redis整理02——如何更好的使用redis
>说明*sql数据库和redis相比较本地缓存和redis缓存相比较什么情况下使用redis不要滥用string类型谨慎使用集合操作巧用ZSET有序集合*multi、exec原子性*谨慎操作以下命令系统设置导致Redis延迟缓冲区大小*保证数据库和缓存的最终一致性先删除缓存再修改数据库#1先删除缓存再修改数据库#2推荐先修改数据库再删除缓存#1推荐先修改数据库再删除缓存#2强一致性其他方式*redis缓存异常缓存雪崩缓存击穿使用互斥锁逻辑过期缓存穿透请求过滤、使用黑名单缓存存入空值使用布隆过滤器缓存污染与淘汰策略*redis保证原子性*redis使用建议redis运维工具
说明
使用docker for window,使用版本:redis 7.0+、.net 6.0+、mysql 8.0+
离职了一个月,心血来潮,想整点好活,本来以为很简单的,结果前前后后搞了十来天(下午3点到下午6点)还是没搞完。内容太多了,留一点到后面吧,比如部署、实践之类的。这篇文章汇聚了很多知识点,方便查阅使用,但很多都是不精的,只记录了应该怎么做,很少记录为什么这么做,喜欢理论和研究源码的同学可以也可以参考文中附带的链接
测试项目:logerlink/RedisTest: .net core Redis 测试 (github.com)
redis帮助类:RedisTest/RedisTest.Share/RedisClient.cs at main · logerlink/RedisTest (github.com)
想成为redis高手吗?让糕手指引你的道路吧!
*sql数据库和redis相比较
redis相比sql数据库最显著的优势:
- 内存存储,数据读写快
- 低延迟,支持高并发(redis可处理每秒数万到数十万的请求,MySql通常可处理每秒数千到数万的请求)相差数十倍
- 可实现消息队列、分布式锁
当然也有其缺点:
- 原生不支持ACID,
- 持久化,可能会丢失数据
- 不支持复杂查询和数据分析
本地缓存和redis缓存相比较
MemoryCache本地缓存的特点:
- 单节点,仅当前应用程序可用,不支持访问其他应用程序的缓存
- 高性能,无需网络连接,比redis性能高
- 低数据,尽量存储小数据,避免占用太多内存导致内存溢出
x /// <summary> /// MemoryCache简单演示 /// </summary> public void CacheTest() { // using System.Runtime.Caching; var cache = MemoryCache.Default; // 根据key获取缓存,重启程序后首次执行都不会有值。 var cachedUser = cache.Get("key") as User; // 添加缓存 cache.Add("key", new User(), DateTime.Now.AddMinutes(1)); // 根据key获取缓存 cachedUser = cache.Get("key") as User; if (cachedUser == null) { // 没有缓存 } // 添加缓存newKey,若不存在key则添加返回null,若已存在不添加并返回缓存 var newValue = cache.AddOrGetExisting("newKey", new User(), null); // 获取缓存对象 var cacheItem = cache.GetCacheItem("newKey"); // 删除缓存key cache.Remove("newKey"); }redis缓存的特点:
- 分布式,redis作为一个中间件,不同的程序可以通过访问redis达到数据互通
- 多功能,redis提供了多种数据存储结构,多种部署方式,redis事务
- 可持久化。可以将缓存持久化到磁盘,重启计算机缓存仍可用
什么情况下使用redis
那什么情况下使用redis呢?一般缓存什么数据(什么场景下使用)?
redis一般用来缓存读写频繁的数据,还可以实现分布式锁、分布式sessionId、消息队列、发布/订阅
使用场景:数据存储缓解数据库压力、排行榜(SORTED SET)、访问计数器(INCR、DECR) 、电商分类树、人员组织结构树、权限树、评论内容、秒杀库存管理、抽奖、限流速率限制、数据自动过期(expire)、地理位置(GEO)、时间序列等
尽量存储可直接使用的数据,不要缓存原始数据,不然每次使用还要取出来处理一大堆逻辑才可使用
更多请查阅:项目中使用过Redis吗?
不要滥用string类型
不要滥用string类型,不要把什么类型都塞进string中,可以根据数据类型使用不同的存储类型。
string不适于存储小数据(如Id),由于string类型元数据偏大,所以存储小数据时消耗的内存空间也会更多。如某个ID仅占用10字节,存入后可能要占用50字节,多占用的40字节(50-10)就是string元数据占用的内存空间。
谨慎使用集合操作
数据量大时,尽量不要使用集合(SET、Sorted Set)的交集(SINTER、ZINTER)、并集(SUNION、ZUNION)、差集(SDIFF、ZDIFF)操作,这些操作复杂度较高,可能会执行很久。建议在从库执行这些操作或者在客户端使用代码查询
巧用ZSET有序集合
最新列表、排行榜建议使用Sorted Set有序集合实现
还可以利用有序集合的分数score来存储值。不过要注意score一致的情况,score一致不会被替换掉,如下,每分钟记录一次温度情况
xxxxxxxxxxzadd 20240101 080808 37.5zadd 20240101 080809 37.1zadd 20240101 080810 40.1zadd 20240101 080811 41.5# 查看每分钟对应的分数zrange 20240101 0 10 WITHSCORES# 插入相同scorezadd 20240101 080808 39.5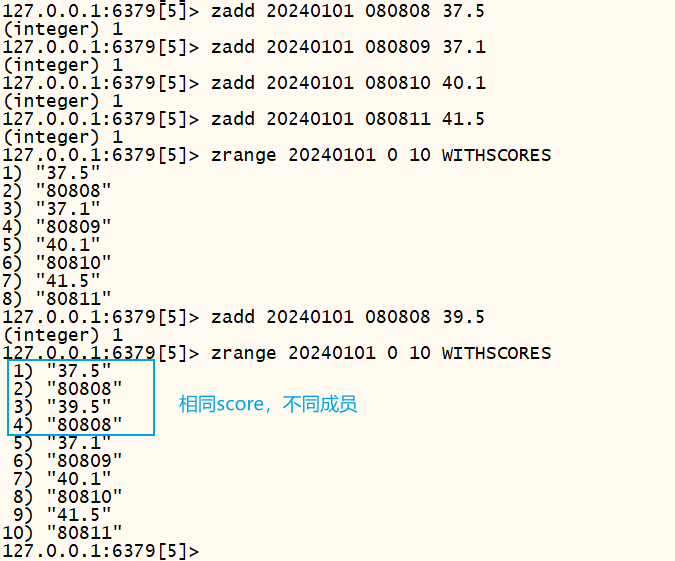
*multi、exec原子性
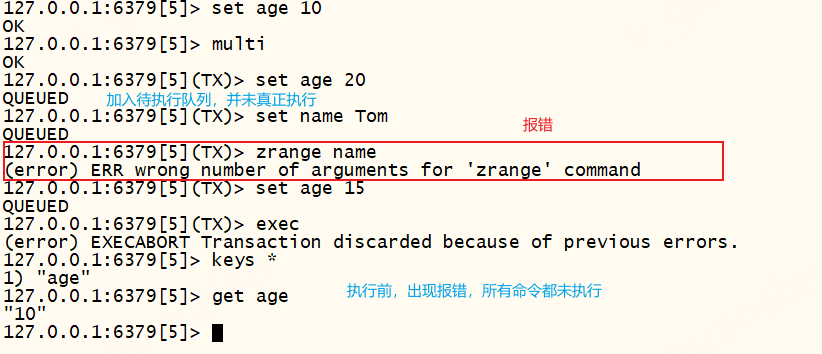
multi、exec一般情况下可以保证多条命令的原子性。开启multi之后,所有的命令都会加入待执行队列,直到遇到exec,若加入队列时发生报错(拼写错误、命令参数错误、网络错误),那么整个队列的命令都不会执行
执行中报错不保证原子性。如果开启了AOF日志,执行中报错时可以先将实例暂停、删除AOF日志(手动回滚已执行的命令)再重启实例
*谨慎操作以下命令
数据量大时慎用以下操作:HGETALL、SMEMBERS、KEYS *、DEL bigKey、集合的聚合操作、FLUSHDB、FLUSHALL、AOF日志同步写、从库加载RDB文件
由于数据量大,这些命令可能会阻塞redis线程,导致后续命令无法及时响应,若真的有需求应使用其他命令替代
| 容易阻塞命令 | 命令含义。特点:简单暴力方便,数据量少时可用 | 替换操作、解决方案 |
|---|---|---|
| HGETALL | 查看hash的全部键值HGETALL myhash | HSCAN myhash 0 MATCH * COUNT 20返回cursor和数据,cursor用于下次分页使用 超过1300 HSCAN命令才生效,不然全部返回 |
| SMEMBERS | 查看SET集合全部成员SMEMBERS myset | SSCAN myset 0 MATCH * COUNT 5返回cursor和数据,cursor用于下次分页使用 |
| KEYS * | 查看keyKEYS *生产环境建议禁用 | SCAN 0 MATCH * COUNT 1返回cursor和数据,cursor用于下次分页使用,SCAN 还可以指定Type |
| DEL 大key | 删除keydel myset如下,某个key存在500w条数据,删除该key的同时执行其他命令,由于单线程阻塞,其他命令只有等待删除操作完成后才开始执行,从而导致该命令"执行慢" 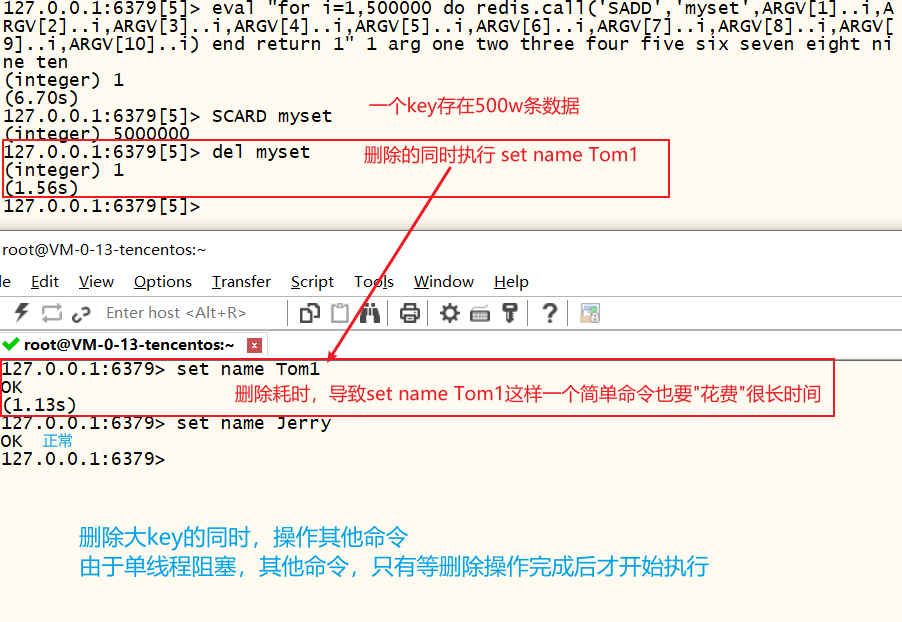 | redis4.0之前,应该多次使用scan查询小部分数据后,再删除查询结果。这样删除虽然会更耗时,更麻烦,但是每个命令都会执行得很快,不会阻塞其他命令,影响其他业务。如下:SSCAN myset 0 MATCH * COUNT 5 SREM myset item1 item2 item3 item4 item5 redis4.0之后,可以使用 UNLINK myset删除key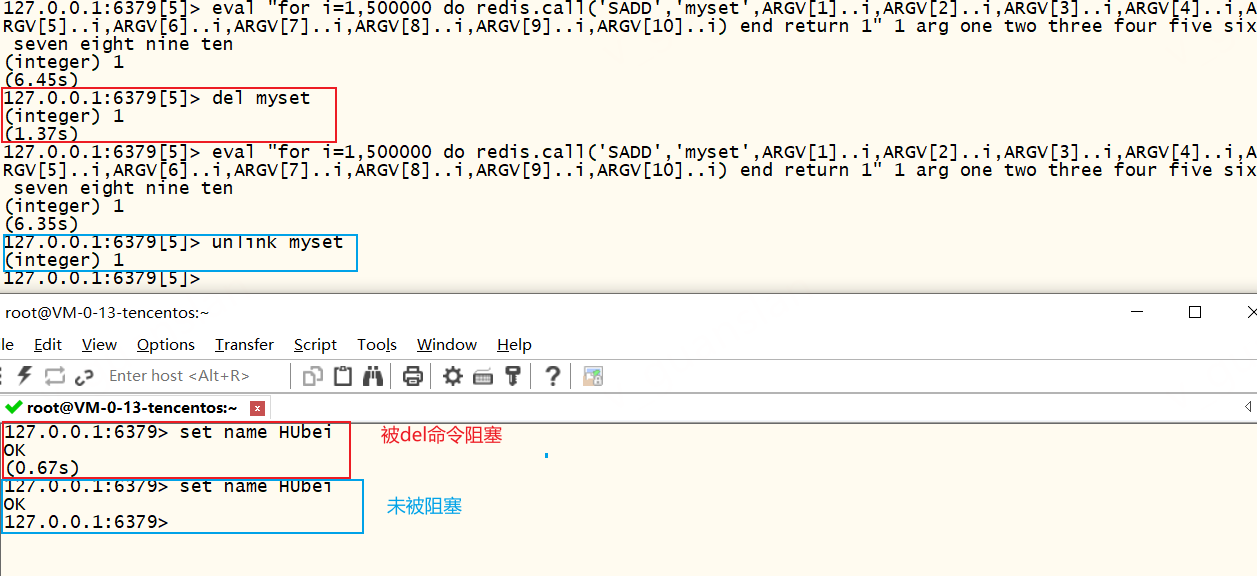 |
| 集合的聚合操作 | 交集(SINTER、ZINTER) 并集(SUNION、ZUNION) 差集(SDIFF、ZDIFF) | 在从库中执行或者使用SSCAN、ZSCAN查询数据后,在客户端使用代码操作集合 |
| FLUSHDB | 清空数据库 生产环境建议禁用 | redis4.0之前,可以使用scan慢慢删除key,对于大key还要使用对应的scan慢慢删除数据,或者选择一个夜深人静系统业务量少的时候操作 redis4.0之后,可以使用 FLUSHDB ASYNC 由子线程执行清空操作不阻塞其他命令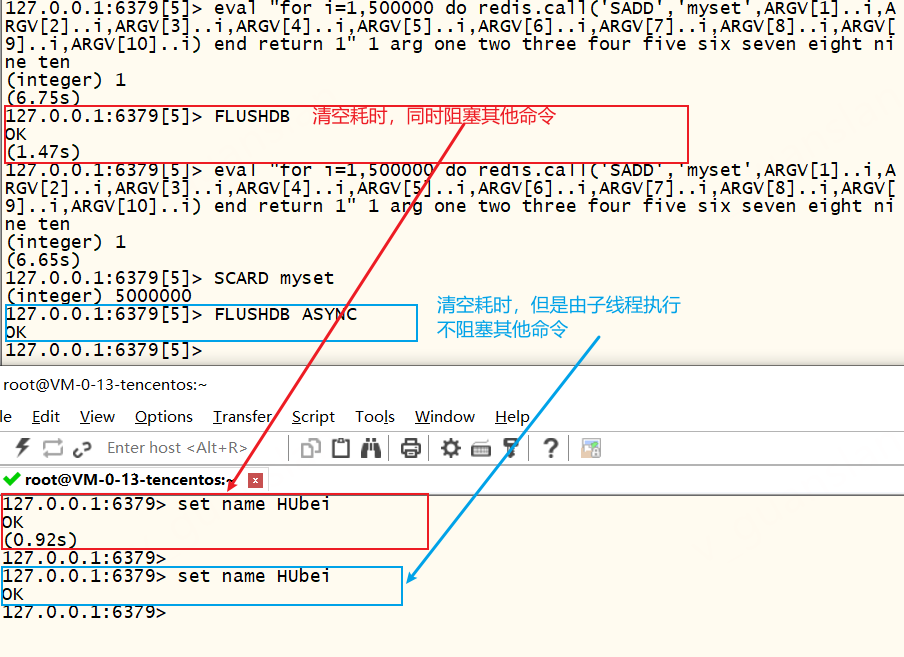 |
| FLUSHALL | 清空所有数据库 生产环境建议禁用 | redis4.0之前,可以使用scan慢慢删除key,对于大key还要使用对应的scan慢慢删除数据,或者选择一个夜深人静系统业务量少的时候操作 redis4.0之后,可以使用 FLUSHALL ASYNC 由子线程执行清空操作不阻塞其他命令 |
| save | 主动保存RDB文件 | 应该使用 BGSAVE异步保存RDB文件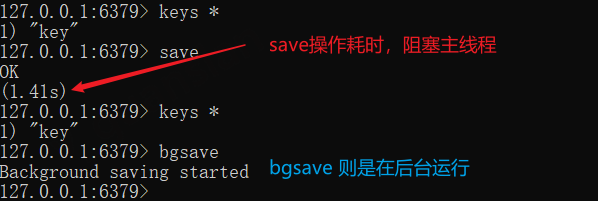 |
以下命令可用于生成测试数据
xxxxxxxxxx# 批量生成1300条hash记录,hash数目大于等于1300条,HSCAN命令才起作用eval "for i=1,130 do redis.call('hset','myhash',ARGV[1]..i,i,ARGV[2]..i,i,ARGV[3]..i,i,ARGV[4]..i,i,ARGV[5]..i,i,ARGV[6]..i,i,ARGV[7]..i,i,ARGV[8]..i,i,ARGV[9]..i,i,ARGV[10]..i,i) end return 1" 1 arg one two three four five six seven eight nine ten# 批量生成20条hash记录eval "for i=1,20 do redis.call('SADD','myset',ARGV[1]..i,ARGV[2]..i,ARGV[3]..i,ARGV[4]..i,ARGV[5]..i,ARGV[6]..i,ARGV[7]..i,ARGV[8]..i,ARGV[9]..i,ARGV[10]..i) end return 1" 1 arg one two three four five six seven eight nine ten# 批量生成一堆keyeval "for i=1,20 do redis.call('SET',ARGV[1]..i,ARGV[1]..i) redis.call('SET',ARGV[2]..i,ARGV[2]..i) end return 1" 1 arg one two# 制造大key,注意循环数量别把服务器卡死了eval "for i=1,500000 do redis.call('SADD','myset',ARGV[1]..i,ARGV[2]..i,ARGV[3]..i,ARGV[4]..i,ARGV[5]..i,ARGV[6]..i,ARGV[7]..i,ARGV[8]..i,ARGV[9]..i,ARGV[10]..i) end return 1" 1 arg one two three four five six seven eight nine ten系统设置导致Redis延迟
这些系统设置不合理,也有可能会导致Redis延迟
| 系统设置 | 替换操作、解决方案 | |
|---|---|---|
| AOF日志同步写 | 修改AOF配置,从库处理(未实操) 若需要提升性能,并且允许部分数据丢失,可以将配置项no-appendfsync-on-rewrite设置为yes,避免AOF重写和fsync竞争磁盘IO资源,导致Redis延迟增加 若需要提升性能又要提高数据可靠性,建议使用高速固态盘作为AOF日志写入盘 | |
| 从库加载RDB文件 | 修改配置,限制主库的RDB文件的大小为2-4G,避免主从复制时从库长时间加载(未实操) | |
| 内存不足 | 加大计算机内存,预留足够内存运行redis,避免swap内存。数据量过大时,建议使用集群 | |
| 是否开启大页机制 | 若开启,关闭内存透明大页机制 | |
| CPU架构影响 | 使用多核CPU可以给redis实例绑定物理核。使用NUMA架构,注意把Redis实例和网络中断处理程序运行在同一个CPU Socket上 | |
| 过期的key自动删除 | 避免使用同一批过期时间,还可以在目标过期时间上随机添加一部分过期时间,避免缓存集中过期 |
缓冲区大小
参考:Redis 输入输出缓冲区解析_redis output buffer-CSDN博客
缓冲区是用来避免请求丢失或数据丢失,可分为输入缓冲区、输出缓冲区。
我们应该控制输入输出的数据量,避免缓冲区大小溢出:
| redis缓冲区 | 如何查看 | 溢出后的后果 | 如何避免 |
|---|---|---|---|
| 输入缓冲区 | client list 关注qbuf(已使用缓冲区大小)、qbuf-free(未使用缓冲区大小)指标 | 可能会导致Redis客户端断开连接或Redis服务器崩溃,影响业务程序 | 避免一次性写入大key,可以分批写入 无法调整输入缓冲区大小 |
| 输出缓冲区 | 查看方式:redis-cli config get client-output-buffer-limit | 可能会导致Redis客户端断开连接或Redis服务器崩溃,影响业务程序 | 1.避免一次性查询大key,可以使用scan分批查询 2.不要持续使用MONITOR命令 3.合理设置缓冲区大小 给普通客户端设置缓冲区: client-output-buffer-limit normal 0 0 0 normal 0 0 0 分别表示:普通客户端、缓冲区大小限制、缓冲区持续写入量限制、缓冲区持续写入时间限制。(0 0 0表示不限制,建议这样设置,默认也是这样设置) 给订阅客户端设置缓冲区: client-output-buffer-limit pubsub 8mb 6mb 60 |
*保证数据库和缓存的最终一致性
重点聊聊如何保证数据库和缓存数据的最终一致性。
首先,我们先看一下如何使用缓存,正常一个请求会先查询redis缓存看看是否有缓存,若有缓存则读取缓存并返回数据。若没有缓存,则查询数据库,将查询结果存到redis中,再将结果返回。草图如下图
xxxxxxxxxx// c# 伪代码var cacheData = GetRedisData(key); // 读取缓存if (cacheData != null) return cacheData;var sqlData = GetSqlData(query); // 读取数据库SetRedisData(key, sqlData);return sqlData;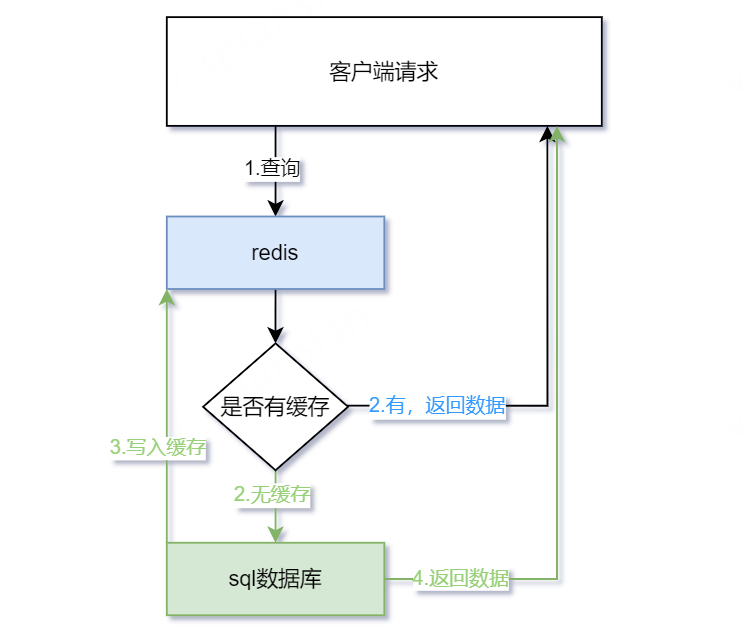
此时,如果修改数据(库),那么缓存应该怎么处理呢?我们可以同时修改缓存或者直接删除缓存。建议直接删除缓存,由下一个查询请求读取数据并将数据存储到redis中。那么我们会有两种情况:先删除缓存再修改数据库、先修改数据库再删除缓存(推荐)。
由于数据库和redis不属于同一个系统,无法使用同一个事务确保两个系统的原子性,而且无论两者做到同时操作成功或失败,总会有一个时间差,导致并发读写的时候可能就会出现缓存不一致的问题。为了满足并发性能,我们只能尽可能避免,无法做到绝对。
假设,原值Age=20,现在要修改为Age=10,我们往下看看应该怎么处理吧
先删除缓存再修改数据库#1
假设两步操作均成功,岂不是万事大吉,无需处理?非也,在并发场景下还是会出现问题的。如下图
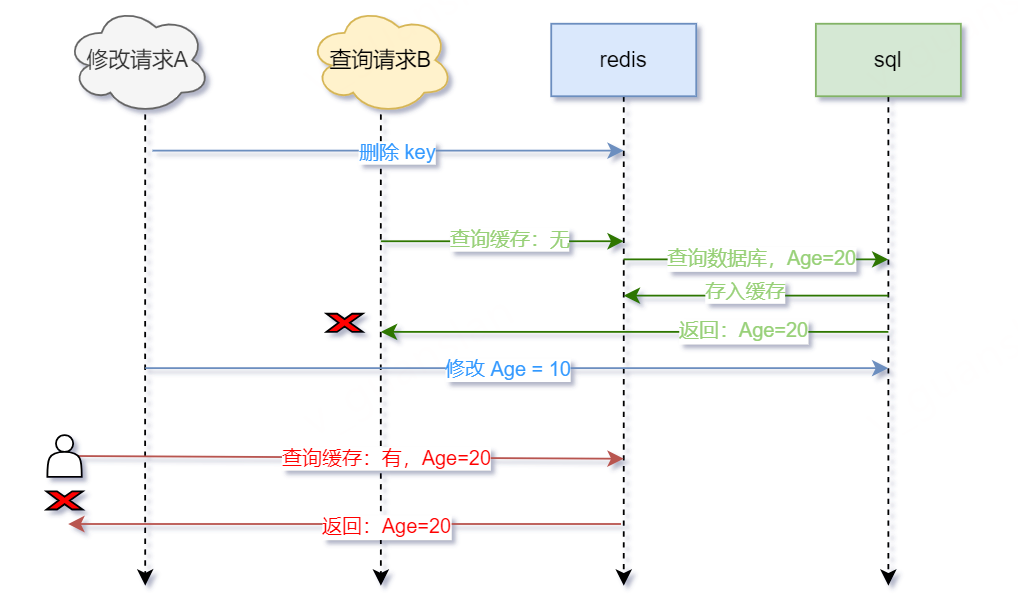
- 请求A用于修改Age,先删除缓存,删除成功
- 此时查询请求B开始请求,先查询缓存——没有缓存,再查询数据库——数据库未修改Age=20,存入缓存,返回Age=20
- 请求A接着修改数据库,修改成功,此时Age=10
- 后续其他查询请求,先查询缓存——有缓存,Age=20,返回Age=20
- 如此,便导致数据库和缓存的数据不一致——数据库Age=10,而缓存Age=20。无其它操作下,只有等缓存过期才会重新请求数据库,再设置缓存Age=10
那是不是不能用这种方式处理一致性呢?还是可以的,我们只需要加上一小步——修改数据库后再延迟删除缓存,这便是大家常说的"延迟双删",看图
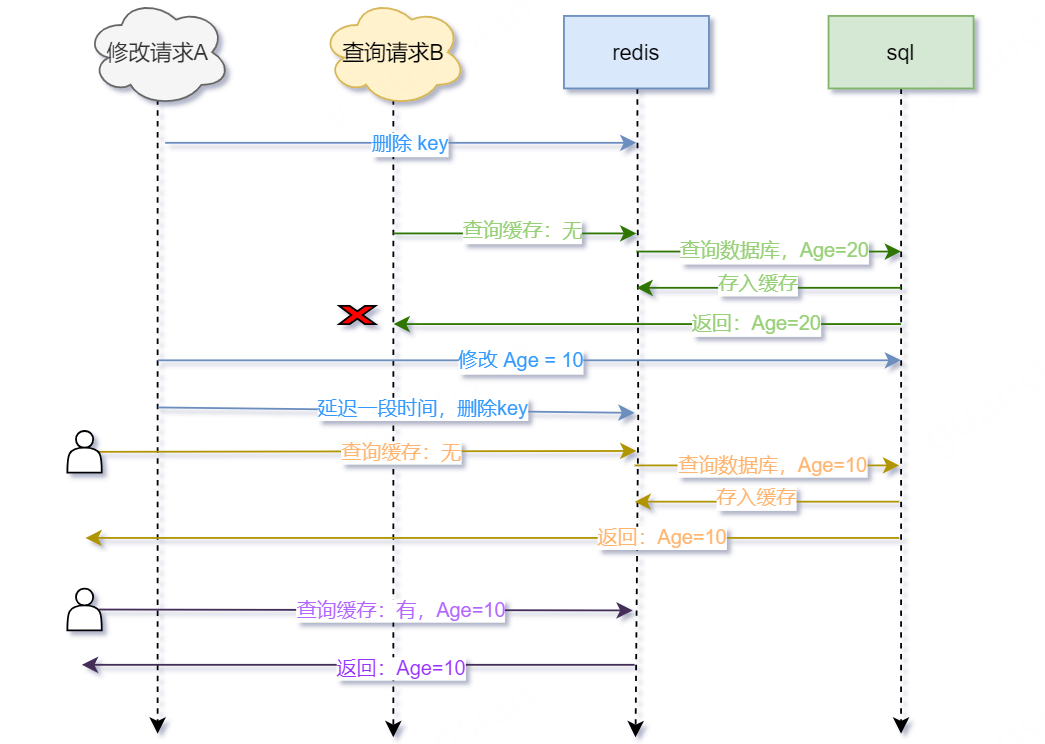
123步不变,直接看第4步
- 修改数据库成功后,延迟等待一段时间,再次删除缓存(不管是否存在key)
- 后续其他查询请求,先查询缓存——没有缓存,再查询数据库——数据库已修改Age=10,存入缓存,返回Age=10
- 后续其他查询请求,先查询缓存——有缓存,Age=10,返回Age=10
- 如此,数据库和缓存的数据一致——Age=10
先删除缓存再修改数据库#2
那假如两步操作其中一步失败呢?会发生什么情况
假设第一步删除缓存失败,此时数据库和缓存均未受影响,Age=20,不符合业务需求
假设第一步删除缓存成功,而修改数据库失败,我们先看看会发生什么情况,看图
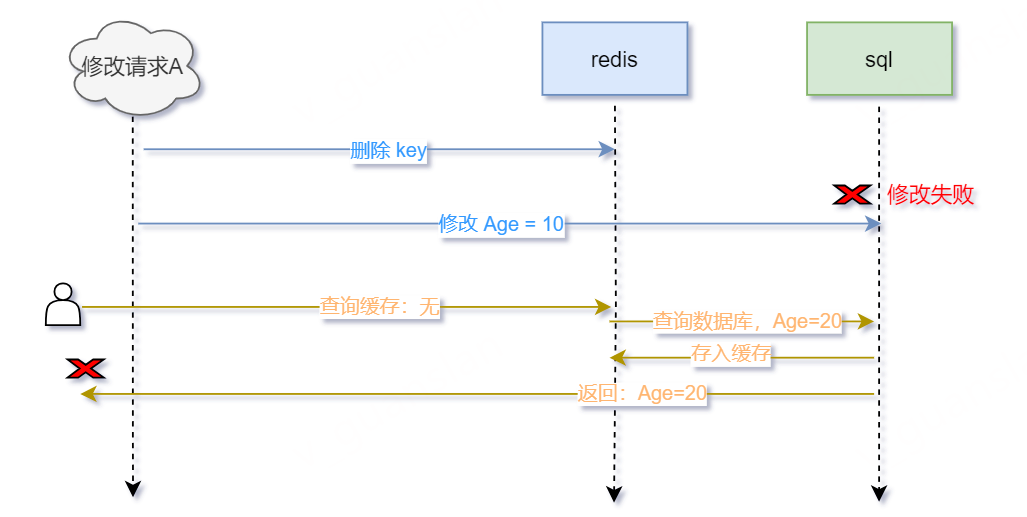
- 请求A用于修改Age,先删除缓存,删除成功
- 接着修改数据库,修改失败,此时Age=20
- 后续其他查询请求,先查询缓存——没有缓存,再查询数据库——数据库未修改成功Age=20,存入缓存,返回Age=20
- 看似两者的数据一致,但不符合业务啊,我们要求的是修改Age=10
那面对这种情况应该怎么处理呢?修改数据库失败大多两种情况:人为可控的——代码逻辑错误,不可控的——链接断开、请求数据库超时。对于人为可控的情况,我们需要修改调整优化逻辑,对于不可控的,我们用得最多的便是重试了。
那我们能不能让程序自动重试呢?当然可以,这也是我们比较推荐的方案,不过我们需要引入消息队列帮助我们完成重试,看图
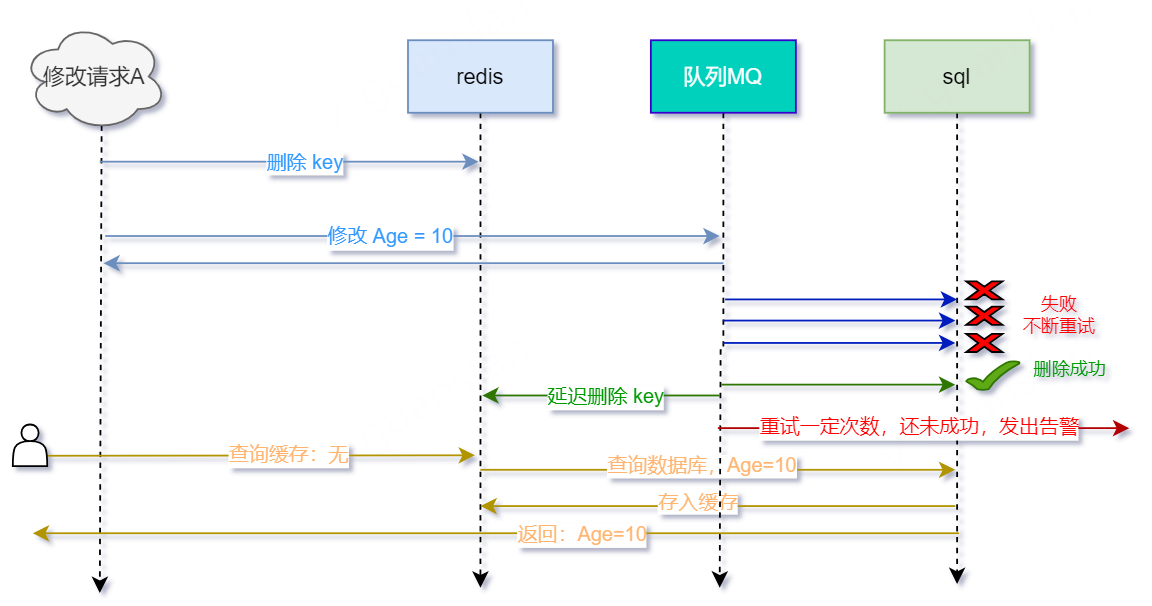
- 请求A用于修改Age,先删除缓存,删除成功
- 请求A接着通过MQ发布"修改数据库"事件,由程序订阅
- 程序订阅"修改修改数据库"事件,修改数据库。若成功,则不再触发,若失败,则过段时间由MQ自动触发达到重试效果,直至成功。建议设置最大重试次数。若多次重试仍不成功,则MQ发出告警通知管理员
- 因为在修改数据库时,可能有查询请求进来。此时会先查询缓存——没有缓存,再查询数据库——数据库未修改成功Age=20,存入缓存。所以修改数据库成功后,仍旧需要延迟删除key,避免缓存脏数据,保证数据库和缓存一致
- 后续其他查询请求,先查询缓存——没有缓存,再查询数据库——数据库已修改成功Age=10,存入缓存,返回Age=10
- 如此,数据库和缓存的数据一致——Age=10
xxxxxxxxxx// c# 先删除缓存再修改数据库 伪代码public void DeleteCache(){ DeleteCache(key); // 1.删除缓存 PushMQEvent("UpdateAge"); // 2.发布事件}[Subscribe("UpdateAge")]public Task UpdateAgeAsync(){ //TODO: 事件幂等处理,避免重复消费 UpdateAgeBySql(); // 3.修改数据库 await Task.Delay(1000); // 4.延迟1000ms DeleteCache(key); // 5.再次删除缓存}我们可以发现,为了避免并发时其他请求缓存脏数据,我们在修改数据库后还需要延迟删除缓存,所以在业务允许下更推荐先修改数据库再删除缓存
推荐先修改数据库再删除缓存#1
假设两步操作均成功,岂不是万事大吉,无需处理?非也,在并发场景下还是会出现一点点问题的。如下图
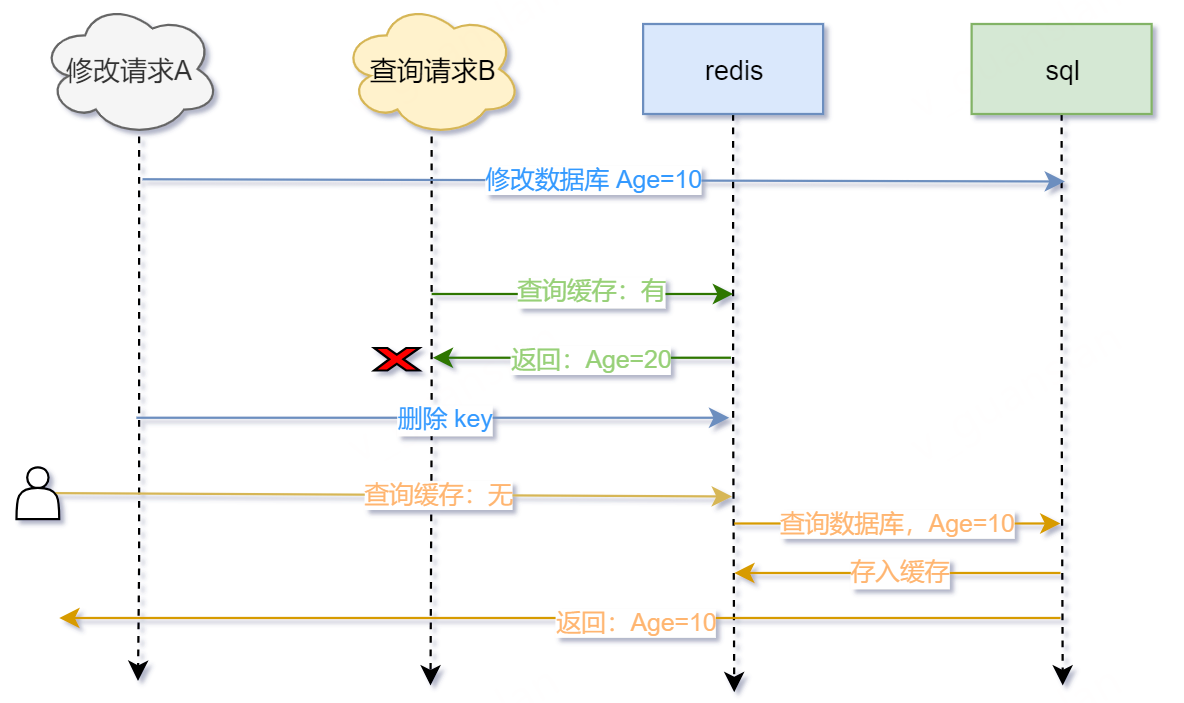
- 请求A用于修改Age,先修改数据库,修改成功Age=10
- 此时查询请求B开始请求,先查询缓存——有缓存Age=20,返回Age=20,脏数据
- 请求A接着删除缓存,删除成功
- 后续其他查询请求,先查询缓存——没有缓存,再查询数据库——数据库已修改成功Age=10,存入缓存,返回Age=10
- 如此,数据库和缓存数据一致。虽然修改数据库后到删除缓存成功的请求依然会读取到脏数据,但删除缓存成功后便不会存在此问题了
推荐先修改数据库再删除缓存#2
那假如两步操作其中一步失败呢?会发生什么情况
假设第一步修改数据库失败,此时数据库和缓存均未受影响,Age=20,不符合业务需求
假设第一步修改数据库成功,而删除缓存失败,我们先看看会发生什么,看图
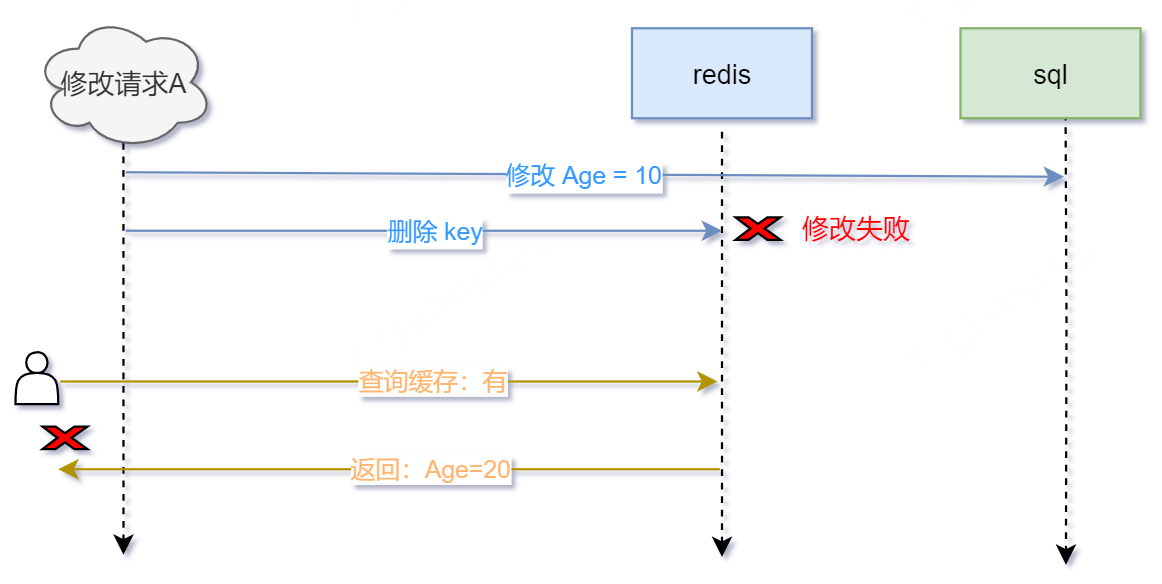
- 请求A用于修改Age,先修改数据库,修改成功Age=10
- 接着删除缓存,删除失败,此时缓存Age=20
- 后续其他查询请求,先查询缓存——有缓存,返回Age=20
- 如此,数据库和缓存的数据不一致——数据库Age=10,而缓存Age=20。无其它操作下,只有等缓存过期才会重新请求数据库,再设置缓存Age=10
那面对这种情况应该怎么处理呢?删除缓存失败大多两种情况:人为可控的——代码逻辑错误,不可控的——链接断开、请求数据库超时。对于人为可控的情况,我们需要修改调整优化逻辑,对于不可控的,我们用得最多的便是重试了。
那我们能不能让程序自动重试呢?当然可以,这也是我们比较推荐的方案,不过我们需要引入消息队列帮助我们完成重试,看图
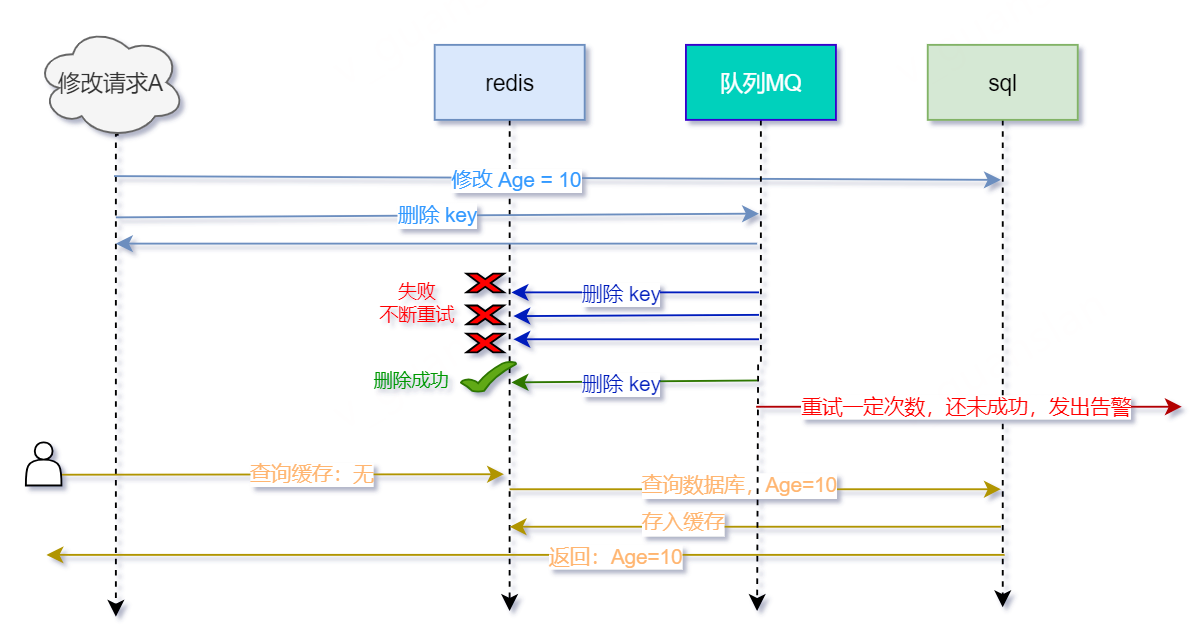
- 请求A用于修改Age,先修改数据库,修改成功
- 请求A接着通过MQ发布"删除缓存"事件,由程序订阅
- 程序订阅"删除缓存"事件,删除缓存。若成功,则不再触发,若失败,则过段时间由MQ自动触发达到重试效果,直至成功。建议设置最大重试次数,若多次重试仍不成功,则发出告警通知管理员
- 后续其他查询请求,先查询缓存——没有缓存,再查询数据库——数据库已修改成功Age=10,存入缓存,返回Age=10
- 如此,数据库和缓存的数据一致——Age=10
xxxxxxxxxx// c# 先删除缓存再修改数据库 伪代码public void UpdateAge(){ UpdateAgeBySql(); // 1.修改数据库 PushMQEvent("DeleteCache"); // 2.发布事件}[Subscribe("DeleteCache")]public Task DeleteCacheAsync(){. // 事件幂等处理,避免重复消费 DeleteCache(key); // 2.删除缓存}更推荐先修改数据库再删除缓存的原因:简单,无需删除两次缓存;对redis删除进行重试的风险更小
强一致性
虽然上面两种方式都能保证数据最终一致性,但是第一步操作成功到第二步操作成功存在时间差,期间并发的请求会读取到脏数据。如果不能容忍脏数据的存在,则需要牺牲部分性能,那就是加锁。(未实操)
其他方式
- 只更新缓存,由缓存自己同步更新数据库
- 只更新缓存,由缓存自己异步更新数据库
- Mysql,监听并读取biglog异步删除缓存
- 定期同步
参考:详解让MySQL和Redis数据保持一致的四种策略Mysql脚本之家 (jb51.net)
美团二面:如何保证Redis与Mysql双写一致性?连续两个面试问到了! - 码农Academy - 博客园 (cnblogs.com)
*redis缓存异常
redis常见的缓存异常问题和解决方案:
| 问题 | 现象 | 解决方案 |
|---|---|---|
| 数据库和缓存数据不一致 | 修改数据库和redis操作数据存在时间差导致数据不一致 | 推荐先修改数据库,再使用队列去执行删除缓存操作 |
| 缓存雪崩 | 在某一时间段内缓存大面积过期失效或者实例出现故障,导致所有请求直接请求数据库,有可能导致数据库崩溃 一般是大量请求读取不同的缓存key | 对于大面积过期,我们应该尽量设置不同的过期时间,并在指定过期时间的基础上加上随机数 对于实例出现故障,建议使用redis集群,增强高可用 |
| 缓存击穿 | 热点缓存数据失效过期,导致所有请求直接请求数据库,有可能导致数据库崩溃 一般是大量请求读取相同的缓存key | 1.访问数据库时使用互斥锁 2.热点数据不设过期时间,使用逻辑过期,缓存重建时也需要加锁 |
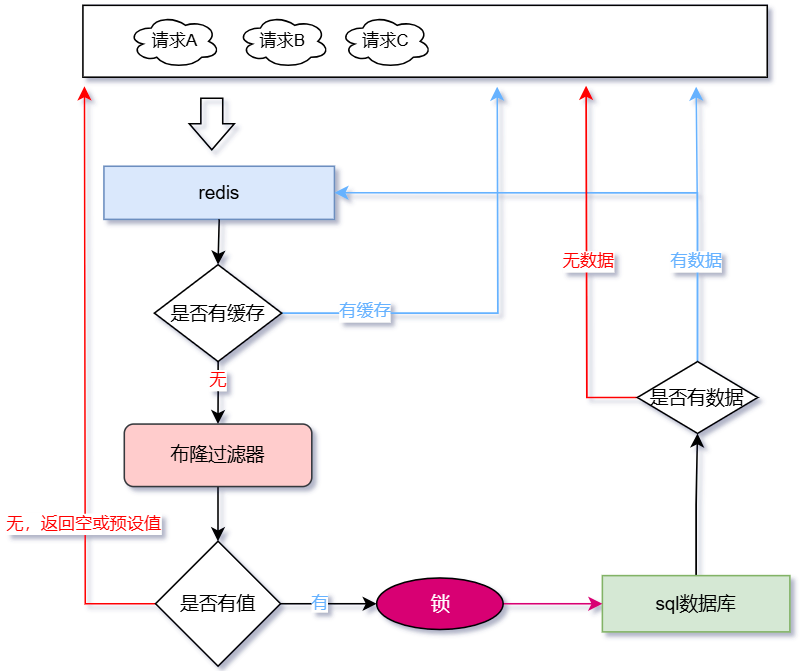
| 缓存穿透 | 大量请求无效数据导致查询为空,由于缓存没有存储该数据,导致每次请求缓存后继续请求数据库,有可能导致数据库崩溃 一般是大量恶意请求,读取不正常的数据(未缓存),从而将大量请求打到数据库上 | 1. 缓存存入空值,查询数据库不管有无数据,都设置缓存 2. 未命中缓存时,在查询数据库前,可以使用布隆过滤器查询一遍(可能会出现误判) 3. 请求过滤,不符合逻辑的请求直接返回预设值或者空值 4. 使用黑名单,限制IP请求 |
参考:Redis的缓存穿透、缓存击穿和缓存雪崩_redis 缓存穿透,雪崩-CSDN博客
缓存雪崩
在某一时间段内缓存大面积过期失效或者实例出现故障,导致所有请求直接请求数据库,有可能导致数据库崩溃
解决方案:
- 对于缓存大面积过期,我们应该尽量设置不同的过期时间。如果可以的话,在指定过期时间的基础上加上随机数
- 对于实例出现故障,建议使用redis集群,增强高可用
xxxxxxxxxx// c# 伪代码SetKeyEx(key1,xx,1000);SetKeyEx(key2,xx2,2000);SetKeyEx(key3,xx3,3000);SetKeyEx(key4,xx4,4000);SetKeyEx(key5,xx5,5000);...public void SetKeyEx<T>(string key, T value, long second, bool isAddRandomTime = true){ var randomMillonSecond = new Random().Next(2000); redis.SetEx(key, value, DateTime.Now.AddSeconds(second).AddMilliseconds(randomMillonSecond));}缓存击穿
热点缓存数据失效过期,导致所有请求直接请求数据库,有可能导致数据库崩溃
解决方案:
1.访问数据库时使用互斥锁。获取到锁的请求才可以访问数据库,其他请求睡眠等待。
2.热点数据不设置过期时间,使用逻辑过期,缓存重建。获取到锁的请求才可以访问数据库,其他请求返回过期数据(视情况而定)
缓存雪崩和缓存击穿有点像,有时会混淆。我们只要记住这两点:缓存雪崩是大量的key缓存失效,一般是大量请求读取不同的缓存key;而缓存击穿是某些热点缓存key失效,一般是大量请求读取相同的缓存key;
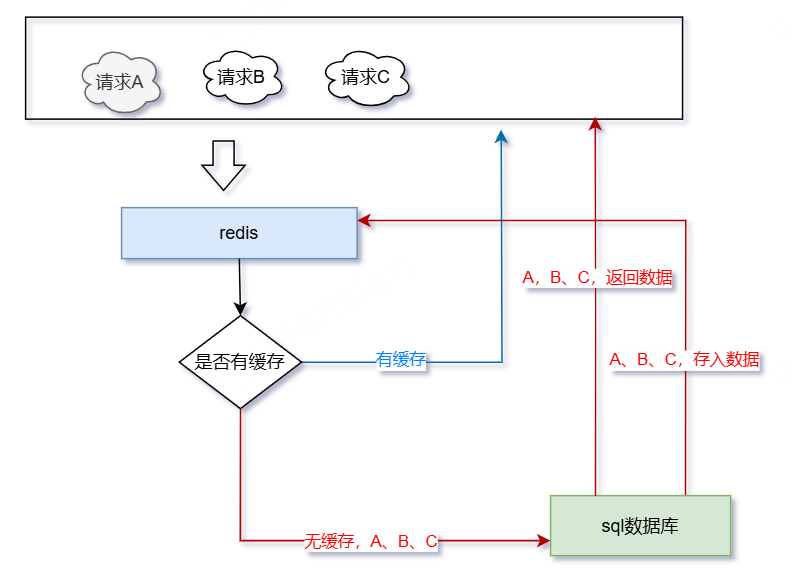
如上图,我们先看一下,会发生什么情况
- 请求A、B、C同时请求某个接口
- 请求A、B、C,查询缓存——没有缓存,查询数据库——有数据,存入缓存,返回数据
- 请求D请求,查询缓存——有缓存,返回数据
xxxxxxxxxx private string GetNow() { return DateTime.Now.ToString("HH:mm:ss:fff"); } /// <summary> /// 请求数据库——不使用互斥锁 /// </summary> /// <param name="firstName">查询条件</param> /// <param name="logGuid">日志Id标识</param> /// <returns></returns> public async Task<int> GetCountWithoutLockAsync(string firstName, string? logGuid = null) { logGuid ??= Guid.NewGuid().ToString(); string key = $"user:count"; _logger.LogInformation($"GetCount:{logGuid}:开始执行。" + GetNow()); var countResult = _redis.HashGet(key, firstName); if (!countResult.IsNull) { _logger.LogInformation($"GetCount:{logGuid}:返回缓存。" + GetNow()); return int.Parse(countResult!); } await Task.Delay(5000); // 模拟耗时 var countdb = await _userRepository.Get(x => x.Name != null && x.Name.StartsWith(firstName.Trim())).CountAsync(); _redis.HashSet(key, firstName, countdb.ToString()); _redis.KeyExpire(key, TimeSpan.FromSeconds(60)); _logger.LogInformation($"GetCount:{logGuid}:设置缓存,返回数据库查询结果。" + GetNow()); return countdb; }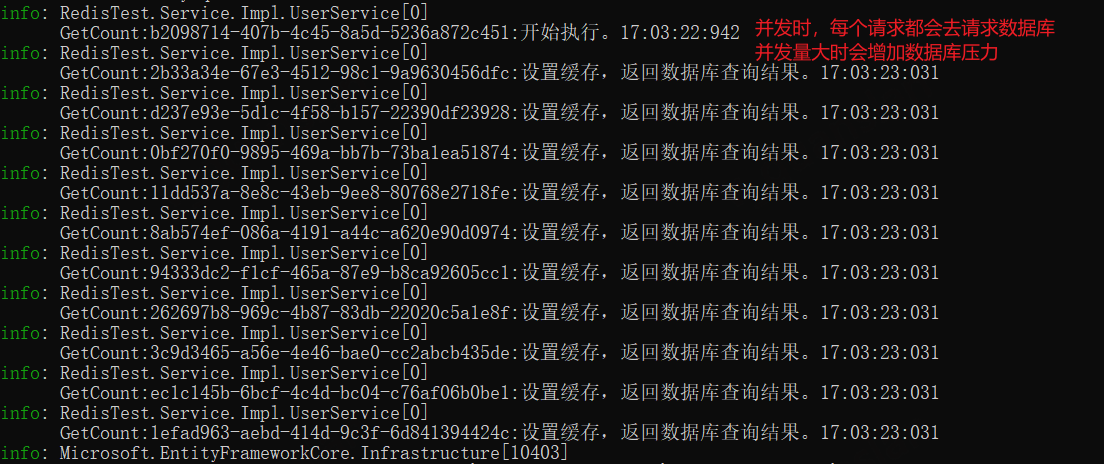
我们可以看到请求A、B、C都做了同样的操作,如果这里并发量很大,对于数据库的压力很大。
使用互斥锁
我们可以在请求数据库时加上一把锁,让某一个请求处理数据库逻辑,并将结果进行缓存,而其他请求只需要耐心等待,使用缓存即可
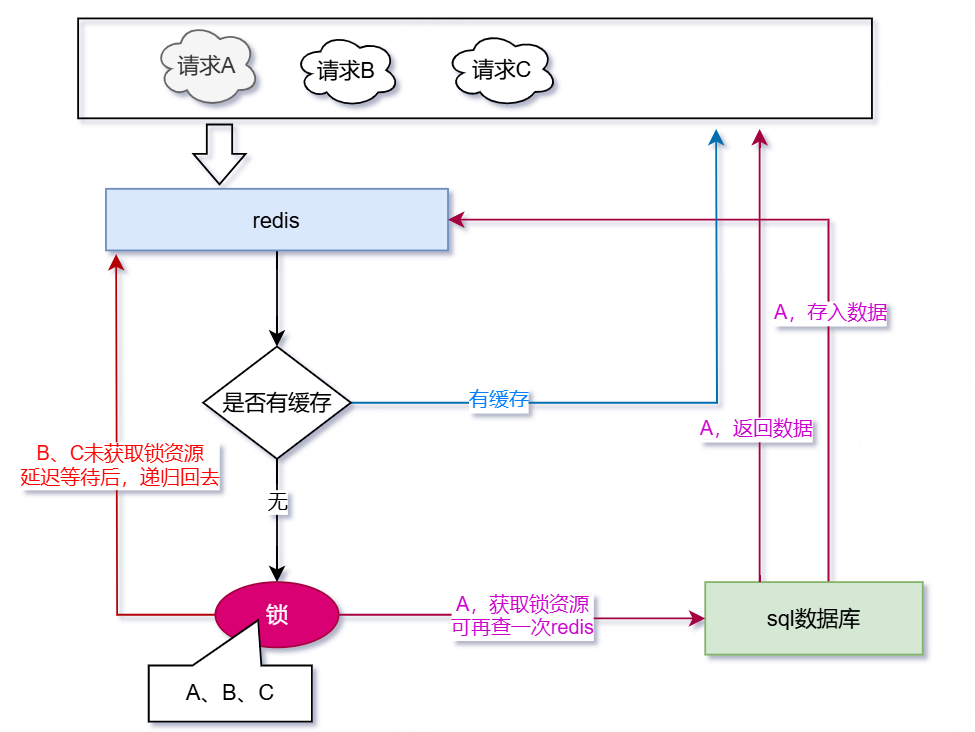
改造一下,看看会发生什么
- 请求A、B、C同时请求某个接口
- 请求A、B、C,查询缓存——没有缓存,请求A获取到锁资源(再判断一次redis),请求B、C未获取到锁资源,延迟等待,然后递归
- 请求A查询数据库,将查询结果存储redis缓存中,返回查询结果
- 请求B、C查询缓存——有缓存,返回缓存。
- 如果第一步查询缓存和获取锁存在较大间隔,可能会出现请求A已经释放锁,而请求B重新拿到新锁,此时重新查询缓存,存在的话,则直接返回缓存即可
xxxxxxxxxx /// <summary> /// 请求数据库——使用互斥锁 /// </summary> /// <param name="firstName">查询条件</param> /// <param name="logGuid">日志Id标识</param> /// <returns></returns> public async Task<int> GetCountWithLockAsync(string firstName, string? logGuid = null) { logGuid ??= Guid.NewGuid().ToString(); string key = $"user:count"; _logger.LogInformation($"GetCount:{logGuid}:开始执行。"+ GetNow()); var countResult = _redis.HashGet(key, firstName); if (!countResult.IsNull) { _logger.LogInformation($"GetCount:{logGuid}:返回缓存。" + GetNow()); return int.Parse(countResult!); } string lockKey = $"lock:{key}:{firstName}"; var lockValue = Guid.NewGuid().ToString(); try { if (await _redis.TryLockAsync(lockKey, lockValue, TimeSpan.FromSeconds(120))) // 根据数据库逻辑时长设置锁时间,可以设置久一点,反正会主动释放 { // 获取到锁,缓存重建 _logger.LogInformation($"GetCount:{logGuid}:获取到锁。" + GetNow()); countResult = _redis.HashGet(key, firstName); if (!countResult.IsNull) { _logger.LogInformation($"GetCount:{logGuid}:返回缓存2"); return int.Parse(countResult!); } await Task.Delay(5000); // 模拟耗时 var countdb = await _userRepository.Get(x => x.Name != null && x.Name.StartsWith(firstName.Trim())).CountAsync(); _redis.HashSet(key, firstName, countdb.ToString()); _redis.KeyExpire(key, TimeSpan.FromSeconds(60)); _logger.LogInformation($"GetCount:{logGuid}:设置缓存,返回数据库查询结果。" + GetNow()); return countdb; } else { // 未获取到锁 _logger.LogWarning($"GetCount:{logGuid}:未获取到锁"); await Task.Delay(1000); return await GetCountWithLockAsync(firstName, logGuid); // Todo:限制递归次数 } } catch (Exception ex) { _logger.LogError(ex, "请求失败"); return -1; } finally { await _redis.ReleaseLockAsync(lockKey, lockValue); } }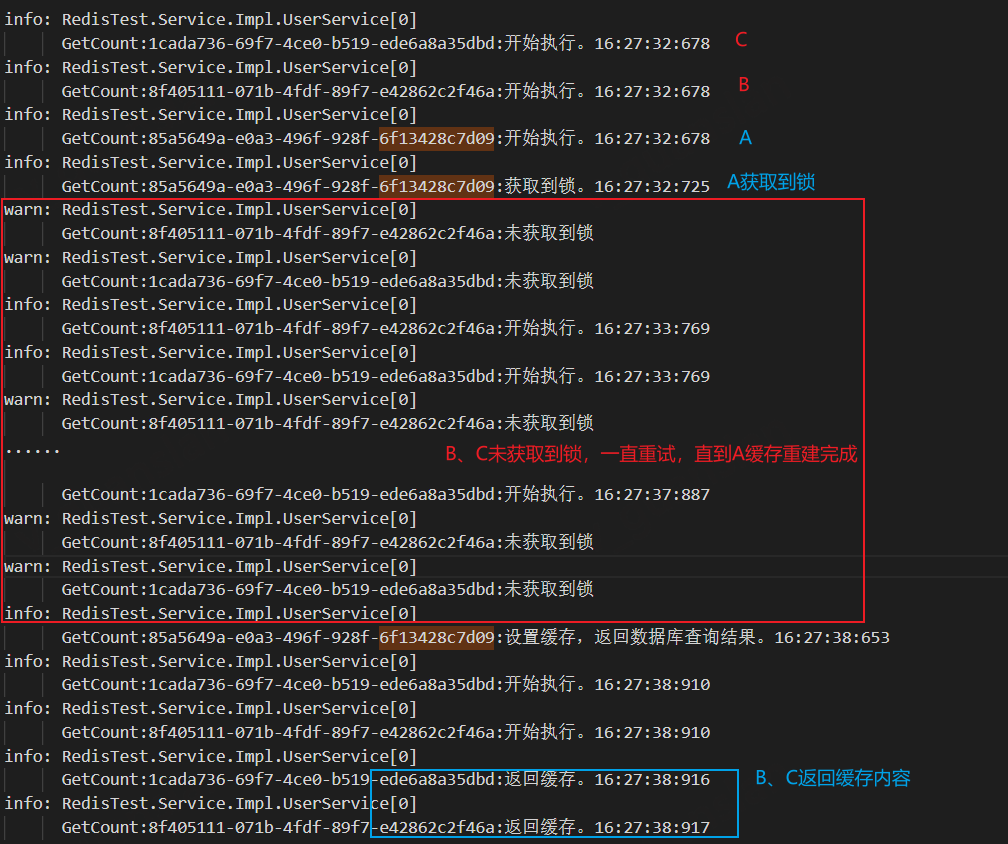
redis加锁
xxxxxxxxxx /// <summary> /// 加锁 /// </summary> /// <returns></returns> public async Task<bool> TryLockAsync(string lockKey, string guidStr, TimeSpan lockTimeout) { var hasLock = await _db.StringSetAsync(AddKeyPrefix(lockKey), guidStr, lockTimeout, When.NotExists); return hasLock; } /// <summary> /// 释放锁 /// </summary> /// <param name="lockKey"></param> /// <param name="guidStr"></param> /// <returns></returns> public async Task<bool> ReleaseLockAsync(string lockKey, string guidStr) { // 释放锁,需要确保是锁的拥有者才能释放 var value = await _db.StringGetAsync(AddKeyPrefix(lockKey)); if (value.HasValue && value == guidStr) { return await _db.KeyDeleteAsync(AddKeyPrefix(lockKey)); } return false; }逻辑过期
我们还可以使用逻辑过期的方式,处理缓存击穿问题。相比较直接使用互斥锁,逻辑过期可能会返回(已过期的)脏数据,但是无需等待锁释放,"用户体验会好一点"。如果容许脏数据的存在,可以使用该方式,不过需要使用定时任务或者管理员提前预备热点数据
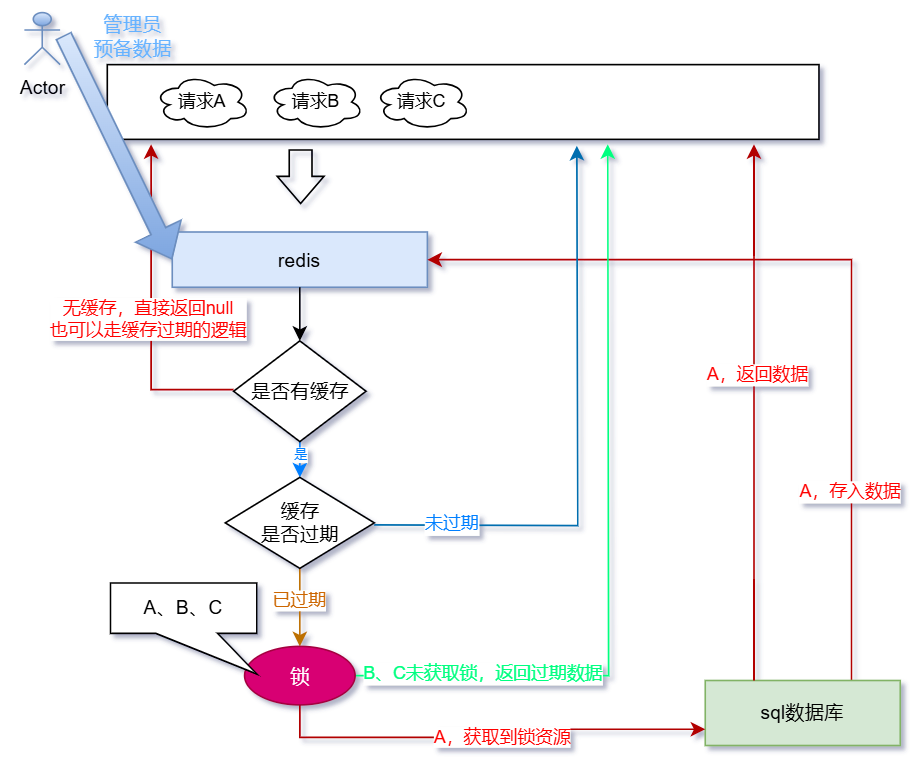
我们看看使用逻辑过期的流程
- 定时任务或者管理员预备热点数据(非常关键)
- 请求A、B、C同时请求某个接口
- 情况一:请求A、B、C,查询缓存——没有缓存,返回空(也可以走缓存过期逻辑,这样就无需预备数据了)。
- 情况二:请求A、B、C,查询缓存——有缓存;判断缓存是否过期——未过期,返回未过期的数据
- 判断缓存是否过期——已过期
- 尝试获取锁资源——请求A获取到锁资源,请求B、C未获取到锁资源,返回已过期的数据(脏数据)
- 请求A查询数据库,将查询结果存储redis缓存中,返回查询结果
xxxxxxxxxx private class ExpireData<T> { /// <summary> /// 真实数据 /// </summary> public T? Data { get; set; } /// <summary> /// 指定过期时间 /// </summary> public DateTime ExpireDate { get; set; } } /// <summary> /// 模拟预备数据 /// </summary> /// <param name="firstName"></param> /// <param name="logGuid"></param> /// <returns></returns> public void SetCacheCountexpire(string firstName, string? logGuid = null) { logGuid ??= Guid.NewGuid().ToString(); string key = $"user:countexpire"; _logger.LogInformation($"SetCacheCountexpire:{logGuid}:设置缓存,开始执行。" + GetNow()); var expireData = new ExpireData<int>() { Data = 1000, ExpireDate = DateTime.Now.AddSeconds(-30) }; _redis.HashSet(key, firstName, expireData); _logger.LogInformation($"SetCacheCountexpire:{logGuid}:设置缓存,成功。" + GetNow()); } /// <summary> /// 请求数据库——逻辑过期 /// </summary> /// <param name="firstName"></param> /// <param name="logGuid"></param> /// <returns></returns> public async Task<int> GetCountWithExpirAsync(string firstName, string? logGuid = null) { logGuid ??= Guid.NewGuid().ToString(); string key = $"user:countexpire"; _logger.LogInformation($"GetCountWithExpirAsync:{logGuid}:开始执行。" + GetNow()); var countResult = _redis.HashGet<ExpireData<int>>(key, firstName); if (countResult == null) { _logger.LogInformation($"GetCountWithExpirAsync:{logGuid}:没有缓存,返回空或预设值。" + GetNow()); // 如果读取缓存为空,表示不是“热点数据”可以直接返回空或预设值即可。不过,也可以在此处走"已过期的逻辑",具体按业务来决定 return -1; } // 未过期 if (countResult.ExpireDate >= DateTime.Now) { _logger.LogInformation($"GetCountWithExpirAsync:{logGuid}:未过期,返回缓存-{countResult.Data}。" + GetNow()); return countResult.Data; } // 已过期 string lockKey = $"lock:{key}:{firstName}"; var lockValue = Guid.NewGuid().ToString(); try { if (await _redis.TryLockAsync(lockKey, lockValue, TimeSpan.FromSeconds(100))) // 根据数据库逻辑时长设置锁时间,可以设置久一点,反正会主动释放 { // 获取到锁,缓存重建 _logger.LogInformation($"GetCountWithExpirAsync:{logGuid}:已过期,获取到锁,缓存重建。" + GetNow()); await Task.Delay(5000); // 模拟耗时 var countdb = await _userRepository.Get(x => x.Name != null && x.Name.StartsWith(firstName.Trim())).CountAsync(); var expireData = new ExpireData<int>() { Data = countdb, ExpireDate = DateTime.Now.AddMinutes(2) }; _redis.HashSet(key, firstName, expireData); // 不设置过期时间,或者设置久一点。确保读取的缓存不为空即可 _logger.LogInformation($"GetCountWithExpirAsync:{logGuid}:设置缓存,返回数据库查询结果——{countdb}。" + GetNow()); return countdb; } else { // 未获取到锁 _logger.LogWarning($"GetCountWithExpirAsync:{logGuid}:已过期且未获取到锁,返回过期数据——{countResult.Data}"); return countResult.Data; } } catch (Exception ex) { _logger.LogError(ex, "请求失败"); return -1; } finally { await _redis.ReleaseLockAsync(lockKey, lockValue); } }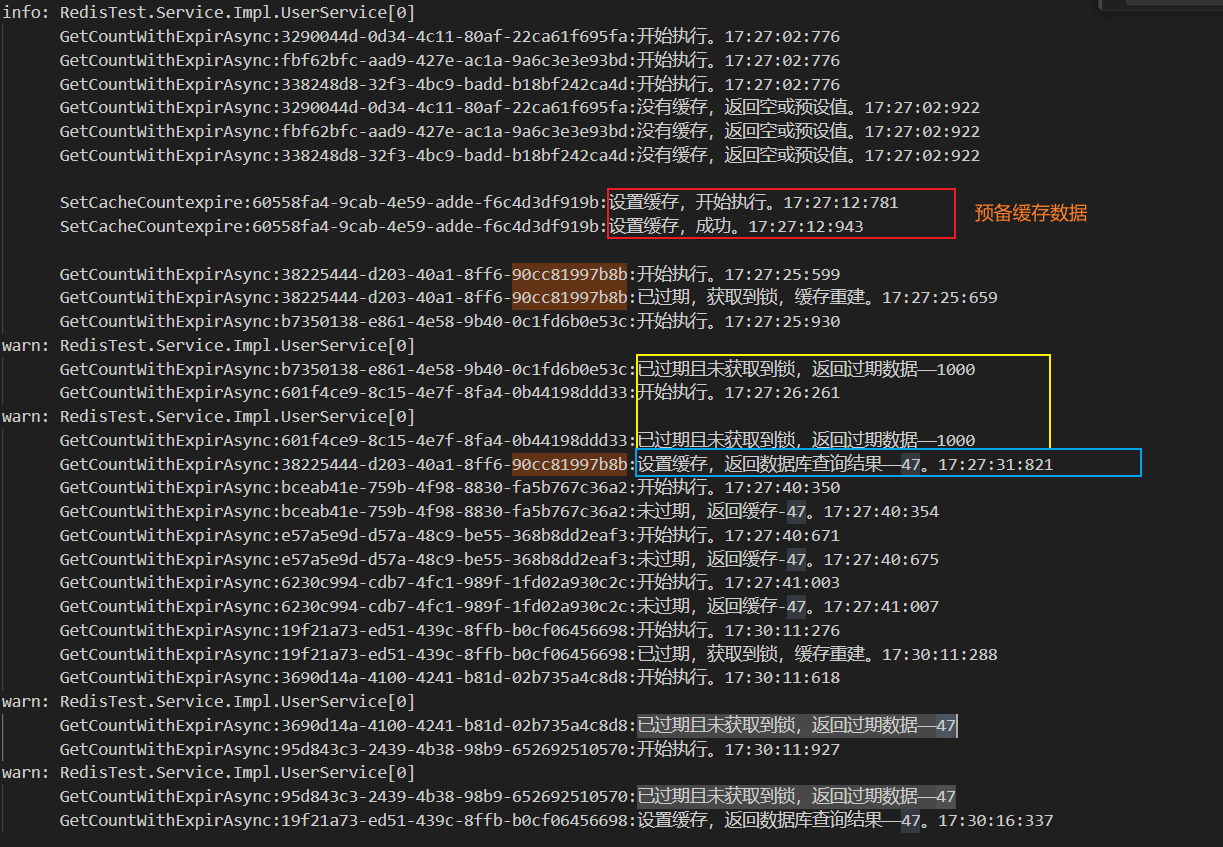
缓存穿透
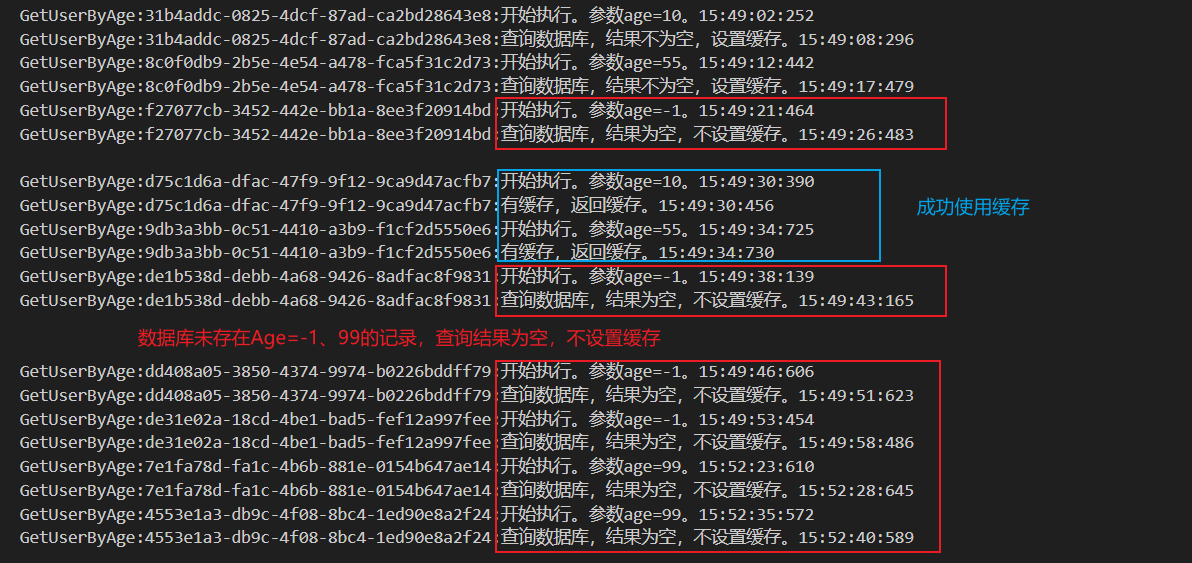
大量请求无效数据导致查询为空,由于缓存没有存储该数据,导致每次请求完缓存后继续请求数据库,有可能导致数据库崩溃。如查询age=-1的数据,数据库未匹配,返回空,不存储缓存,下一次同样的请求,永远都不会走缓存
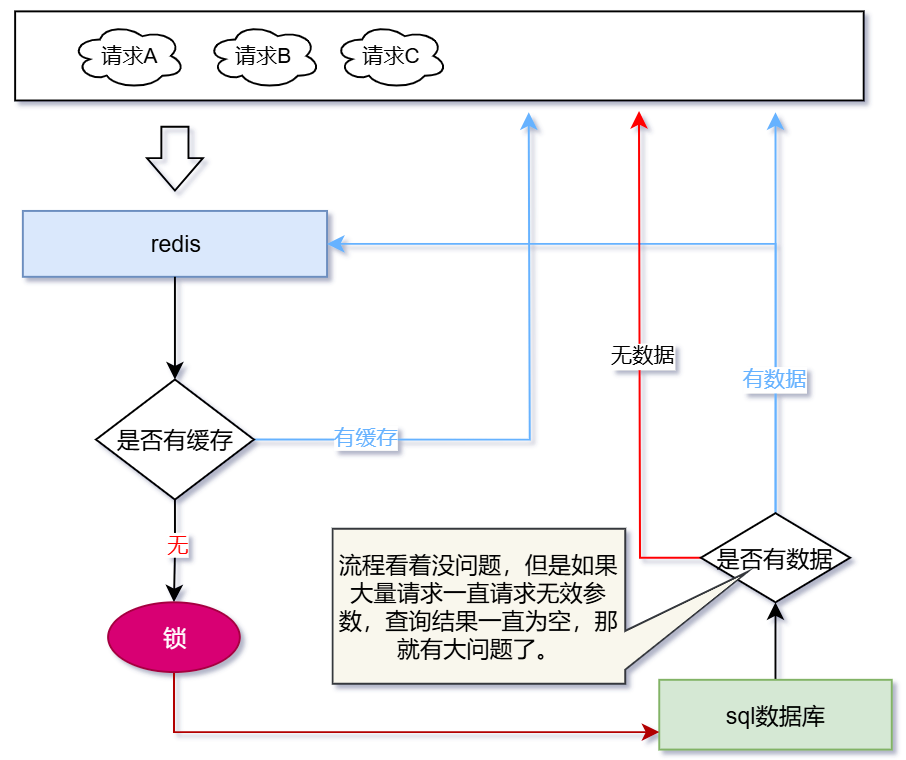
xxxxxxxxxx /// <summary> /// 根据年龄查询数据库——模拟缓存穿透,age=-1 /// </summary> /// <param name="age"></param> /// <param name="logGuid"></param> /// <returns></returns> public async Task<List<User>?> GetUserByAgeAsync(int age, string? logGuid = null) { logGuid ??= Guid.NewGuid().ToString(); string key = $"user:age:{age}"; _logger.LogInformation($"GetUserByAge:{logGuid}:开始执行。参数age={age}。" + GetNow()); var users = _redis.StringGet<List<User>>(key); if (users?.Any() == true) { _logger.LogInformation($"GetUserByAge:{logGuid}:有缓存,返回缓存。" + GetNow()); return users; } // Todo:使用互斥锁 await Task.Delay(5000); // 模拟耗时 users = _userRepository.Get(x => x.Age == age).ToList(); if (users?.Any() == true) { _logger.LogInformation($"GetUserByAge:{logGuid}:查询数据库,结果不为空,设置缓存。" + GetNow()); _redis.StringSet(key, users); } else { _logger.LogInformation($"GetUserByAge:{logGuid}:查询数据库,结果为空,不设置缓存。" + GetNow()); } return users; }数据库未存在age=-1、99的数据,查询结果为空,不设置缓存,每次请求都需要查询数据库
解决方案:
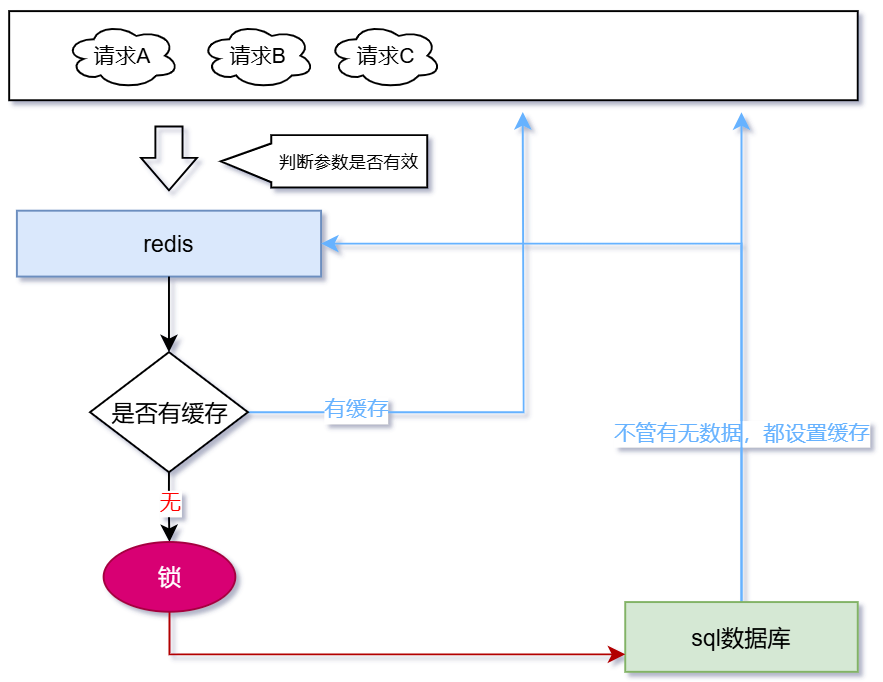
- 缓存存入空值,查询数据库不管有无数据,都设置缓存
- 未命中缓存时,在查询数据库前,可以使用布隆过滤器查询一遍(可能会出现误判)
- 请求过滤,不符合逻辑的请求直接返回预设值或者空值
- 使用黑名单,限制IP请求
缓存存入空值或使用布隆过滤器都可以有效避免缓存穿透问题,不过存入空值可能会多出很多"无意义"的key,而使用布隆过滤器小几率会存在误判情况
请求过滤、使用黑名单
请求过滤是最基本的判断,我们可以提前判断参数是否符合逻辑,不符合逻辑直接返回空或预设值即可,如age=-1。但是这种方式会有局限,只能过滤不正常的请求参数
xxxxxxxxxx// 年龄不能小于0,否则返回空或预设值if (age < 0) return null;若检测到大批量无效参数的请求,还可以将该ip纳入黑名单,限制访问
缓存存入空值
我们看上面的缓存穿透例子,最大的原因就是查询数据库时,若结果为空则不设置缓存。那我们在查询数据库时,不管有无数据都建立缓存,不就解决问题了
xxxxxxxxxx /// <summary> /// 根据年龄查询数据库——模拟处理缓存穿透,age=99 /// </summary> /// <param name="age"></param> /// <param name="logGuid"></param> /// <returns></returns> public async Task<List<User>?> GetUserByAgeNullAsync(int age, string? logGuid = null) { // 年龄不能小于0,否则返回空或预设值 if (age < 0) { _logger.LogWarning($"GetUserByAge:{logGuid}:检查参数。参数age={age}。年龄不能小于0" + GetNow()); return null; } logGuid ??= Guid.NewGuid().ToString(); string key = $"user:age:{age}"; _logger.LogInformation($"GetUserByAge:{logGuid}:开始执行。参数age={age}。" + GetNow()); // 判断缓存key是否存在 if (_redis.KeyExists(key)) { var users = _redis.StringGet<List<User>>(key); _logger.LogInformation($"GetUserByAge:{logGuid}:有缓存,返回缓存。数据为空:{users?.Any() != true}。" + GetNow()); return users; } // Todo:使用互斥锁 await Task.Delay(5000); // 模拟耗时 var dbUsers = _userRepository.Get(x => x.Age == age).ToList(); _logger.LogInformation($"GetUserByAge:{logGuid}:查询数据库,数据为空:{dbUsers?.Any() != true}。设置缓存。" + GetNow()); _redis.StringSet(key, dbUsers); return dbUsers; }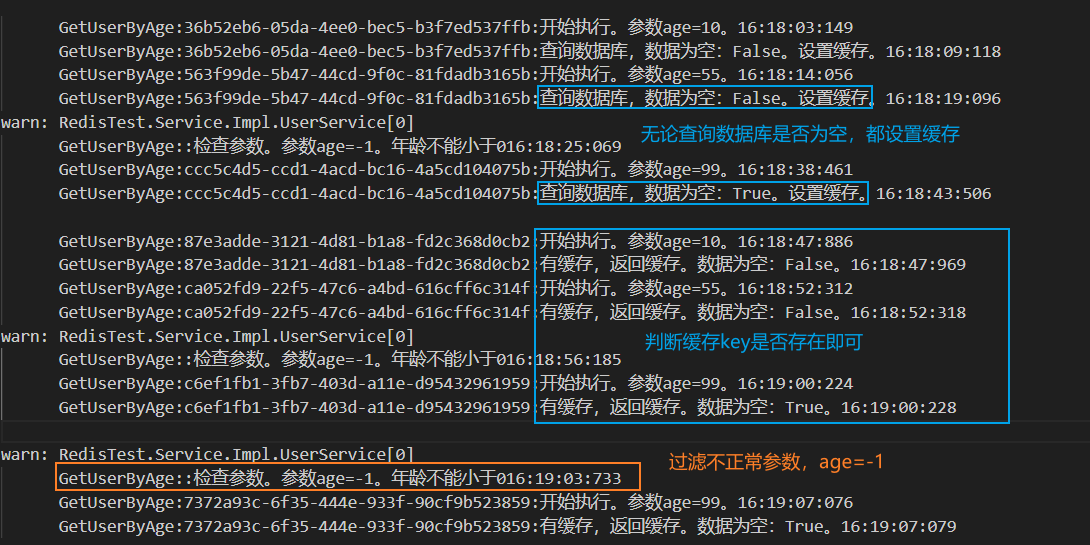
无论查询数据库是否为空,都将查询结果存入redis缓存。我们只需要判断缓存是否存在即可,存在则返回缓存,不存在则请求数据库。这样做有个比较明显的问题需要注意——如当前数据库没有age=99的记录,则redis缓存空数据。此时刚好新增一条age=99的数据,我们要在数据库新增完成后,将redis对应的key删除,保证数据库和缓存数据的最终一致性。
使用布隆过滤器
使用带有布隆过滤器的redis,推荐使用redis-stack。参考:带有布隆过滤器的redis
xxxxxxxxxx# 使用带有布隆过滤器的redis https://hub.docker.com/r/redis/redis-stackdocker pull redis/redis-stack:7.4.0-v0docker run -d --restart=always --name redis-stack -p 6379:6379 -p 8001:8001 -v /f/dockerHome/redis/data:/data -e REDIS_ARGS="--requirepass 123456" redis/redis-stack:7.4.0-v0除了存入空值,我们还可以使用布隆过滤器处理缓存穿透问题,我们只需要判断缓存是否存在再判断一次布隆过滤器即可。
那为什么使用布隆过滤器?这个问题和"为什么使用redis"一样,布隆过滤器作为redis的插件拥有这两个特点:空间效率和查询时间的高效性,而且redis比sql数据库能抗下更高的并发量。
xxxxxxxxxx /// <summary> /// 批量添加用户 /// </summary> /// <param name="count"></param> /// <param name="logGuid"></param> /// <returns></returns> public async Task<int> AddUserBloomAsync(int count, string? logGuid = null) { logGuid ??= Guid.NewGuid().ToString(); var list = Enumerable.Range(0, count).Select(x => new User() { Id = Guid.NewGuid(), Age = MockData.Number.Get(10, 100), Name = MockData.UserInfo.GetFullName() }).ToList(); _userRepository.AddItems(list); var bloomKey = "bloom:user:age"; // 判断过滤器是否存在 var keyInfo = await _redis.BloomInfoAsync(bloomKey); if (keyInfo == null) { // 不存在则创建,错误率:0.01,初始容量:200 await _redis.BloomReserveAsync(bloomKey, 0.01, 200); } // 往布隆过滤器插入年龄, await _redis.BloomMAddAsync(bloomKey, list.Select(x => x.Age.ToString()).Distinct()); // 保存数据库 // todo:保证数据库和缓存的最终一致性 return _unitOfWork.SaveChanges(); } /// <summary> /// 根据年龄查询数据库——模拟处理缓存穿透,age=99,布隆过滤器 /// </summary> /// <param name="age"></param> /// <param name="logGuid"></param> /// <returns></returns> public async Task<List<User>?> GetUserByAgeBloomAsync(int age, string? logGuid = null) { // 年龄不能小于0,否则返回空或预设值 if (age < 0) { _logger.LogWarning($"GetUserByAgeBloomAsync:{logGuid}:检查参数。参数age={age}。年龄不能小于0" + GetNow()); return null; } logGuid ??= Guid.NewGuid().ToString(); string key = $"user:age:{age}"; _logger.LogInformation($"GetUserByAgeBloomAsync:{logGuid}:开始执行。参数age={age}。" + GetNow()); // 判断缓存key是否存在 var users = _redis.StringGet<List<User>>(key); if (users?.Any() == true) { _logger.LogInformation($"GetUserByAgeBloomAsync:{logGuid}:有缓存,返回缓存。" + GetNow()); return users; } var bloomKey = "bloom:user:age"; // 判断布隆过滤器是否存在指定年龄age if (!(await _redis.BloomExistAsync(bloomKey, age.ToString()))) { // 不存在年龄age,返回空或预设值 _logger.LogInformation($"GetUserByAgeBloomAsync:{logGuid}:布隆过滤器没有值,返回空或预设值。" + GetNow()); return null; } // 存在年龄age,再查询数据库 _logger.LogInformation($"GetUserByAgeBloomAsync:{logGuid}:布隆过滤器有值,开始查询数据库。" + GetNow()); // Todo:使用互斥锁 await Task.Delay(5000); // 模拟耗时 var dbUsers = _userRepository.Get(x => x.Age == age).ToList(); if(dbUsers?.Any() != true) { // 虽然加了一层布隆过滤器,但还是会有误判率或者有人把布隆过滤器的key删掉了 _logger.LogInformation($"GetUserByAgeBloomAsync:{logGuid}:查询数据库。没有值,返回空或预设值。" + GetNow()); return null; } _logger.LogInformation($"GetUserByAgeBloomAsync:{logGuid}:查询数据库。有值,设置缓存。" + GetNow()); _redis.StringSet(key, dbUsers); return dbUsers; } /// <summary> /// 将现有数据加入到布隆过滤器中 /// </summary> /// <param name="logGuid"></param> /// <returns></returns> public async Task LoadAgeBloomAsync(string? logGuid = null) { var bloomKey = "bloom:user:age"; // 判断过滤器是否存在 var keyInfo = await _redis.BloomInfoAsync(bloomKey); if (keyInfo == null) { // 不存在则创建,错误率:0.01,初始容量:200 await _redis.BloomReserveAsync(bloomKey, 0.01, 200); } var ages = _userRepository.Get(x => true).GroupBy(x => x.Age).Select(x => x.Key.ToString()).ToList(); _logger.LogInformation($"LoadAgeBloomAsync:{logGuid}:开始执行。查询数据库。" + GetNow()); await _redis.BloomMAddAsync(bloomKey, ages); _logger.LogInformation($"LoadAgeBloomAsync:{logGuid}:重新设置布隆过滤器。" + GetNow()); }首先,清空表数据,从0开始
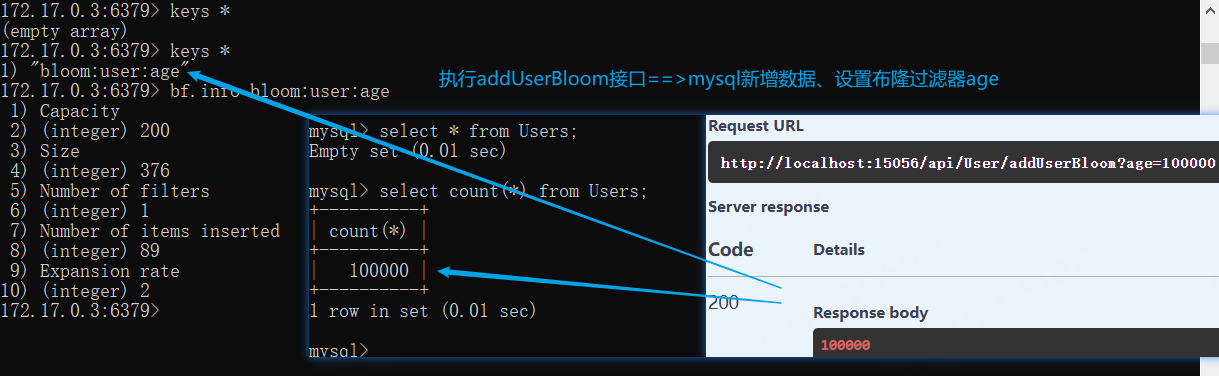
xxxxxxxxxxtruncate table Users;

第二步,执行addUserBloom接口,成功执行后,mysql会新增数据,同时设置布隆过滤器age
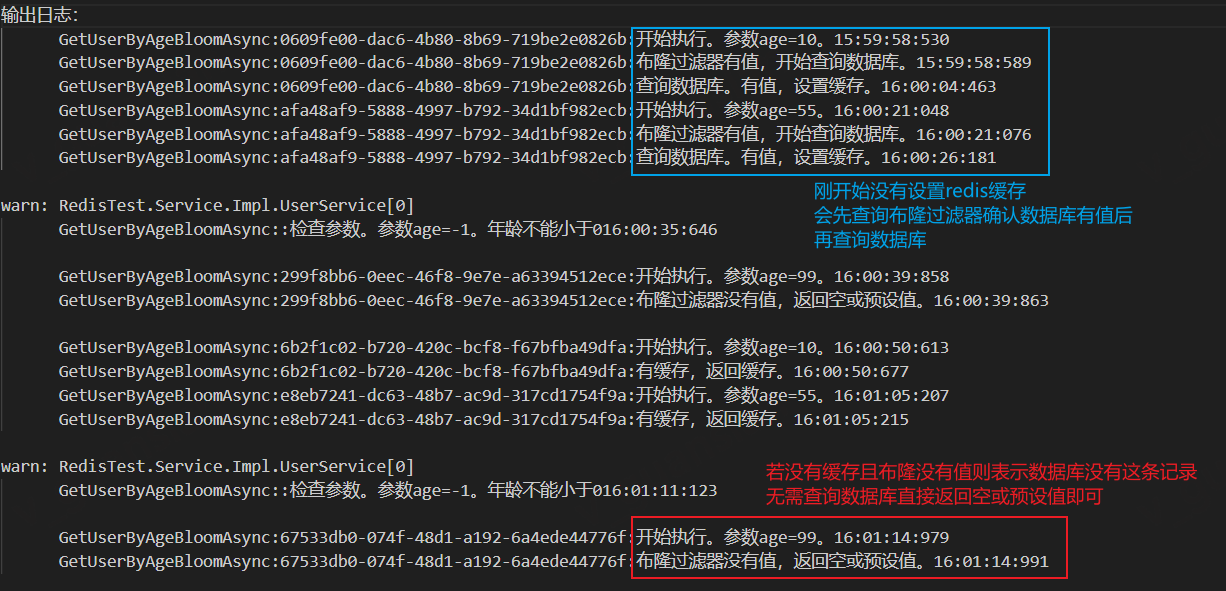
第三步,执行userByAgeBloom接口,根据年龄查询数据库。刚开始没有设置redis缓存会先查询布隆过滤器确认数据库有值后再查询数据库。若没有缓存且布隆过滤器也没有值则表示数据库没有这条记录(存在一定误判率),那么无需查询数据库直接返回空或预设值即可
第四步,删除布隆过滤器key,执行loadAgeBloom接口可以把现有数据加载到布隆过滤器中

缓存污染与淘汰策略
缓存污染是指缓存中存在大量不经常使用的缓存甚至未曾使用的缓存,占据大量空间。
对于这些数据我们可以使用LFU淘汰策略,当缓存空间不足时,LFU会优先淘汰访问次数少的数据,访问次数相同则淘汰更久远的数据;相反LRU淘汰策略更关注数据的时效性,会优先淘汰更久远的数据
*redis保证原子性
redis保证原子性的方式:
- 递增(INCR)、递减(DECR),单命令基本可以实现原子性
- lua脚本
- 代码加锁,不过加锁会影响并发效率
- multi、exec可以保证执行前的原子性,执行中报错不保证原子性
*redis使用建议
为了更好地使用redis,可参考以下建议:
- key命名。一般以业务为前缀使用冒号(:)分割,可适当缩写控制key长度
- 避免bigkey的出现。string类型大小控制在10kb以下,很大时可以进行压缩再存储;集合类型的个数控制在1w以下,很多时可以拆分成多个小集合。能用整数尽量用整数,redis内置0-9999的整数对象共享池(LRU策略无法使用)
- redis用于保存热数据,不同的业务使用不同的实例,避免互相影响
- redis设置缓存一定要设置过期时间,避免设置同一过期时间导致缓存集中过期
- redis容量大小控制在2-6GB之间
- 线上禁用命令:keys *、flushdb、flushall
- 线上慎用命令:MONITOR、全量查询命令(HGETALL、SMEMBERS)、大数据写入可分小批量多次写入
- redis4.0+,建议使用unlink代替del命令、使用flushdb async、flushall async 代替 flushdb、flushall
- redis4.0+,建议开启lazy-free
- 读请求量大,使用读写分离。写请求量大,使用切片集群
- 不要使用redis替代sql存储
redis运维工具
| 运维工具 | 用途 |
|---|---|
| info 命令 | 关注Stats、CPU、Memory、Persistence、Replication指标 |
| Prometheus https://prometheus.io/download/ | ”普罗米修斯“,可视化监控 |
| redis-exporter、redis-stat、redis live oliver006/redis_exporter junegunn/redis-stat nkrode/RedisLive | 监控工具 |
| redis-shake tair-opensource/RedisShake | 数据迁移 |
| redis-full-check tair-opensource/RedisFullCheck | 迁移后对比工具 |
| cacheCloud sohutv/cachecloud | 集群监控工具 |