——redis-cli节点相关插槽相关其他常见问题总结
说明
linux(contos)、redis7.0+、.net core6.0+、docker
记录一下redis数据持久化、主从同步、哨兵机制、分片集群相关内容,使用docker部署
为了方便,本文是在同一台机器上演示的集群,正常情况下要在不同的机器部署节点,真别傻乎乎的在同一个机器部署集群,集群性能没有任何提升
单点redis的问题
单点redis实例可处理每秒数万到数十万的请求,一些小项目已经足够。但是如果业务比较复杂——并发更高、数据量更大,单点redis可能会出现以下问题:
- 数据丢失——修改RDB、AOF的存储配置
- 并发能力不足——搭建主从集群,实现读写分离。master主节点写数据、从节点读取数据
- 故障恢复——添加哨兵机制,健康检测,故障恢复
- 存储能力——搭建分片集群,每个分片存储不同的数据
redis持久化
redis持久化数据可分为RDB和AOF两种方式,不指定任何配置时默认使用RDB持久化的方式,两者各有各的优势,也可以结合两者使用。
redis容器内部没有配置文件,需要自己映射或者把配置内容写道docker run命令,建议使用配置文件启动
xdocker pull redis:7.0# 创建目录并复制conf文件并进入目录mkdir -p test-redis-rdb-aof/conf && cp redis7.conf test-redis-rdb-aof/conf/redis7.conf && cd test-redis-rdb-aof# 启动redis挂载磁盘并使用docker run -d -p 6380:6379 \--name test-redis-rdb-aof \--restart=always \-v /home/redis-test/test-redis-rdb-aof/data:/data \-v /home/redis-test/test-redis-rdb-aof/conf/redis7.conf:/etc/redis/redis.conf \redis:7.0 redis-server /etc/redis/redis.conf# redis-server /etc/redis/redis.conf 指定(挂载的)配置文件启动redis# 查看test-的容器信息docker ps | grep test-# 进入容器docker exec -it id bash# 连接redisredis-cli# redis命令:设置rediskey缓存MSET name Tom age 10# redis命令:查看redis的rdb、aof配置CONFIG get save dbfilename appendonlyredis配置文件
redis7.0的配置文件详解——redis-7.0.conf,默认的配置文件是开启RDB持久化方式,禁用AOF持久化方式
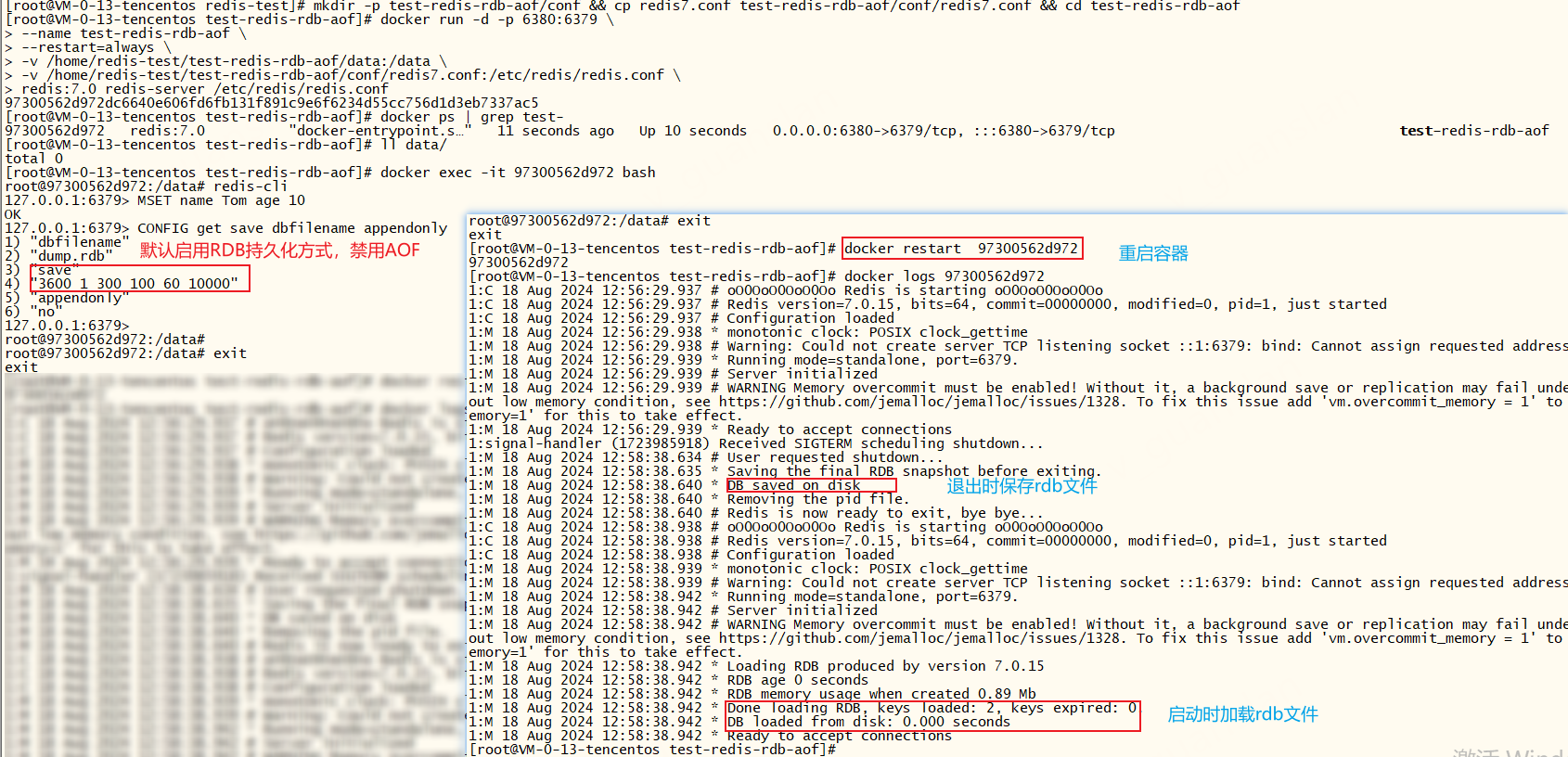
redis重点关注配置
xxxxxxxxxx# 指定 Redis 服务器监听的 IP 地址。 127.0.0.1 表示 localhost,::1 表示 IPv6 localhost。0.0.0.1 外网bind 127.0.0.1 -::1# Redis 服务器监听的端口号,默认是 6379。port 6379# 日志级别,可选择 debug, verbose, notice, warning, error, fatal。loglevel notice# 日志文件路径。如果为空,则不记录日志。logfile ""##### ##### ###RDB 相关配置 ##### ##### #####启用RDB,并设置什么时候保存一次# save 3600 1 300 100 60 10000# RDB文件名称。dbfilename dump.rdb# Redis 数据文件所在的目录。dir ./##### ##### ###AOF 相关配置 ##### ##### ##### 关闭 AOFappendonly no# AOF 日志文件名称。appendfilename "appendonly.aof"# AOF 日志文件目录。appenddirname "appendonlydir"# AOF 日志文件同步频率,单位秒。appendfsync everysec# 在 AOF 日志文件记录时间戳。 # 与6.0有区别aof-timestamp-enabled no##### ##### ###慢查询设置 ##### ##### ##### 记录慢查询的时间阈值,单位毫秒。slowlog-log-slower-than 10000# 慢查询日志最大长度。slowlog-max-len 128redis7.0配置文件详解,去掉注释了有需要请查看官方原版文件,更多配置文件请查看:Redis conf
xxxxxxxxxx##### ##### ##### ###服务器基本设置# 指定 Redis 服务器监听的 IP 地址。 127.0.0.1 表示 localhost,::1 表示 IPv6 localhost。bind 127.0.0.1 -::1# 启用保护模式,只能从本机连接protected-mode yes# Redis 服务器监听的端口号,默认是 6379。port 6379# TCP 连接队列长度,决定了服务器可以同时处理多少个连接请求tcp-backlog 511# 客户端连接的超时时间,单位秒。 0 表示永不过期。timeout 0# TCP 长连接保持心跳的时间间隔,单位秒。tcp-keepalive 300# 是否以守护进程运行。 yes 表示以守护进程运行,no 表示以前台进程运行。daemonize no# Redis 进程 ID 文件路径。pidfile /var/run/redis_6379.pid##### ##### ##### ##日志设置# 日志级别,可选择 debug, verbose, notice, warning, error, fatal。loglevel notice# 日志文件路径。如果为空,则不记录日志。logfile ""# 数据库数量。databases 16##### ##### ##### ##其他设置# 启动时是否显示 Redis 版本信息。 # 与6.0有区别always-show-logo no# 设置进程标题。 # 与6.0有区别set-proc-title yes# 进程标题模板。 # 与6.0有区别proc-title-template "{title} {listen-addr} {server-mode}"# 在后台保存数据库文件失败时,阻止写入操作。stop-writes-on-bgsave-error yes# 启用 RDB 文件压缩。rdbcompression yes# 在 RDB 文件中添加校验和。rdbchecksum yes# RDB文件名称。dbfilename dump.rdb# 删除同步文件。rdb-del-sync-files no# Redis 数据文件所在的目录。dir ./##### ##### ##### ##### 复制设置# 允许从服务器返回旧数据。replica-serve-stale-data yes# 从服务器只读模式。replica-read-only yes# 磁盘less 复制模式。 # 与6.0有区别repl-diskless-sync yes# 磁盘less 复制延迟时间,单位秒。repl-diskless-sync-delay 5# 磁盘less 复制最大副本数。# 与6.0有区别repl-diskless-sync-max-replicas 0# 磁盘less 加载模式。repl-diskless-load disabled# 禁用 TCP 节点延迟。repl-disable-tcp-nodelay no# 从节点优先级,默认都是100,越高则越容易被选为主节点replica-priority 100# 内存设置acllog-max-len 128# 延迟释放内存。lazyfree-lazy-eviction no# 延迟过期。lazyfree-lazy-expire no# 延迟删除服务器。lazyfree-lazy-server-del no# 延迟刷新。replica-lazy-flush no# 延迟删除用户。lazyfree-lazy-user-del no# 延迟刷新用户。lazyfree-lazy-user-flush no# 调整内存分配优先级。oom-score-adj no# 内存分配优先级值。oom-score-adj-values 0 200 800# 禁用 Transparent Huge Pages。 # 与6.0有区别disable-thp yes# 日志设置# 启用 AOFappendonly no# AOF 日志文件名称。appendfilename "appendonly.aof"# AOF 日志文件目录。appenddirname "appendonlydir"# AOF 日志文件同步频率,单位秒。appendfsync everysec# 在重写 AOF 日志文件时不进行同步。no-appendfsync-on-rewrite no# 自动重写 AOF 日志文件百分比。auto-aof-rewrite-percentage 100# 自动重写 AOF 日志文件最小大小,单位 MB。auto-aof-rewrite-min-size 64mb# 加载截断的 AOF 日志文件。aof-load-truncated yes# 在 AOF 日志文件开头添加 RDB 预备语。aof-use-rdb-preamble yes# 在 AOF 日志文件记录时间戳。# 与6.0有区别aof-timestamp-enabled no##### ##### ###慢查询设置# 记录慢查询的时间阈值,单位毫秒。slowlog-log-slower-than 10000# 慢查询日志最大长度。slowlog-max-len 128##### ##### ####其他设置# 延迟监控阈值。latency-monitor-threshold 0# 通知事件。notify-keyspace-events ""# 哈希表最大列表长度。hash-max-listpack-entries 512# 哈希表最大值长度。hash-max-listpack-value 64# 列表最大大小。list-max-listpack-size -2# 列表压缩深度。list-compress-depth 0# 集合最大元素数量。set-max-intset-entries 512# zset 最大列表长度。zset-max-listpack-entries 128# zset 最大值长度。zset-max-listpack-value 64# hll 稀疏最大字节数。hll-sparse-max-bytes 3000# 流节点最大字节数。stream-node-max-bytes 4096# 流节点最大条目数。stream-node-max-entries 100# 启用主动哈希。activerehashing yes# 客户端输出缓冲区大小。client-output-buffer-limit normal 0 0 0# 复制客户端输出缓冲区大小。client-output-buffer-limit replica 256mb 64mb 60# 订阅客户端输出缓冲区大小。client-output-buffer-limit pubsub 32mb 8mb 60# Redis 心跳频率,单位 Hz。hz 10# 动态调整心跳频率。dynamic-hz yes# 启用增量文件同步。aof-rewrite-incremental-fsync yes# 启用增量文件同步。rdb-save-incremental-fsync yes# 启用 jemalloc 后台线程。jemalloc-bg-thread yes# 设置节点密码# requirepass mypassword# 设置主节点密码,请保证主从节点的密码一致# masterauth mypassword# 从节点中执行,# replicaof masterip masterportRDB
RDB:Redis Database,定时对整个内存做快照,宕机时恢复数据快、迁移方便、自动压缩文件体积小但是丢失数据较多(两次备份期间未持久化的数据将全部丢失),做快照时占用大量CPU和内存资源
准备RDB配置文件
xxxxxxxxxx##### ##### ###RDB 相关配置 ##### ##### #####启用RDB,并设置什么时候保存一次 在3600秒内有一次key变更、300秒内有100次key变更、...则保存save 3600 1 300 100 60 10000# RDB文件名称。dbfilename dump.rdb# Redis 数据文件所在的目录。dir ./使用RDB持久化配置运行redis
xxxxxxxxxxmkdir -p test-redis-rdb/conf && cd test-redis-rdbvim conf/redis7-rdb.conf# 启动redis挂载磁盘并使用docker run -d -p 6380:6379 \--name test-redis-rdb \--restart=always \-v /home/redis-test/test-redis-rdb/data:/data \-v /home/redis-test/test-redis-rdb/conf/redis7-rdb.conf:/etc/redis/redis.conf \redis:7.0 redis-server /etc/redis/redis.conf# redis-server /etc/redis/redis.conf 指定(挂载的)配置文件启动redis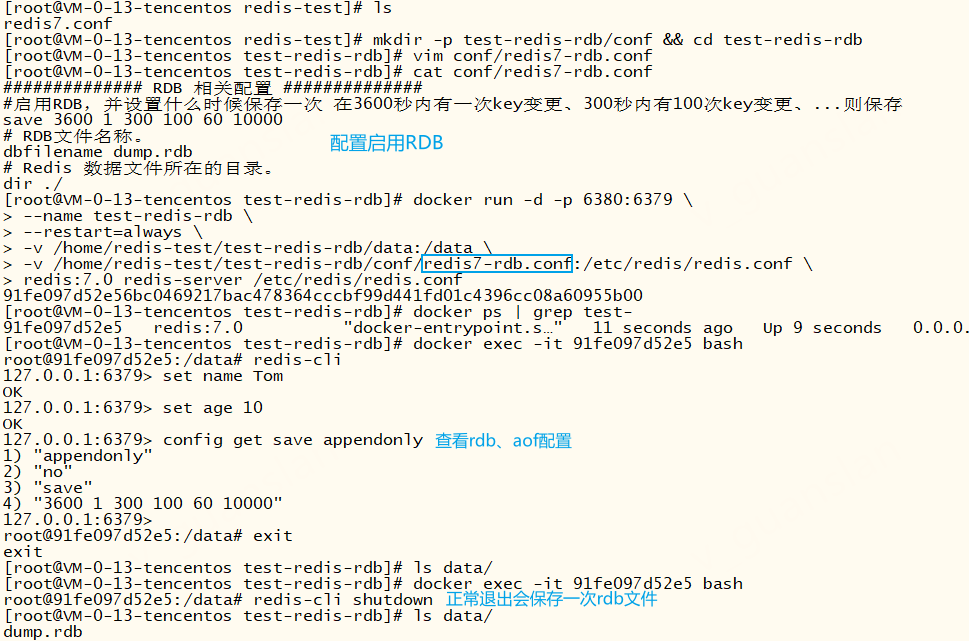
由以下的redis日志可以看出,启用rdb持久化时,正常退出会保存rdb文件(配置文件dbfilename),启动redis会加载rdb文件
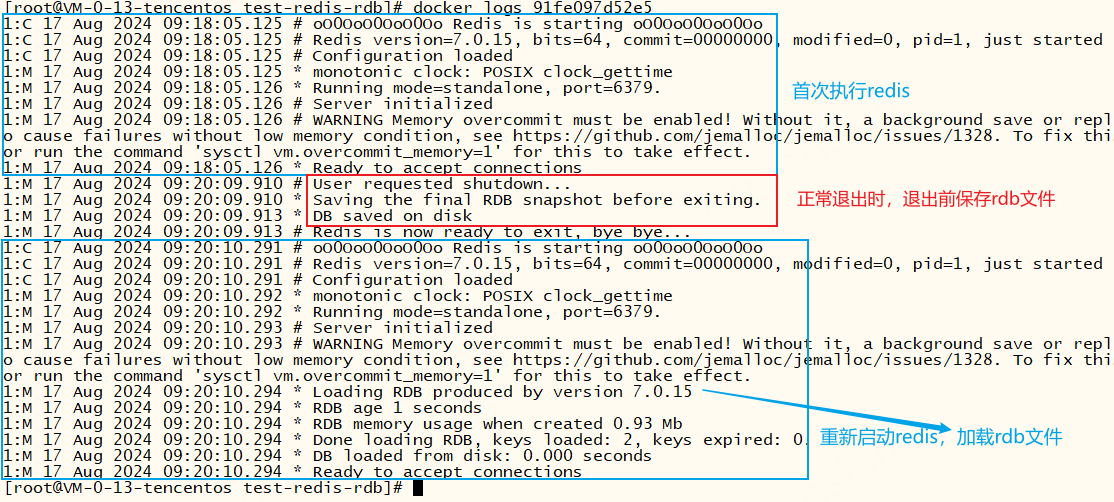
docker stop、docker restart 命令都会保存一次rdb文件、docker kill、docker pause 命令或突然关机、宕机时不会保存rdb文件,这就会导致数据丢失
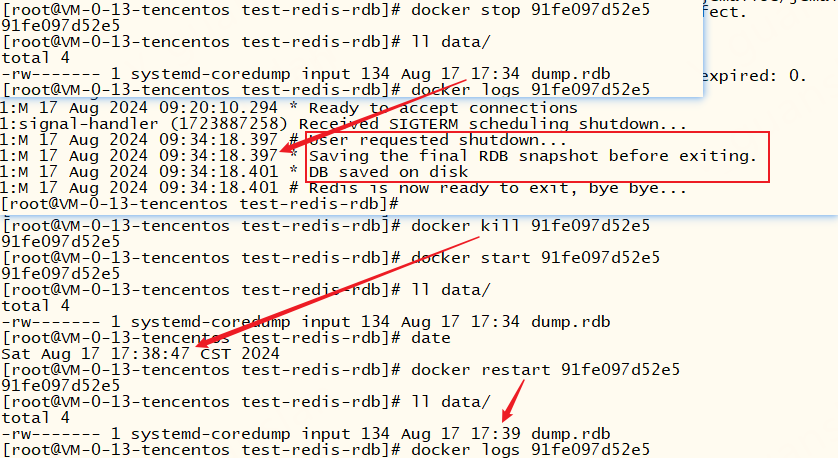
除此之外,我们还可以使用SAVE、BGSAVE这两个命令主动保存rdb文件、key的变更频率达到3600 1 300 100 60 10000也会触发保存文件
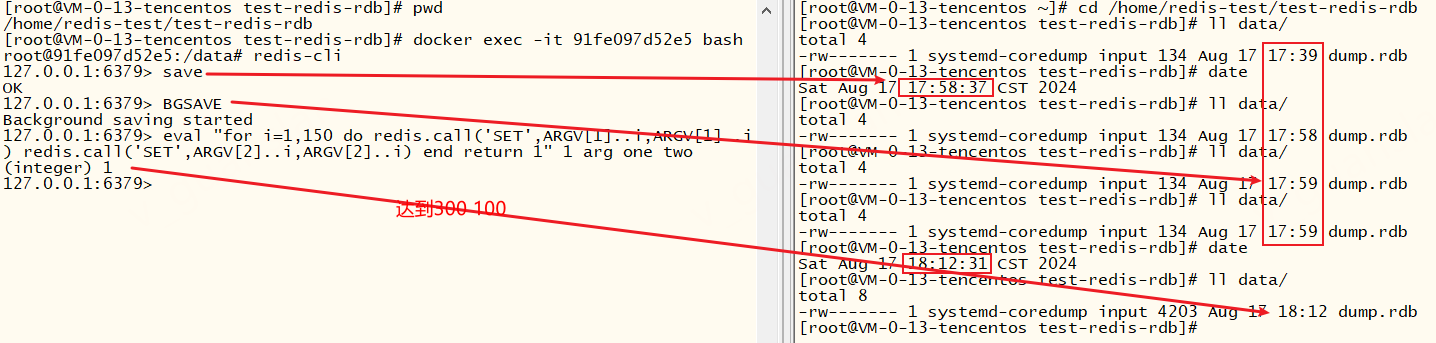
总结:启用rdb持久化时,正常退出会保存rdb文件、启动时会加载rdb文件。所以有了rdb文件,迁移数据是很简单的。但是rdb文件的保存是不固定的,所以宕机时可能会丢失部分数据。我们可以修改save配置提高保存rdb文件的频率,但是不建议这样做。因为每次都是全量保存(先做快照再替换旧rdb文件),需要占用大量cpu和内存资源
AOF
AOF:Append Only File,记录每一次执行的redis命令,宕机恢复数据较慢(恢复数据时要重新执行这些命令)、文件体积较大但是数据相对完整可做到最多只会丢失一秒的数据(推荐使用everysec配置),主要消耗磁盘IO资源,不会大量占用cpu和内存资源(不过AOF重写还是会占用消耗cpu和内存资源)
准备AOF配置文件
xxxxxxxxxx##### ##### ###AOF 相关配置 ##### ##### ##### 关闭rdb,或者指定频率低一点 save 86000 1 => 每天至少有一个key变更则备份一次save ""# 启用 AOFappendonly yes# AOF 日志文件名称。appendfilename "appendonly.aof"# AOF 日志文件目录。appenddirname "appendonlydir"# AOF 日志文件同步频率。everysec、always、noappendfsync everysec# 在 AOF 日志文件记录时间戳。 # 与6.0有区别aof-timestamp-enabled no使用AOF持久化配置运行redis
xxxxxxxxxxmkdir -p test-redis-aof/conf && cd test-redis-aofvim conf/redis7-aof.conf# 启动redis挂载磁盘并使用docker run -d -p 6380:6379 \--name test-redis-aof \--restart=always \-v /home/redis-test/test-redis-aof/data:/data \-v /home/redis-test/test-redis-aof/conf/redis7-aof.conf:/etc/redis/redis.conf \redis:7.0 redis-server /etc/redis/redis.conf# redis-server /etc/redis/redis.conf 指定(挂载的)配置文件启动redis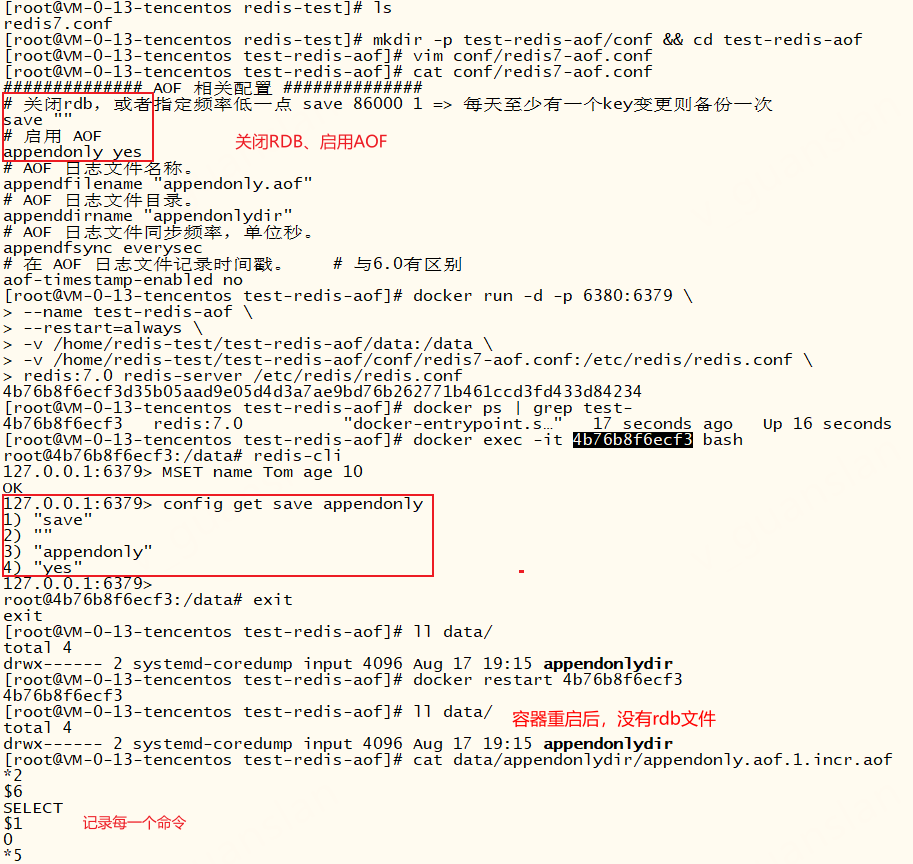
AOF 日志文件同步频率参数取值有三个选项:everysec、always、no,推荐使用everysec。
always,每次执行写操作都将命令写入磁盘(1秒有十次写操作,则写入十次)。这是最安全的选项,性能最差(IO磁盘写入)
everysec,每秒将数据写入磁盘(1秒有十次写操作,则写入一次)。这是较为安全的选项,推荐使用,降低性能(IO磁盘写入)
no,不将数据写入磁盘,最不安全的选项,性能最高
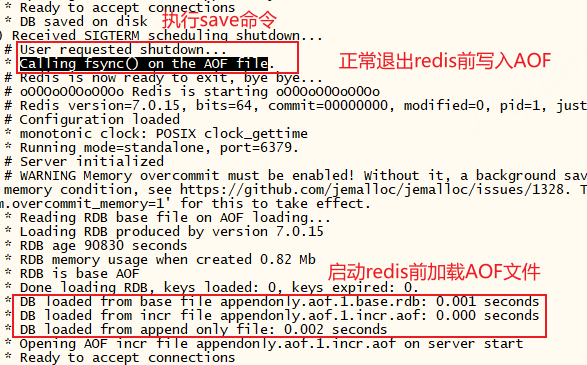
不开启RDB,仍然可以通过SAVE、BGSAVE命令保存RDB文件,重启容器,我们在日志可以看到,退出容器前会再次(写入)同步AOF文件,启动容器时也会加载AOF文件
AOF重写
随着数据量越来越多,AOF文件不断增大,可以通过以下配置控制 AOF 重写,将 AOF 文件中的冗余数据和不必要的记录删除,从而减小 AOF 文件的大小,提高读写性能
no-appendfsync-on-rewrite是否禁用在 AOF 重写过程中对磁盘的同步操作。为yes的话,重写时Redis 将不会将数据立即写入磁盘,而是将数据缓存在内存中,可以提高AOF重写的速度,但是也会有数据丢失的风险auto-aof-rewrite-percentage当 AOF 文件的大小增长到这个百分比时,Redis 会自动启动 AOF 重写过程。auto-aof-rewrite-min-size: 当 AOF 文件的大小超过这个字节数时,Redis 会自动启动 AOF 重写过程
总结:启用AOF持久化时,会将我们执行的每一条命令按一定的频率写入文件中,推荐使用everysec配置。随着数据增大,AOF文件不断增大,大到一定程度会对AOF文件进行重写,缩小文件大小从而提高读写性能。虽然有重写,但AOF文件体积也要远远大于RDB文件。不过写入AOF文件仅占用IO磁盘资源,而且还可以控制数据丢失范围在一秒以内,相对于RDB持久化方式AOF持久化方式占用cpu内存资源小,数据更安全
主从模式—Replica
接下来我们来处理单点redis读并发能力不足的问题。举个例子,假如一台redis实例A能抗下每秒1万次读并发请求,那并发量提高一倍,我们可不可以再增加一台redis实例B,处理另外一万次读并发请求呢?答案肯定是可以的,不可以的话就不会问的那么刻意了...那应该怎么实现呢?
主从模式图解
主从模式,自动实现读写分离
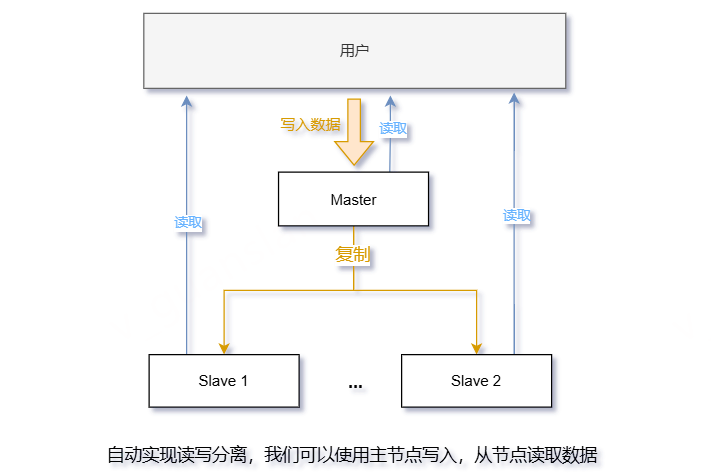
数据同步原理,参考:高级篇-分布式缓存-08-Redis主从-主从的全量同步原理哔哩哔哩bilibili
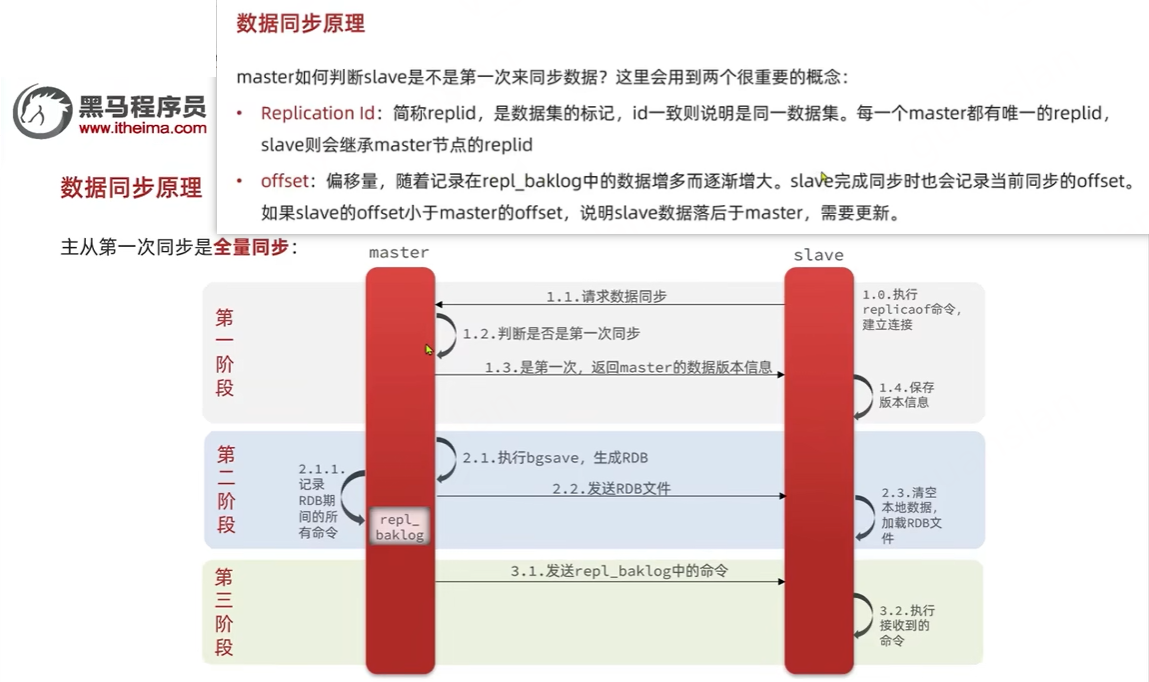
配置文件redis.conf
xxxxxxxxxx# bind 127.0.0.1 -::1 0.0.0.0外网可访问bind 0.0.0.0# 指定端口port 6379# 指定节点密码requirepass 123456# 指定主节点的密码masterauth 123456# 永久指定主从关系,重启后仍可用# replicaof 0.0.0.0 7001# 开启rdbsave 3600 1 300 100 60 10000# 关闭AOF appendonly no公网服务器还需要设置安全组开放指定端口,谨慎操作

7001——主节点
xxxxxxxxxx# 开放7001端口,真正的服务器还得在服务器商控制台开放7001端口。测试环境请忽略firewall-cmd --zone=public --add-port=7001/tcp --add-port=6379/tcp --permanentfirewall-cmd --reloadmkdir -p test-redis-replica/7001/conf# vim补充上面的配置文件vim test-redis-replica/7001/conf/redis-re.conf# 启动容器docker run -d -p 7001:6379 --name test-redis-7001 --restart=always \-v /home/redis-test/test-redis-replica/7001/data:/data \-v /home/redis-test/test-redis-replica/7001/conf/redis-re.conf:/etc/redis/redis.conf \redis:7.0 redis-server /etc/redis/redis.conf# 哨兵下使用,需要更改映射并添加写权限,避免主从切换时出现无权限更新配置文件错误,更推荐使用这种方式启动#docker run -d -p 7003:6379 --name test-redis-7003 --restart=always \# -v /home/redis-test/test-redis-replica/7003/data:/data \# -v /home/redis-test/test-redis-replica/7003/conf:/etc/redis/conf \# redis:7.0 redis-server /etc/redis/conf/redis-re.conf## chmod 777 /home/redis-test/test-redis-replica/7003/conf# 查看当前机器的ipip a | grep eth0 # 取出ip
7002——从节点
xxxxxxxxxx# 开放端口7002firewall-cmd --zone=public --add-port=7002/tcp --permanentfirewall-cmd --reloadmkdir -p test-redis-replica/7002/conf# vim补充上面的配置文件vim test-redis-replica/7002/conf/redis-re.conf# 替换 replicaof 的ip为7001机器的ip(可以使用公网IP,测试环境可以使用ip -a 查出来的IP),记住要开放7001端口sed -i 's/# replicaof 0.0.0.0 7001/replicaof 119.45.100.200 7001/' test-redis-replica/7002/conf/redis-re.conf# 启动容器docker run -d -p 7002:6379 --name test-redis-7002 --restart=always \-v /home/redis-test/test-redis-replica/7002/data:/data \-v /home/redis-test/test-redis-replica/7002/conf/redis-re.conf:/etc/redis/redis.conf \redis:7.0 redis-server /etc/redis/redis.conf# 哨兵下使用,需要更改映射并添加写权限,避免主从切换时出现无权限更新配置文件错误,更推荐使用这种方式启动#docker run -d -p 7003:6379 --name test-redis-7003 --restart=always \# -v /home/redis-test/test-redis-replica/7003/data:/data \# -v /home/redis-test/test-redis-replica/7003/conf:/etc/redis/conf \# redis:7.0 redis-server /etc/redis/conf/redis-re.conf## chmod 777 /home/redis-test/test-redis-replica/7003/conf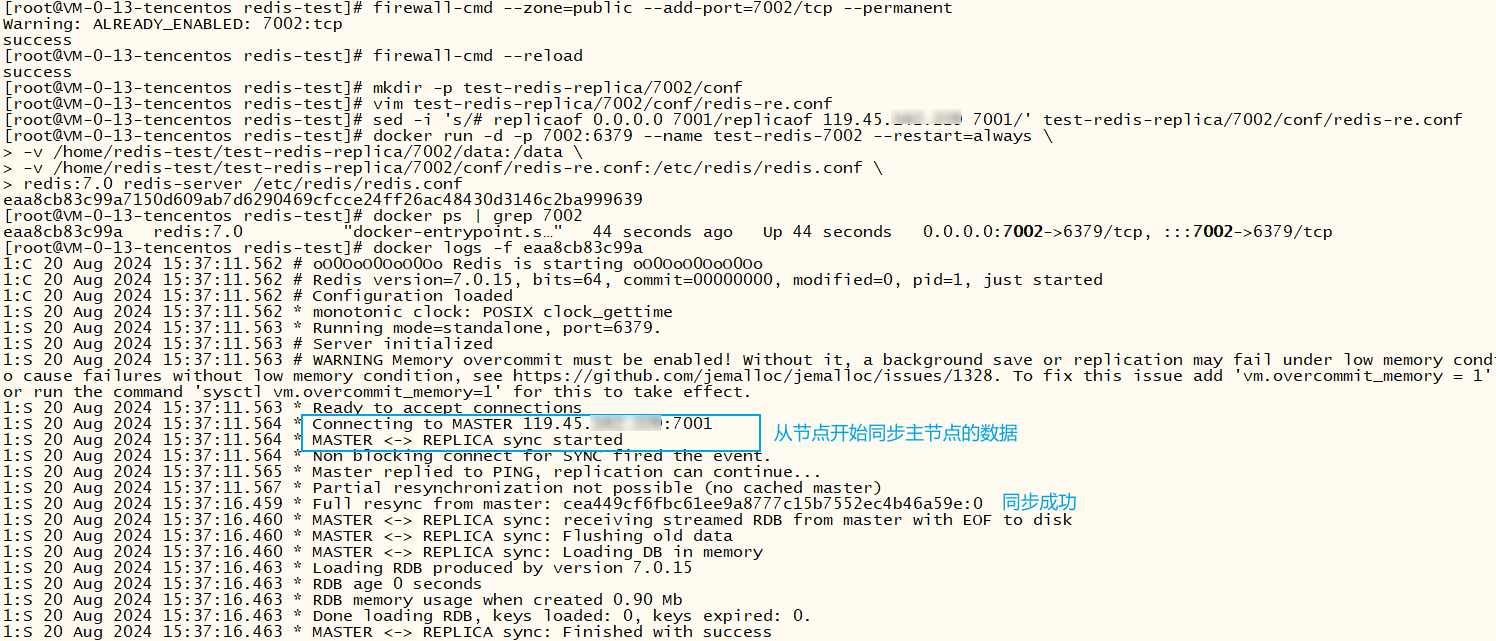
7003——从节点
xxxxxxxxxx# 开放端口7003firewall-cmd --zone=public --add-port=7003/tcp --permanentfirewall-cmd --reloadmkdir -p test-redis-replica/7003/conf# vim补充上面的配置文件vim test-redis-replica/7003/conf/redis-re.conf# 替换 replicaof 的ip为7001机器的ip(可以使用公网IP,测试环境可以使用ip -a 查出来的IP),记住要开放7001端口sed -i 's/# replicaof 0.0.0.0 7001/replicaof 10.206.0.13 7001/' test-redis-replica/7003/conf/redis-re.conf# 启动容器docker run -d -p 7003:6379 --name test-redis-7003 --restart=always \-v /home/redis-test/test-redis-replica/7003/data:/data \-v /home/redis-test/test-redis-replica/7003/conf/redis-re.conf:/etc/redis/redis.conf \redis:7.0 redis-server /etc/redis/redis.conf# 哨兵下使用,需要更改映射并添加写权限,避免主从切换时出现无权限更新配置文件错误,更推荐使用这种方式启动#docker run -d -p 7003:6379 --name test-redis-7003 --restart=always \# -v /home/redis-test/test-redis-replica/7003/data:/data \# -v /home/redis-test/test-redis-replica/7003/conf:/etc/redis/conf \# redis:7.0 redis-server /etc/redis/conf/redis-re.conf## chmod 777 /home/redis-test/test-redis-replica/7003/conf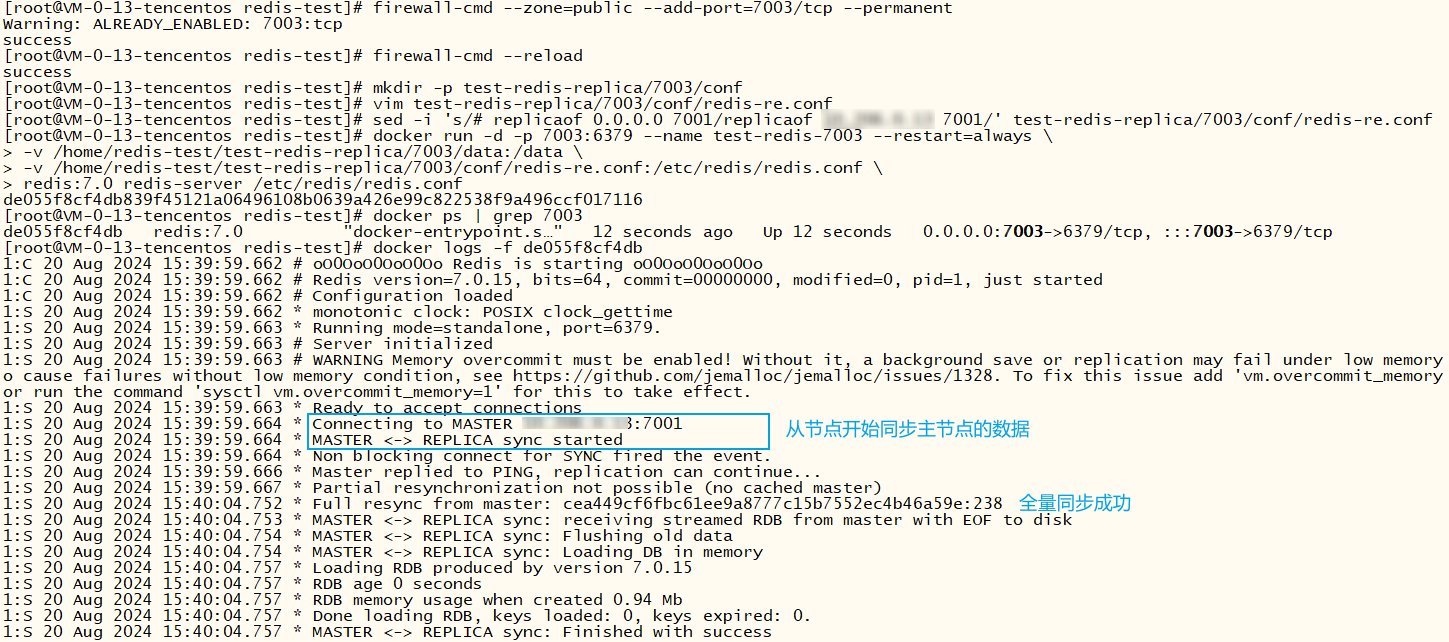
主从演示
xxxxxxxxxx# 查看主从节点信息info replication主节点可读写,从节点仅可读,所以我们可以把读的请求分给从节点处理
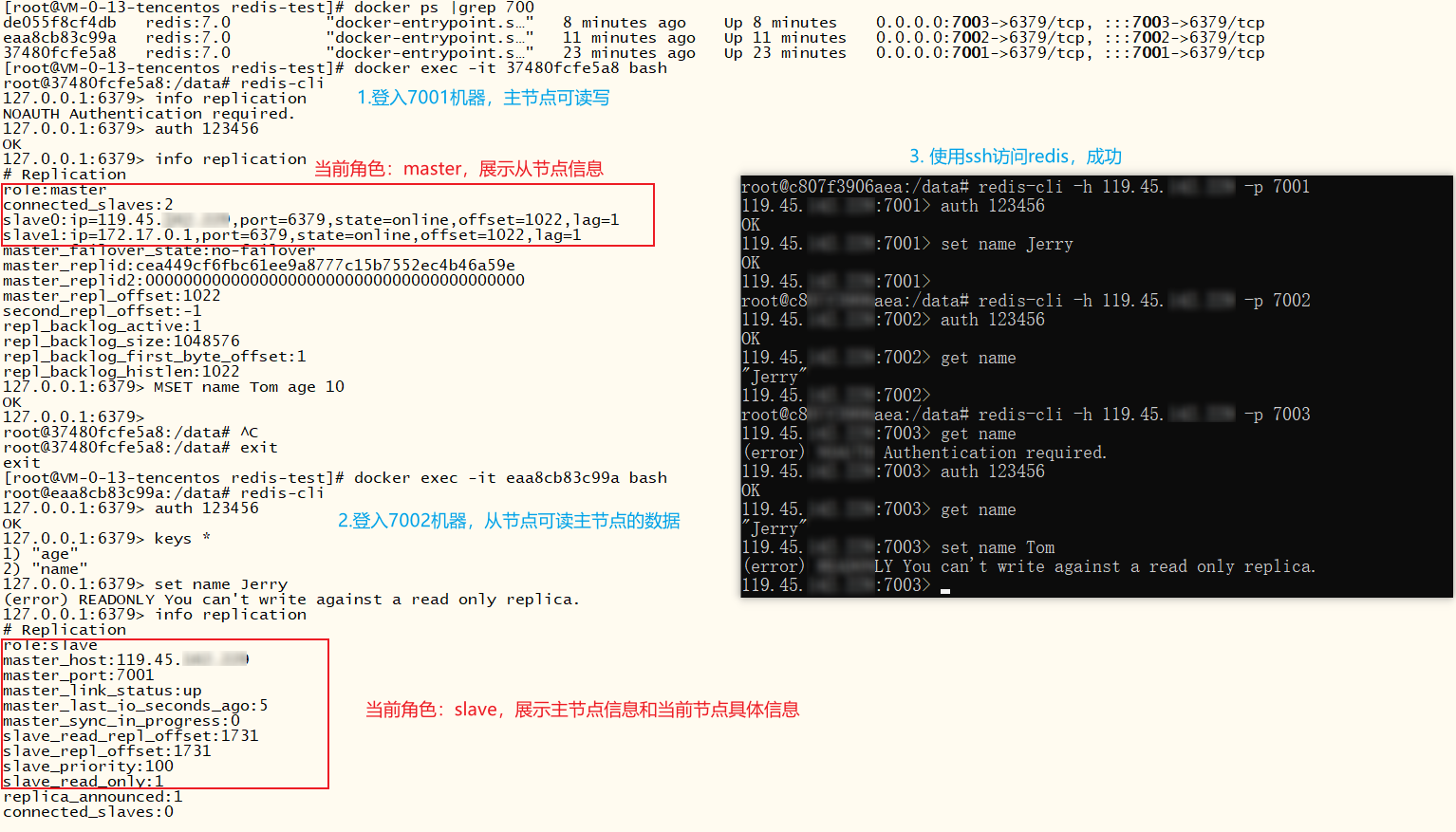
c#代码演示
以下演示一下c#代码如何连接并使用主从模式,源码参考:redis 兼容主从复制 · logerlink/RedisTest@043a31e (github.com)
redis主从模式连接字符串
xxxxxxxxxx"ConnectionStrings": { "Redis": "119.45.100.100:7001,119.45.100.100:7002,119.45.100.100:7003,password=123456" },redis 帮助类改造——CommandFlags.PreferReplica优先从节点读取数据
xxxxxxxxxx /// <summary> /// 设置 key 并保存字符串(如果 key 已存在,则覆盖值) /// </summary> /// <param name="redisKey"></param> /// <param name="redisValue"></param> /// <param name="expiry"></param> /// <returns></returns> public bool StringSet(string redisKey, string redisValue, TimeSpan? expiry = null) { redisKey = AddKeyPrefix(redisKey); return _db.StringSet(redisKey, redisValue, expiry); } /// <summary> /// 获取字符串 /// </summary> /// <param name="redisKey"></param> /// <param name="expiry"></param> /// <returns></returns> public string? StringGet(string redisKey, TimeSpan? expiry = null) { redisKey = AddKeyPrefix(redisKey); return _db.StringGet(redisKey, CommandFlags.PreferReplica); }// 我们只需要在相关的读操作后面添加 CommandFlags.PreferReplica 参数,自动优先从节点读取数据// 写操作无需此参数,因为主从模式下,只有主节点可读写,从节点都是仅可读的具体使用
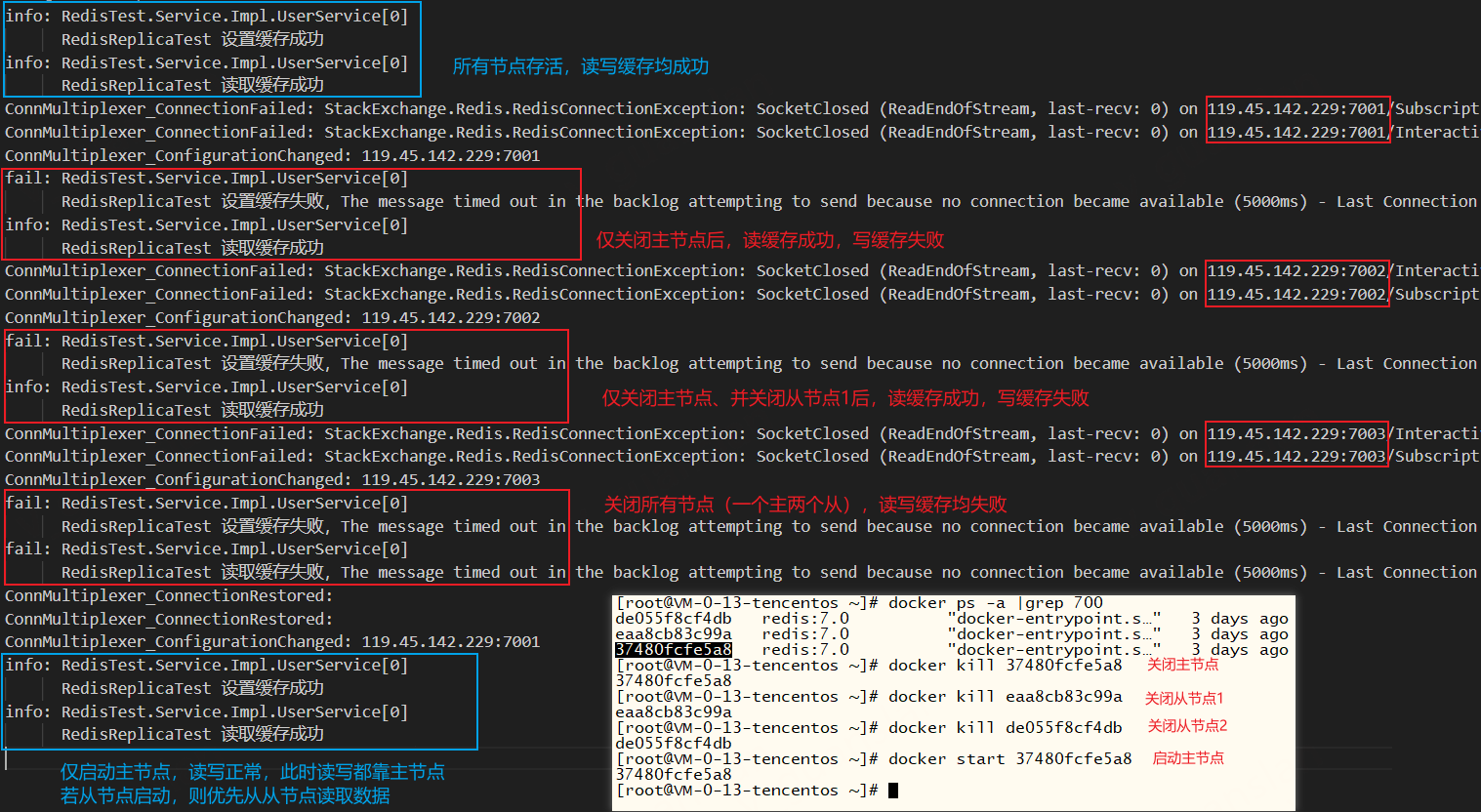
xxxxxxxxxx /// <summary> /// redis 简单演示 /// </summary> public void RedisReplicaTest() { var key = "redis_key"; try { _redis.StringSet(key, "Hello world"); _logger.LogInformation($"RedisReplicaTest 设置缓存成功"); } catch (Exception ex) { _logger.LogError($"RedisReplicaTest 设置缓存失败,{ex.Message}"); } try { var data = _redis.StringGet("redis_key"); _logger.LogInformation($"RedisReplicaTest 读取缓存成功"); } catch (Exception ex) { _logger.LogError($"RedisReplicaTest 读取缓存失败,{ex.Message}"); } }如下图,
所有节点存活时,读取缓存均成功——主写从读
仅关闭主节点后或者仅关闭主节点和从节点1后,读取缓存成功,写缓存失败——主写失败,从读成功
关闭所有节点(一主两从),读写缓存均失败
仅启动主节点时,读取缓存均成功——主写主读,又变成"单实例redis"了
故障演示
从节点脱离主节点后,主节点Id会发生改变。若从节点再次链接主节点,则会进行全量同步主节点的数据,保证数据统一
xxxxxxxxxx# 脱离主节点SLAVEOF NO ONE# 加入主节点成为master的从节点replicaof host ipslaveof host ip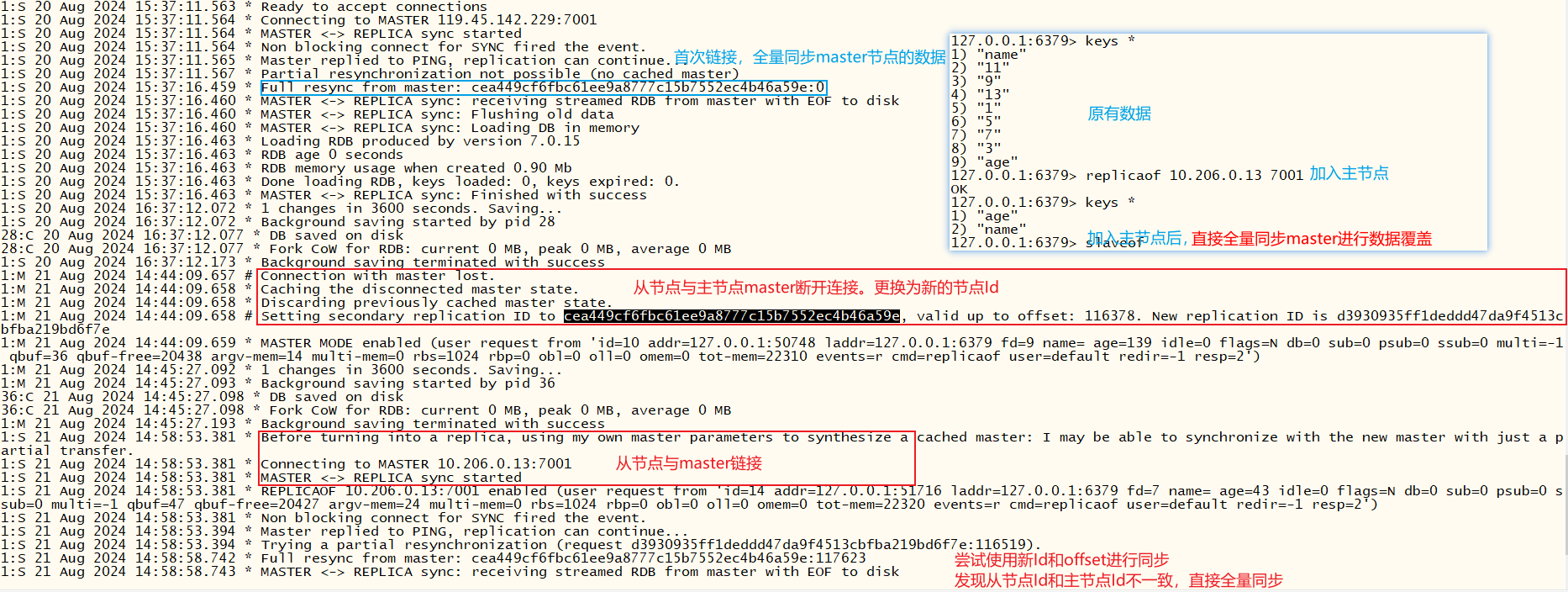
从节点异常断开连接,正常启动后,由于节点Id没有改变,所以会自动根据偏移量同步主节点的数据,保证数据统一
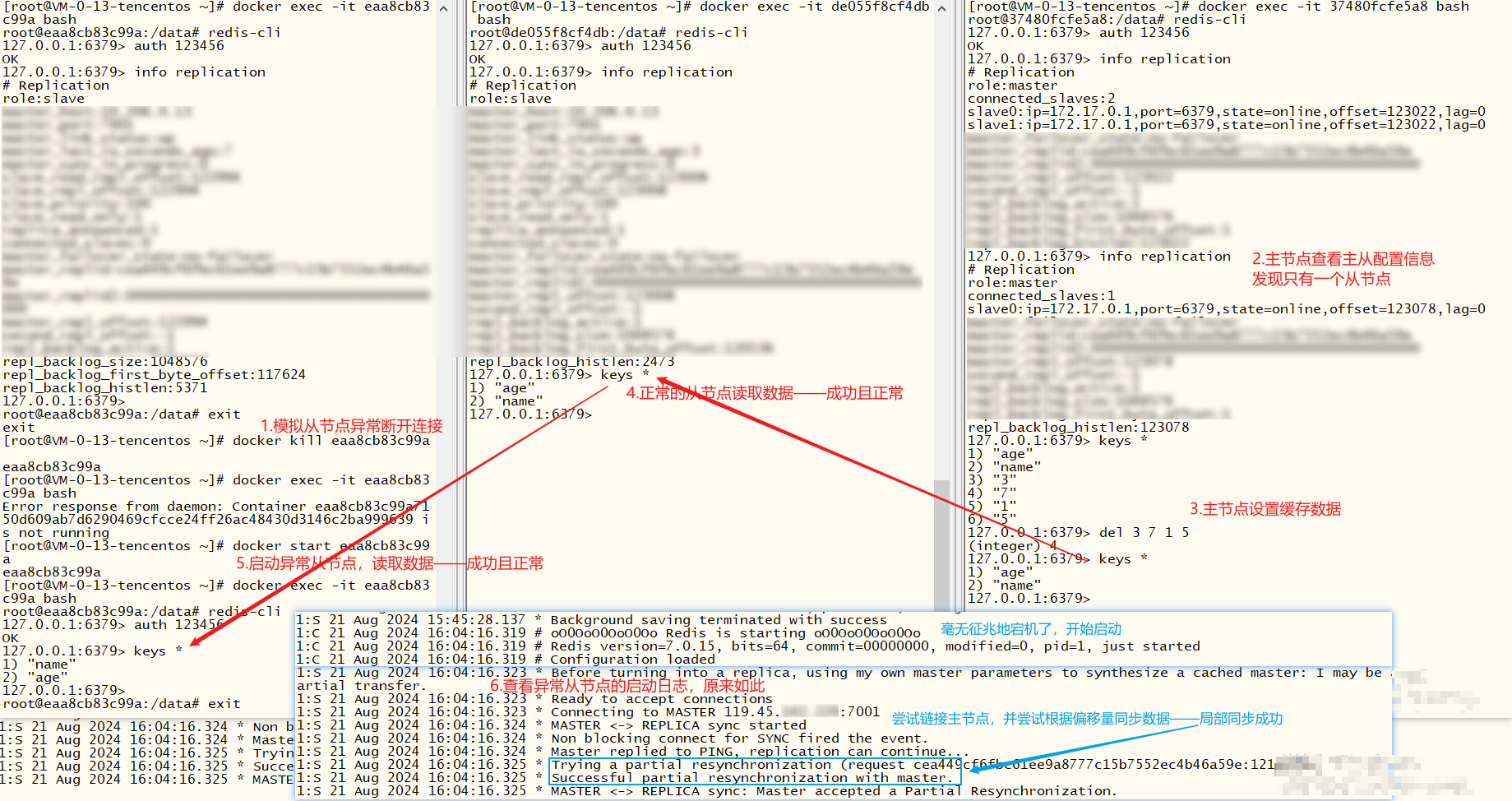
超过半数的节点(此处两个从节点)断开连接后,主节点仍可用(可读写)。若此时继续处理高并发,全部节点断开连接,那肯定就不可用了
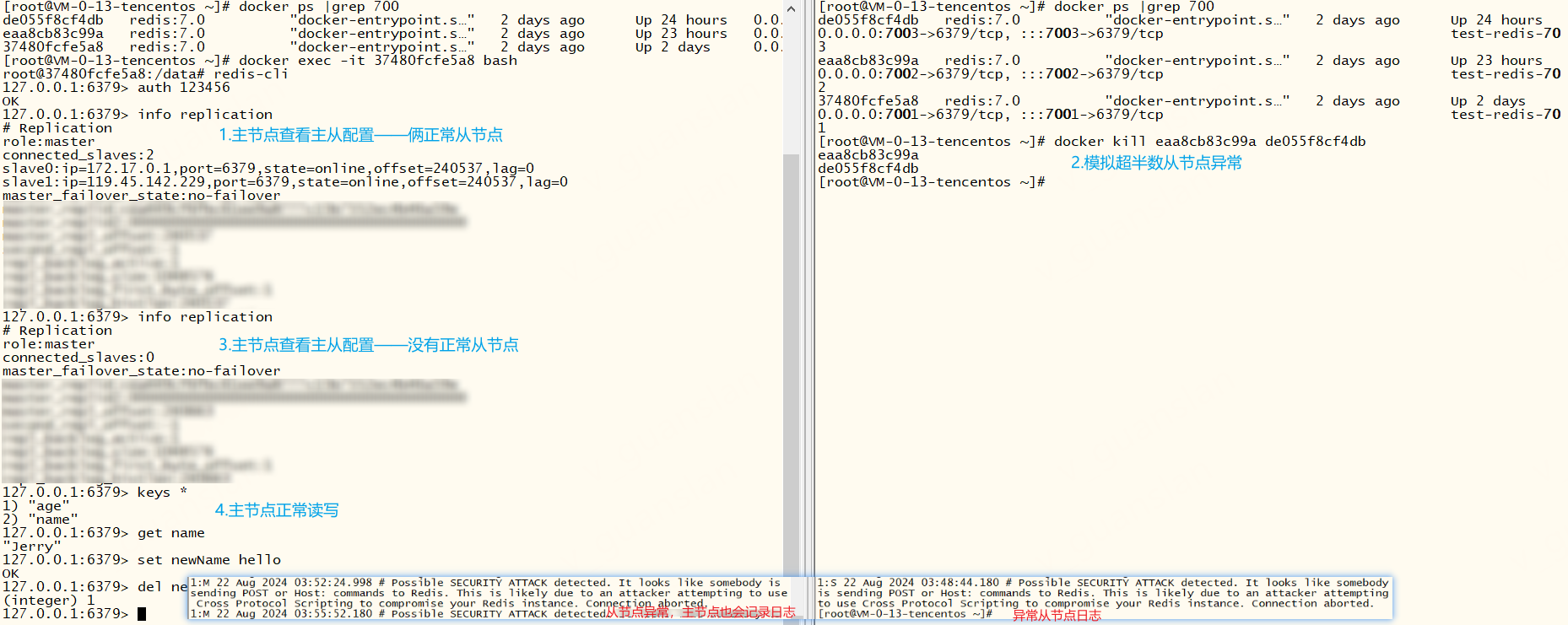
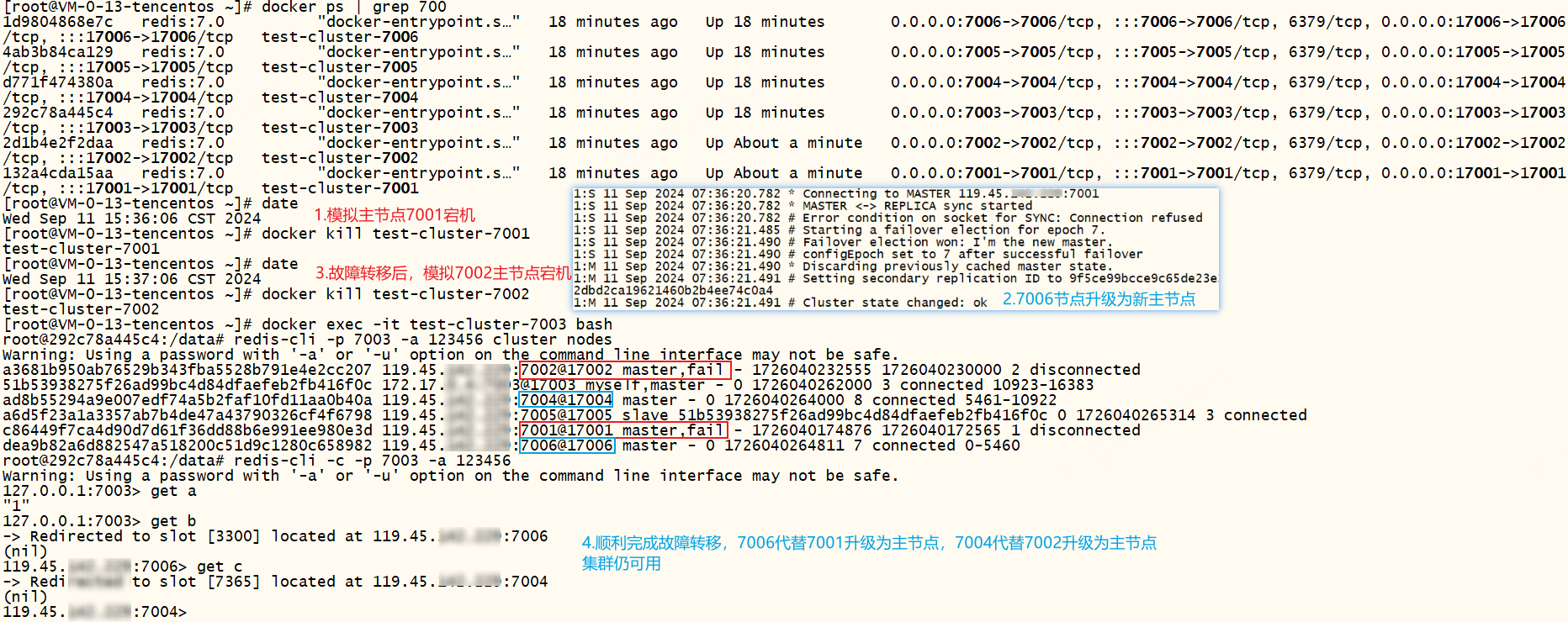
主节点宕机断开连接,从节点不影响读取数据,但是无法设置缓存(因为他不是主节点),那我们得想办法让其中一台正常的机器升级为主节点.
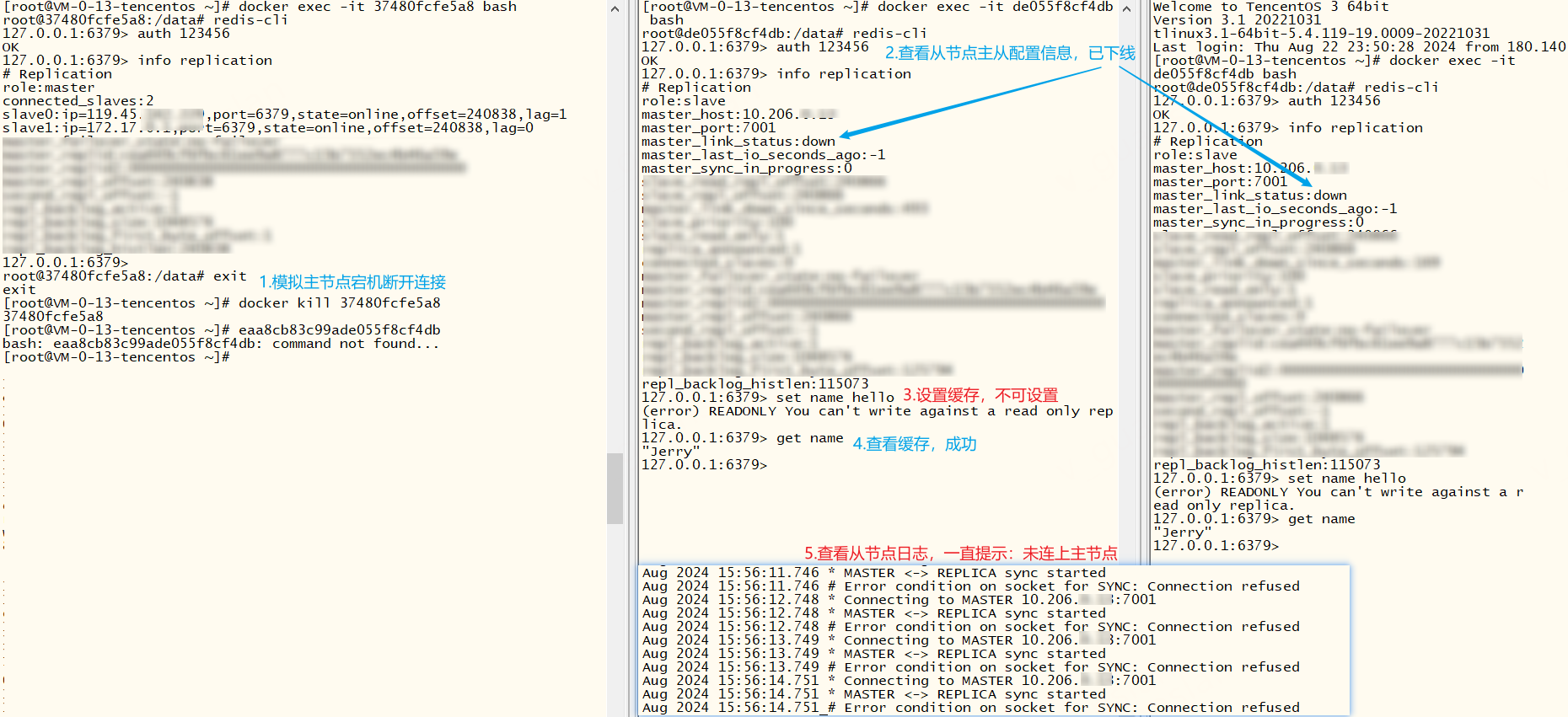
若原有集群含有大量数据,此时新增一个从节点,这个从节点大概多久能进行工作呢?从节点要完全复制主节点的数据才能开始工作
一键部署主从模式
测试环境下,单个机器部署多个redis节点,一键部署主从模式,方便测试。将以下命令写进replica-start.sh文件,并执行即可——replica-start.sh
xxxxxxxxxxchomd +x ./replica-start.shxxxxxxxxxx##### 7001mkdir -p /home/redis-test/test-redis-replica/7001/confchmod 777 /home/redis-test/test-redis-replica/7001/confcat << EOF > /home/redis-test/test-redis-replica/7001/conf/redis-re.conf# bind 127.0.0.1 -:1 0.0.0.0外网可访问bind 0.0.0.0# 指定端口port 6379# 指定节点密码requirepass 123456# 指定主节点的密码masterauth 123456# 永久指定主从关系,重启后仍可用# replicaof 0.0.0.0 7001# 开启rdbsave 3600 1 300 100 60 10000# 关闭AOF appendonly noEOFdocker run -d -p 7001:6379 --name test-redis-7001 --restart=always \ -v /home/redis-test/test-redis-replica/7001/data:/data \ -v /home/redis-test/test-redis-replica/7001/conf:/etc/redis/conf \ redis:7.0 redis-server /etc/redis/conf/redis-re.conf##### 7002 mkdir -p /home/redis-test/test-redis-replica/7002/confchmod 777 /home/redis-test/test-redis-replica/7002/confcat << EOF > /home/redis-test/test-redis-replica/7002/conf/redis-re.conf# bind 127.0.0.1 -:1 0.0.0.0外网可访问bind 0.0.0.0# 指定端口port 6379# 指定节点密码requirepass 123456# 指定主节点的密码masterauth 123456# 永久指定主从关系,重启后仍可用replicaof 119.45.100.200 7001# 开启rdbsave 3600 1 300 100 60 10000# 关闭AOF appendonly noEOFdocker run -d -p 7002:6379 --name test-redis-7002 --restart=always \ -v /home/redis-test/test-redis-replica/7002/data:/data \ -v /home/redis-test/test-redis-replica/7002/conf:/etc/redis/conf \ redis:7.0 redis-server /etc/redis/conf/redis-re.conf##### 7003mkdir -p /home/redis-test/test-redis-replica/7003/confchmod 777 /home/redis-test/test-redis-replica/7003/conf# vim补充上面的配置文件cat << EOF > /home/redis-test/test-redis-replica/7003/conf/redis-re.conf# bind 127.0.0.1 -:1 0.0.0.0外网可访问bind 0.0.0.0# 指定端口port 6379# 指定节点密码requirepass 123456# 指定主节点的密码masterauth 123456# 永久指定主从关系,重启后仍可用replicaof 119.45.100.200 7001# 开启rdbsave 3600 1 300 100 60 10000# 关闭AOF appendonly noEOF# 启动容器docker run -d -p 7003:6379 --name test-redis-7003 --restart=always \ -v /home/redis-test/test-redis-replica/7003/data:/data \ -v /home/redis-test/test-redis-replica/7003/conf:/etc/redis/conf \ redis:7.0 redis-server /etc/redis/conf/redis-re.conf哨兵机制—Sentinel
上面的主从模式虽然可以实现读写分离,但是仍有个隐患——主节点宕机之后,整个集群无法写数据。那有没有办法让主节点"自动复活"之类的操作呢?答案肯定也是有的。
我们可以安排一个小工头去监控整个集群工作情况,若主节点无法正常工作,则让另一个节点代替主节点工作,保证读写正常。当然了,一个小工头能力也有限,如果小工头也宕机罢工不干了,那就没人来监控了,所以我们也可以添加多个小工头一起来进行监控整个集群工作情况
哨兵机制图解
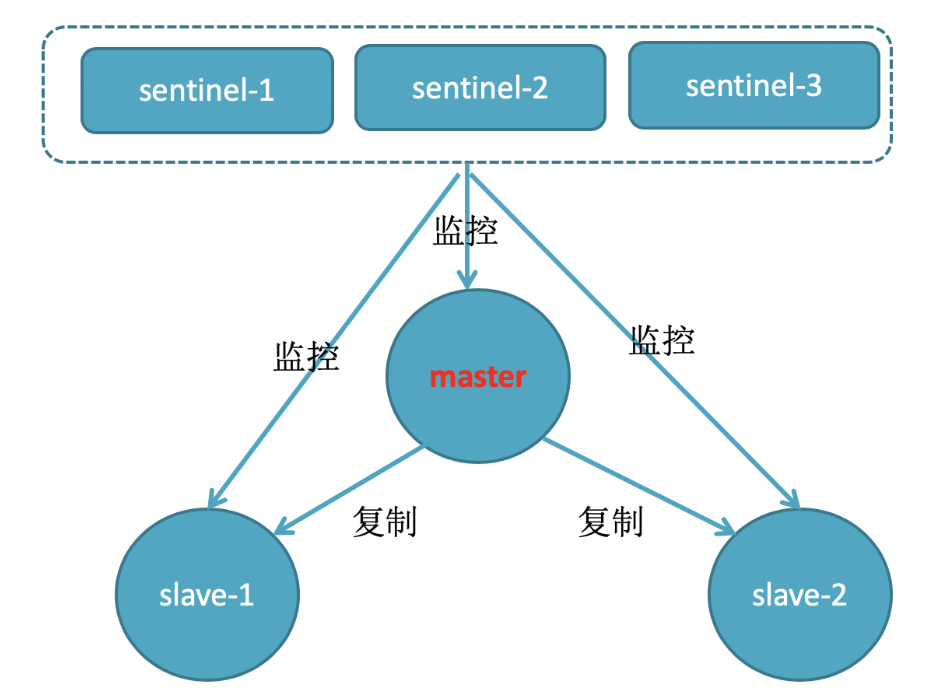
哨兵三大功能
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障转移,主要起到监控、自动故障转移、通知三个功能
监控:哨兵会不断检查主节点和从节点是否正常工作。
心跳机制,每秒发送ping命令,若节点不回复,则认为该实例主观下线(sdown)。若超过指定数量(quorum)的哨兵都认为该实例主观下线,则认为该实例客观下线(odown,已确认宕机)
自动故障转移:若主节点宕机,哨兵会自动选择一个从节点升级为主节点,前一个主节点恢复后会变成从节点
选择从节点的选举依据
- 首先判断从节点与主节点断开的时间长短,若超过指定值(down-after-milliseconds * 10),则直接排除该从节点
- 第二步判断节点的slave-priority值,越小优先级越高,0表示不参加选举
- 第三步判断从节点的offset,越大说明数据越新,优先级越高(最重要)
- 最后判断从节点的运行Id(启动时自动生成的),越小优先级越高
如何实现故障转移?
哨兵选中一个从节点,并发送slaveof NO ONE命令给该节点执行,让其成为主节点
哨兵会给剩下的从节点发送slaveof 从IP 从端口命令,让其成为新主节点的从节点,并开始同步master数据
最后,哨兵会将故障节点标记为从节点,加入slaveof 从IP 从端口命令到配置文件,等故障节点恢复后自动成为主节点的从节点
通知:集群发生故障时,Redis哨兵通过使用pub/sub机制向客户端发送切换通知,客户端通过订阅哨兵的消息来接收通知并重新连接到新的主节点,实现了高可用性和可靠性的Redis部署
配置文件sentinel.conf
我们只需要在原有的主从模式下添加哨兵集群即可,注意是使用redis-sentinel xx.conf启动哨兵而且哨兵集群无需主从复制,以下是通用配置文件
xxxxxxxxxxbind 0.0.0.0# 端口,默认26379port 26379# 最重要的。监控主节点获取主节点和从节点(info replication)的信息 2表示quorum,建议设置为哨兵节点个数的一半并向上取整sentinel monitor masterName 119.45.100.200 7001 2# 主从模式主节点的密码sentinel auth-pass masterName 123456# 故障转移,选举master时使用。从节点与主节点断开时间长短指定值sentinel down-after-milliseconds masterName 10000 # 指定 Sentinel 在主节点不可达后,尝试将从节点切换为主节点的时间限制(毫秒)#sentinel failover-timeout masterName 50000# 指定从节点为7002、7003。docker环境下最好手动指定从节点,避免哨兵找不到从节点(docker根据主节点找到的从节点端口都是6379)sentinel known-replica masterName 119.45.100.200 7002sentinel known-replica masterName 119.45.100.200 7003s1-7005
xxxxxxxxxx# 开放7005端口firewall-cmd --zone=public --add-port=7005/tcp --permanent && firewall-cmd --reloadmkdir -p test-redis-replica/s7005/conf# vim补充上面的配置文件vim /home/redis-test/test-redis-replica/s7005/conf/redis-sentinel.conf# 启动容器docker run -d -p 7005:26379 --name test-redis-s-7005 --restart=always \-v /home/redis-test/test-redis-replica/s7005/data:/data \-v /home/redis-test/test-redis-replica/s7005/conf:/etc/redis \redis:7.0 redis-sentinel /etc/redis/redis-sentinel.conf# -v /home/redis-test/test-redis-replica/s7005/conf:/etc/redis docker挂载配置文件所在的目录,不要映射指定redis-sentinel.conf文件,不然会发出警告:而且哨兵也无法正常工作# 警告:# Could not rename tmp config file (Device or resource busy)# WARNING: Sentinel was not able to save the new configuration on disk!!!: Device or resource busy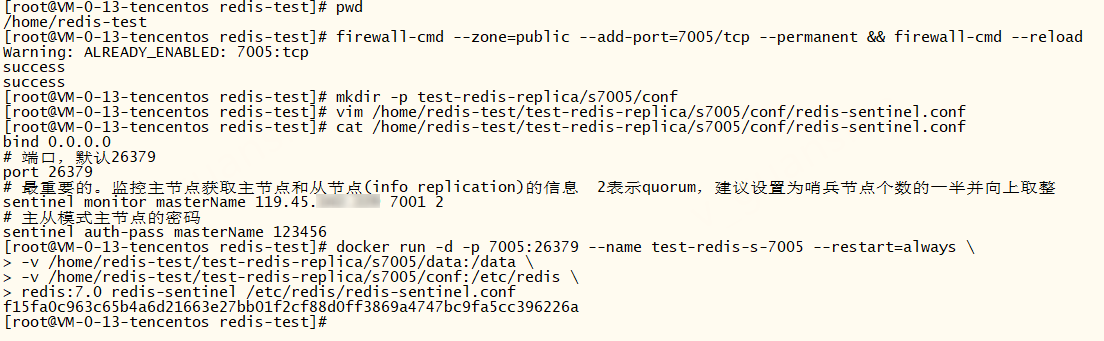
s2-7006
xxxxxxxxxx# 开放7006端口firewall-cmd --zone=public --add-port=7006/tcp --permanent && firewall-cmd --reloadmkdir -p test-redis-replica/s7006/conf# vim补充上面的配置文件vim /home/redis-test/test-redis-replica/s7006/conf/redis-sentinel.conf# 启动容器docker run -d -p 7006:26379 --name test-redis-s-7006 --restart=always \-v /home/redis-test/test-redis-replica/s7006/data:/data \-v /home/redis-test/test-redis-replica/s7006/conf:/etc/redis \redis:7.0 redis-sentinel /etc/redis/redis-sentinel.conf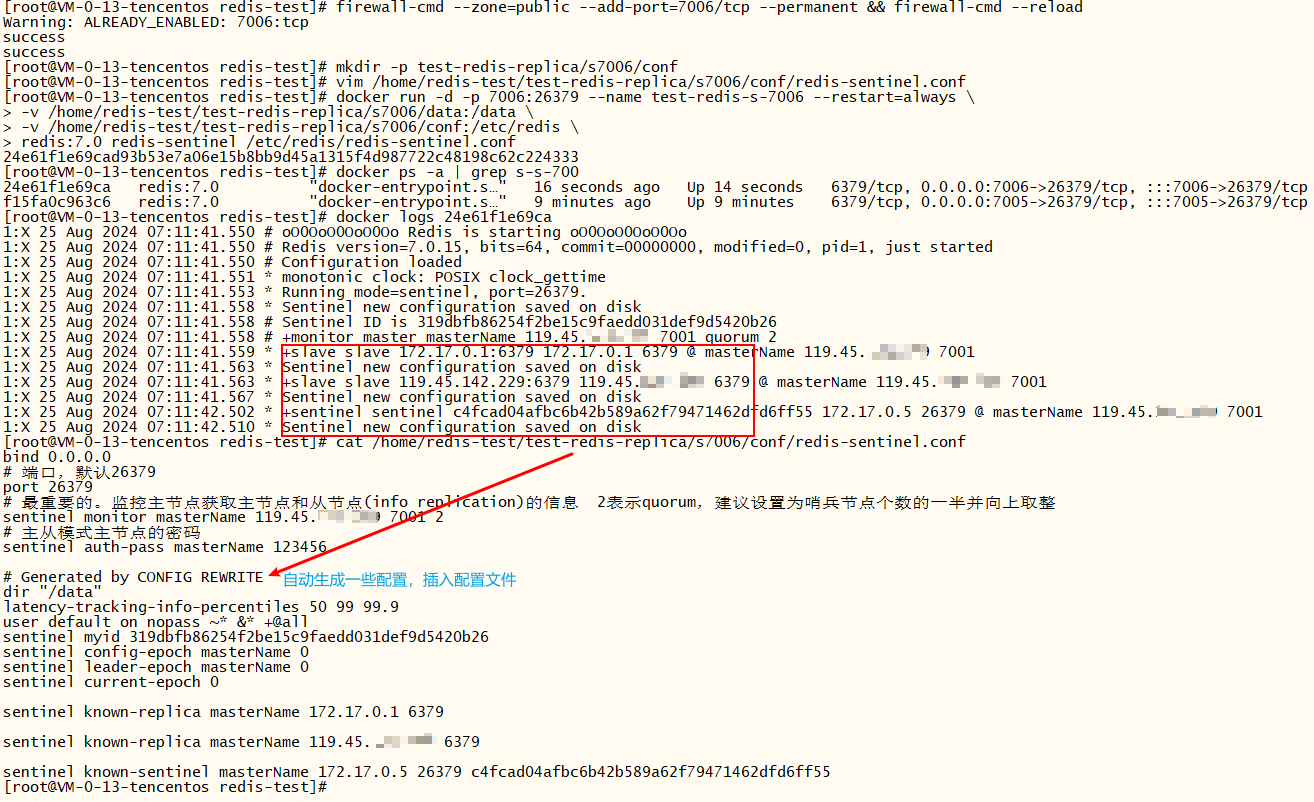
s3-7007
xxxxxxxxxx# 开放7007端口firewall-cmd --zone=public --add-port=7007/tcp --permanent && firewall-cmd --reloadmkdir -p test-redis-replica/s7007/conf# vim补充上面的配置文件vim /home/redis-test/test-redis-replica/s7007/conf/redis-sentinel.conf# 启动容器docker run -d -p 7007:26379 --name test-redis-s-7007 --restart=always \-v /home/redis-test/test-redis-replica/s7007/data:/data \-v /home/redis-test/test-redis-replica/s7007/conf:/etc/redis \redis:7.0 redis-sentinel /etc/redis/redis-sentinel.conf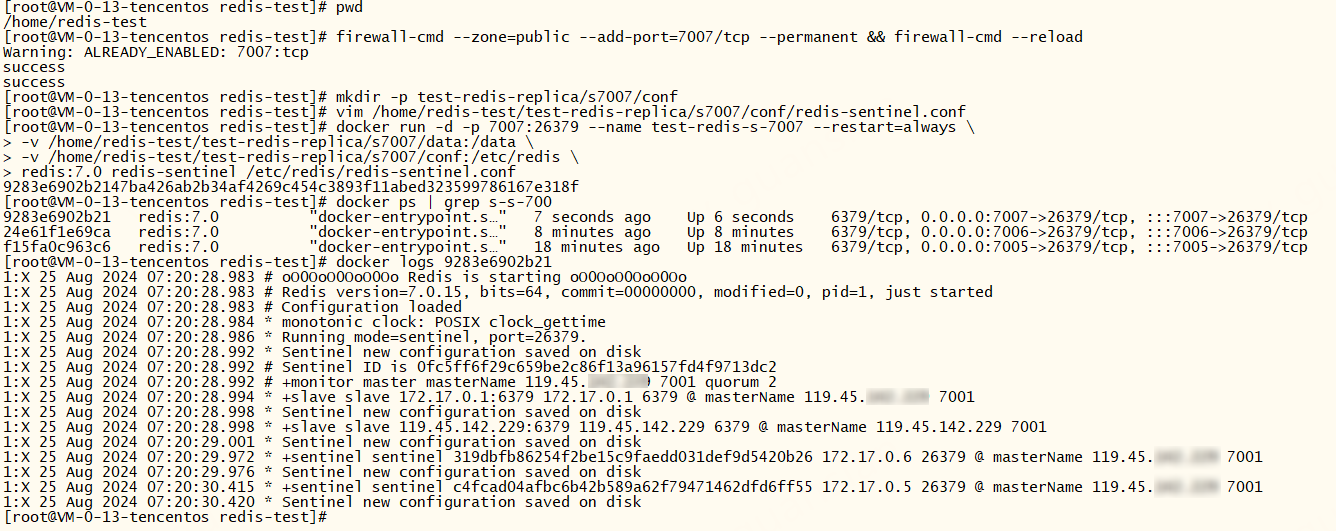
哨兵及故障演示
分别成功启动主从模式和哨兵机制,模拟主节点宕机,我们查看哨兵leader的日志可以看到故障转移全过程
+monitor ...哨兵启动,监控原主节点7001+slave slave ...哨兵自动连接上7001下的从节点。有个问题需要注意,docker环境下会自动连接6379端口作为从节点,忽略即可+sentinel sentinel ...识别两个哨兵,组成哨兵集群,用于一起监控主节点是否下线。+sdown ...主节点7001主观下线。+odown ...若超过quorum个哨兵都认为7001主观下线(sdown),则视为客观下线(odown)+try failover ...尝试对7001进行故障转移+vote-for-leader ...哨兵集群投票选举哨兵leader,来负责本次故障转移操作+elected-leader ...哨兵leader赢得选取+failover-state-select-slave ...哨兵leader开始寻找可升级的从节点+selected-slave ...leader选择7003作为新的主节点+failover-state-send-slaveof-noone slave ...哨兵leader向7003节点发送slaveof no one脱离主从,成为单实例(master)+failover-state-wait-promotion ...等待其他哨兵确认7003新主节点+promoted-slave ...其他哨兵更新哨兵配置文件,确认新主节点成功+failover-state-reconf-slaves ...故障转移状态切换到了reconf-slaves状态+slave-reconf-sent ...哨兵leader向其他从节点发送slaveof命令让其跟随新的主节点+failover-end-for-timeout ...故障转移因超时而终止,超时时间可调整failover-timeout配置 。虽然超时对结果不影响,但是超时期间,从节点无法拿到新主节点的新数据,待超时后从节点才会从新主节点上同步数据+failover-end ...故障转移结束+slave-reconf-sent-be ...哨兵leader发送slaveof命令成功+switch-master ...哨兵选择新的主节点,并监控新主节点+slave slave哨兵自动连接新主节点下的所有从节点,包括故障节点-failover-abort-no-good-slave ...若出现这个指令,说明当前没有从节点可升级为主节点,终止故障转移。这时我们需要看一下主节点是否正常,可以参考故障转移不成功的例子
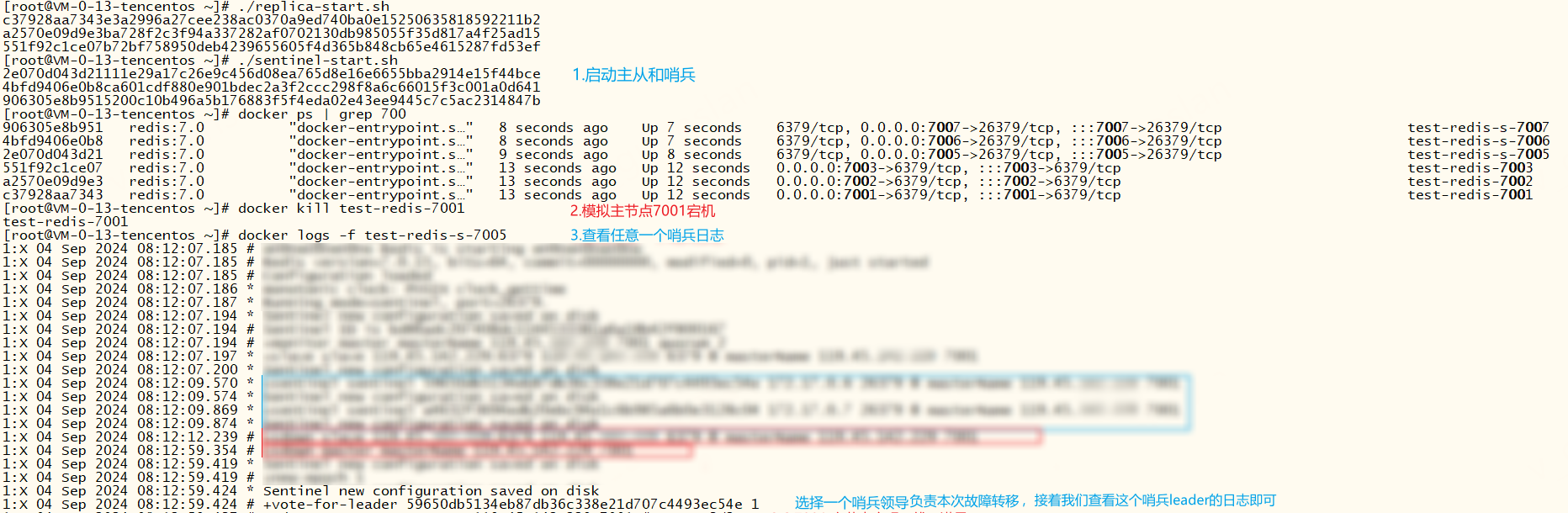
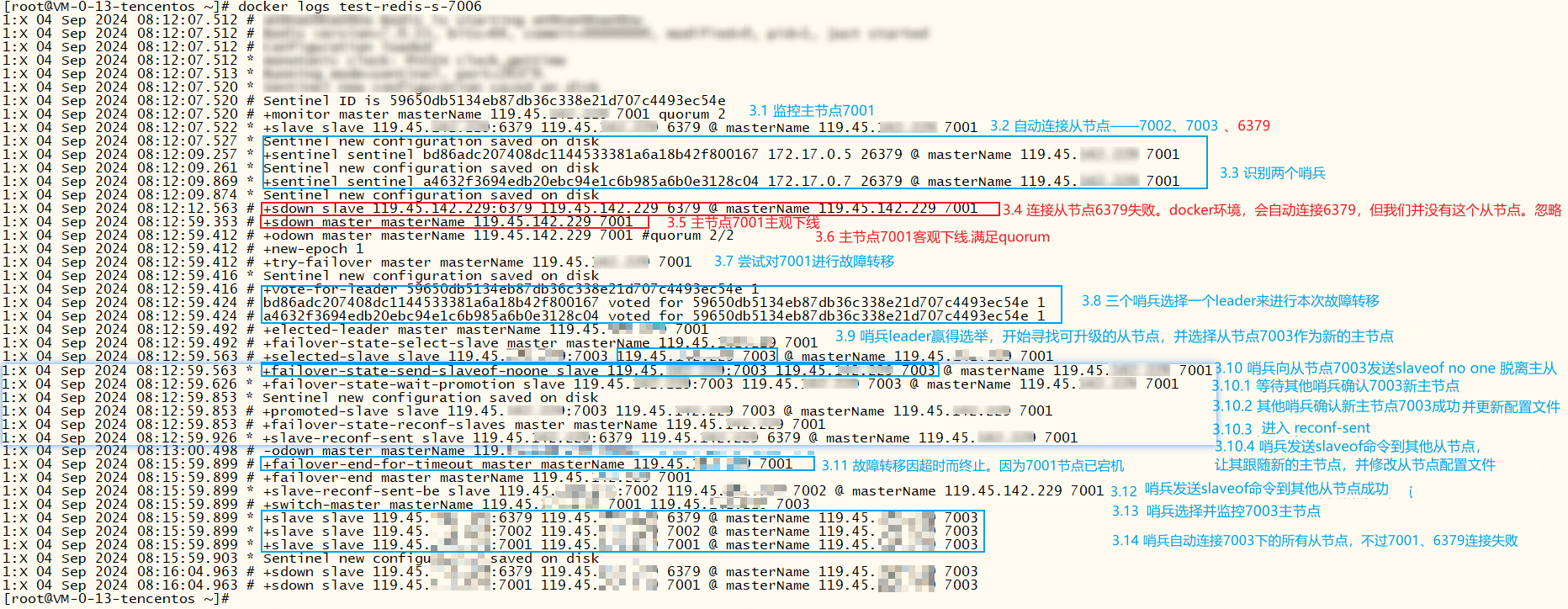
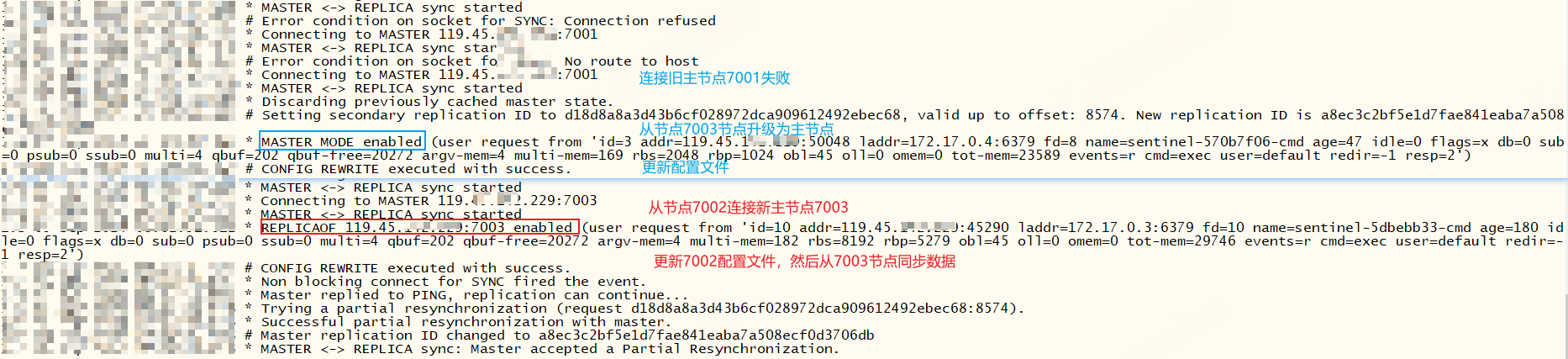
查看redis7002、7003节点日志,从节点7003已经成功升级为主节点,从节点7002也跟着成为7003的从节点,并开始同步主节点数据
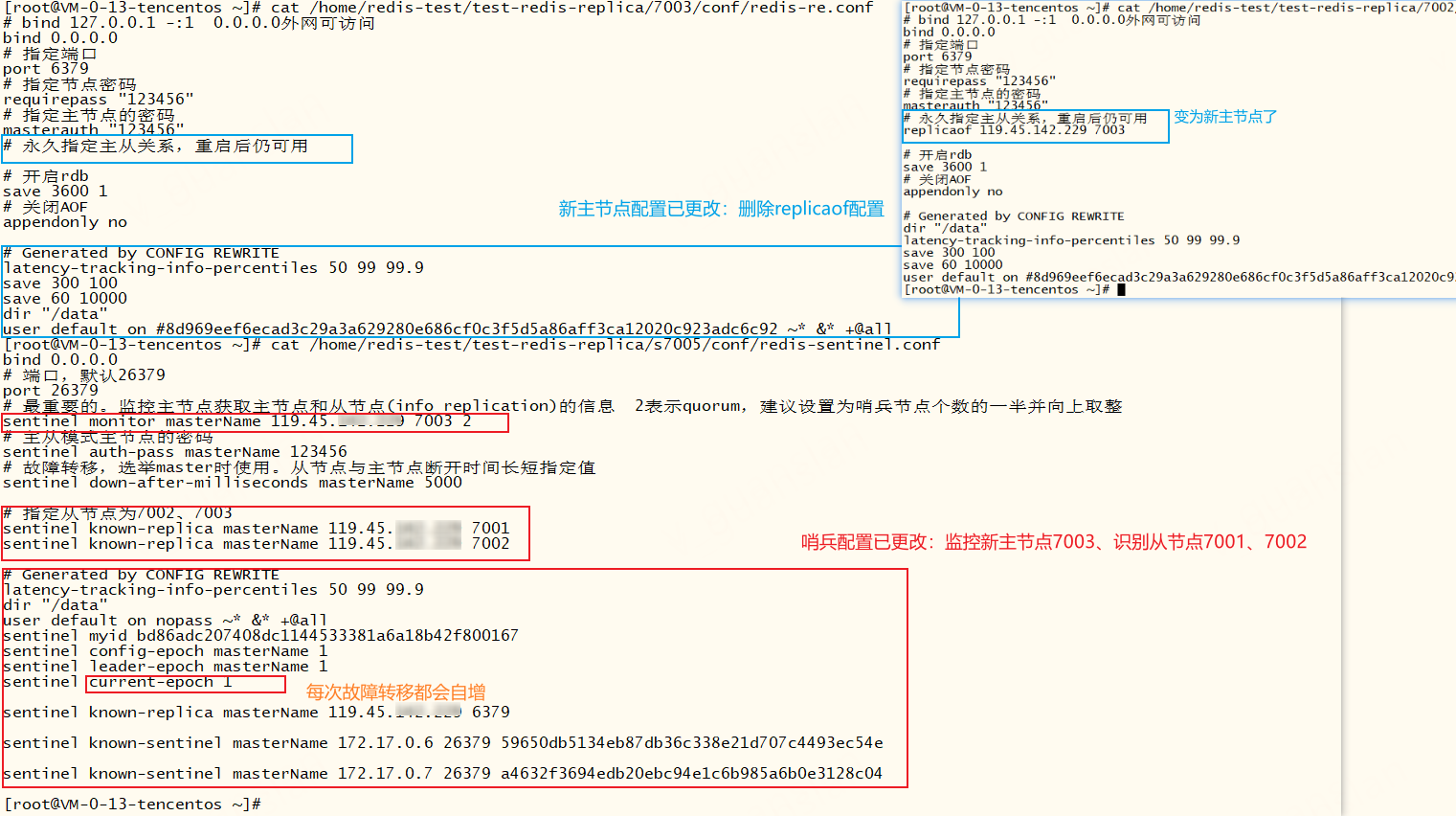
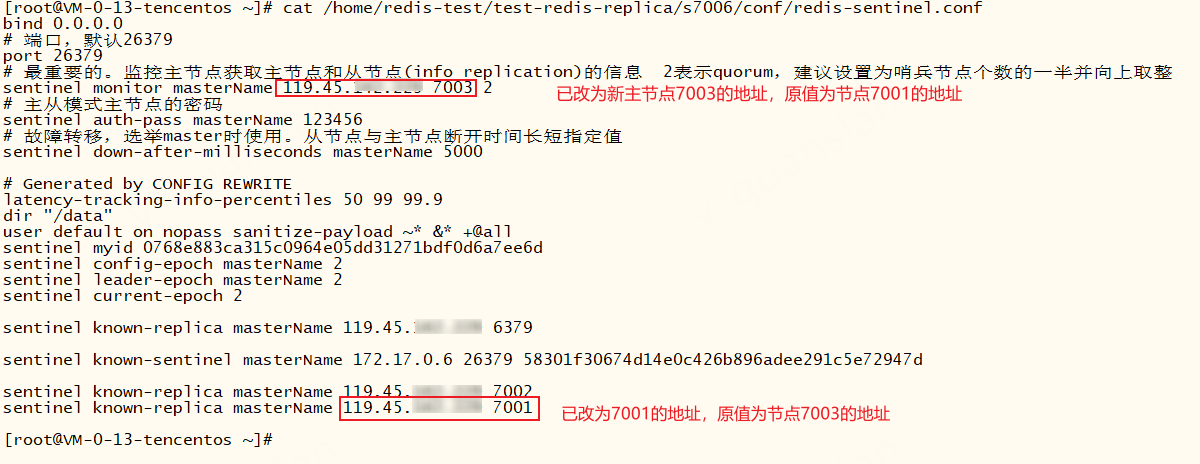
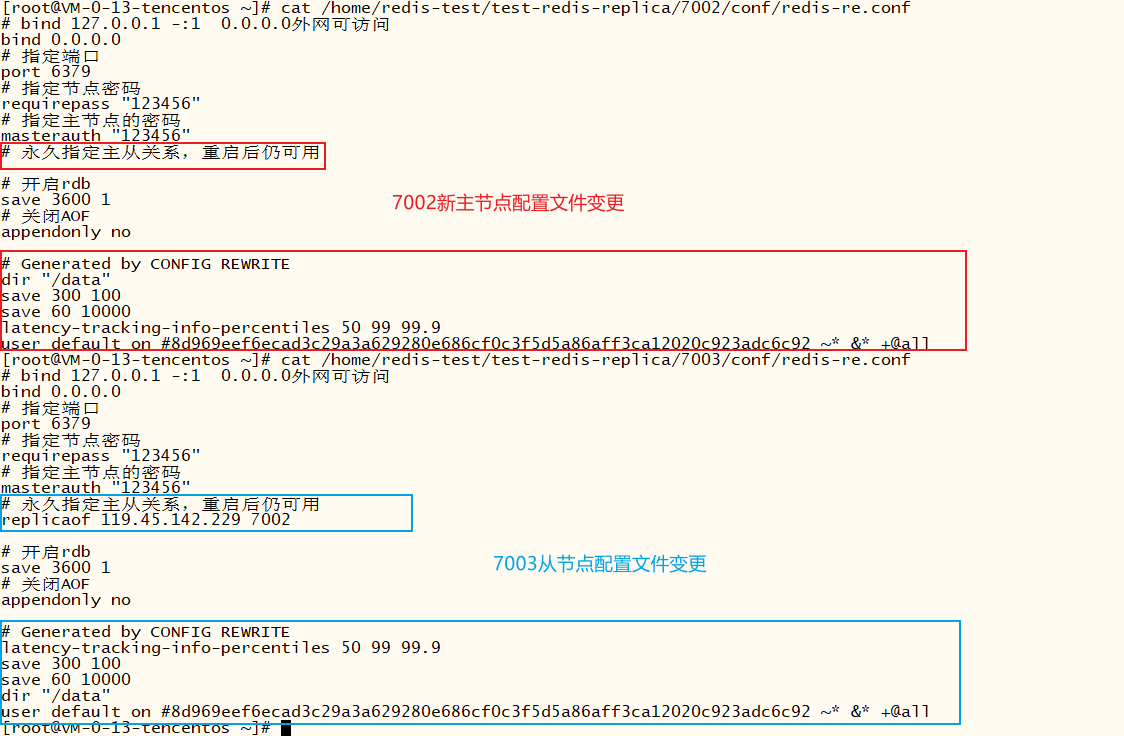
此时我们再去看redis主从节点和哨兵的配置文件,发现已经被修改
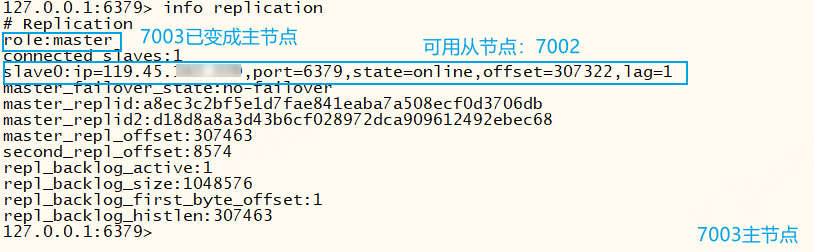
查看新主节点7003的info信息,7003已升级为主节点
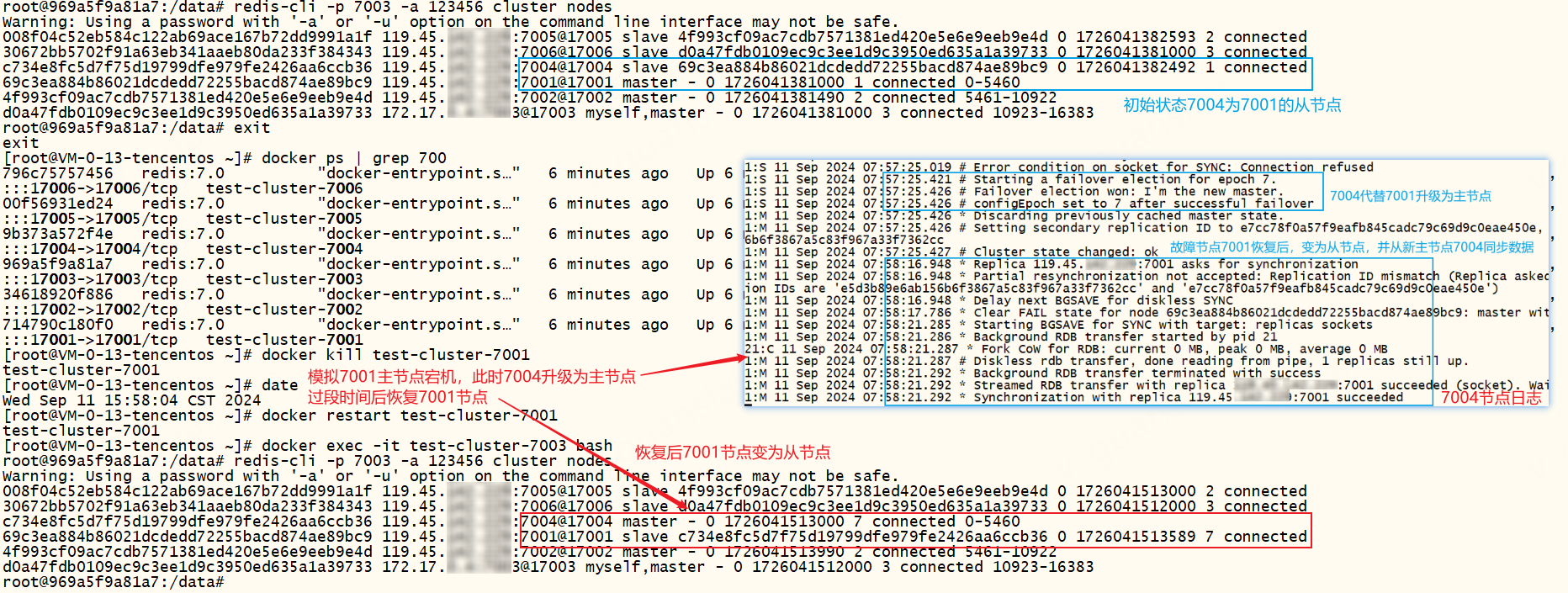
但是故障主节点7001的配置文件未被更改,如果故障节点7001修复后重启,还是主节点吗?
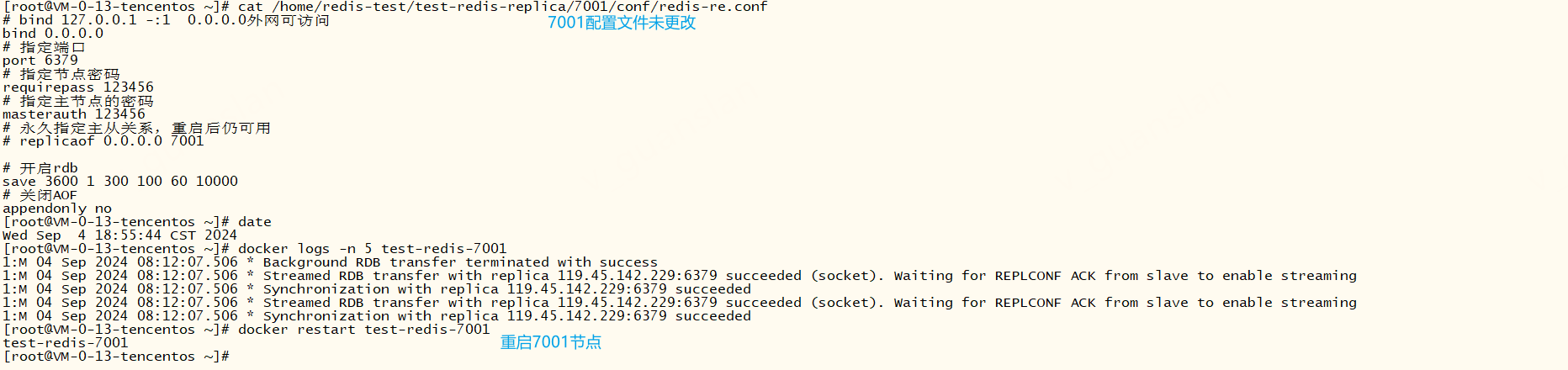
重启后我们查看哨兵日志和7001节点日志,发现7001直接变成7003的从节点,而且7001的配置文件也被更改了
虽然故障转移成功后7001的配置文件未被更改,但是故障转移期间哨兵已经将故障节点标记为从节点,所以故障节点修复后重启会变成从节点并从新的主节点同步数据
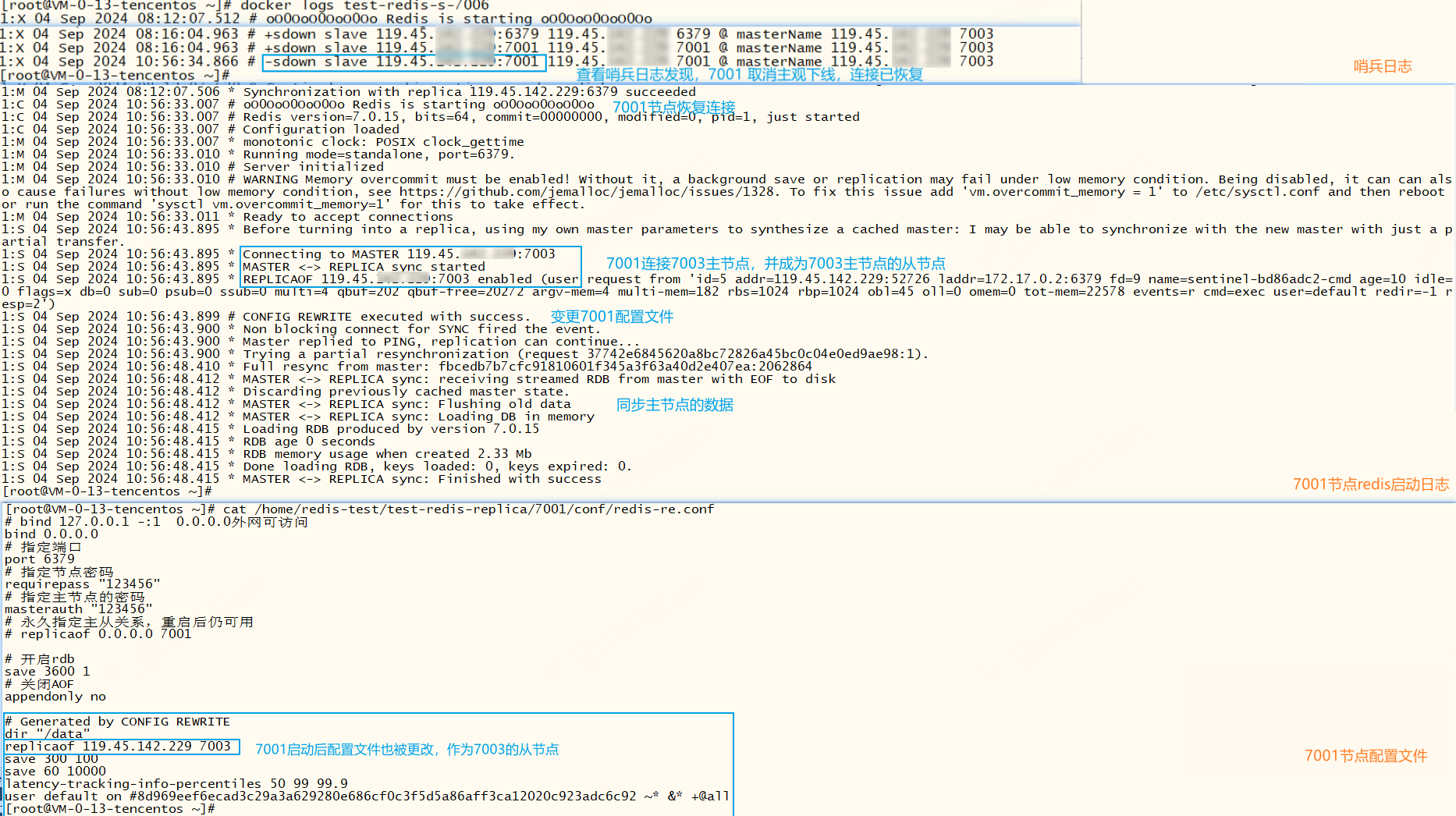
一主两从三哨兵的模式下,主节点宕机后,新主节点也宕机,此时仍旧支持故障转移并访问,若所有的redis节点都宕机,哨兵无法找到可用的节点故障转移失败,过段时间(failover-timeout)继续尝试故障转移,直到成功为止
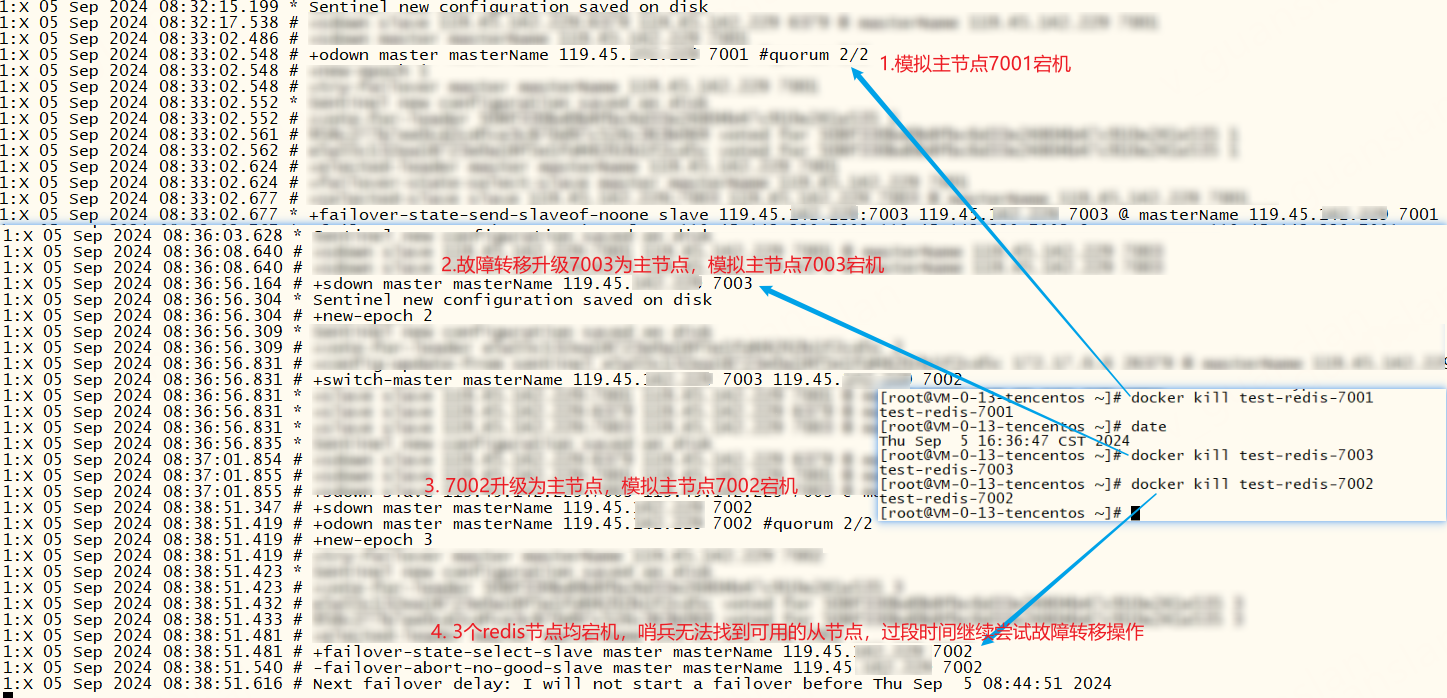
一主两从三哨兵的模式下,从节点宕机主节点正常的情况下 ,哨兵不会进行故障转移
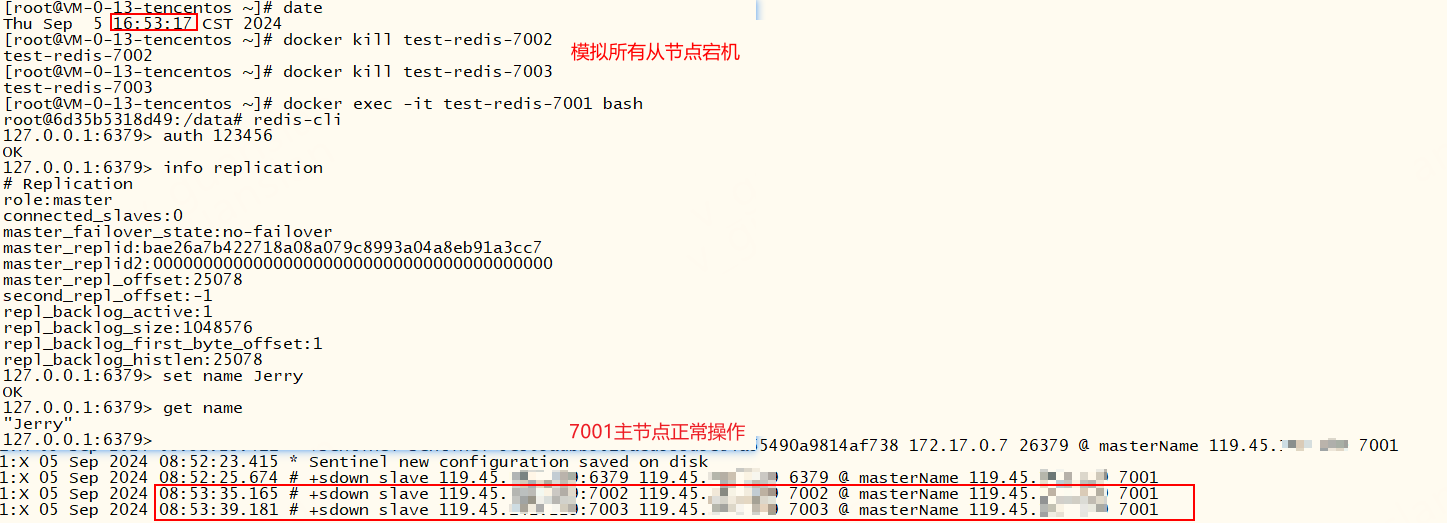
我们也可以手动触发故障转移,手动触发一般不会出现超时情况,因为此时7001仍可用
xxxxxxxxxxSENTINEL FAILOVER <master-name>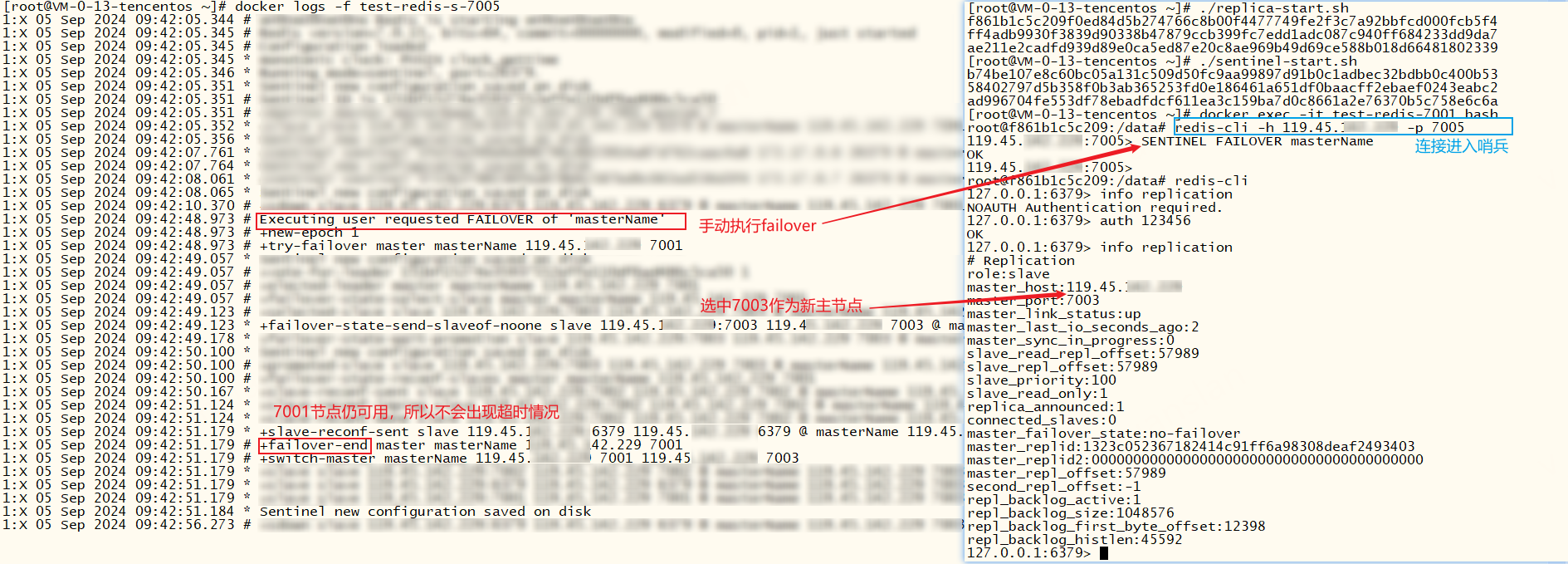
更多哨兵常用命令
xxxxxxxxxxSENTINEL help# 查看当前主节点masterName信息SENTINEL MASTER masterName# 查看主节点masterName下的所有从节点 SENTINEL SLAVES masterNameSENTINEL REPLICAS masterName# 查看主节点是否满足quorum。达到客观下线SENTINEL CKQUORUM masterName# 查看当前哨兵监控的所有主节点,说明哨兵是可以同时监控多个集群的SENTINEL MASTERS# 查看当前哨兵IdSENTINEL MYID# 查看其他哨兵SENTINEL SENTINELS masterName# 监控主节点 MONITOR 主节点名称 ip port quorumSENTINEL MONITOR masterName 119.45.x.x 7003 2# 取消监控主节点SENTINEL REMOVE masterName# 修改监控主节点配置 SENTINEL SET masterName key valueSENTINEL SET masterName quorum 1# sentinel 配置相关SENTINEL CONFIG SET <param> <value>SENTINEL CONFIG GET <param># 手动触发故障转移SENTINEL FAILOVER masterNamec#代码演示
以下演示一下c#代码如何连接并使用主从模式+哨兵机制,源码参考:使用哨兵 · logerlink/RedisTest@6d1589f (github.com)
redis主从模式+哨兵机制连接字符串,只需加上serviceName即可,注意需要redis主从的密码,而且连接的是哨兵集群地址。
xxxxxxxxxx"ConnectionStrings": { "Redis": "119.45.100.100:7005,119.45.100.100:7006,119.45.100.100:7007,password=123456,serviceName=masterName" },redis 帮助类改造——CommandFlags.PreferReplica优先从节点读取数据
xxxxxxxxxx /// <summary> /// 设置 key 并保存字符串(如果 key 已存在,则覆盖值) /// </summary> /// <param name="redisKey"></param> /// <param name="redisValue"></param> /// <param name="expiry"></param> /// <returns></returns> public bool StringSet(string redisKey, string redisValue, TimeSpan? expiry = null) { redisKey = AddKeyPrefix(redisKey); return _db.StringSet(redisKey, redisValue, expiry); } /// <summary> /// 获取字符串 /// </summary> /// <param name="redisKey"></param> /// <param name="expiry"></param> /// <returns></returns> public string? StringGet(string redisKey, TimeSpan? expiry = null) { redisKey = AddKeyPrefix(redisKey); return _db.StringGet(redisKey, CommandFlags.PreferReplica); }// 我们只需要在相关的读操作后面添加 CommandFlags.PreferReplica 参数,自动优先从节点读取数据// 写操作无需此参数,因为主从模式下,只有主节点可读写,从节点都是仅可读的具体使用
xxxxxxxxxx /// <summary> /// redis 主从模式+哨兵简单演示 /// </summary> public void RedisReplicaSentinelTest() { var key = "redis_sentinel_key"; try { var success = _redis.StringSet(key, "Hello world"); if(success) _logger.LogInformation($"RedisReplicaSentinelTest 设置缓存成功"); else _logger.LogError($"RedisReplicaSentinelTest 设置缓存失败"); } catch (Exception ex) { _logger.LogError($"RedisReplicaSentinelTest 设置缓存失败,{ex.Message}"); } try { var data = _redis.StringGet(key); _logger.LogInformation($"RedisReplicaSentinelTest 读取缓存成功"); } catch (Exception ex) { _logger.LogError($"RedisReplicaSentinelTest 读取缓存失败,{ex.Message}"); } }程序执行如下图:
- 主从模式和哨兵均正常,读写缓存成功
- 模拟主节点宕机的同时,立即执行程序,设置缓存失败,读取正常。原因:故障转移需要时间未完成,主节点无法工作,导致设置缓存失败
- 模拟主节点宕机,故障转移成功,7002升级为新的主节点,读写缓存成功。主从切换成功,会修改配置文件,此时会触发
IConnectionMultiplexer.ConfigurationChanged事件 - 分别模拟三个哨兵宕机,对程序不影响,读写缓存成功。注意,若启动程序前,哨兵全部宕机,此时是无法连接redis节点的
- 模拟新主节点7002宕机,由于哨兵不可用,无法自动实现故障转移,主节点不可用,设置缓存失败,但从节点仍可读取
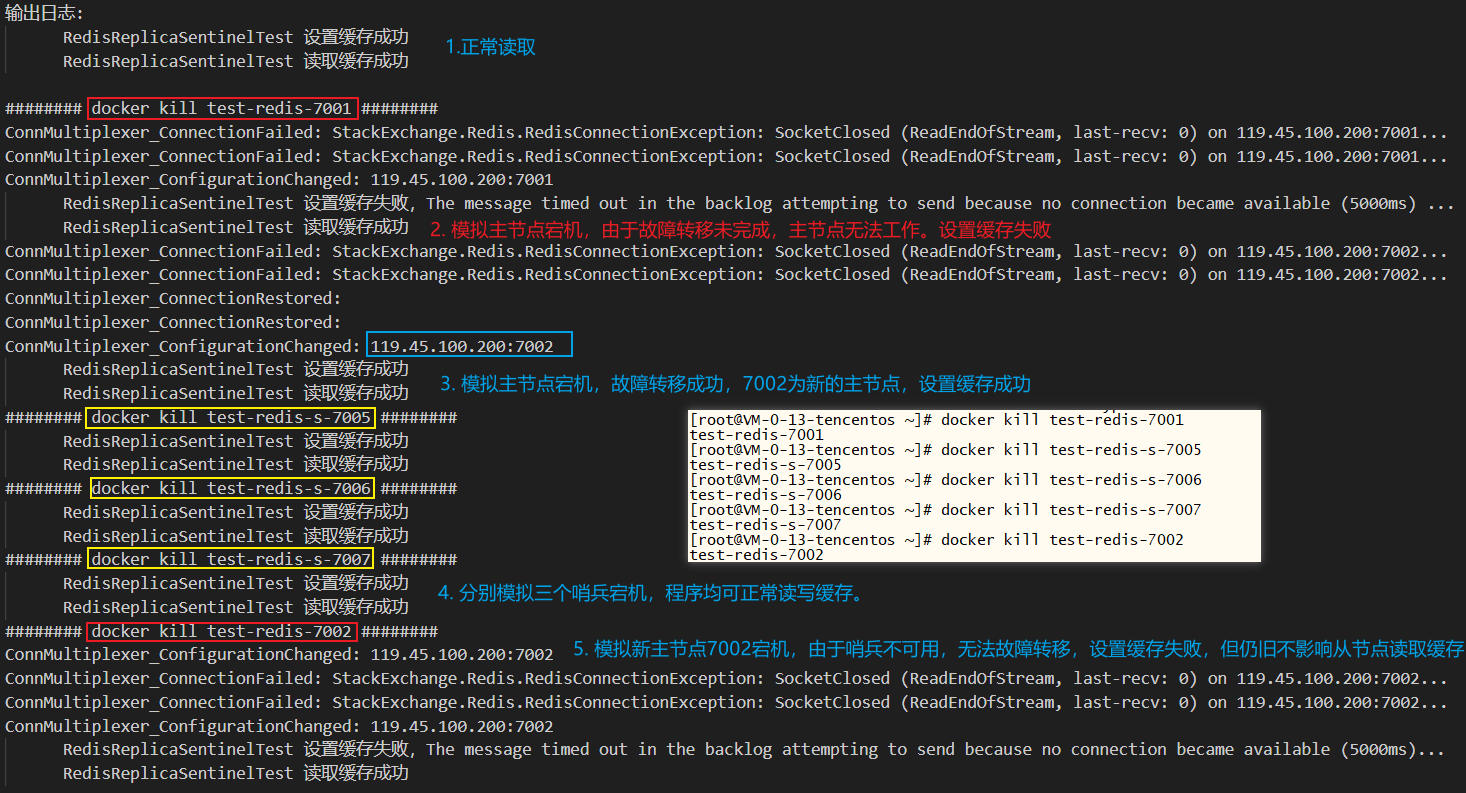
常见问题
故障转移不一定会成功,如果主节点发生故障,哨兵没有找到合适的从节点可升级为主节点,此时会终止故障转移,并等待一段时间后(failover-timeout 默认6分钟)继续重试升级从节点为主节点的操作
xxxxxxxxxx# +failover-state-select-slave master masterName 119.45.100.200 7001 # 查找从节点# -failover-abort-no-good-slave master masterName 119.45.100.200 7001 # 终止故障转移,未找到合适的从节点# Next failover delay: I will not start a failover before Tue Aug 27 07:18:33 # 我等会还会重试故障转移操作的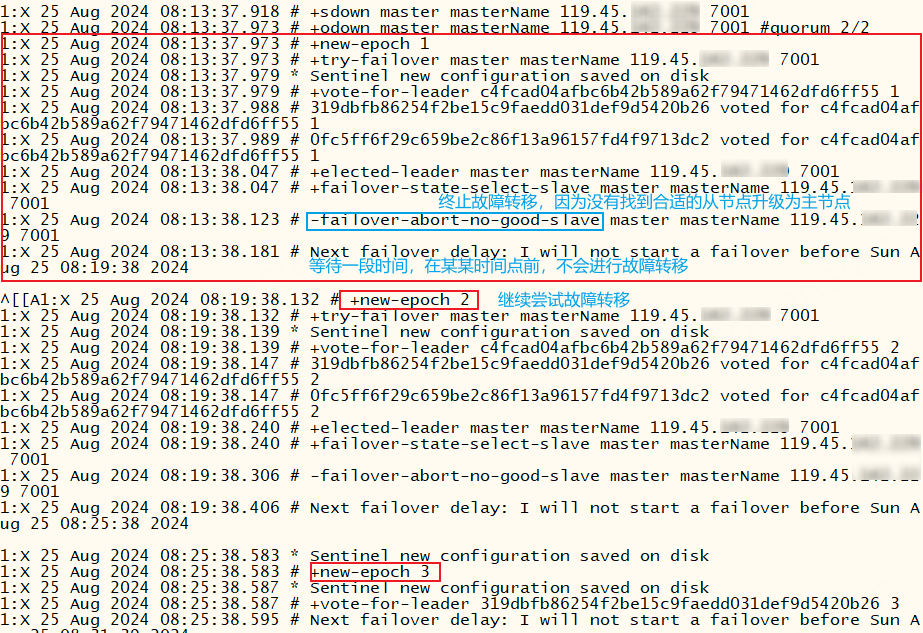
故障转移不成功,原因排查——主从模式是否设置密码?若有密码则加上sentinel auth-pass <password>并保证密码正确
故障转移不成功,原因排查——docker环境下,哨兵未找到主从模式的从节点,如下我们推演一下执行过程
- 使用docker,正常启动主从模式后添加两个哨兵
- 模拟主节点7001宕机,此时哨兵应该自动选取新的主节点,但是没有成功,哨兵选取新的主节点失败
- 我们查看哨兵日志,发现主节点7001主观下线且客观下线(满足quorum)
- 接着哨兵尝试投票选取主节点,但是又选中了主节点7001故障节点
- 紧接着哨兵终止故障转移,原因是没有找到可用的节点。那为什么没有找到可用节点呢?明明还有两个正常的从节点
- 继续往上查看更久远的日志,发现哨兵启动后,监控主节点(+monitor master...),并连接两个从节点(+slave slave ...)但是连接从节点失败(+sdown slave ...)。
- 定位到原因:原来连接从节点失败且主节点故障,导致哨兵自动故障转移操作被终止,无法完成主从切换。
xxxxxxxxxx# +monitor master masterName 119.45.100.200 7001 quorum 2* +slave slave 119.45.100.200:6379 119.45.100.200 6379 @ masterName 119.45.100.200 7001* Sentinel new configuration saved on disk* +slave slave 172.17.0.1:6379 172.17.0.1 6379 @ masterName 119.45.100.200 7001* Sentinel new configuration saved on disk* +sentinel sentinel 39ab47f6ced85979a624c0b7c7c731c61725e3a1 172.17.0.5 26379 @ masterName 119.45.100.200 7001* Sentinel new configuration saved on disk# +sdown slave 119.45.100.200:6379 119.45.100.200 6379 @ masterName 119.45.100.200 7001# +sdown slave 172.17.0.1:6379 172.17.0.1 6379 @ masterName 119.45.100.200 7001# +sdown master masterName 119.45.100.200 7001# +odown master masterName 119.45.100.200 7001 #quorum 2/2# +new-epoch 1# +try-failover master masterName 119.45.100.200 7001* Sentinel new configuration saved on disk# +vote-for-leader a70da4c0d5d93bc79f47e0c2a5d99b8d759b2b8b 1# 39ab47f6ced85979a624c0b7c7c731c61725e3a1 voted for a70da4c0d5d93bc79f47e0c2a5d99b8d759b2b8b 1# +elected-leader master masterName 119.45.100.200 7001# +failover-state-select-slave master masterName 119.45.100.200 7001# -failover-abort-no-good-slave master masterName 119.45.100.200 7001# Next failover delay: I will not start a failover before Tue Aug 27 10:31:07 2024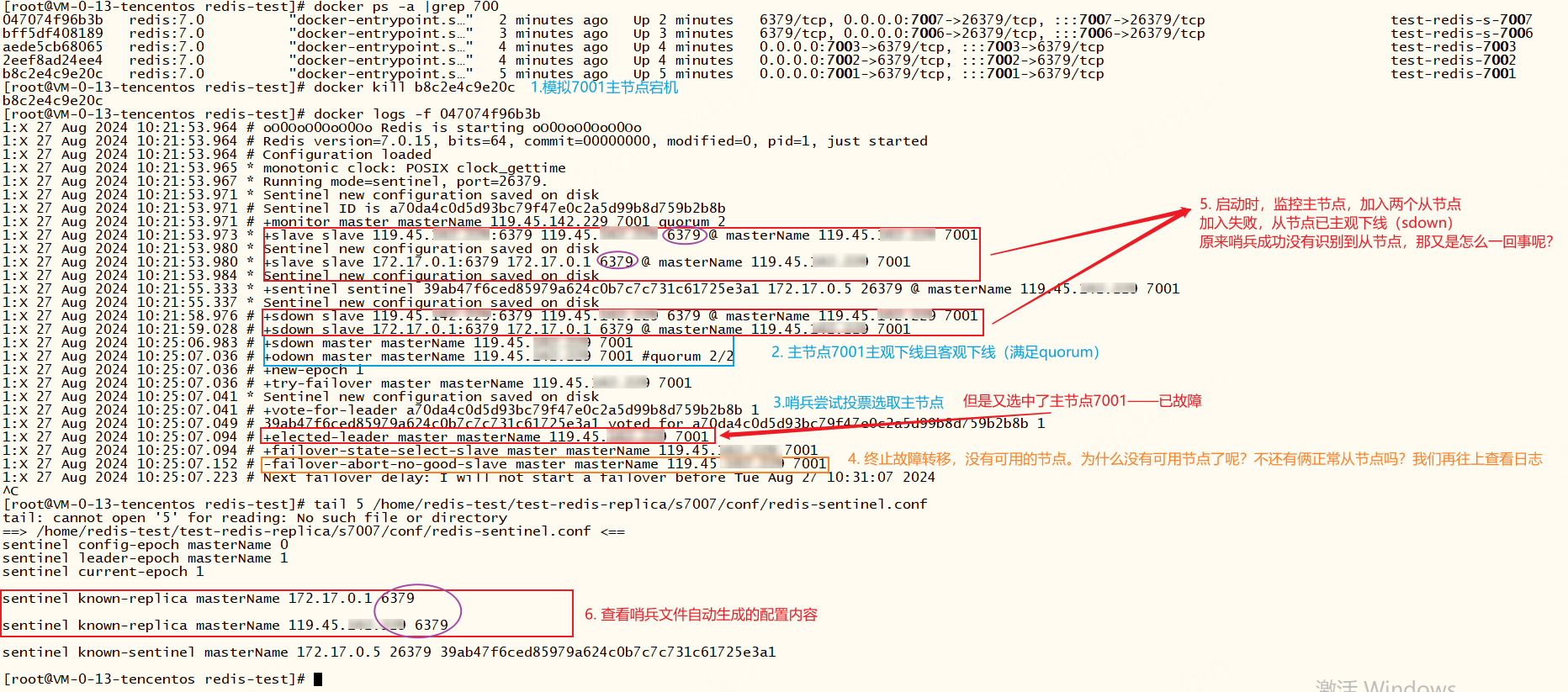
那为什么哨兵连接从节点失败呢?我们先看一下监控主节点后的日志——哎,这两个从节点,为什么端口都是6379呢?我们设定的端口不是7001主节点,7002、7003为从节点吗?

我们再看一下哨兵s7007的配置文件,查看哨兵自动生成的配置,我们发现自动生成连接从节点命令sentinel known-replica masterName 从ip 从端口,但是端口不正确,所以导致哨兵连接从节点失败
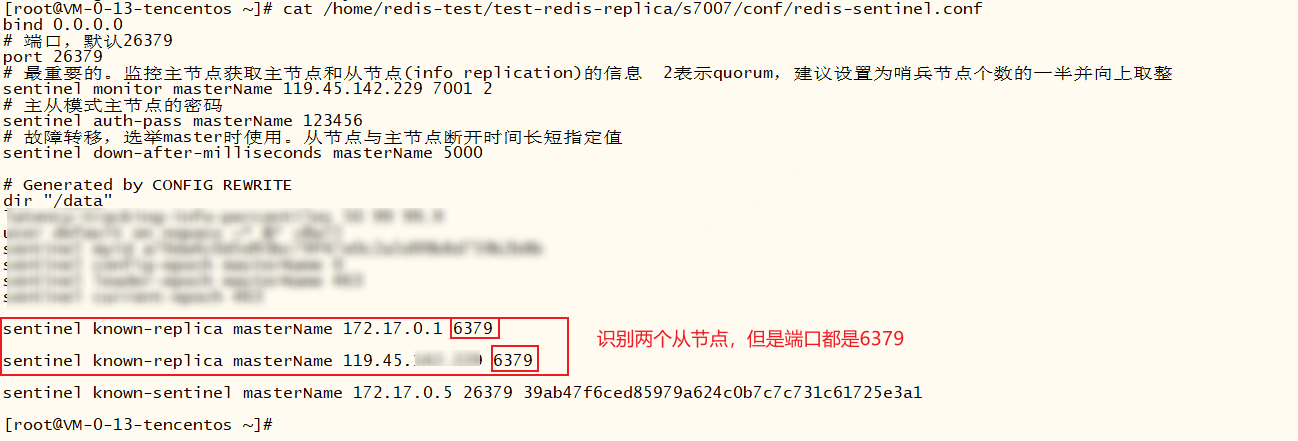
出现这个问题的原因:哨兵监控主节点,并通过info命令获取到从节点信息(ip:port),从而自动识别从节点。但是在docker环境下执行info命令拿到的端口是docker内部的端口而不是外部映射的端口,如图
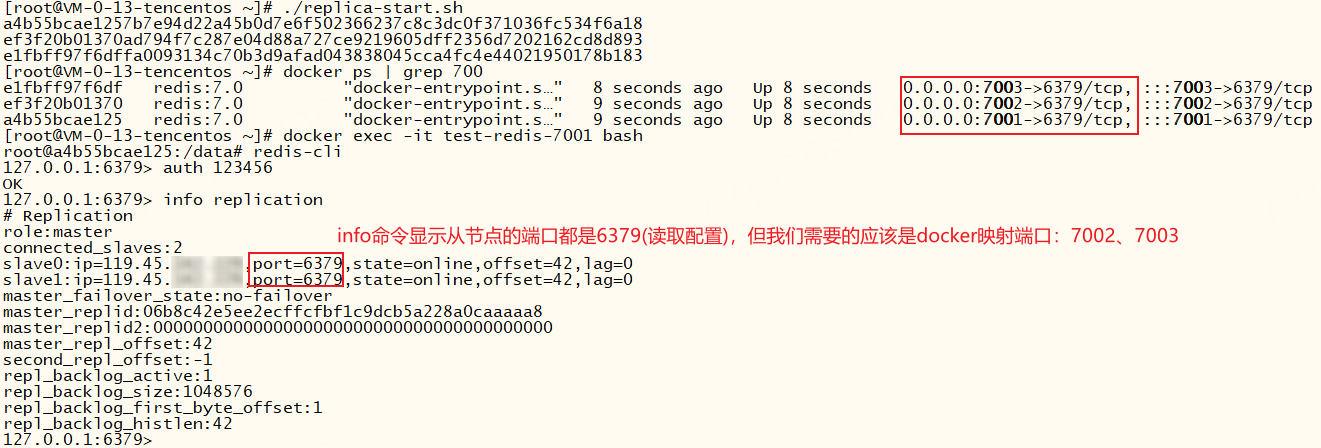
我们只需要把两个从节点真正的地址追加到哨兵配置文件即可
xxxxxxxxxx# sentinel known-replica masterName 119.45.100.200 7002# sentinel known-replica masterName 119.45.100.200 7003printf "sentinel known-replica masterName 119.45.100.200 7002 \nsentinel known-replica masterName 119.45.100.200 7003 \n" >> /home/redis-test/test-redis-replica/s7007/conf/redis-sentinel.confprintf "sentinel known-replica masterName 119.45.100.200 7002 \nsentinel known-replica masterName 119.45.100.200 7003 \n" >> /home/redis-test/test-redis-replica/s7006/conf/redis-sentinel.conf# 重启哨兵服务docker restart test-redis-s-7006 test-redis-s-7007# 模拟主节点7001宕机docker kill test-redis-7001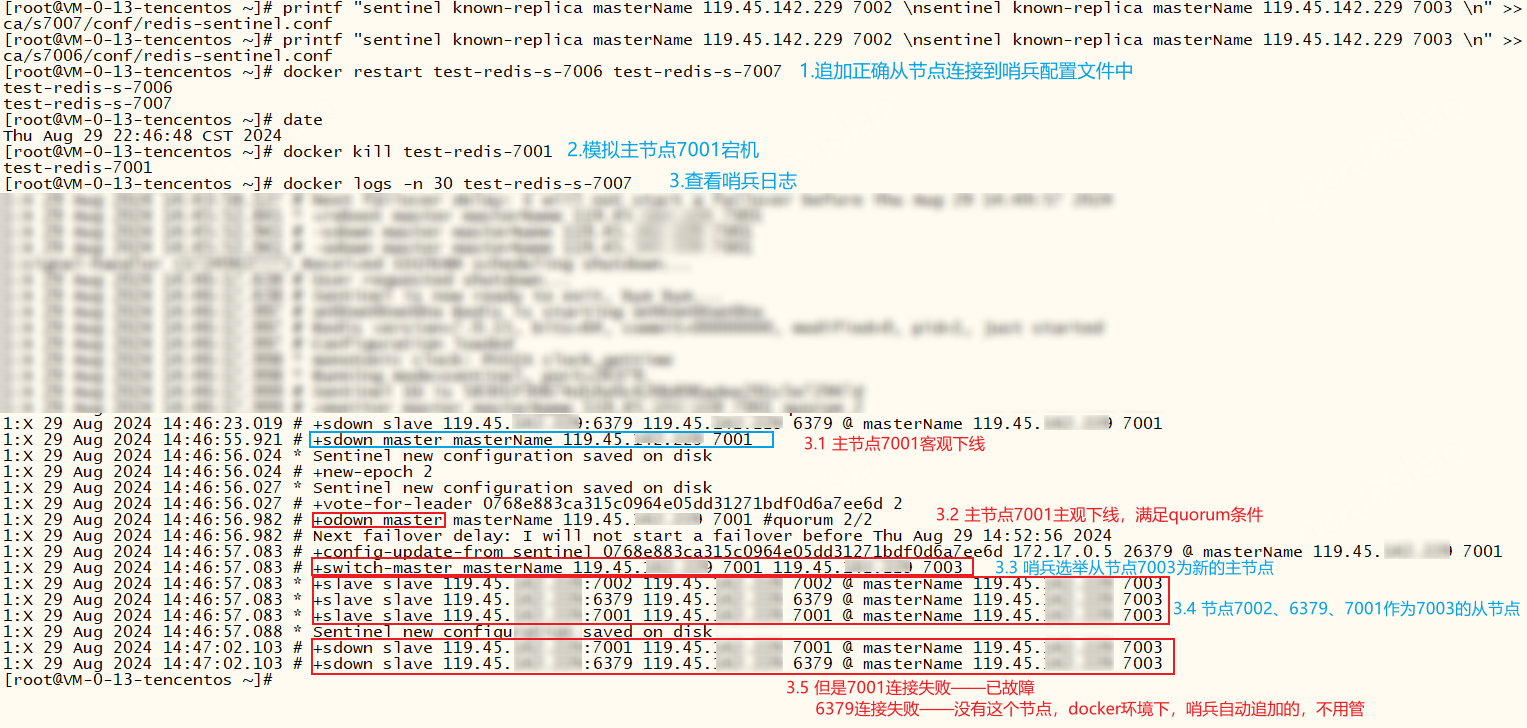
到此,哨兵可自动完成切换,哨兵切换的同时也会修改哨兵的配置文件,如下,监听主节点和连接从节点的地址都发生改变
当然,为了方便,在使用docker搭建哨兵模式时,也可以直接把从节点写到我们的配置文件中
xxxxxxxxxx# 指定从节点为7002、7003sentinel known-replica masterName 119.45.100.200 7002sentinel known-replica masterName 119.45.100.200 7003哨兵故障转移后,redis节点日志出现权限不足无法修改配置文件的情况
# Could not create tmp config file (Permission denied) # CONFIG REWRITE failed: Permission denied

这种情况一般是docker挂载直接映射配置文件导致的,我们修改成映射配置文件所在的目录并给该目录添加写权限即可
xxxxxxxxxxdocker run -d -p 7001:6379 --name test-redis-7001 --restart=always \ -v /home/redis-test/test-redis-replica/7001/data:/data \ -v /home/redis-test/test-redis-replica/7001/conf:/etc/redis/conf \ redis:7.0 redis-server /etc/redis/conf/redis-re.conf# -v /home/redis-test/test-redis-replica/7001/conf:/etc/redis/conf 映射配置文件所在的目录,redis-re.conf 名称要写对chmod 777 /home/redis-test/test-redis-replica/7001/conf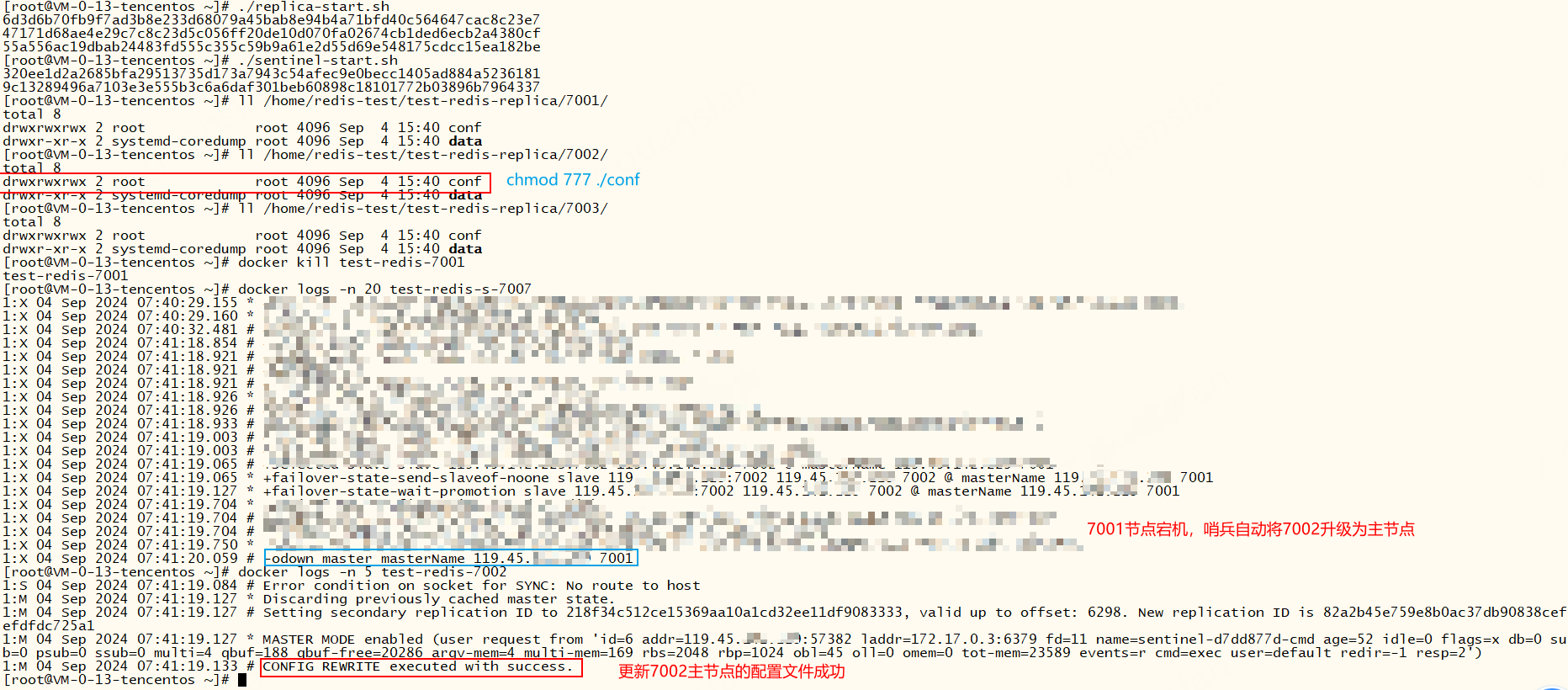
故障转移后更新配置文件成功如下
一键启动哨兵
测试环境下,单个机器部署多个哨兵节点,一键部署,方便测试。将以下命令写进sentinel-start.sh文件,并执行即可——sentinel-start.sh
xxxxxxxxxxchomd +x ./sentinel-start.shxxxxxxxxxx#### s7005mkdir -p /home/redis-test/test-redis-replica/s7005/confcat << EOF > /home/redis-test/test-redis-replica/s7005/conf/redis-sentinel.confbind 0.0.0.0# 端口,默认26379port 26379# 最重要的。监控主节点获取主节点和从节点(info replication)的信息 2表示quorum,建议设置为哨兵节点个数的一半并向上取整sentinel monitor masterName 119.45.100.200 7001 2# 主从模式主节点的密码sentinel auth-pass masterName 123456# 故障转移,选举master时使用。从节点与主节点断开时间长短指定值sentinel down-after-milliseconds masterName 10000 sentinel failover-timeout masterName 50000# 指定从节点为7002、7003sentinel known-replica masterName 119.45.100.200 7002sentinel known-replica masterName 119.45.100.200 7003EOFdocker run -d -p 7005:26379 --name test-redis-s-7005 --restart=always \ -v /home/redis-test/test-redis-replica/s7005/data:/data \ -v /home/redis-test/test-redis-replica/s7005/conf:/etc/redis:rw \ redis:7.0 redis-sentinel /etc/redis/redis-sentinel.conf#### s7006mkdir -p /home/redis-test/test-redis-replica/s7006/confcat << EOF > /home/redis-test/test-redis-replica/s7006/conf/redis-sentinel.confbind 0.0.0.0# 端口,默认26379port 26379# 最重要的。监控主节点获取主节点和从节点(info replication)的信息 2表示quorum,建议设置为哨兵节点个数的一半并向上取整sentinel monitor masterName 119.45.100.200 7001 2# 主从模式主节点的密码sentinel auth-pass masterName 123456# 故障转移,选举master时使用。从节点与主节点断开时间长短指定值sentinel down-after-milliseconds masterName 10000 sentinel failover-timeout masterName 50000# 指定从节点为7002、7003sentinel known-replica masterName 119.45.100.200 7002sentinel known-replica masterName 119.45.100.200 7003EOFdocker run -d -p 7006:26379 --name test-redis-s-7006 --restart=always \ -v /home/redis-test/test-redis-replica/s7006/data:/data \ -v /home/redis-test/test-redis-replica/s7006/conf:/etc/redis:rw \ redis:7.0 redis-sentinel /etc/redis/redis-sentinel.conf#### s7007mkdir -p /home/redis-test/test-redis-replica/s7007/confcat << EOF >/home/redis-test/test-redis-replica/s7007/conf/redis-sentinel.confbind 0.0.0.0# 端口,默认26379port 26379# 最重要的。监控主节点获取主节点和从节点(info replication)的信息 2表示quorum,建议设置为哨兵节点个数的一半并向上取整sentinel monitor masterName 119.45.100.200 7001 2# 主从模式主节点的密码sentinel auth-pass masterName 123456# 故障转移,选举master时使用。从节点与主节点断开时间长短指定值sentinel down-after-milliseconds masterName 10000 sentinel failover-timeout masterName 50000# 指定从节点为7002、7003sentinel known-replica masterName 119.45.100.200 7002sentinel known-replica masterName 119.45.100.200 7003EOFdocker run -d -p 7007:26379 --name test-redis-s-7007 --restart=always \ -v /home/redis-test/test-redis-replica/s7007/data:/data \ -v /home/redis-test/test-redis-replica/s7007/conf:/etc/redis:rw \ redis:7.0 redis-sentinel /etc/redis/redis-sentinel.conf一键关闭哨兵
测试环境下,单个机器部署多个哨兵节点,一键关闭主从+哨兵,方便测试。将以下命令写进stop-all.sh文件,并执行即可——stop-all.sh
xxxxxxxxxx rm -rf /home/redis-test/test-redis-replicamkdir /home/redis-test/test-redis-replicadocker rm -f test-redis-7001 test-redis-7002 test-redis-7003 test-redis-s-7005 test-redis-s-7006 test-redis-s-7007分片集群—Cluster
主从模式+哨兵机制可以很好的帮助我们提高redis并发能力和故障恢复,实现高并发高可用的效果。但还有一个问题,随着业务量增大,数据会越来越大。由于主从模式是通过复制来实现数据一致的,相当于三台机器保存同一份大文件(如总数据大小100G,使用主从复制,A、B、C三台机器均保存100G文件)这样才能在不同的机器读取到相同数据。显而易见,这种方式数据冗余比较多,而且三台机器都要使用更大的存储空间和内存来保存数据。而且主从模式+哨兵,很难扩容,节点越多越复杂
我们可不可以实现三台机器各自保存一部分数据呢?(如总数据大小100G,A机器保存40G,B、C机器各保存30G)而且还要支持在不同的机器读取到相同数据。当然可以,redis分片集群支持分片保存数据。
分片集群图解
redis分片集群可用来解决海量数据存储和高并发写问题。分片集群有以下特点
- 一个分片集群有多个master节点,每个master节点存储不同的数据
- 每个master都可以有多个slave节点,用于故障转移主从切换
- 不再需要哨兵监控,每个master通过ping检测彼此健康状态
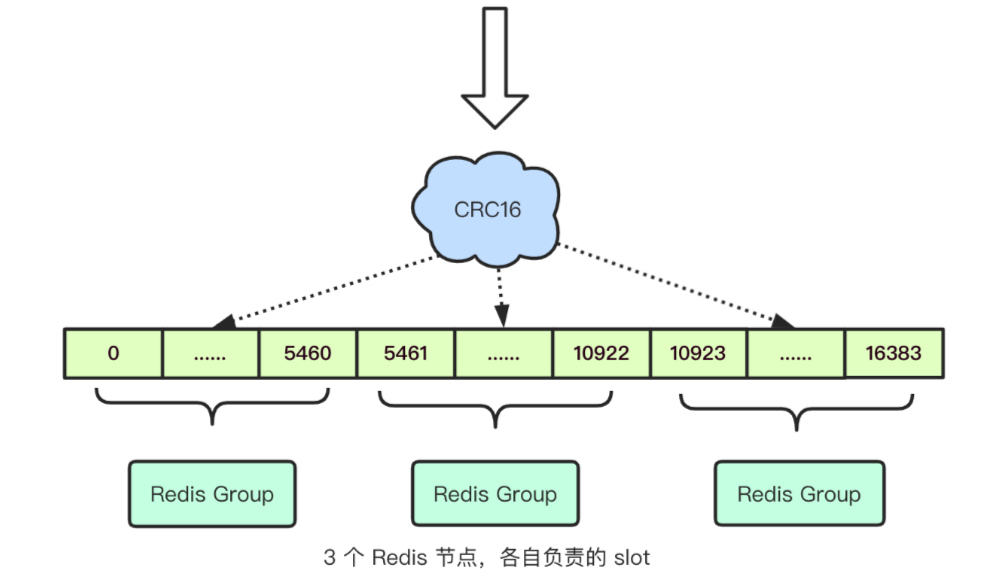
Redis默认使用虚拟槽分区,Redis会预先给每个主节点分配16384个插槽(slot),每个节点负责一定区间的slot(如 A:0-5460,B:5461-10922,C: 10923-16383)。存储和读取缓存时,自动对 key 使用 CRC16 算法计算再对16384取余,得到一个slot的值,并根据slot值寻找并路由到相应节点,然后在该节点上存储或读取数据。当有新的节点加入或者移除的时候,通过迁移槽以及其对应的数据,可以很方便的进行动态扩容或缩容
注意分片集群不是只能存储16384个key,slot值仅仅是用来确认操作节点。不同的key计算出相同的slot不会互相覆盖
配置文件cluster.conf
xxxxxxxxxxport 6379# bind 127.0.0.1 -:1 0.0.0.0外网可访问bind 0.0.0.0# 开启集群cluster-enabled yes# 指定集群配置文件,无需创建,自动生成cluster-config-file conf/nodes.conf# 节点心跳超时事件cluster-node-timeout 5000# 持久化文件存放目录dir data/# 后台运行 使用docker启动,不要指定yesdaemonize no# 保护模式protected-mode no# 日志文件logfile logs/run.log一键部署关闭集群
测试环境下,单个机器部署多个redis节点,一键部署主从模式,方便测试。将以下命令写进replica-start.sh文件,并执行即可——cluster-start.sh
xxxxxxxxxx# 一键部署7001-7006节点##### 7001mkdir -p /home/redis-test/test-redis-cluster/7001/confchmod 777 /home/redis-test/test-redis-cluster/7001/confcat << EOF > /home/redis-test/test-redis-cluster/7001/conf/redis-cluster.conf# 指定端口port 7001# bind 127.0.0.1 -:1 0.0.0.0外网可访问bind 0.0.0.0# 开启集群cluster-enabled yes# 指定集群配置文件,无需创建,自动生成cluster-config-file /etc/redis/conf/nodes.conf# 节点心跳超时事件cluster-node-timeout 5000# 持久化文件存放目录dir /data/# 后台运行daemonize no# 保护模式protected-mode no# 日志文件logfile /data/logs/run.log# 指定密码requirepass 123456masterauth 123456# 集群总线端口cluster-announce-bus-port 17001EOFdocker run -d -p 7001:7001 -p 17001:17001 --name test-cluster-7001 --restart=always \ -v /home/redis-test/test-redis-cluster/7001/data:/data \ -v /home/redis-test/test-redis-cluster/7001/conf:/etc/redis/conf \ -v /home/redis-test/test-redis-cluster/7001/logs:/data/logs \ redis:7.0 redis-server /etc/redis/conf/redis-cluster.conf##### 7002mkdir -p /home/redis-test/test-redis-cluster/7002/confchmod 777 /home/redis-test/test-redis-cluster/7002/confcat << EOF > /home/redis-test/test-redis-cluster/7002/conf/redis-cluster.conf# 指定端口port 7002# bind 127.0.0.1 -:1 0.0.0.0外网可访问bind 0.0.0.0# 开启集群cluster-enabled yes# 指定集群配置文件,无需创建,自动生成cluster-config-file /etc/redis/conf/nodes.conf# 节点心跳超时事件cluster-node-timeout 5000# 持久化文件存放目录dir /data/# 后台运行daemonize no# 保护模式protected-mode no# 日志文件logfile /data/logs/run.log# 指定密码requirepass 123456masterauth 123456# 集群总线端口cluster-announce-bus-port 17002EOFdocker run -d -p 7002:7002 -p 17002:17002 --name test-cluster-7002 --restart=always \ -v /home/redis-test/test-redis-cluster/7002/data:/data \ -v /home/redis-test/test-redis-cluster/7002/conf:/etc/redis/conf \ -v /home/redis-test/test-redis-cluster/7002/logs:/data/logs \ redis:7.0 redis-server /etc/redis/conf/redis-cluster.conf##### 7003mkdir -p /home/redis-test/test-redis-cluster/7003/confchmod 777 /home/redis-test/test-redis-cluster/7003/confcat << EOF > /home/redis-test/test-redis-cluster/7003/conf/redis-cluster.conf# 指定端口port 7003# bind 127.0.0.1 -:1 0.0.0.0外网可访问bind 0.0.0.0# 开启集群cluster-enabled yes# 指定集群配置文件,无需创建,自动生成cluster-config-file /etc/redis/conf/nodes.conf# 节点心跳超时事件cluster-node-timeout 5000# 持久化文件存放目录dir /data/# 后台运行daemonize no# 保护模式protected-mode no# 日志文件logfile /data/logs/run.log# 指定密码requirepass 123456masterauth 123456# 集群总线端口cluster-announce-bus-port 17003EOFdocker run -d -p 7003:7003 -p 17003:17003 --name test-cluster-7003 --restart=always \ -v /home/redis-test/test-redis-cluster/7003/data:/data \ -v /home/redis-test/test-redis-cluster/7003/conf:/etc/redis/conf \ -v /home/redis-test/test-redis-cluster/7003/logs:/data/logs \ redis:7.0 redis-server /etc/redis/conf/redis-cluster.conf##### 7004mkdir -p /home/redis-test/test-redis-cluster/7004/confchmod 777 /home/redis-test/test-redis-cluster/7004/confcat << EOF > /home/redis-test/test-redis-cluster/7004/conf/redis-cluster.conf# 指定端口port 7004# bind 127.0.0.1 -:1 0.0.0.0外网可访问bind 0.0.0.0# 开启集群cluster-enabled yes# 指定集群配置文件,无需创建,自动生成cluster-config-file /etc/redis/conf/nodes.conf# 节点心跳超时事件cluster-node-timeout 5000# 持久化文件存放目录dir /data/# 后台运行daemonize no# 保护模式protected-mode no# 日志文件logfile /data/logs/run.log# 指定密码requirepass 123456masterauth 123456# 集群总线端口cluster-announce-bus-port 17004EOFdocker run -d -p 7004:7004 -p 17004:17004 --name test-cluster-7004 --restart=always \ -v /home/redis-test/test-redis-cluster/7004/data:/data \ -v /home/redis-test/test-redis-cluster/7004/conf:/etc/redis/conf \ -v /home/redis-test/test-redis-cluster/7004/logs:/data/logs \ redis:7.0 redis-server /etc/redis/conf/redis-cluster.conf##### 7005mkdir -p /home/redis-test/test-redis-cluster/7005/confchmod 777 /home/redis-test/test-redis-cluster/7005/confcat << EOF > /home/redis-test/test-redis-cluster/7005/conf/redis-cluster.conf# 指定端口port 7005# bind 127.0.0.1 -:1 0.0.0.0外网可访问bind 0.0.0.0# 开启集群cluster-enabled yes# 指定集群配置文件,无需创建,自动生成cluster-config-file /etc/redis/conf/nodes.conf# 节点心跳超时事件cluster-node-timeout 5000# 持久化文件存放目录dir /data/# 后台运行daemonize no# 保护模式protected-mode no# 日志文件logfile /data/logs/run.log# 指定密码requirepass 123456masterauth 123456# 集群总线端口cluster-announce-bus-port 17005EOFdocker run -d -p 7005:7005 -p 17005:17005 --name test-cluster-7005 --restart=always \ -v /home/redis-test/test-redis-cluster/7005/data:/data \ -v /home/redis-test/test-redis-cluster/7005/conf:/etc/redis/conf \ -v /home/redis-test/test-redis-cluster/7005/logs:/data/logs \ redis:7.0 redis-server /etc/redis/conf/redis-cluster.conf##### 7006mkdir -p /home/redis-test/test-redis-cluster/7006/confchmod 777 /home/redis-test/test-redis-cluster/7006/confcat << EOF > /home/redis-test/test-redis-cluster/7006/conf/redis-cluster.conf# 指定端口port 7006# bind 127.0.0.1 -:1 0.0.0.0外网可访问bind 0.0.0.0# 开启集群cluster-enabled yes# 指定集群配置文件,无需创建,自动生成cluster-config-file /etc/redis/conf/nodes.conf# 节点心跳超时事件cluster-node-timeout 5000# 持久化文件存放目录dir /data/# 后台运行daemonize no# 保护模式protected-mode no# 日志文件logfile /data/logs/run.log# 指定密码requirepass 123456masterauth 123456# 集群总线端口cluster-announce-bus-port 17006EOFdocker run -d -p 7006:7006 -p 17006:17006 --name test-cluster-7006 --restart=always \ -v /home/redis-test/test-redis-cluster/7006/data:/data \ -v /home/redis-test/test-redis-cluster/7006/conf:/etc/redis/conf \ -v /home/redis-test/test-redis-cluster/7006/logs:/data/logs \ redis:7.0 redis-server /etc/redis/conf/redis-cluster.confxxxxxxxxxx# 一键关闭7001-7006节点rm -rf /home/redis-test/test-redis-clustermkdir /home/redis-test/test-redis-clusterfor port in $(seq 7001 7006);do docker rm -f test-cluster-${port}done创建集群
创建集群之前,防火墙先开放端口:节点端口7001-7010,总线端口17001-17010。
xxxxxxxxxx# 记得开放端口firewall-cmd --zone=public --add-port=7001-7010/tcp --permanent# 开放总线端口firewall-cmd --zone=public --add-port=17001-17010/tcp --permanentfirewall-cmd --reload公网服务器还需要设置安全组开放指定端口,谨慎操作
部署并启动6个节点后,还需要手动执行相应命令创建集群,将所有节点关联起来
xxxxxxxxxx# 随便进入一个节点docker exec -it test-cluster-7001 bash# 创建集群 执行后输入yes,输入其他的话会直接终止创建集群redis-cli --cluster create --cluster-replicas 1 119.45.100.200:7001 119.45.100.200:7002 119.45.100.200:7003 119.45.100.200:7004 119.45.100.200:7005 119.45.100.200:7006 -a 123456# --cluster-replicas 1 表示集群的副本数量为1,master默认是1,两个节点一组。这里一共6个节点,6/2=3,一共三个master节点。默认前三个为master节点,后三个为副本节点。注意,这里主从没有固定的对应关系,7001的从节点可能是7004、7005、7006三个其中一个,一切要看实际分配方案,也可以创建集群后通过 redis-cli -p 7001 cluster nodes 查看集群状态查看# 没有从节点可以不指定--cluster-replicas,或者指定为--cluster-replicas 0即可# -a 123456 指定密码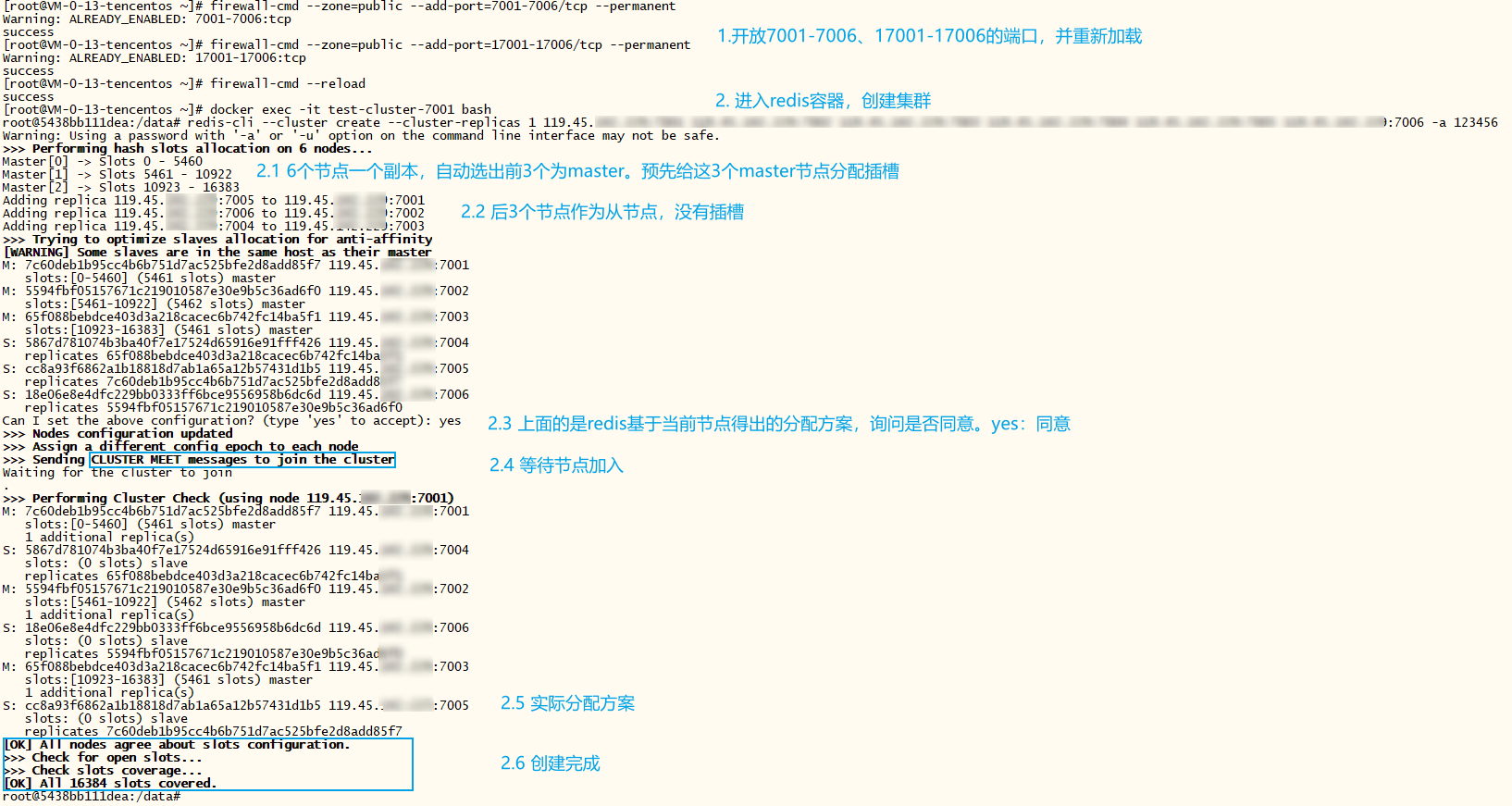
注意,Redis5.0之后,集群管理操作已经集成到了redis-cli中,我们只需要redis-cli命令即可管理集群。Redis5.0之前,需安装redis-trib.rb才能管理集群
分片集群演示
演示之前我们先了解一下插槽,Redis会预先分配16384个插槽给每个主节点,每个主节点负责一定区间的slot。redis会根据key的有效部分自动计算插槽值,再找到对应的节点进行读写数据。意味着我们无需刻意知道数据与哪个插槽绑定,更不需要知道数据在哪个节点上
redis数据key不是和节点绑定,而是与插槽绑定,方便扩容缩容迁移数据,若数据key和节点绑定,节点宕机无法恢复,那意味着数据就永久丢失了。

redis分片集群可以连接从节点写入数据,不过最终写入操作还是由主节点执行(从节点只计算插槽并路由)
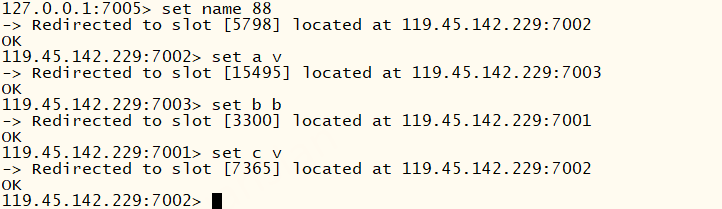
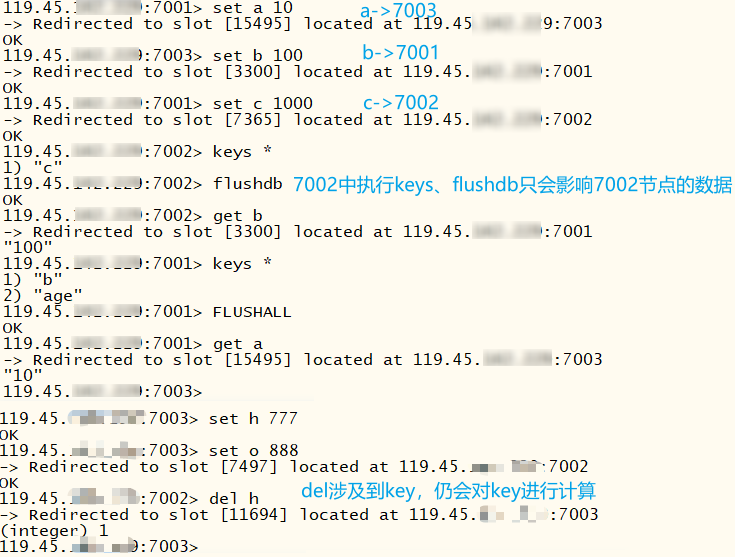
注意在redis集群中,keys * 、flushdb、flushall只能操作当前节点的数据,不能操作整个集群的数据。
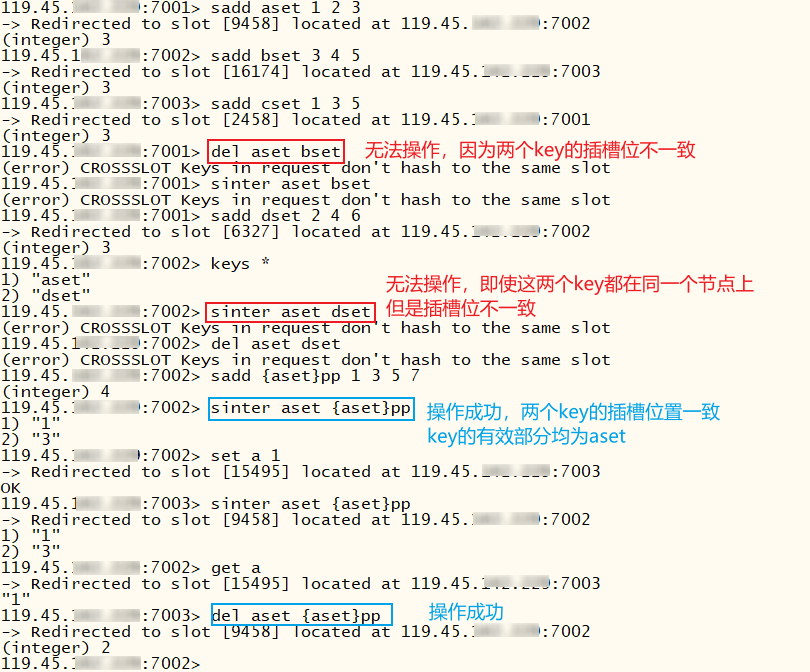
一条命令有时无法同时操作多个key(如DEL、SINTER...)判断依据是key的有效部分。若这些key有效部分相同则允许操作,若不一致则会报错:(error) CROSSSLOT Keys in request don't hash to the same slot
redis分片集群默认只有1个数据库,无法执行select db选择数据库,否则报错:(error) ERR SELECT is not allowed in cluster mode

故障演示
redis三主三从分片集群,如果某个主节点宕机后,该主节点的下的从节点会自动选举升级为新主节点,代替故障主节点工作
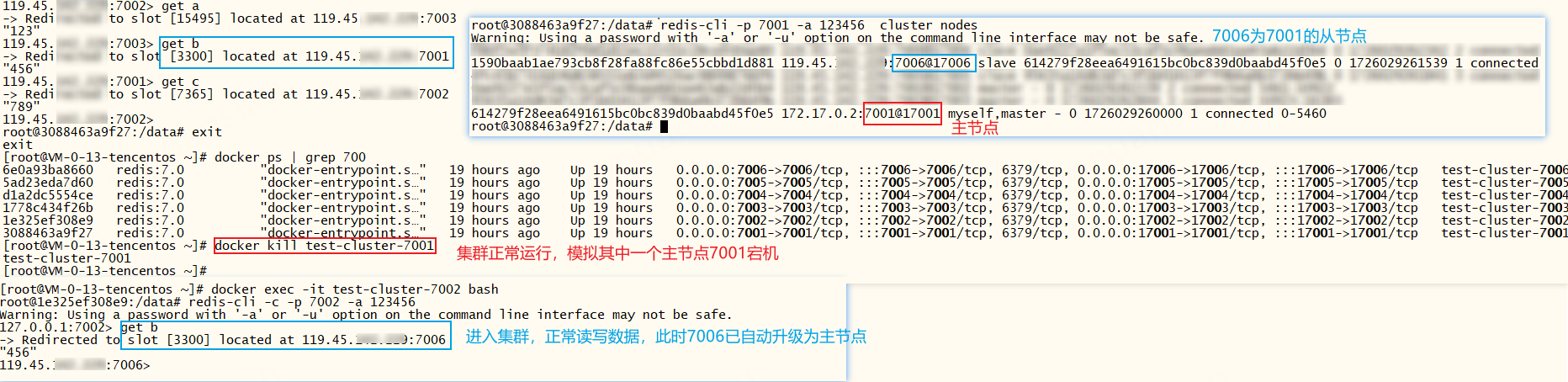
我们可以查看一下新主节点7006的日志和当前集群状态
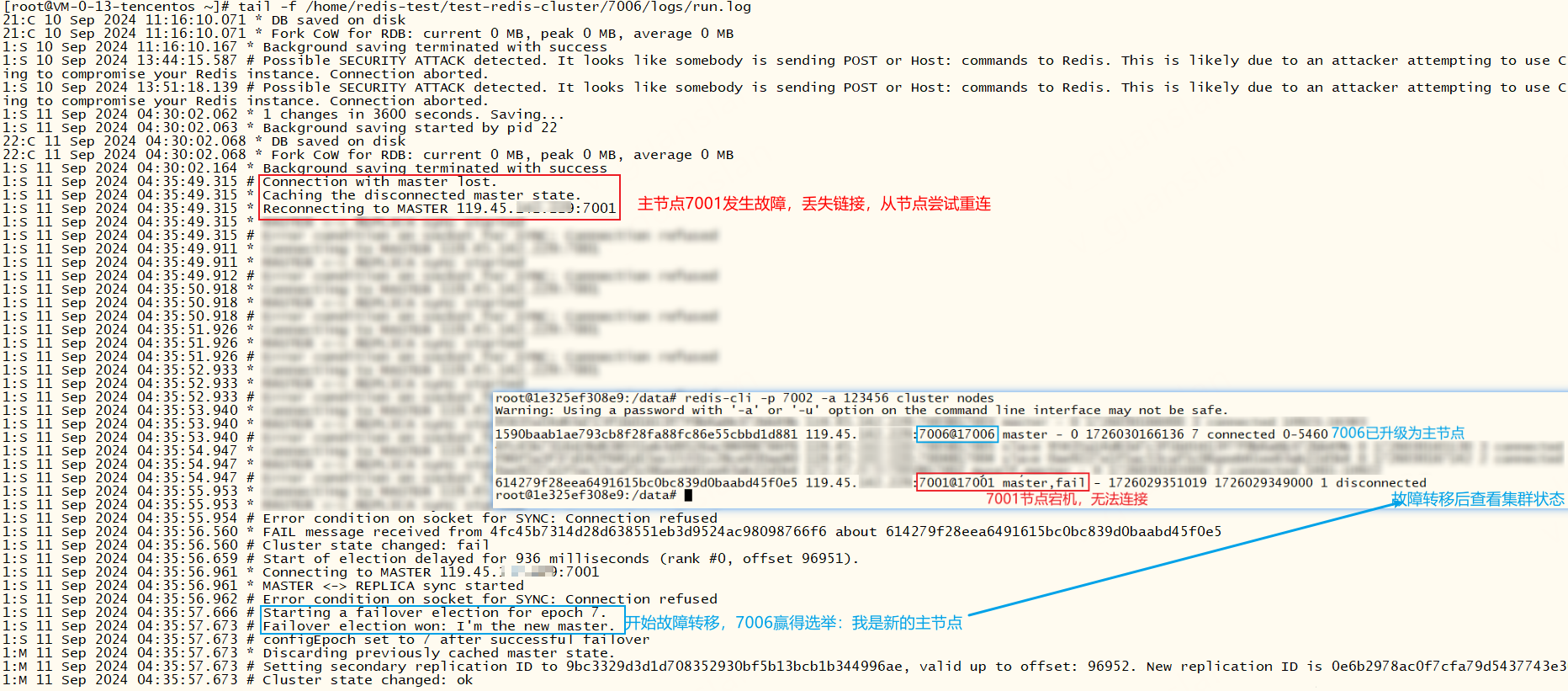
redis三主三从分片集群,如果某个主节点宕机后,故障转移完成后,新主节点再次宕机,此时整个集群将不可用,报错:(error) CLUSTERDOWN The cluster is down。难道redis分片集群最少需要三个主节点才能正常工作吗?继续往下看
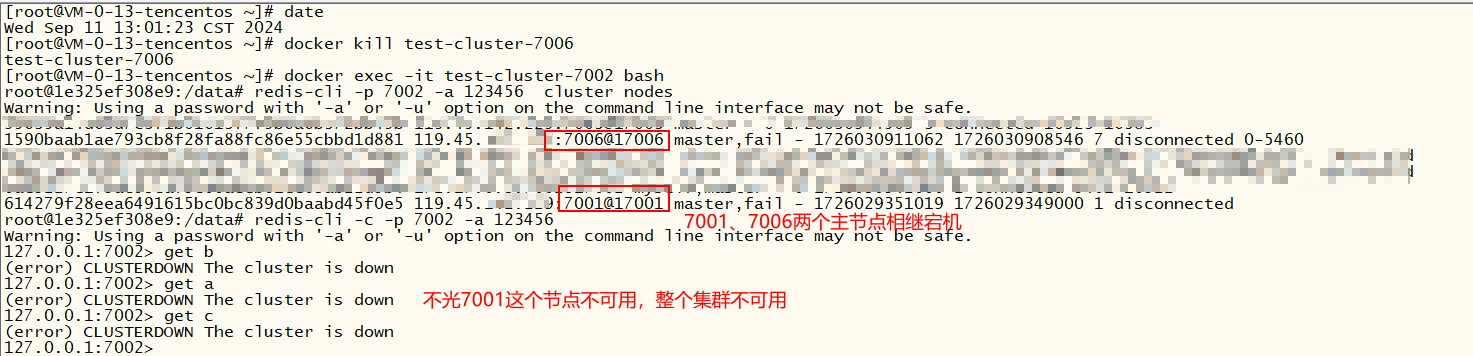

redis三主三从分片集群,升级为四主四从,如果某个主节点宕机后,故障转移完成后,新主节点再次宕机,此时集群仍不可用,报错:(error) CLUSTERDOWN The cluster is down。说明当某个主节点宕机且该主节点不存在可用从节点时会导致集群不可用
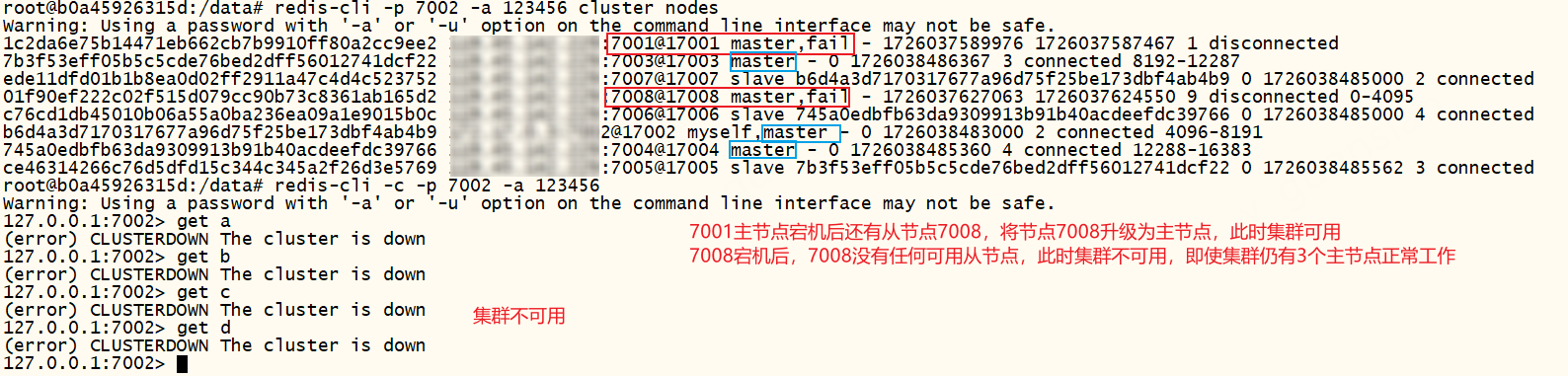
redis三主三从分片集群,如果超过半数的主节点宕机,集群不可用,报错:(error) CLUSTERDOWN The cluster is down。说明当集群中超过半数的主节点宕机,会导致集群不可用,即使故障主节点下存在可用的从节点。
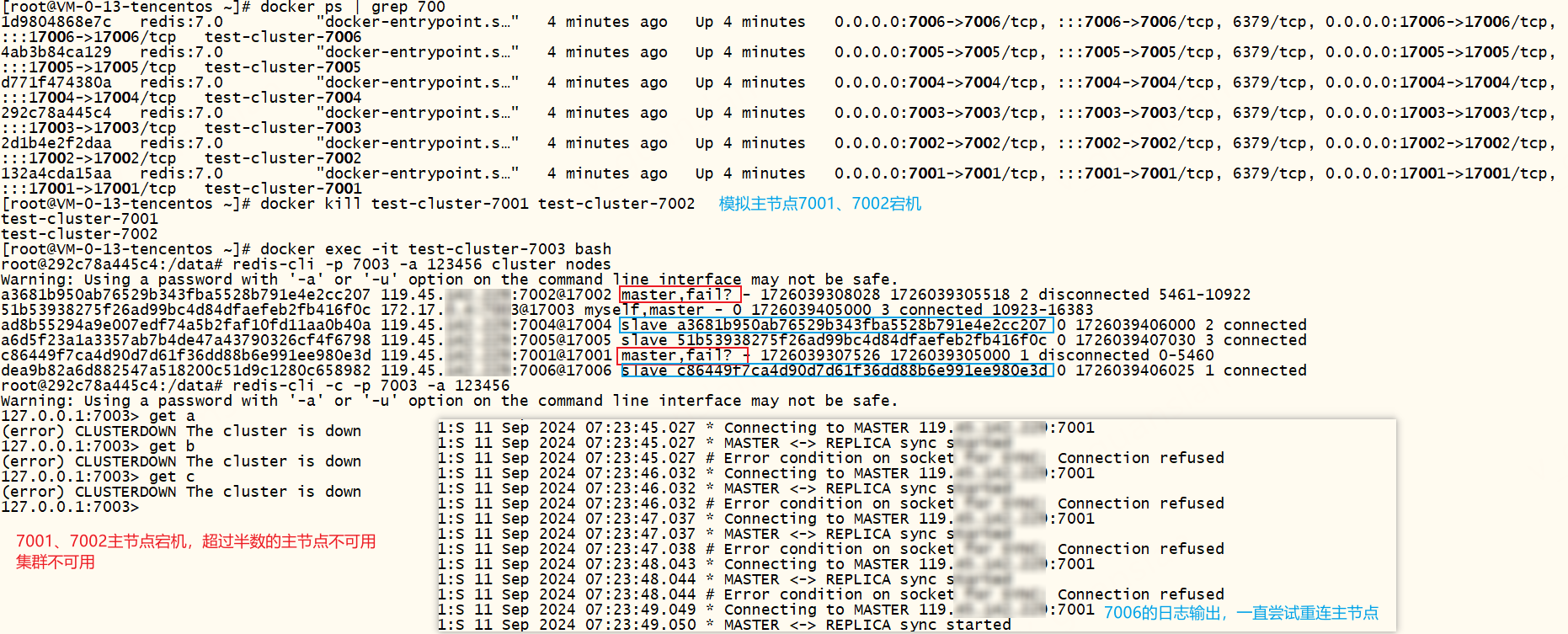
redis三主三从分片集群,若某个主节点宕机后,完成故障转移后,另一个主节点才宕机,待完成故障转移,此时集群仍可用。
redis三主三从分片集群,若某个主节点宕机后,完成故障转移后,故障主节点恢复后会直接变成从节点,并从新主节点同步数据
c#代码演示
以下演示一下c#代码如何连接并使用分片集群,源码参考:分片集群 · logerlink/RedisTest@9c84c6d (github.com)
redis分片集群连接字符串
xxxxxxxxxx"ConnectionStrings": { "Redis": "119.45.100.100:7001,119.45.100.100:7002,119.45.100.100:7003,119.45.100.100:7004,119.45.100.100:7005,119.45.100.100:7006,password=123456" },redis 帮助类改造——CommandFlags.PreferReplica优先从节点读取数据
xxxxxxxxxx /// <summary> /// redis 分片集群简单演示 /// </summary> public void RedisClusterTest() { var key = "redis_cluster_key_" + Guid.NewGuid(); try { var success = _redis.StringSet(key, "Hello world"); if (success) _logger.LogInformation($"RedisClusterTest 设置缓存成功"); else _logger.LogError($"RedisClusterTest 设置缓存失败"); } catch (Exception ex) { _logger.LogError($"RedisClusterTest 设置缓存失败,{ex.Message}"); } try { var data = _redis.StringGet(key); _logger.LogInformation($"RedisClusterTest 读取缓存成功"); } catch (Exception ex) { _logger.LogError($"RedisClusterTest 读取缓存失败,{ex.Message}"); } }redis集群常见命令——cluster
redis集群创建成功,我们可以使用cluster的相关命令查看和操作集群,需要进入redis环境中执行
xxxxxxxxxx# 查看帮助信息cluster help# 查看集群连接信息cluster LINKS# 查看集群信息 在redis中查看cluster info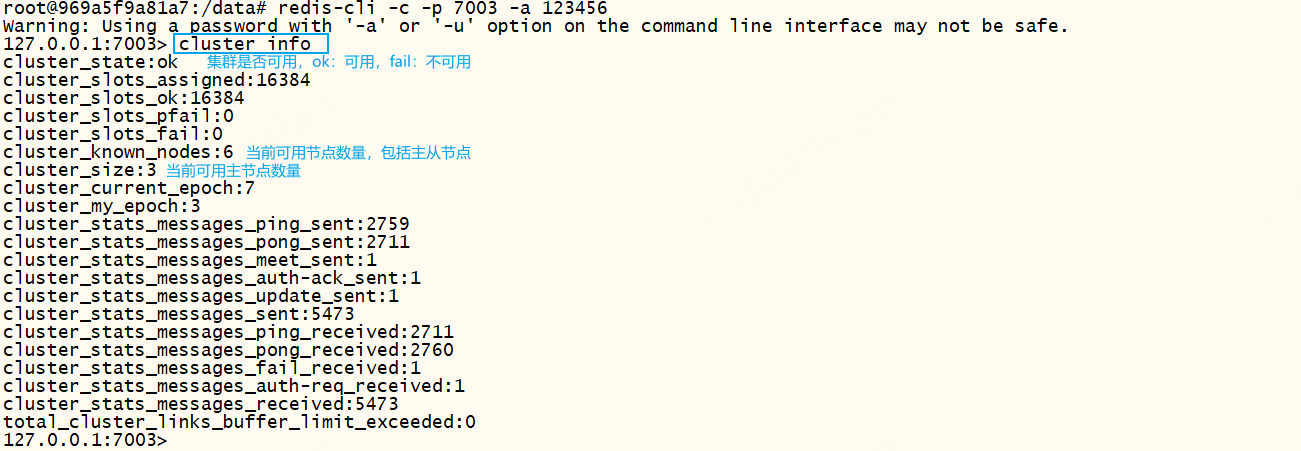
插槽相关
xxxxxxxxxx# 查看插槽分配情况cluster slots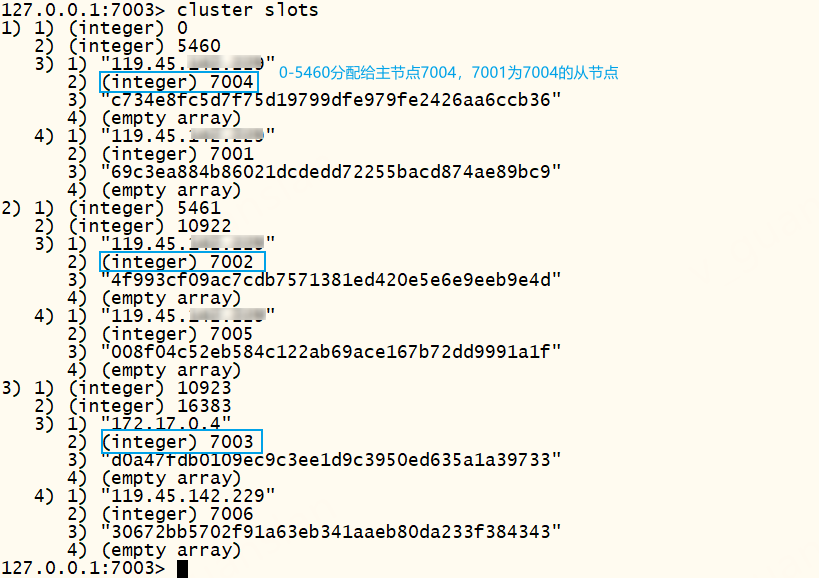
xxxxxxxxxx# 计数当前节点某个插槽有多少个keyCLUSTER COUNTKEYSINSLOT <slot># 查看当前节点插槽槽位上的所有keyCLUSTER GETKEYSINSLOT <slot> <COUNT># 查看集群中key的槽位,可以跨节点查询CLUSTER KEYSLOT <key># 清除当前节点预分配的所有槽位,若该节点存在数据,需要先清除,否则报错:(error) ERR DB must be empty to perform CLUSTER FLUSHSLOTS# 仅撤销当前节点的插槽,撤销插槽后,插槽未分配会导致该节点不可用。CLUSTER FLUSHSLOTS# 以下这些命令不知道怎么使用,组合在一起完全看不到效果,只能在同一个节点撤销插槽和分配插槽有什么用???建议使用redis-cli reshard命令来分配插槽# 撤销插槽。仅撤销当前节点的插槽,撤销插槽后,插槽未分配会导致该节点不可用。CLUSTER DELSLOTS <slot>...# 撤销一批插槽 slot1-slot2。仅撤销当前节点的插槽,撤销插槽后,插槽未分配会导致该节点不可用。CLUSTER DELSLOTSRANGE <slot1> <slot2># 指派插槽。不能跨节点指派,那有什么用?CLUSTER ADDSLOTS <slot>...# 指派一批插槽 slot1-slot2.不能跨节点指派,那有什么用?CLUSTER ADDSLOTSRANGE <slot1> <slot2>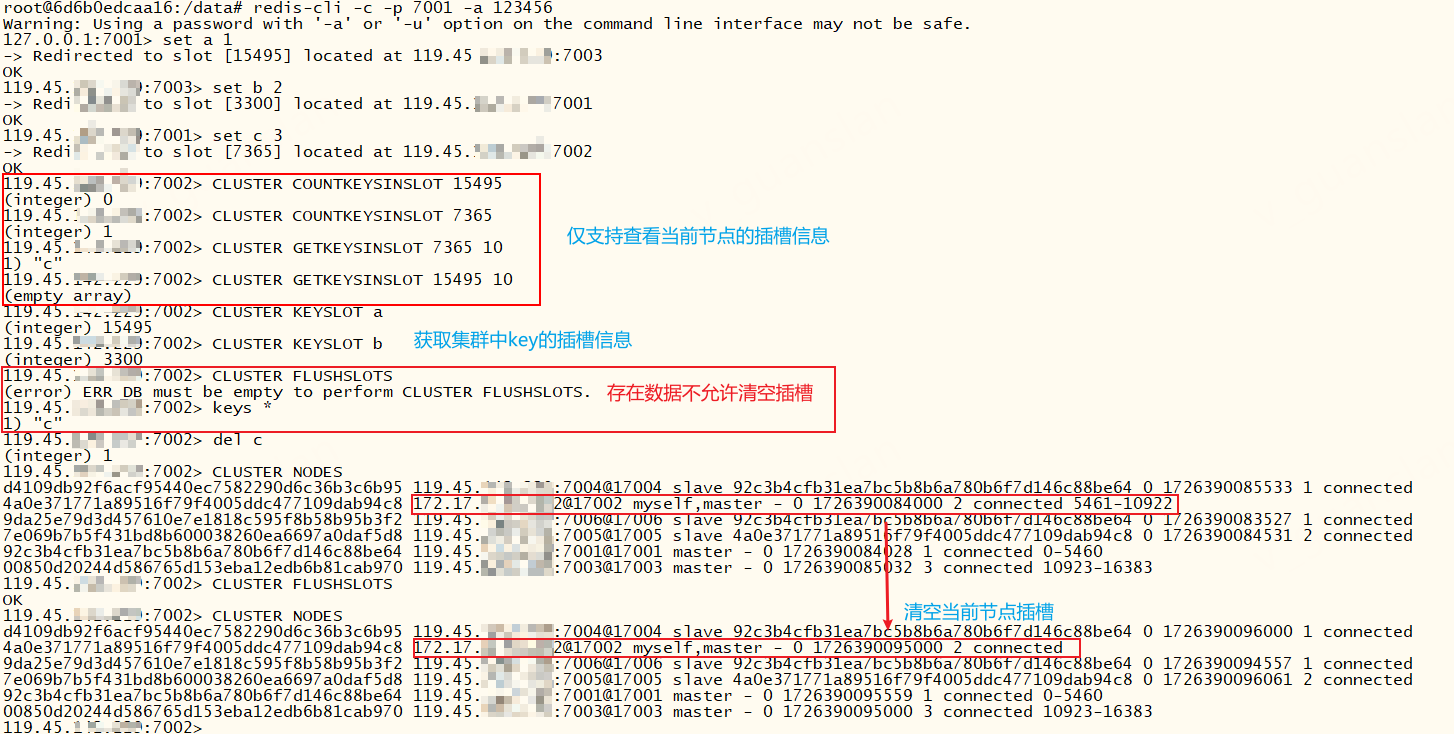
节点相关
xxxxxxxxxx# 查看节点IdCLUSTER MYID# 查看主节点的副本节点 node-id:节点Id,可通过CLUSTER MYID、CLUSTER NODES查看node-id。# 要在主节点执行,否则报错:(error) ERR The specified node is not a masterCLUSTER REPLICAS <node-id># 查看集群的所有节点CLUSTER NODES# 查看集群分片情况 包括插槽、节点信息CLUSTER SHARDS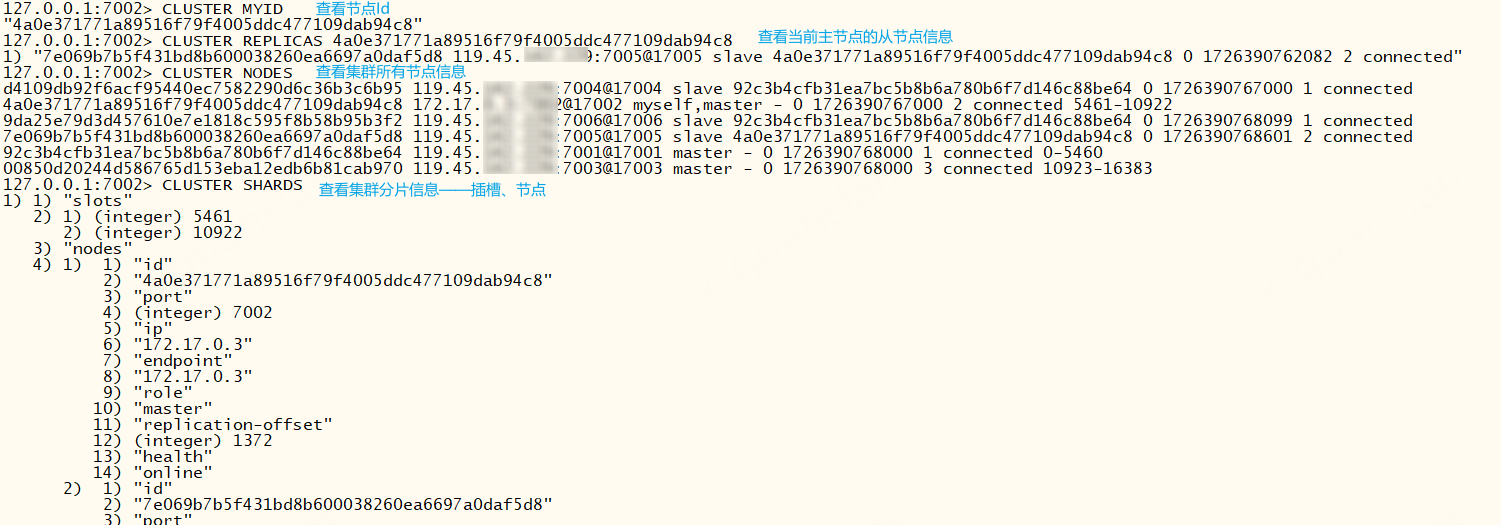
xxxxxxxxxx# 将指定节点加入集群# 默认添加进来的就是主节点,但是不会自动分配插槽,我们仍可以在这个新节点中执行 CLUSTER REPLICATE 主节点Id 将其变为从节点CLUSTER MEET <node_ip> <node_port> [bus_port]# 配置从节点复制主节点。# 注意要在即将变成从节点的节点上执行,且这个节点没有数据也没有分配插槽,否则报错:(error) ERR To set a master the node must be empty and without assigned slots.CLUSTER REPLICATE <nodeId># 从集群中移除节点。逻辑删除,并不是真正的移除,过一会又回来了(不明白有什么用)# 不能移除自身,否则报错:(error) ERR I tried hard but I can't forget myself。# 从节点也不能移除其主节点,否则报错:(error) ERR Can't forget my master!CLUSTER FORGET <node_id>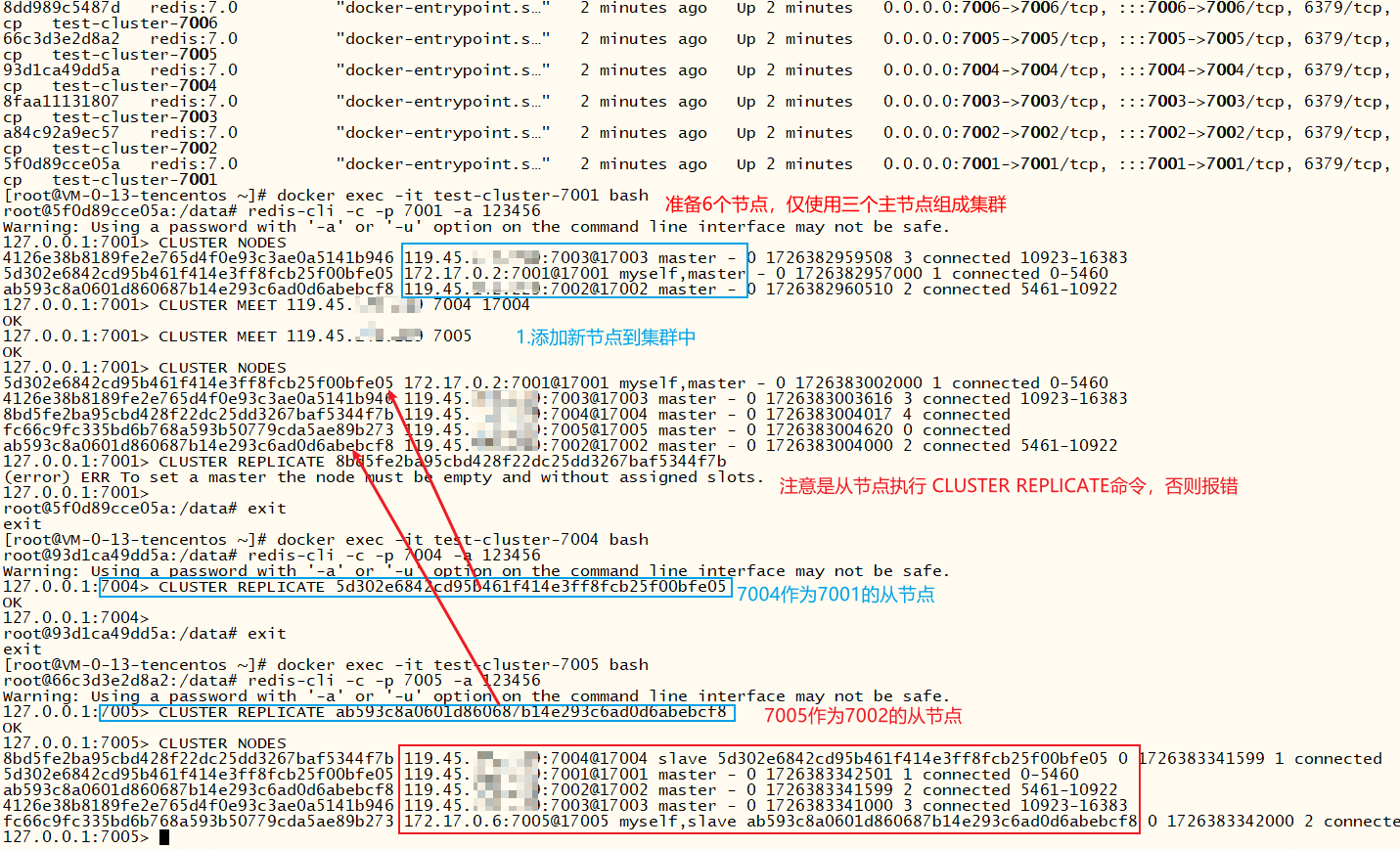
xxxxxxxxxx# 重置节点,遗忘该节点已知的其他所有节点CLUSTER RESETCLUSTER RESET用于重置节点,遗忘该节点已知的其他所有节点,撤销指派给该节点的所有槽,并清空节点内部的槽-节点映射。
重置之前主节点不可存在任何key(从节点不受限制)否则报错:(error) ERR CLUSTER RESET can't be called with master nodes containing keys。
可选参数HARD、SOFT,默认SOFT配置。如果执行的是HARD重置,那么该节点会创建一个新节点ID,并将节点的纪元和配置纪元都设置为0
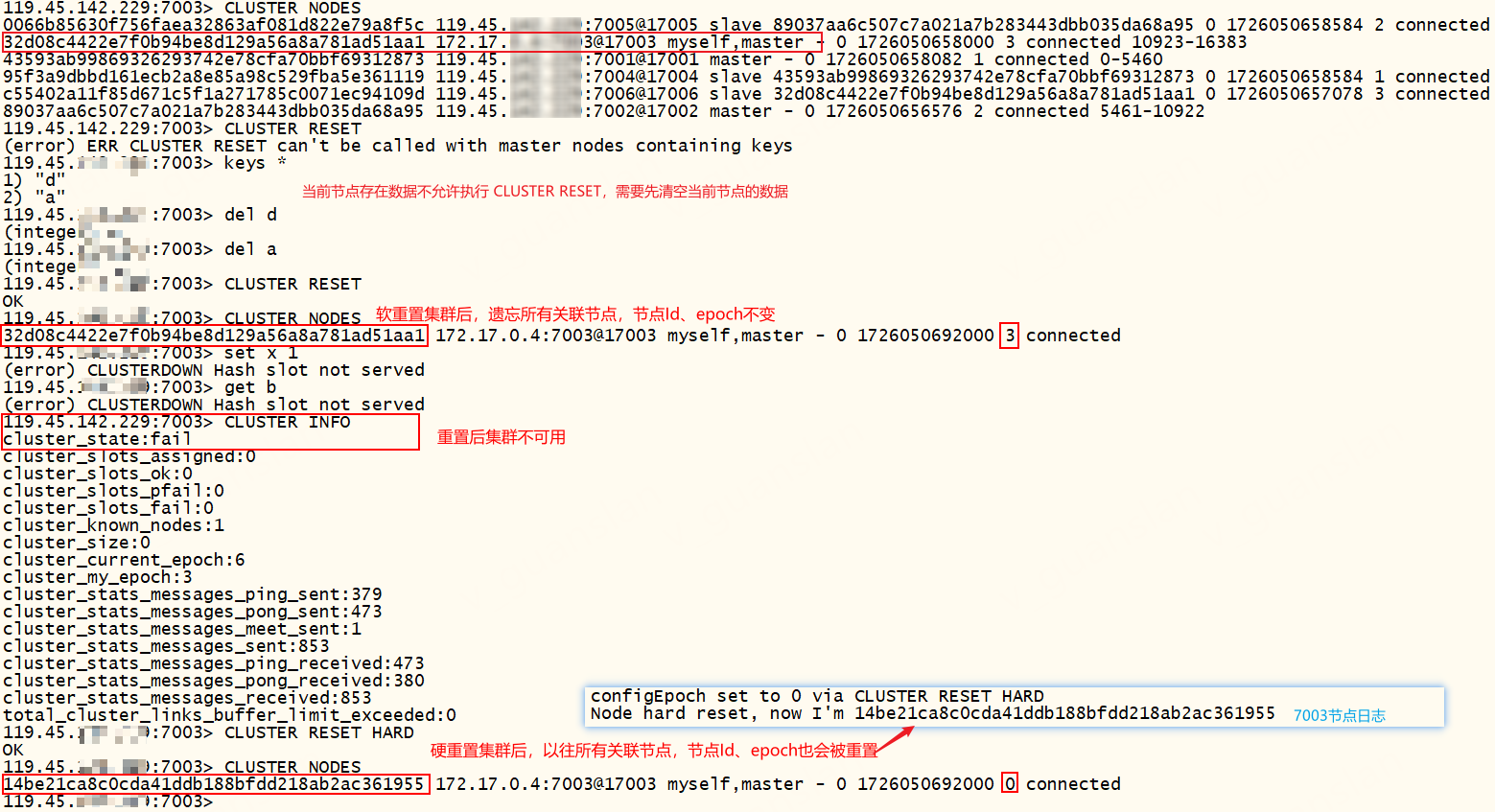
重置主节点后,集群状态显示ok,表示可用,7003节点失联。但是集群有些插槽不可用,读写数据时,redis计算key的slot值刚好落到已重置主节点之前的槽位,会报错这两种错误:
- (error) CLUSTERDOWN Hash slot not served (指定SOFT参数会出这个错误)。解决方案:连接另一个可用节点7001进去集群执行
CLUSTER MEET 119.45.100.200 7003 17003将重置节点7003重新加入集群,再连接重置节点7003进入集群执行CLUSTER ADDSLOTSRANGE 10923 16383添加全部插槽(不添加全部插槽仍然是失败的) - Could not connect to Redis at :0: Name or service not known(指定HARD参数会出这个错误),未重置的其他主节点不受影响,正常读写。解决方案:连接另一个可用节点7001进去集群执行
CLUSTER MEET 119.45.100.200 7003 17003将重置节点7003重新加入集群,并执行CLUSTER FORGET 原7003强重置前的节点Id让集群忘记旧节点Id,再连接重置节点7003进入集群执行CLUSTER ADDSLOTSRANGE 10923 16383添加全部插槽(不添加全部插槽仍然是失败的)
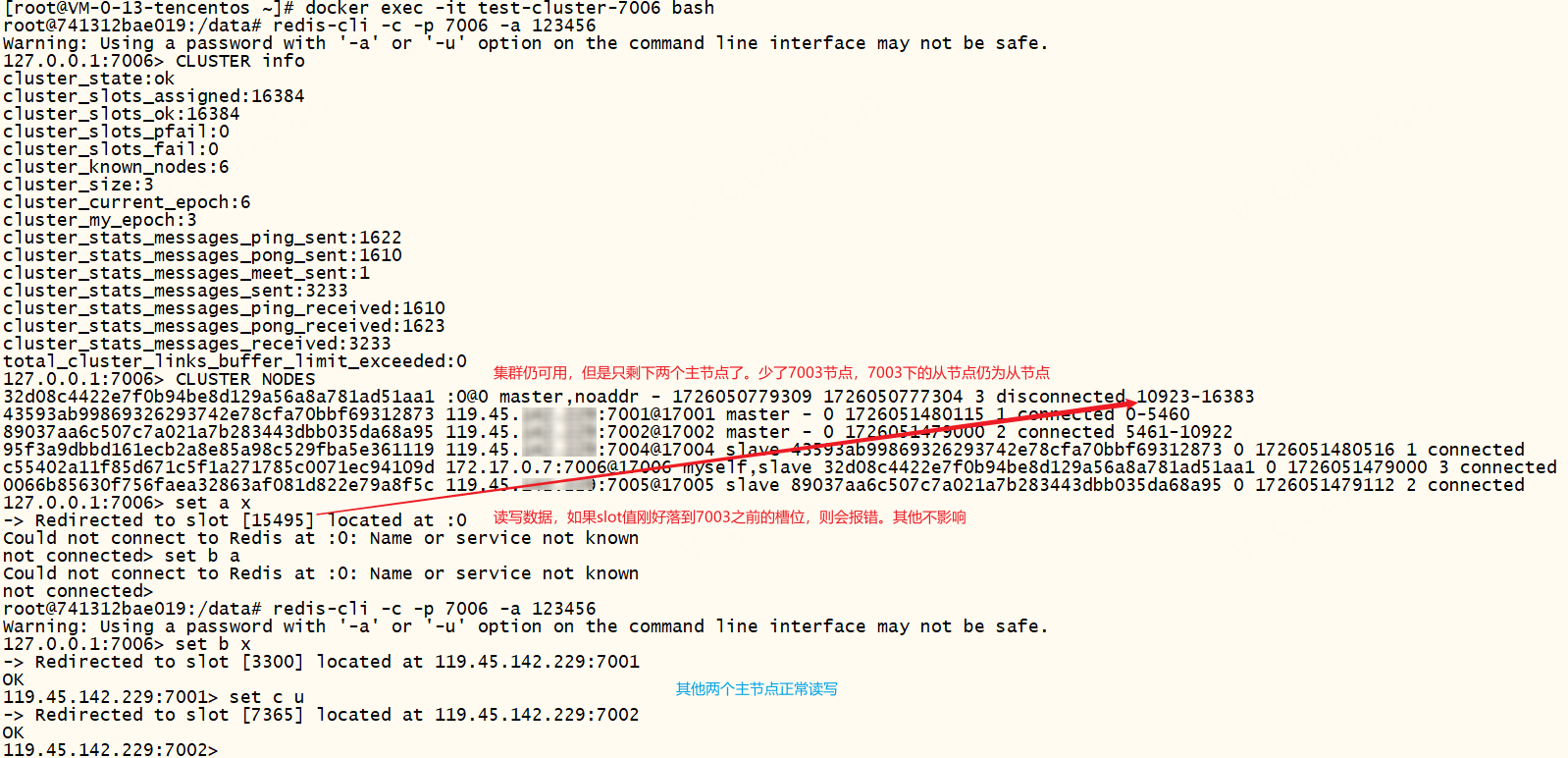
重置从节点后,集群状态显示fail不可用,该节点7006会变成主节点,但不可直接使用也不影响整个集群,其他节点正常读写数据。
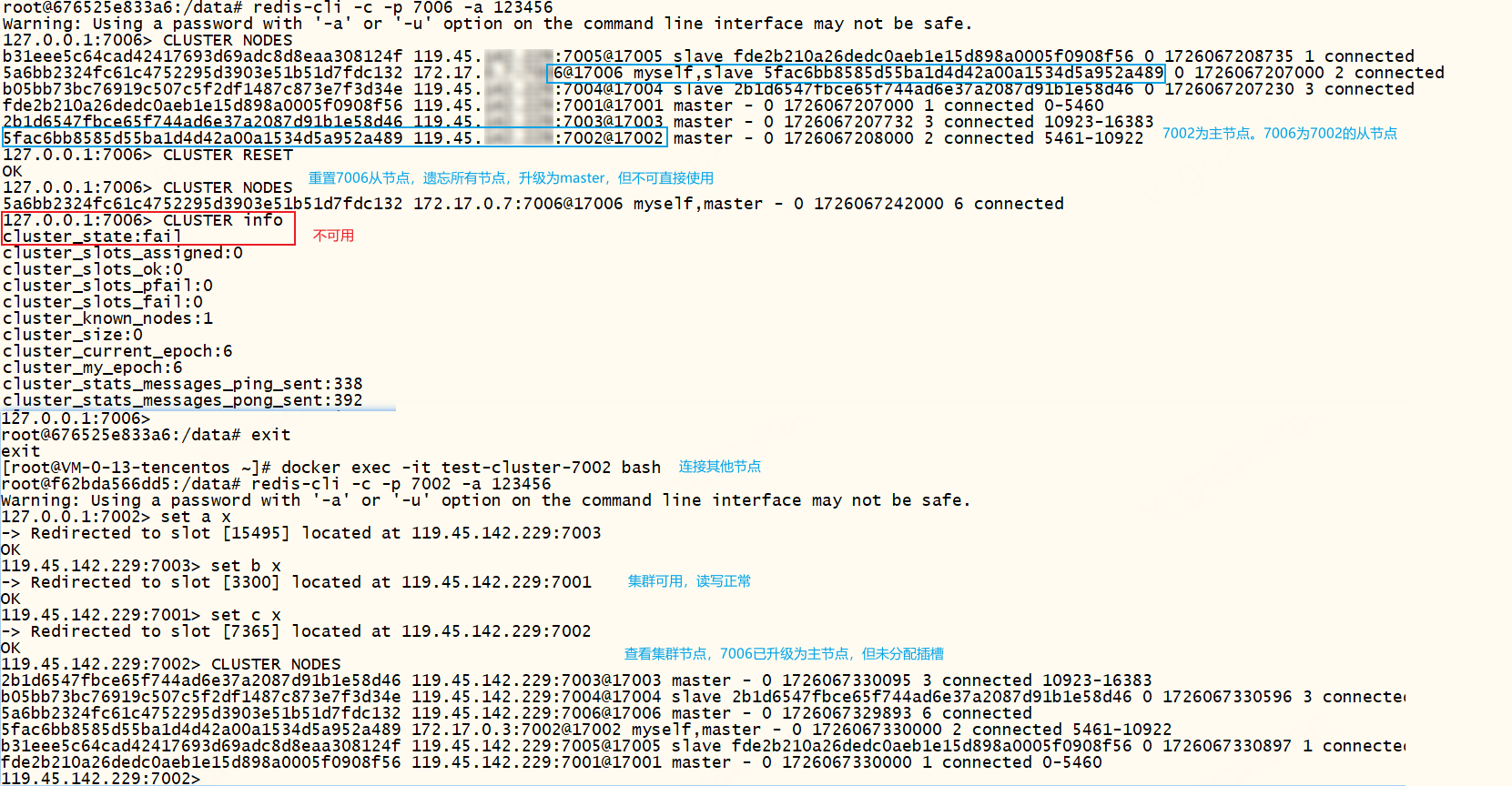
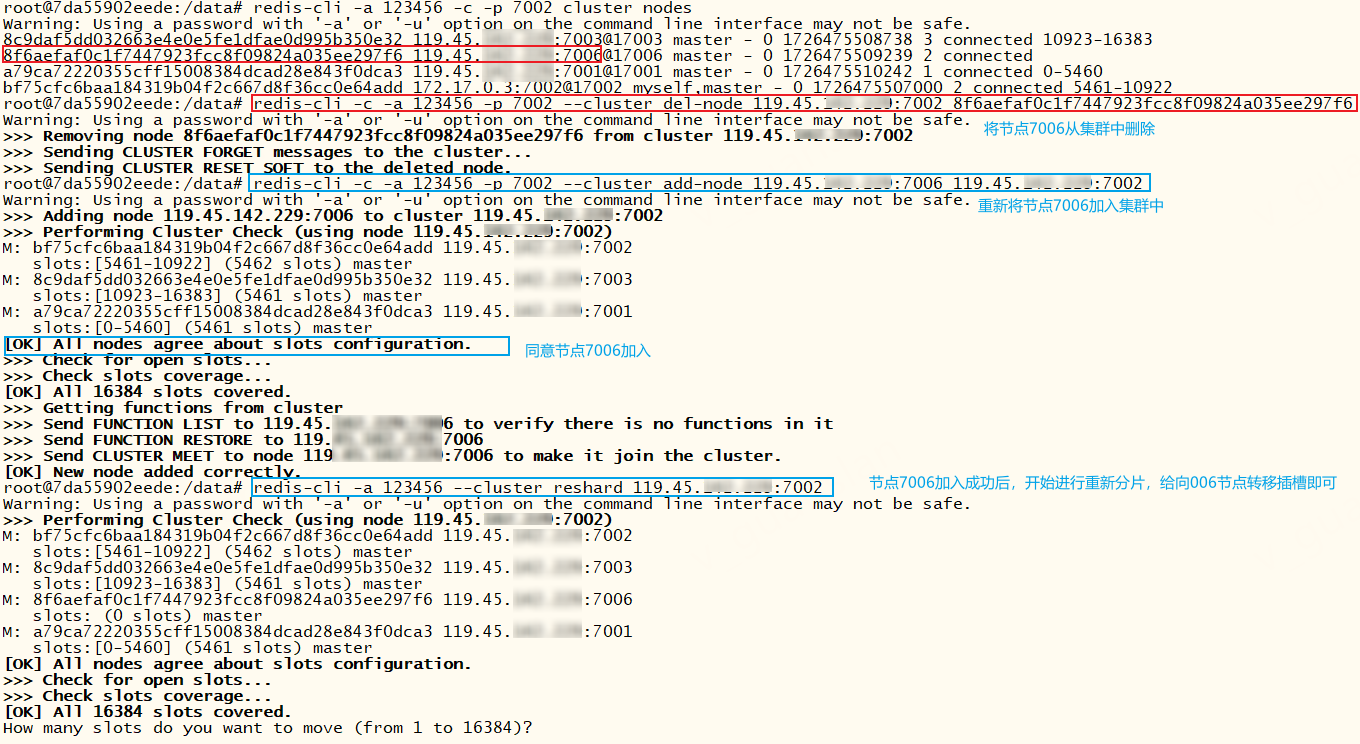
重置从节点7006后,我们想让该节点分配插槽存储数据应该怎么处理呢?此时使用redis-cli的check、fix、reshard、rebalance命令都会出现一个错误:[ERR] Nodes don't agree about configuration!。我们只需要手动将节点7006移出集群,再将7006加入集群即可
我们可以先观察一下节点状态、集群状态是否正常,如果正常则观察所有节点的配置文件(集群自动生成和维护那个文件)看看是否正常,不正常则手动修改该配置文件。如果两个问题都正常则连接另一个可用节点7002,执行redis-cli -c -a 123456 -p 7002 --cluster del-node 119.45.100.200:7002 7006节点Id移除7006节点,再执行redis-cli -c -a 123456 -p 7002 --cluster add-node 119.45.100.200:7006 119.45.100.200:7002添加7006节点到集群中,再执行reshard或rebalance就可以分配插槽了。这个场景下不要用cluster meet加入节点7006,也不要使用cluster ADDSLOTS分配插槽,否则报错:(error) ERR Slot xxx is already busy
故障转移
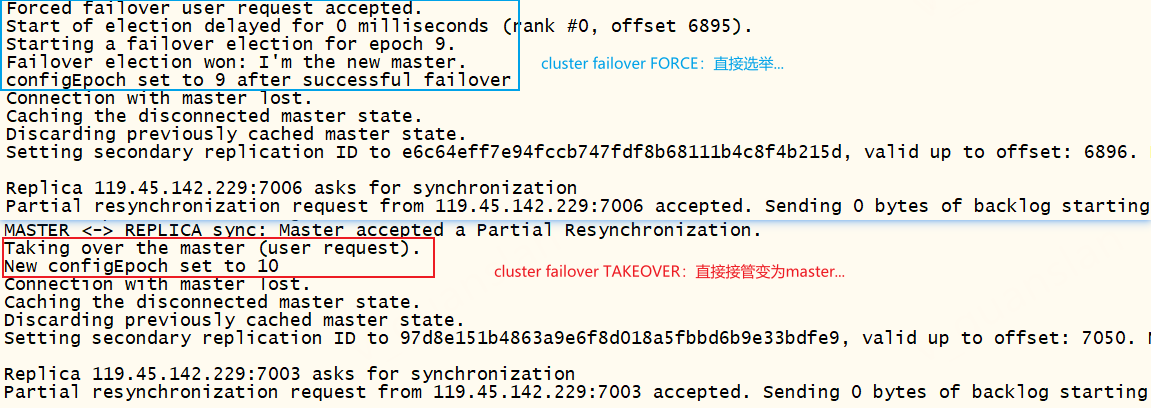
手动故障转移,在从节点上执行,将从节点升级为新的主节点,而原来的主节点降级为从节点。缺省参数FORCE:强制执行,TAKEOVER:更加强制执行
无法在主节点执行手动故障转移,否则报错:(ERR)You should send CLUSTER FAILOVER to a replica
xxxxxxxxxx# 手动故障转移CLUSTER FAILOVER# 正常(默认):从节点与主节点交互,复制偏移量、发起选举、统计选票、赢得选举、升级为主节点并更新配置# FORCE:直接发起选举、统计选票、赢得选举、升级为主节点并更新配置# TAKEOVER:直接升级为主节点并更新配置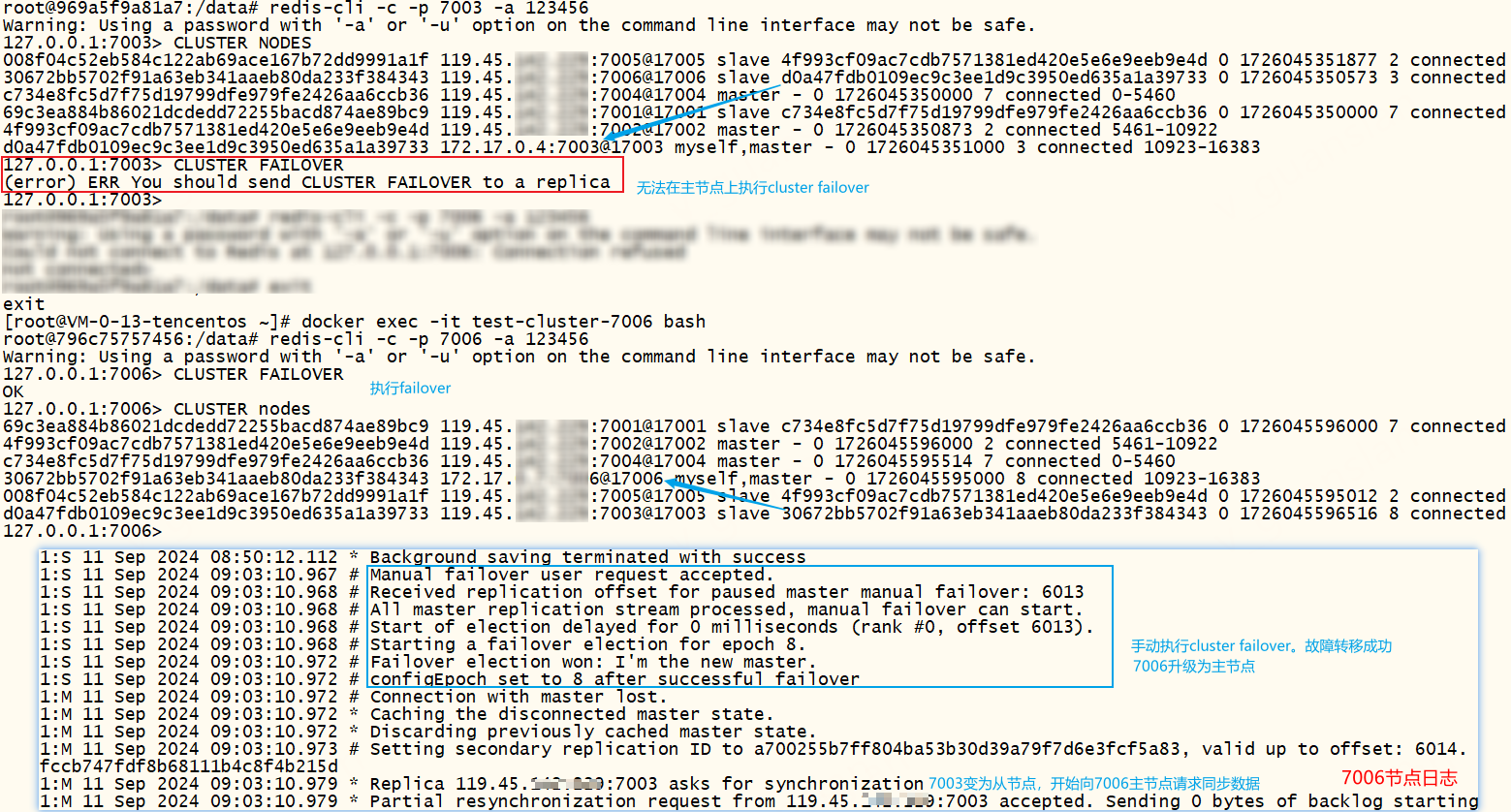
指定FORCE、TAKEOVER的故障转移流程,如下
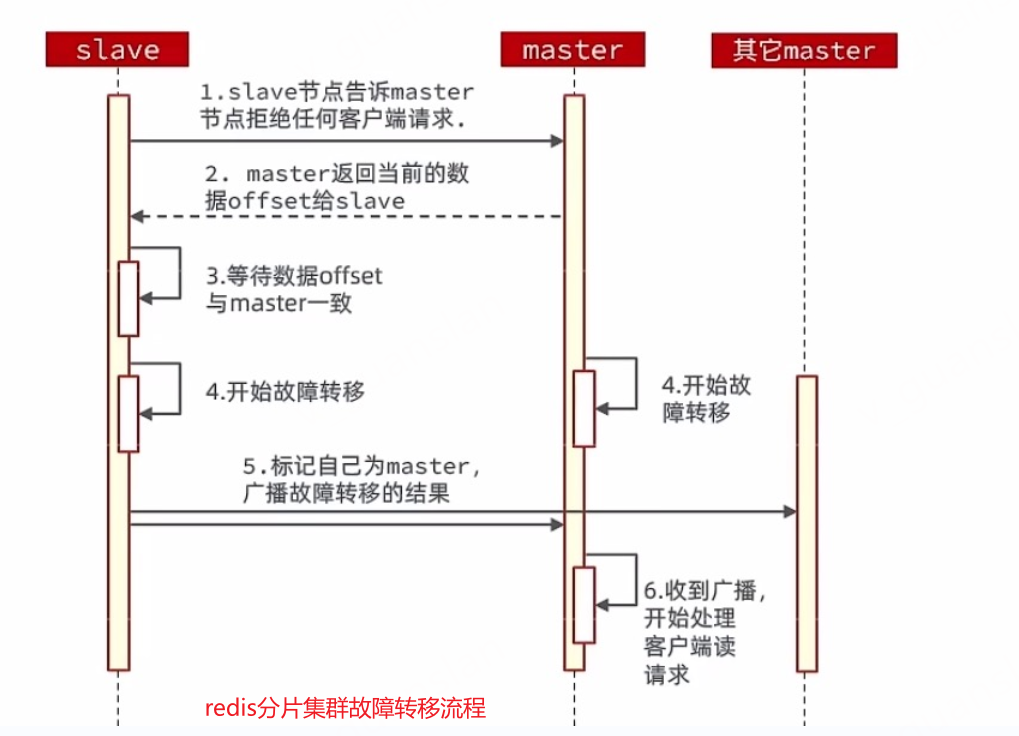
故障转移大致流程图如下。关于故障转移更多信息请参考:https://www.cnblogs.com/gqtcgq/p/7247041.html;https://developer.aliyun.com/article/638627
redis集群常见命令——redis-cli
使用redis-cli的相关命令查看和操作集群,不需要进入redis环境中执行
xxxxxxxxxx# redis-cli 集群帮助redis-cli --cluster help# 创建集群redis-cli --cluster create --cluster-replicas 0 119.45.100.200:7001 119.45.100.200:7002 119.45.100.200:7003 -a 123456# 连接集群 -c:cluster -a 指定密码,也可以不用-a,先连接再执行auth 123456命令。不指定-c可能会报错:(error) MOVED 3300 119.45.100.200:7001redis-cli -c -p 7001 -a 123456xxxxxxxxxx# 查看集群节点信息和状态 -a 指定密码redis-cli -c -a 123456 -p 7001 cluster nodes
xxxxxxxxxx# 查看集群插槽、节点信息,使用--cluster不能用-credis-cli -a 123456 --cluster info 119.45.100.200 7002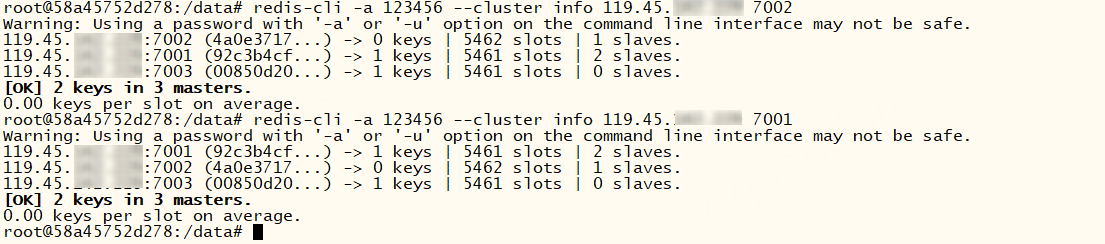
xxxxxxxxxx# 集群验证及监控 查看key分布情况、节点、插槽信息redis-cli -a 123456 --cluster check 119.45.100.200:7001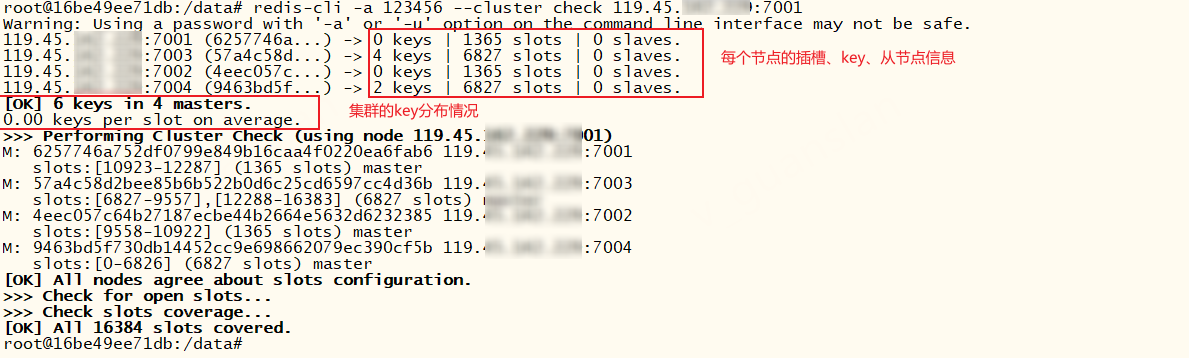
节点相关
删除节点,有数据不允许删除节点,否则报错:[ERR] Node 119.45.100.200:7004 is not empty! Reshard data away and try again.
添加节点,默认添加为主节点,但不会自动为新节点分配插槽
xxxxxxxxxx# 删除节点redis-cli -a 123456 --cluster del-node 119.45.100.200:7004 <nodeId># 添加节点 --cluster-slave 添加为从节点 --cluster-master-id <id> 指定主节点redis-cli -a 123456 --cluster add-node 119.45.100.200:7004 119.45.100.200:7005 --cluster-slave --cluster-master-id <master-nodeId># 添加节点格式:redis-cli -a 123456 --cluster add-node 新节点 任意一个可用旧节点 --cluster-slave --cluster-master-id 主节点Id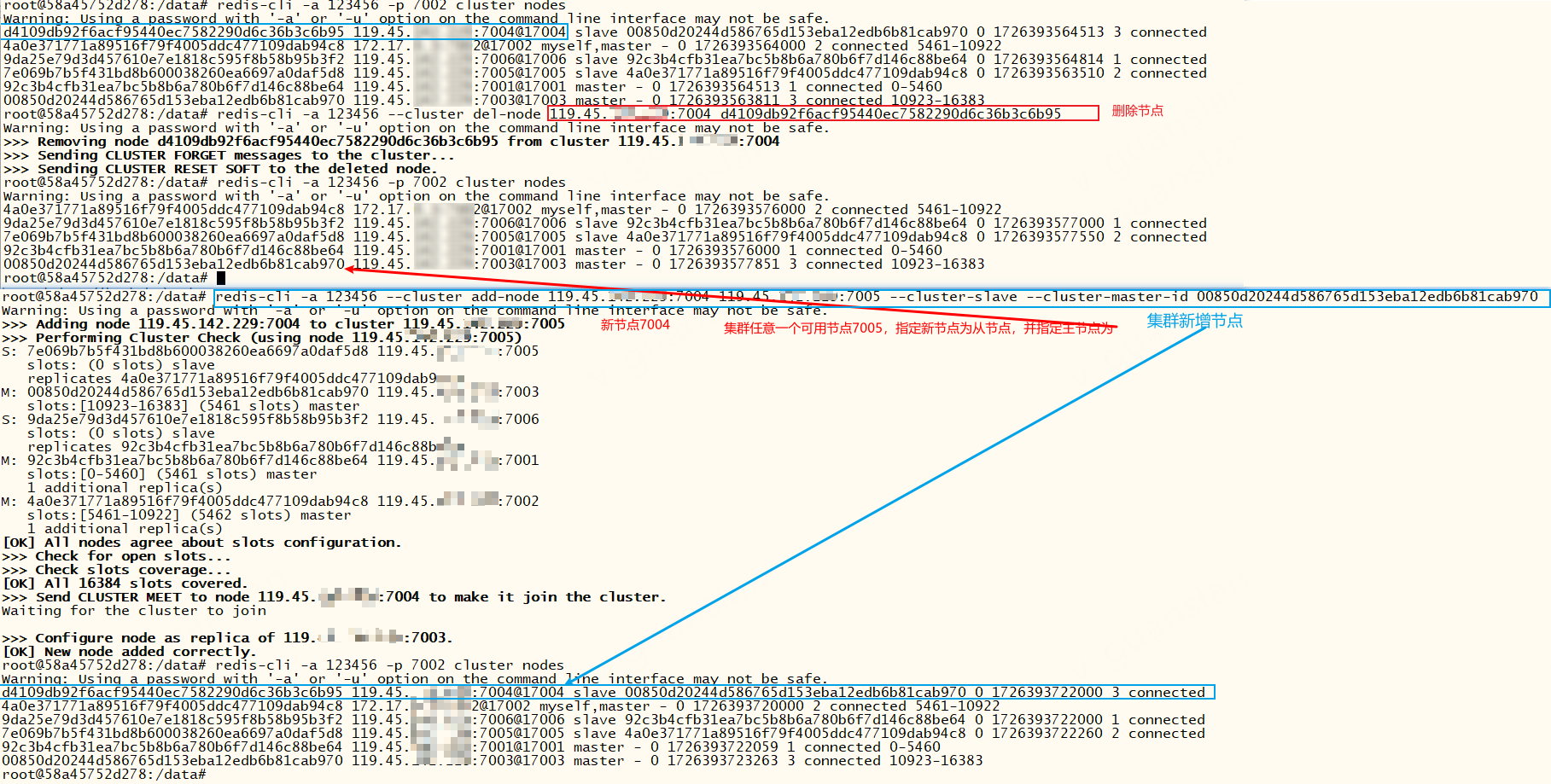
插槽相关
重新分配插槽,仅能重新分配插槽给主节点,否则(选择receiveId时)报错:The specified node (e65ee025151ea6c5f3a1049adfc25d1aa4cad77a) is not known or not a master, please retry.不管该节点有无数据,都可以进行重新分配插槽
xxxxxxxxxx# 重新分配插槽,迁移插槽、迁移数据到某个主节点。redis-cli -a 123456 --cluster reshard 119.45.100.200:7004# 执行后按图示操作。有两种方式——下图2.1或2.2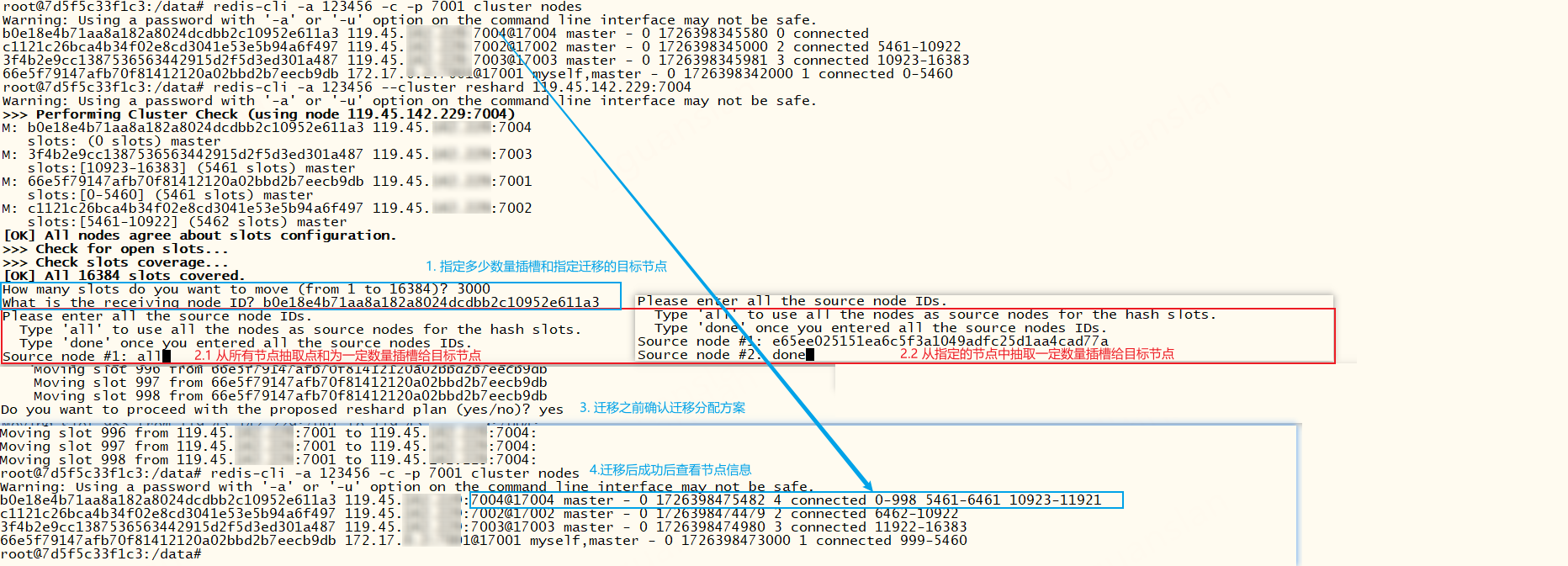
需要注意的是若将某个节点1的插槽全部迁移至另一个节点2,则节点1将会变成节点2的从节点。
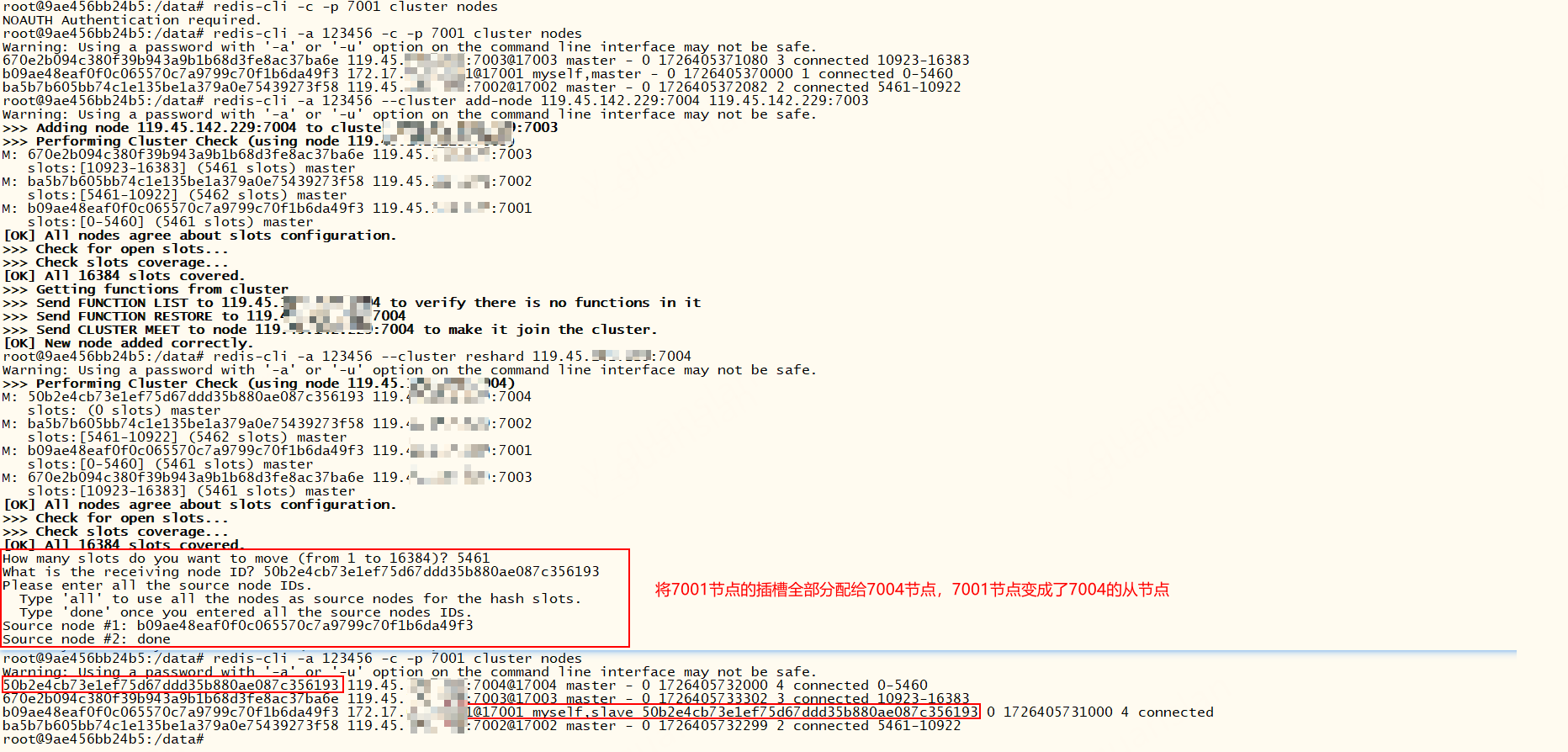
那过段时间我又想给这个节点1分配插槽呢?我们可以手动将节点1删除,再以主节点的身份加入集群,这样就可以重新分配插槽了。这里不要使用forget和reset命令删除从节点,反正我没成功过
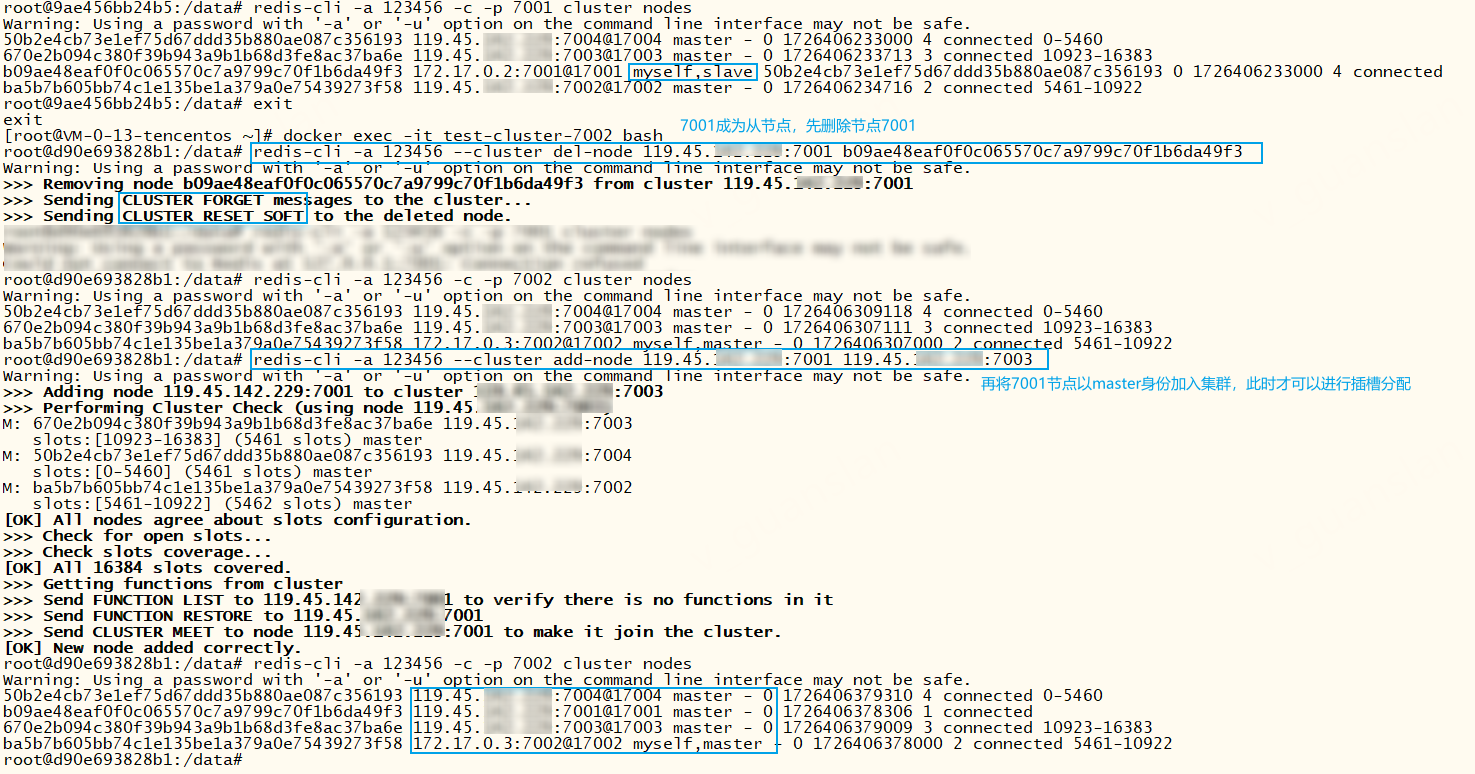
xxxxxxxxxx# 重新分配插槽达到一种平衡,默认规则,可连接任意一个节点redis-cli -a 123456 --cluster rebalance 119.45.100.200:7004# 重新分配插槽达到一种平衡, --cluster-use-empty-masters:给空节点分配点数据 redis-cli -a 123456 --cluster rebalance 119.45.100.200:7004 --cluster-use-empty-masters# 重新分配插槽达到一种平衡,指定权重,权重越大分配的插槽就越多 --cluster-weight <nodeId1=w1...nodeIdN=wN> 指定权重redis-cli -a 123456 --cluster rebalance 119.45.100.200:7004 --cluster-weight 6257746a752df0799e849b16caa4f0220ea6fab6=1 9463bd5f730db14452cc9e698662079ec390cf5b=5 57a4c58d2bee85b6b522b0d6c25cd6597cc4d36b=5 4eec057c64b27187ecbe44b2664e5632d6232385=1# --cluster-simulate:模拟运行,不会真正执行redis-cli -a 123456 --cluster rebalance 119.45.100.200:7004 --cluster-simulate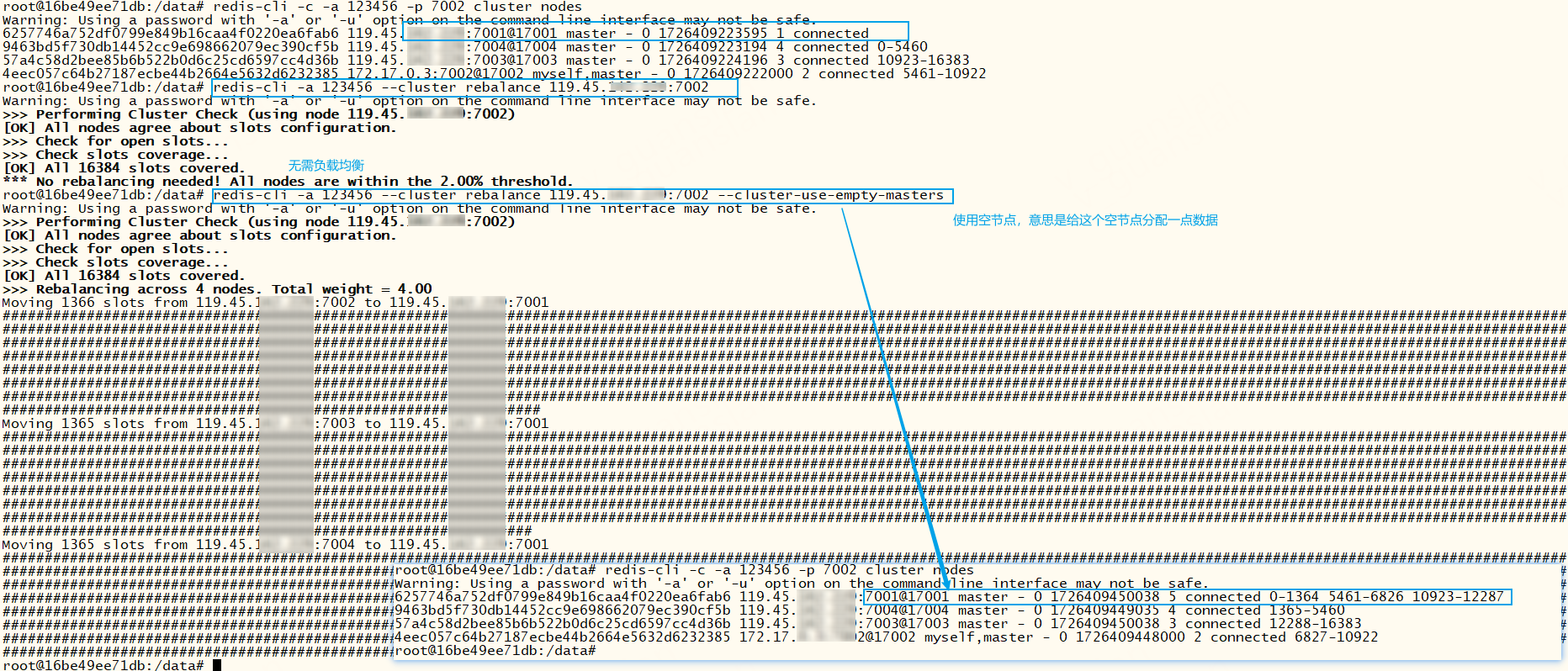

其他
xxxxxxxxxx# 修复集群# --cluster-search-multiple-owners:是否修复多个拥有者的槽位。当集群中的槽位在迁移过程中,出现意外时,使用fix可使用该参数。fix功能,redis内部在槽位的某些异常情况下会交互式的询问操作者是否同意它的修复策略,一般情况下,默认即可# --cluster-fix-with-unreachable-masters:是否修复不可达的主节点上的槽位。例如,集群中某个主节点就是坏掉了,也没有故障转移成功。此时如何恢复该主节点上的所有槽位呢,这时就可以使用该参数,会将处于该主节点上的所有槽位恢复到存活的主节点上(之前的数据会丢失,仅仅是恢复了槽位)redis-cli -a 123456 --cluster fix 119.45.100.200:7004 --cluster-search-multiple-owners# 在集群中执行redis命令 --cluster-only-masters:仅主节点执行,--cluster-only-replicas:仅从节点执行# 如每个都执行keys * 命令redis-cli -a 123456 --cluster call 119.45.100.200:7004 keys \*# 整个集群的cluster-node-timeout时间,单位毫秒redis-cli -a 123456 --cluster set-timeout 119.45.100.200:7004 # 导入数据 --cluster-replace 出现重复key时强行替换targetIP的key;--cluster-copy保留fromIP的数据,默认删除;建议使用redis-shake 迁移数据redis-cli -a 123456 --cluster import targetIP:6379 --cluster-from fromIP:6379 --cluster-replace --cluster-copy# 备份集群rdp文件redis-cli -a 123456 --cluster backup 119.45.100.200:7004 ./outputDirredis-cli的check, fix, reshard, del-node, set-timeout, info, rebalance, call, import, backup命令可以指定集群内的任意一个节点执行,可以的话建议使用不重要的节点执行这些命令
redis-cli可以和cluster的一些命令结合使用,如下
xxxxxxxxxx# 查看节点Idredis-cli -c -a 123456 -p 7002 cluster MYID# 查看a key的插槽redis-cli -c -a 123456 -p 7002 cluster KEYSLOT a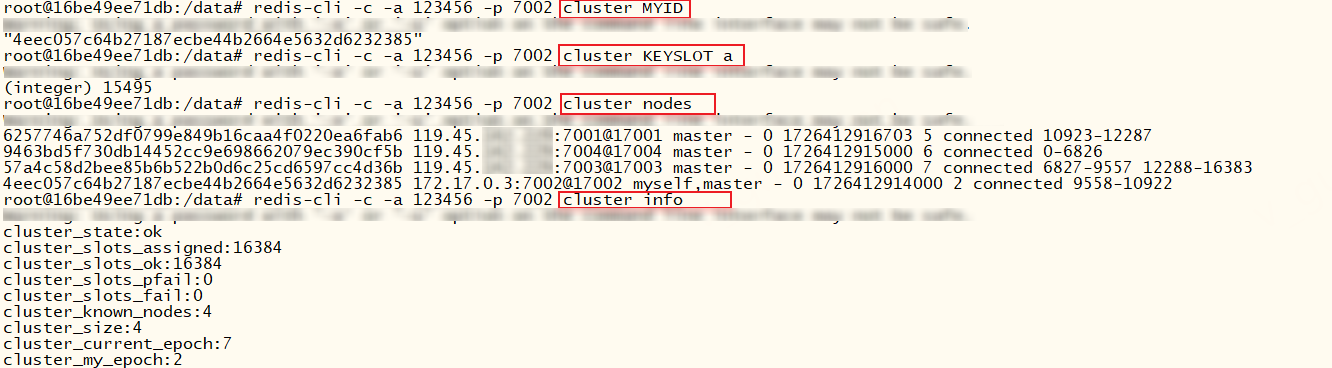
常见问题
使用docker启动redis,容器一直处于重启状态?
把daemonize yes后台运行改成daemonize no即可,亲测有效。修改docker--restart参数不管用
创建集群时,报错:[ERR] Node 119.45.100.200:7001 NOAUTH Authentication required?
redis-cli指定-a加上密码即可,redis-cli --cluster ... -a <password>

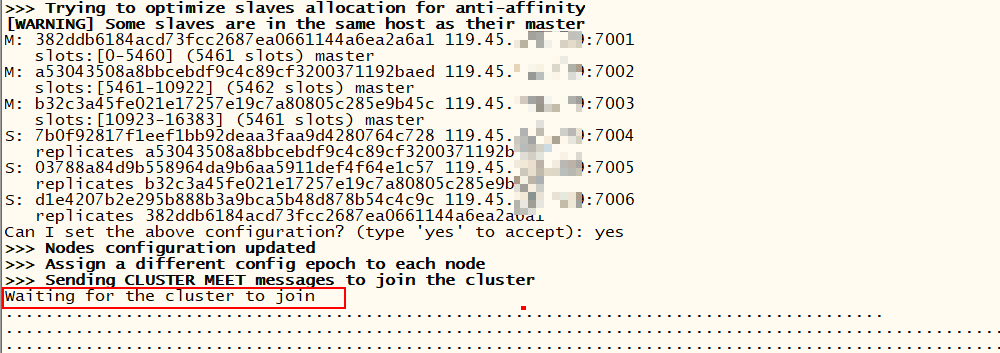
创建集群后一直处于Waiting for the cluster to join状态?
大多两个原因:集群的节点端口没有开放;集群的节点总线端口没有开放。集群总线端口用于集群之间互相通信
还有一个原因:同一个机器创建多个节点创建集群并且使用docker运行redis时,各个节点的配置文件的节点端口和总线端口不要一致(如都是6379、16379)否则可能连不上。搞了半天原来是这个原因
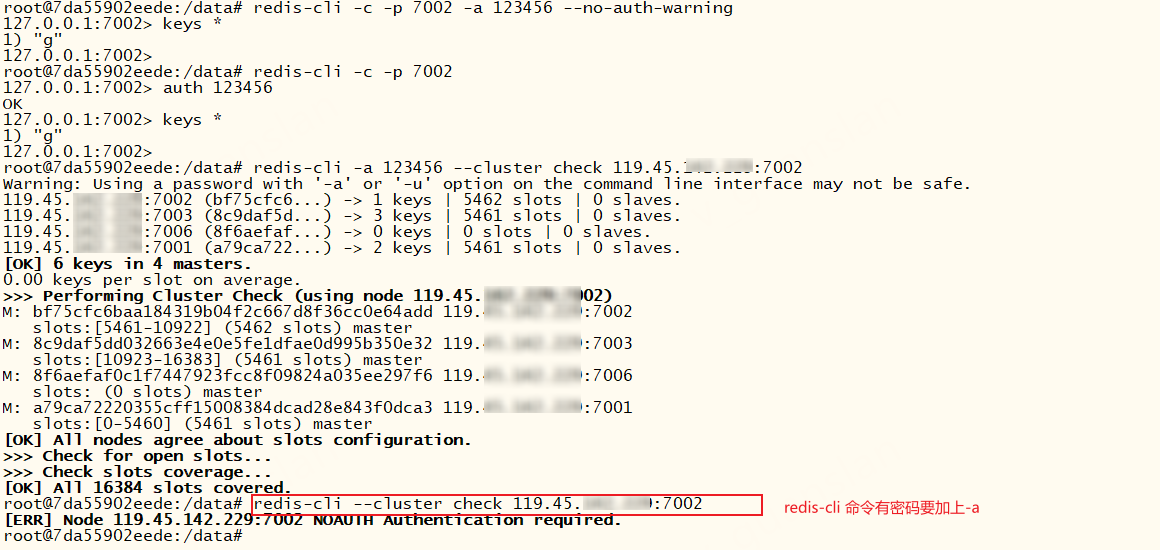
如何更安全的设置密码?使用 -a 提示:Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
若集群设置密码,我们可以使用--no-auth-warning参数取消不安全警告;也可以连接集群后,在redis内部使用auth password指定密码。但是有些redis-cli --cluster一定要加上-a指定密码才可以执行
如何让一批不同的key落到同一个节点上?
redis会根据key的有效部分自动计算插槽值,再找到对应的节点进行读写数据
- key包含“{}”且“{}”包含一个字符,则“{}”中的内容视为有效部分;
- key不包含“{}”,则整个key视为有效部分
这个有效部分有妙用,可以起到分组的作用,如我们想让一批key全部落到同一个节点上,我们只需要让这些key的有效部分相同,就可以让这些key有相同的插槽,从而达到让一批不同的key落到同一个节点上。如abc、{abc}name、{abc}info、{abc}age,这些key的有效部分相同——abc,所以都会落到同一个节点上
Redis集群是最多有16384个分片吗
不一定,但是多出来的分片可能分配不到槽位,因为默认情况下,最多只有16384个槽位。建议分片最多不超过1000个节点
为什么是16384个槽位
插槽不是越多越好,因为插槽位太多,会浪费带宽,压缩比高。
插槽使用位图这样的数据结构表示,16384(16k,个数基本够用)个slots,需要的是2kb大小,如果给定的slots数量更多了,则需要消耗更多的空间,假如65536 那么他就是(8kb) 心跳包是周期性通信的(非常频繁,吃网络带宽)
redis数据分片算法
主流的数据分片算法有:
- 哈希取模——hash(key) % n。实现简单,但是对扩缩容不友好
- 一致性哈希算法——65535个操作。扩缩容时只影响该节点附近的节点,影响节点较少
- 哈希槽分区算法——crc16(key)%16384。16384固定值,数据与插槽绑定而非机器,方便扩缩容,数据分布均匀
redis使用的是哈希槽分区算法,相较于一致性哈希算法,哈希槽分区算法数据分布更均匀,可手动调整插槽的分配情况
更多请参考:
Redis第10讲——Redis数据分片的三种算法_redis分片规则-CSDN博客
Redis集群,集群的概念 三种主流分片方式-阿里云开发者社区 (aliyun.com)
总结
redis支持很多功能,单实例redis并发读能力不行,我们可以搭建主从集群(Replica),实现读写分离,缓解读压力。但是主从集群无法自动故障恢复,又在主从集群的基础上添加哨兵机制实现健康检测,故障恢复。然而主从+哨兵仍有不足,我们还可以搭建分片集群缓解高并发写和存储大量数据。但是我们会发现学习成本也越来越大,尤其是redis分片集群,经常会冷不丁的就报错:ERR...完全出乎意料,简单总结一下吧
| redis | 优点 | 缺点 |
|---|---|---|
| 单实例 | 易,机器成本小,简单方便快捷 | 读写并发不足,读写没有高可用 |
| 主从模式 | 中,支持高并发读,读高可用 | 写并发不足,写没有高可用,机器成本较大,多个节点数据冗余 |
| 主从模式+哨兵机制 | 较难,支持高并发读,读写高可用 | 写并发不足,多个节点数据冗余,机器成本大,在主从的基础上增加机器部署哨兵,然而哨兵又不能存储数据(不过哨兵机器的性能配置可以降低) |
| 分片集群 | 难,支持高并发读写,读写高可用,存储大量数据 | 维护困难,机器成本大,扩缩容简单 |