mongodb从入门到放弃
>准备工作参考资料搭建副本集主节点myrs_27017:从节点myrs_27018:仲裁节点myrs_27019:连接节点添加副本从节点添加仲裁者节点副本集读写操作演示主节点的选举原则SpringDataMongoDB连接副本集分片集群分片包含的组件第一套副本集Myshardrs01_27018Myshardrs01_27118Myshardrs01_27218启动第一套副本集:一主一副本一仲裁第二套副本集myshardrs02_27318myshardrs02_27418myshardrs02_27518启动第二套副本集:一主一副本一仲裁配置节点副本集的创建Myconfigrs_27019myconfigrs_27119myconfigrs_27219启动配置节点副本集:一主二副本路由集Mymongos_27017启动并打开mongos路由分片功能及演示添加分片将第一套副本集添加进来将第二套副本集添加进来移除分片参考(了解)开启DB分片功能开启集合分片功能分片规则一:哈希策略分片规则二:范围策略哈希与范围分片规则对比:查看分片状态分片不成功处理增加第二个路由节点启动并打开第二个mongos路由安全认证一些问题外部无法链接mongodbrs.add('localhost:27019')报错mongod启动报错sh.addShard("myshardrs01/localhost:27018,localhost:27118,localhost:27218")报错pymongo链接副本集集群pymongo链接分片集群关闭副本集集群关闭分片集群mongodb插入时报错mongodb插入时自动添加_t,_v属性
准备工作
linux创建用户,用户名为mongo,然后切换到mongo用户
参考资料
原文档:documents/MongoDB.md · Aoisama/studied - Gitee.com
pdf: mongodb_advance.pdf
搭建副本集
一主一从一仲裁。
主节点
建立存放数据和日志的目录
#---------myrs#主节点mkdir -p /home/mongo/mongodb/replica_sets/myrs_27017/logmkdir -p /home/mongo/mongodb/replica_sets/myrs_27017/data/db新建或修改配置文件:
xxxxxxxxxxvim mongodb/replica_sets/myrs_27017/mongod.confmyrs_27017:
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/replica_sets/myrs_27017/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/replica_sets/myrs_27017/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/replica_sets/myrs_27017/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27017replication: #副本集的名称 replSetName: myrs启动节点服务:
xxxxxxxxxx/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/replica_sets/myrs_27017/mongod.conf
从节点
建立存放数据和日志的目录
xxxxxxxxxx#---------myrs#从节点mkdir -p /home/mongo/mongodb/replica_sets/myrs_27018/logmkdir -p /home/mongo/mongodb/replica_sets/myrs_27018/data/db新建或修改配置文件:
xxxxxxxxxxvim /home/mongo/mongodb/replica_sets/myrs_27018/mongod.confmyrs_27018:
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/replica_sets/myrs_27018/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/replica_sets/myrs_27018/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/replica_sets/myrs_27018/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27018replication: #副本集的名称 replSetName: myrs启动服务
xxxxxxxxxx/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/replica_sets/myrs_27018/mongod.conf
仲裁节点
建立存放数据和日志的目录
xxxxxxxxxx#---------myrs#从节点mkdir -p /home/mongo/mongodb/replica_sets/myrs_27019/logmkdir -p /home/mongo/mongodb/replica_sets/myrs_27019/data/db新建或修改配置文件:
xxxxxxxxxxvim /home/mongo/mongodb/replica_sets/myrs_27019/mongod.confmyrs_27019:
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/replica_sets/myrs_27019/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/replica_sets/myrs_27019/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/replica_sets/myrs_27019/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27019replication: #副本集的名称 replSetName: myrs启动服务
xxxxxxxxxx/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/replica_sets/myrs_27019/mongod.conf
连接节点
使用客户端命令连接任意一个节点,但这里尽量要连接主节点(27017节点)使之成为主节点:
xxxxxxxxxx/home/mongo/mongodb/bin/mongo localhost:27017连入后必须初始化副本才行
xxxxxxxxxxrs.initiate() #可加参数configuration初始化之后按一下回车从secondary变为primary

之后可以使用
rs.conf()和rs.status()来查看相应的信息
添加副本从节点
在主节点添加从节点,将其他成员加入到副本集中
语法:
xxxxxxxxxxrs.add(host,arbiterOnly)| Parameter | Type | Description |
|---|---|---|
| host | string or document | 要添加到副本集的新成员。指定为字符串或配置文档:1)如果是一个字符串,则需要指定新成员的主机名和可选的端口号;2)如果是一个文档,请指定在members数组中找到的副本集成员配置文档。您必须在成员配置文档中指定主机字段。有关文档配置字段的说明,详见下方文档:"主机成员的配置文档" |
| arbiterOnly | boolean | 可选的。仅在值为字符串时适用。如果为true,则添加的主机是仲裁者。 |
主机成员的配置文档:
xxxxxxxxxx{_id:<int>,host:<string>,arbiterOnly:<boolean>,buildIndexes:<boolean>,hidden:<boolean>,priority:<number>,tags:<document>,slaveDelay:<int>,votes:<number>}
示例:
将27018的副本节点加添加到副本集汇总:
xxxxxxxxxxrs.add("localhost:27018")添加仲裁者节点
xxxxxxxxxxrs.add(host,arbiterOnly)或rs.addArb(host)xxxxxxxxxxrs.addArb("localhost:27019")
副本集读写操作演示
登陆主节点27017,写入和读取数据:
xxxxxxxxxx/home/mongo/mongodb/bin/mongo localhost:27017use testdb.comment.insert({"articleid":"100000","content":"今天天气真好,阳光明媚","userid":"1001","nickname":"Aoi","createdatetime":new Date()})登陆从节点:
x/home/mongo/mongodb/bin/mongo localhost:27018
#此时进入时会发现无法读取任何数据,要先将当前节点变为从节点#旧版本#rs.slaveOk()#或#rs.slaveOk(true)#新版本 slaveOk() is deprecated and may be removed in the next major release. Please use secondaryOk() insteadrs.secondaryOk()#取消从节点#旧版本#rs.slaveOk(false)#新版本rs.secondaryOk(false)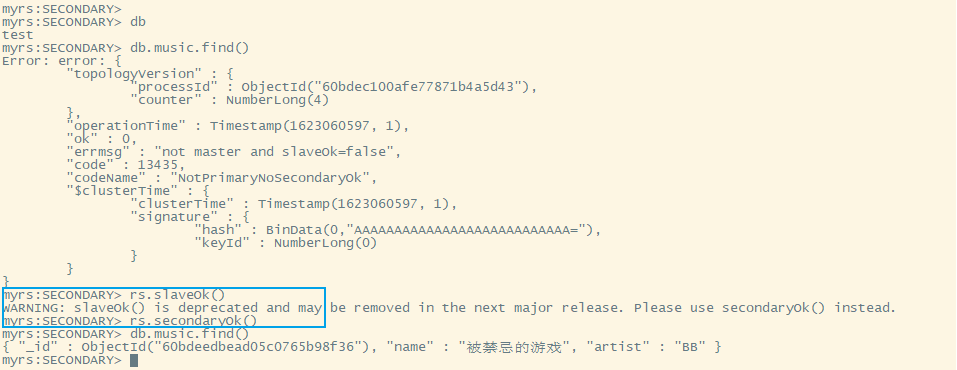
仲裁者节点
该节点不存放任何数据信息,只用于查看配置信息
主节点的选举原则
MongoDB在副本集中,会自动进行主节点的选举,主节点选举的触发条件:
- 主节点故障
- 主节点网络不可达(默认心跳信息为10秒)
- 人工干预(rs.stepDown(600))
一旦触发选举,就要根据一定的规则来选主节点
选举规则是根据票数来决定谁获胜:
- 票数最高,且获得了"大多数"成员的投票支持的节点获胜
"大多数"的定义为:假设复制集内投票成员数量为N,则大多数为N/2+1。例如:3个投票成员,则大多数的值是2.当复制集内存活的数量不足大多数时,整个复制集将无法选举出Primary,复制集将无法提供写服务,处于只读状态。
- 若票数相同,且都获得了"大多数"成员的投票支持的,数据新的节点获胜。
数据的新旧是通过操作日志oplog来对比的。
【了解】修改优先级 (从主节点更改)
比如,下面提升从节点的优先级:
1)先将配置导入cfg变量
2)然后修改值(ID号默认从0开始)
3)重新加载配置 稍等片刻会重新开始选举。
xxxxxxxxxxcfg=rs.conf()cfg.members[1].priority=2rs.reconfig(cfg)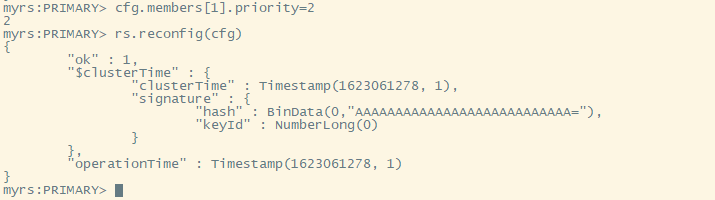
SpringDataMongoDB连接副本集
语法:
xxxxxxxxxxmongodb://host1,host2,host3/?connect=replicaSet&slaveOk=true&replicaSet=副本集名字其中:
- slaveOk=true:开启副本节点读的功能,可实现读写分离。
- connect=replicaSet:自动到副本集中选择读写的主机。如果slaveOk是打开的,则实现读写分离。
示例:
连接replica set三台服务器(端口27017,27018,27019),直接连接第一个服务器,无论是replica set一部分或者主服务器或者从服务器,写入操作应用在主服务器并且分布查询到从服务器。
xxxxxxxxxxspring:#数据源配置data:mongodb:#主机地址#host: localhost#数据库#database: test#默认端口号是27017#port: 27017#也可以使用uri连接uri: mongodb://localhost:27017,localhost:27018,localhost:27019/test?connect=replicaSet&slaveOk=true&replicaSet=myrs
分片集群
先杀掉上面的27017、27018、27019的进程
分片是一种跨多台机器分布数据的方法,MongoDB使用分片来支持具有非常大的数据集和高吞吐量操作的部署。
换句话说:分片就是将数据拆分,将其分散到不同的机器上的过程。
分片包含的组件
- 分片(存储):每个分片包含分片数据的子集。每个分片都可以部署为副本集。
- mongos(路由):mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口。
- config servers("调度"的配置):配置服务器存储群集的元数据和配置设置。
第一套副本集
准备存放数据和日志的目录
xxxxxxxxxx#--------------------myshardrs01mkdir -p /home/mongo/mongodb/myshardrs01_27018/logmkdir -p /home/mongo/mongodb/myshardrs01_27018/data/db
mkdir -p /home/mongo/mongodb/myshardrs01_27118/logmkdir -p /home/mongo/mongodb/myshardrs01_27118/data/db
mkdir -p /home/mongo/mongodb/myshardrs01_27218/logmkdir -p /home/mongo/mongodb/myshardrs01_27218/data/db新建或修改配置文件
xxxxxxxxxxvim /home/mongo/mongodb/myshardrs01_27018/mongod.confMyshardrs01_27018
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/myshardrs01_27018/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/myshardrs01_27018/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/myshardrs01_27018/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27018replication: #副本集的名称 replSetName: myshardrs01sharding: #分片角色 clusterRole: shardsvrsharding.clusterRole:
| Value | Description |
|---|---|
| configsvr | Start this instance as a config server.The instance starts on port 27019 by default. |
| shardsvr | Start this instance as a shard.The instance starts on port 27018 by default. |
注意:
设置sharding.clusterRole需要mongod示例运行复制。要将实例部署为副本集成员,请使用replSetName设置并指定副本集的名称。
第二个服务:
新建或修改配置文件:
xxxxxxxxxxvim /home/mongo/mongodb/myshardrs01_27118/mongod.confMyshardrs01_27118
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/myshardrs01_27118/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/myshardrs01_27118/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/myshardrs01_27118/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27118replication: #副本集的名称 replSetName: myshardrs01sharding: #分片角色 clusterRole: shardsvr第三个服务:
新建或修改配置文件:
xxxxxxxxxxvim /home/mongo/mongodb/myshardrs01_27218/mongod.confMyshardrs01_27218
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/myshardrs01_27218/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/myshardrs01_27218/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/myshardrs01_27218/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27218replication: #副本集的名称 replSetName: myshardrs01sharding: #分片角色 clusterRole: shardsvr启动第一套副本集:一主一副本一仲裁
xxxxxxxxxx/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/myshardrs01_27018/mongod.conf/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/myshardrs01_27118/mongod.conf/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/myshardrs01_27218/mongod.conf
xxxxxxxxxx/home/mongo/mongodb/bin/mongo localhost:27018xxxxxxxxxxrs.initiate()rs.add("localhost:27118")rs.addArb("localhost:27218")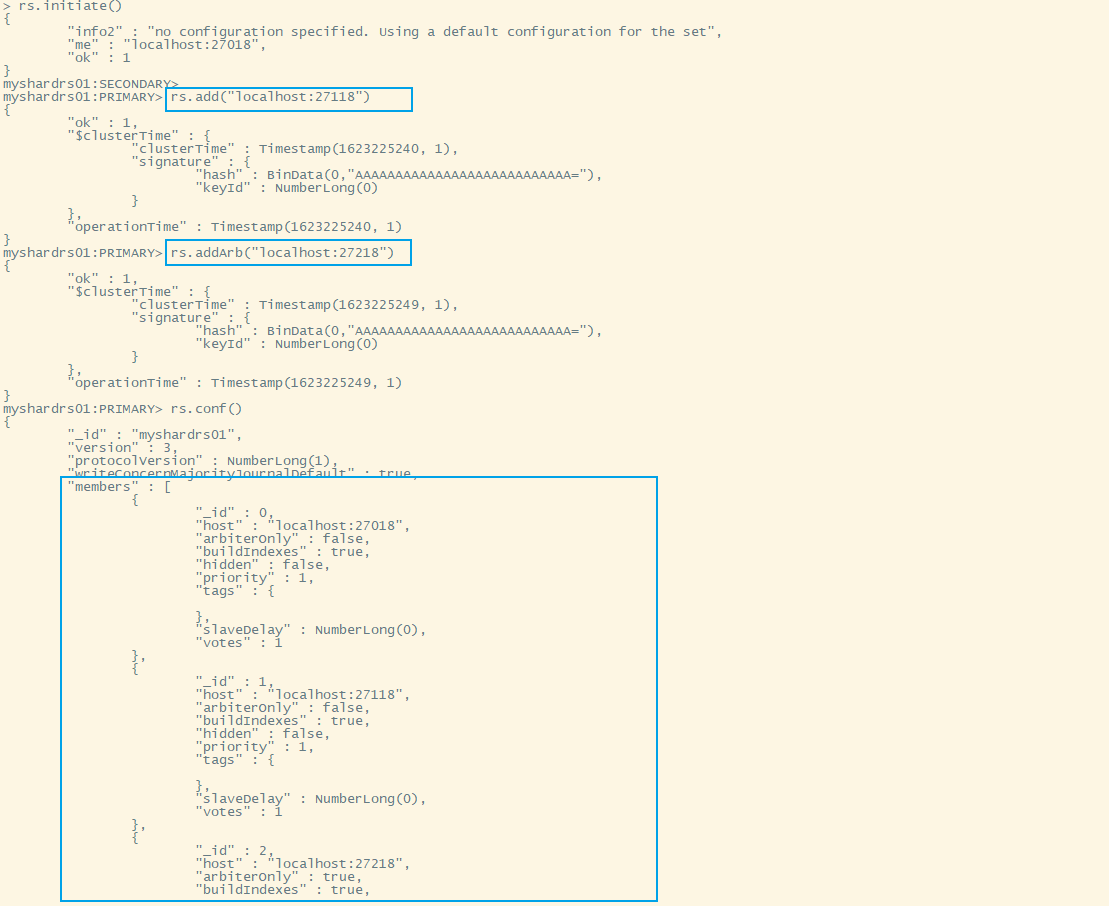
第二套副本集
准备存放数据和日志的目录
xxxxxxxxxx#--------------------myshardrs01mkdir -p /home/mongo/mongodb/myshardrs02_27318/logmkdir -p /home/mongo/mongodb/myshardrs02_27318/data/db
mkdir -p /home/mongo/mongodb/myshardrs02_27418/logmkdir -p /home/mongo/mongodb/myshardrs02_27418/data/db
mkdir -p /home/mongo/mongodb/myshardrs02_27518/logmkdir -p /home/mongo/mongodb/myshardrs02_27518/data/db新建或修改配置文件
xxxxxxxxxxvim /home/mongo/mongodb/myshardrs02_27318/mongod.confmyshardrs02_27318
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/myshardrs02_27318/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/myshardrs02_27318/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/myshardrs02_27318/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27318replication: #副本集的名称 replSetName: myshardrs02sharding: #分片角色 clusterRole: shardsvr新建或修改配置文件
xxxxxxxxxxvim /home/mongo/mongodb/myshardrs02_27418/mongod.confmyshardrs02_27418
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/myshardrs02_27418/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/myshardrs02_27418/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/myshardrs02_27418/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27418replication: #副本集的名称 replSetName: myshardrs02sharding: #分片角色 clusterRole: shardsvr新建或修改配置文件
xxxxxxxxxxvim /home/mongo/mongodb/myshardrs02_27518/mongod.confmyshardrs02_27518
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/myshardrs02_27518/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/myshardrs02_27518/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/myshardrs02_27518/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27518replication: #副本集的名称 replSetName: myshardrs02sharding: #分片角色 clusterRole: shardsvr启动第二套副本集:一主一副本一仲裁
xxxxxxxxxx/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/myshardrs02_27318/mongod.conf/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/myshardrs02_27418/mongod.conf/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/myshardrs02_27518/mongod.conf

xxxxxxxxxx/home/mongo/mongodb/bin/mongo localhost:27318rs.initiate() #回车两次rs.add("localhost:27418")rs.addArb("localhost:27518")#rs.conf()
配置节点副本集的创建
xxxxxxxxxxmkdir -p /home/mongo/mongodb/myconfigrs_27019/logmkdir -p /home/mongo/mongodb/myconfigrs_27019/data/db
mkdir -p /home/mongo/mongodb/myconfigrs_27119/logmkdir -p /home/mongo/mongodb/myconfigrs_27119/data/db
mkdir -p /home/mongo/mongodb/myconfigrs_27219/logmkdir -p /home/mongo/mongodb/myconfigrs_27219/data/dbxxxxxxxxxxvim /home/mongo/mongodb/myconfigrs_27019/mongod.confMyconfigrs_27019
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/myconfigrs_27019/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/myconfigrs_27019/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/myconfigrs_27019/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27019replication: #副本集的名称 replSetName: myconfigrssharding: #分片角色 clusterRole: configsvrxxxxxxxxxxvim /home/mongo/mongodb/myconfigrs_27119/mongod.confmyconfigrs_27119
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/myconfigrs_27119/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/myconfigrs_27119/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/myconfigrs_27119/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27119replication: #副本集的名称 replSetName: myconfigrssharding: #分片角色 clusterRole: configsvrxxxxxxxxxxvim /home/mongo/mongodb/myconfigrs_27219/mongod.confmyconfigrs_27219
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/myconfigrs_27219/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: truestorage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 dbPath: "/home/mongo/mongodb/myconfigrs_27219/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/myconfigrs_27219/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27219replication: #副本集的名称 replSetName: myconfigrssharding: #分片角色 clusterRole: configsvr启动配置节点副本集:一主二副本
xxxxxxxxxx/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/myconfigrs_27019/mongod.conf/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/myconfigrs_27119/mongod.conf/home/mongo/mongodb/bin/mongod -f /home/mongo/mongodb/myconfigrs_27219/mongod.conf
xxxxxxxxxx/home/mongo/mongodb/bin/mongo localhost:27019rs.initiate() #回车两次rs.add("localhost:27119")rs.add("localhost:27219")rs.conf()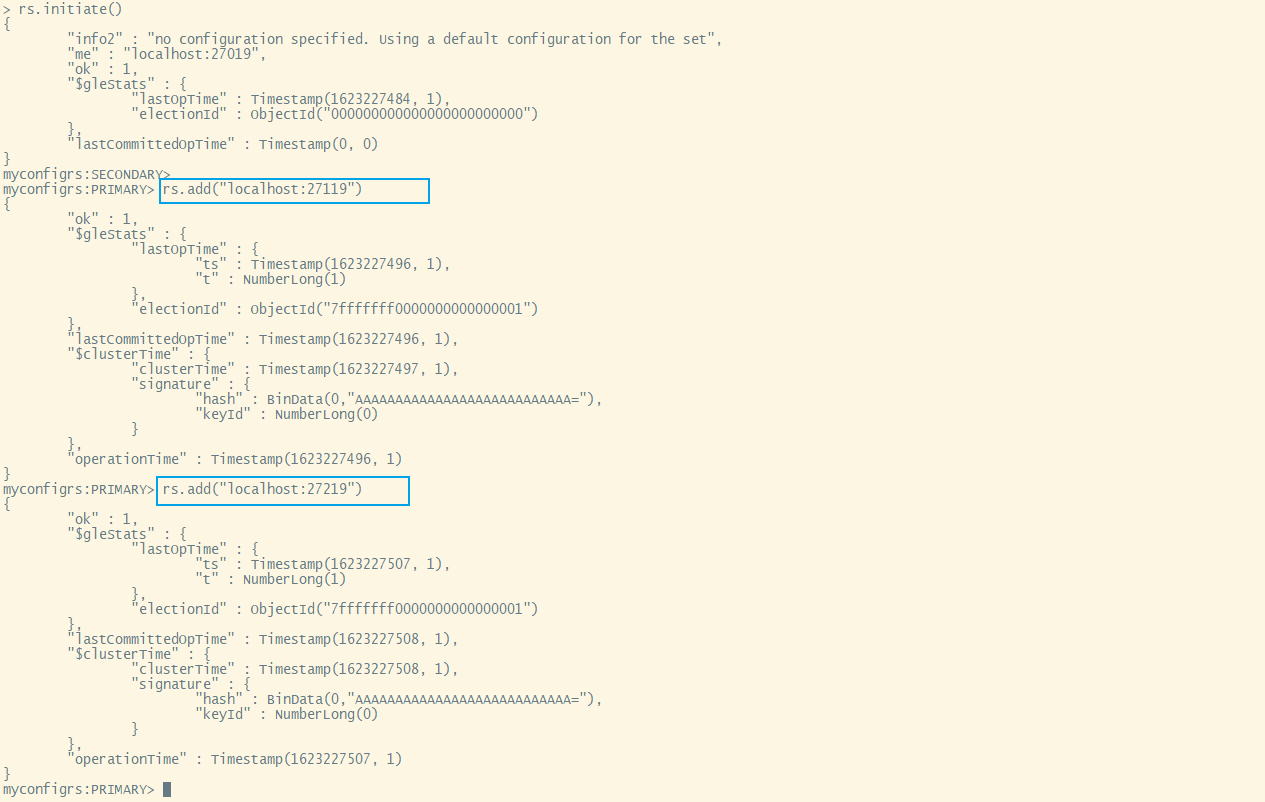

路由集
是mongos的服务,不是mongod的服务
第一步:准备存放日志的目录:
xxxxxxxxxx#-------------------mongos01 路由节点不存放数据,所以不需要存放数据的目录mkdir /home/mongo/mongodb/mymongos_27017/log -pMymongos_27017
新建或修改配置文件:
xxxxxxxxxxvim /home/mongo/mongodb/mymongos_27017/mongos.confmongos.conf
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/mymongos_27017/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: true#storage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 #dbPath: "/home/mongo/mongodb/mymongos_27017/data/db" #journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 #enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/mymongos_27017/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27017sharding: #指定配置节点副本集 configDB: myconfigrs/localhost:27019,localhost:27119,localhost:27219启动并打开mongos路由
xxxxxxxxxx/home/mongo/mongodb/bin/mongos -f /home/mongo/mongodb/mymongos_27017/mongos.conf
/home/mongo/mongodb/bin/mongo localhost:27017
此时路由还不能找到分片,所要要添加分片到路由中。
使用命令添加分片:
分片功能及演示
添加分片
xxxxxxxxxxsh.addShard("IP:Port")将第一套副本集添加进来
xxxxxxxxxxsh.addShard("myshardrs01/localhost:27018,localhost:27118,localhost:27218")#---------------查看分片状况情况sh.status()将第二套副本集添加进来
xxxxxxxxxxsh.addShard("myshardrs02/localhost:27318,localhost:27418,localhost:27518")#---------------查看分片状况情况sh.status()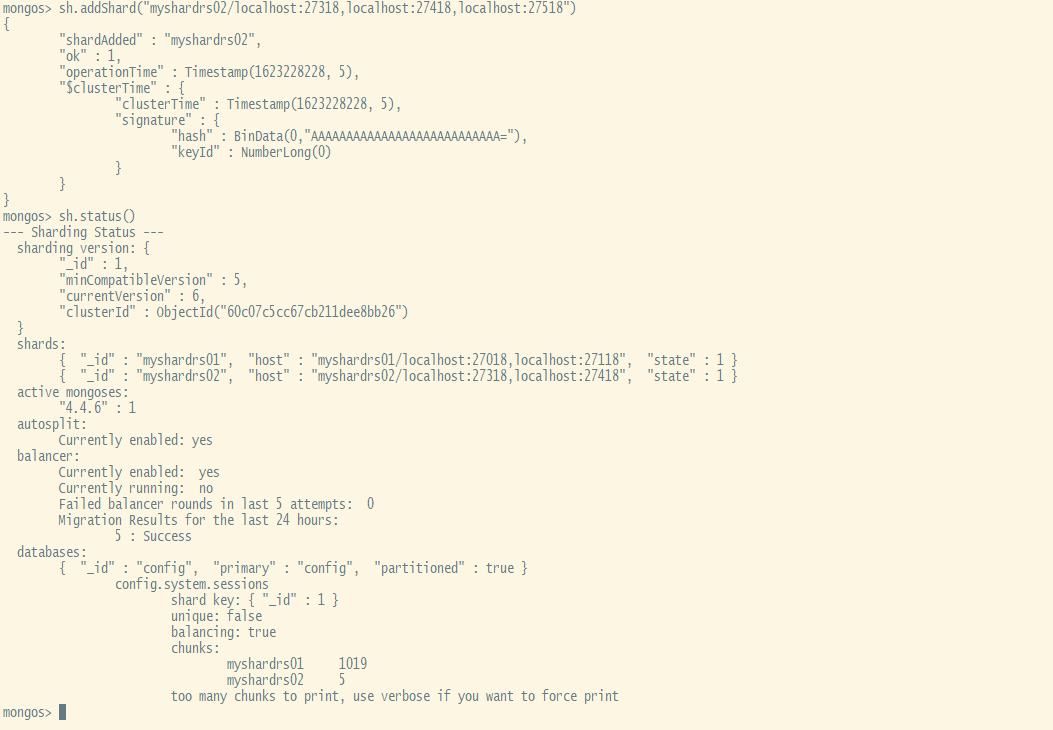
提示:如果添加分片失败,需要先手动移除分片,检查添加分片的信息的正确性后,再次添加分片。
移除分片参考(了解)
xxxxxxxxxxuse admin #选择库db.runCommand( { removeShard: "myshardrs02" } )注意:如果只剩下最后一个shard,是无法删除的 移除时会自动转移分片数据,需要一个时间过程。 完成后,再次执行删除分片命令才能真正删除。
开启DB分片功能
sh.enableSharding("库名")、sh.shardCollection("库名.集合名",{"key":1})
xxxxxxxxxxsh.enableSharding("articledb")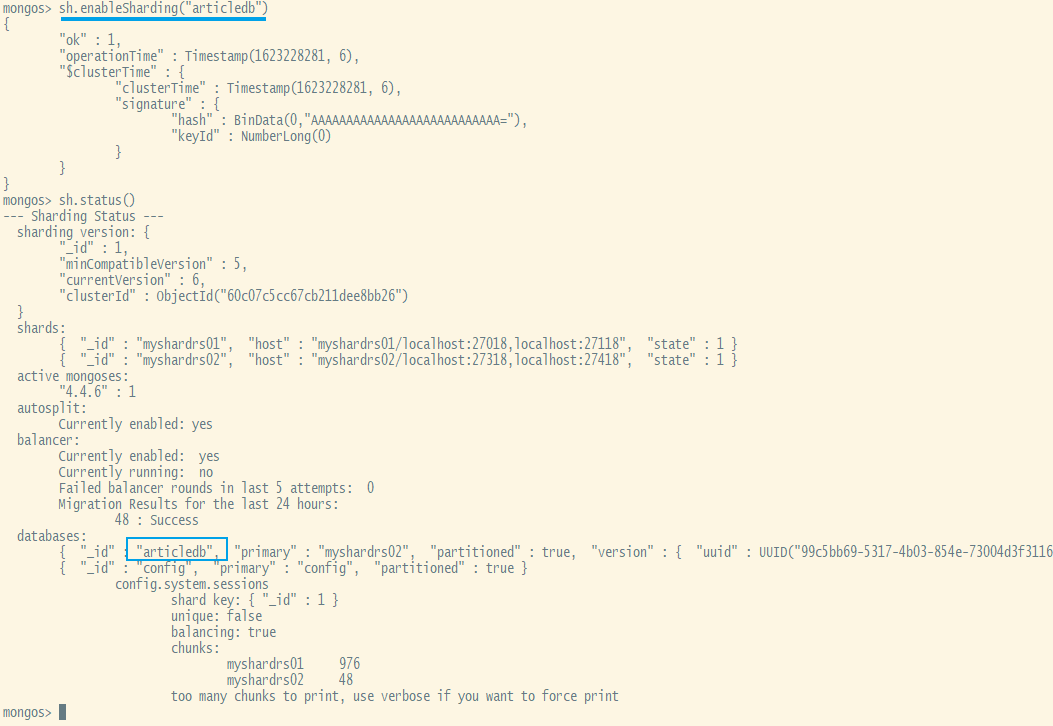
开启集合分片功能
对集合分片,必须使用sh.shardCollection()方法指定集合和分片键
语法:
xxxxxxxxxxsh.shardCollection(namespace,key,unique)| Parameter | Type | Description |
|---|---|---|
| namespace | string | 要(分片)共享对目标集合对命名空间,格式:. |
| key | document | 用作分片键对所以规则文档。shard键决定MongoDB如何在shard之间分法文档。除非集合为空,否则索引必须在shard collection命令之前存在。如果集合为空,则MongoDB在对集合进行分片之前创建索引,前提是支持分片键的索引不存在。简单来说:由包含字段和该字段的索引遍历方向的文档组成。 |
| unique | boolean | 当值为true,片键字段上会限制为确保是唯一索引,哈希策略片键不支持唯一索引,默认为false |
例如在articled库中的comment集合中,以nickname为键,以哈希策略来分片。
xxxxxxxxxx#-------------------------首先开启article库的分片功能sh.enableSharding("articledb")
sh.shardCollection("articledb.comment",{"nickname":"hashed"})分片规则一:哈希策略
对于 基于哈希的分片 ,MongoDB计算一个字段的哈希值,并用这个哈希值来创建数据块.
在使用基于哈希分片的系统中,拥有”相近”片键的文档 很可能不会 存储在同一个数据块中,因此数据的分 离性更好一些.
使用nickname作为片键,根据其值的哈希值进行数据分片
xxxxxxxxxxsh.shardCollection("articledb.comment",{"nickname":"hashed"})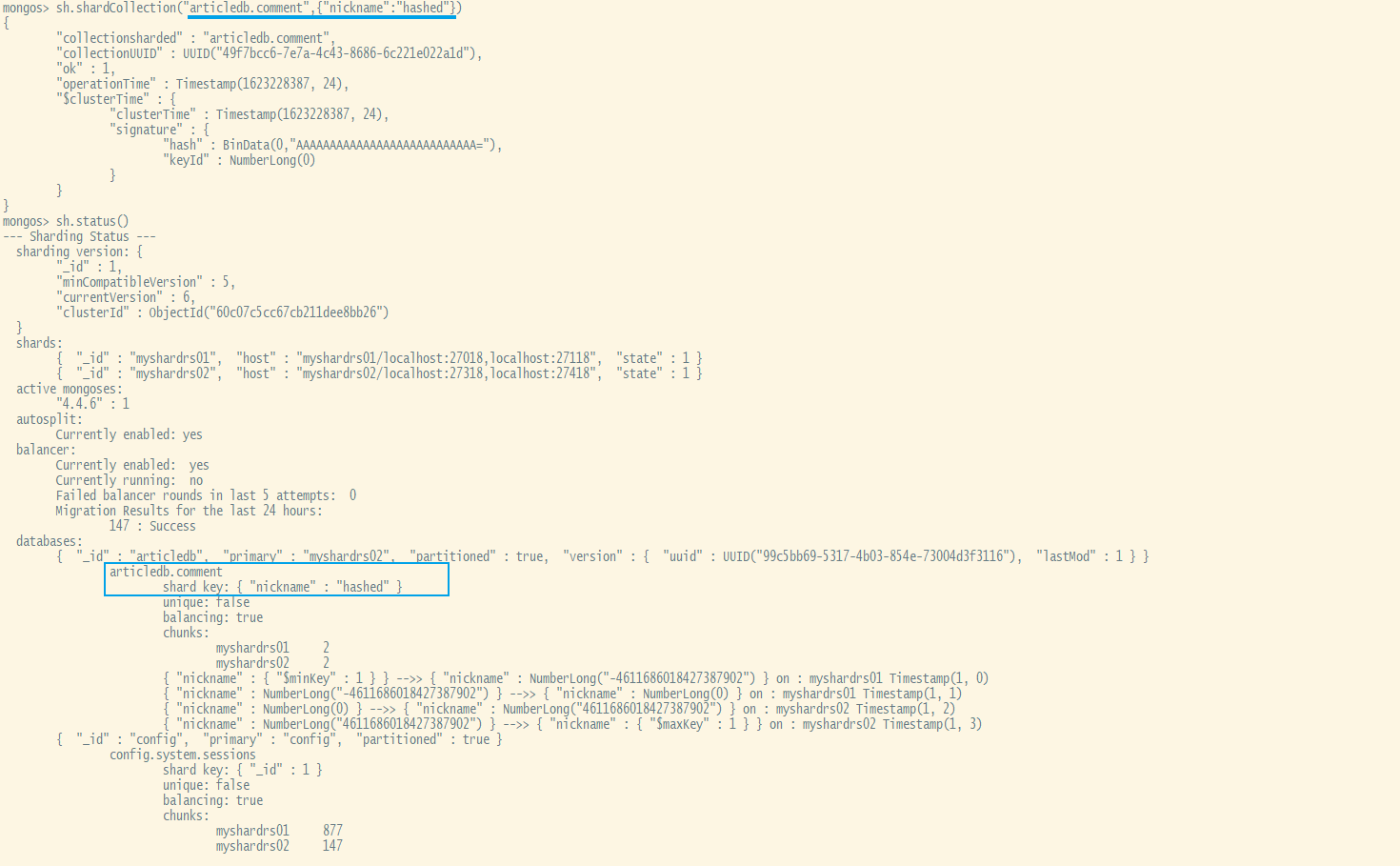
分片测试(哈希规则):登录mongs后,向comment循环插入1000条数据做测试
xxxxxxxxxxuse articledb for(var i=1;i<=1000;i++){db.comment.insert({_id:i+"",nickname:"BoBo"+i})}通过db.comment.count()来查看两分片内的数据条数即可看出效果
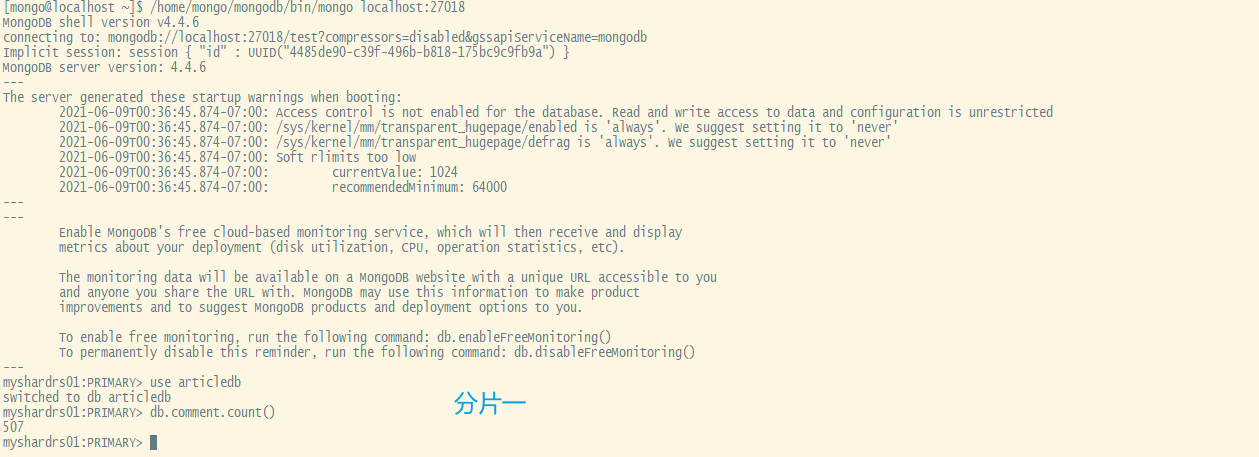
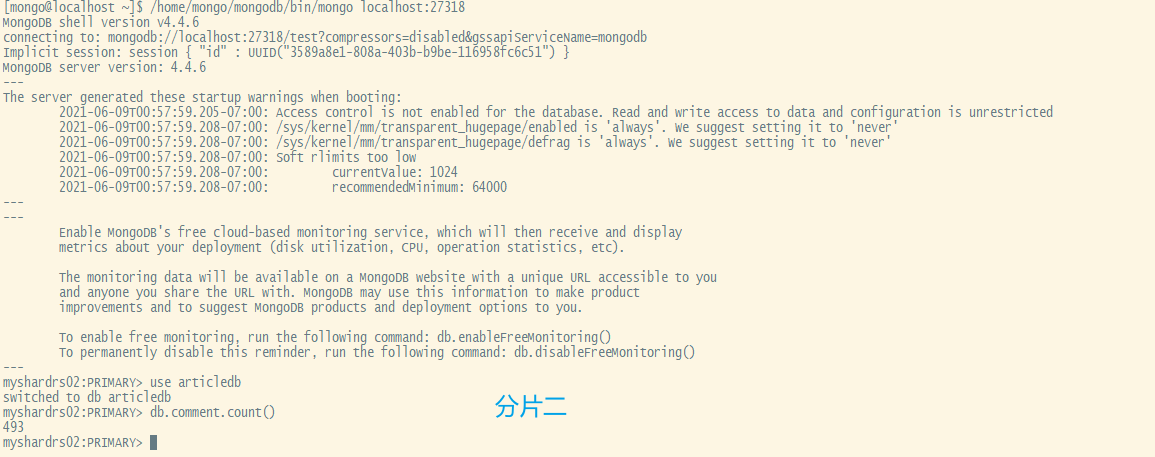
可以看到,1000条数据近似均匀的分布到了2个shard上。是根据片键的哈希值分配的。
这种分配方式非常易于水平扩展:一旦数据存储需要更大空间,可以直接再增加分片即可,同时提升了 性能。
使用db.comment.stats()查看单个集合的完整情况,mongos执行该命令可以查看该集合的数据分片的 情况。
使用sh.status()查看本库内所有集合的分片信息。
分片规则二:范围策略
对于 基于范围的分片 ,MongoDB按照片键的范围把数据分成不同部分.假设有一个数字的片键:想象一个 从负无穷到正无穷的直线,每一个片键的值都在直线上画了一个点.MongoDB把这条直线划分为更短的不 重叠的片段,并称之为 数据块 ,每个数据块包含了片键在一定范围内的数据.
在使用片键做范围划分的系统中,拥有”相近”片键的文档很可能存储在同一个数据块中,因此也会存储在同 一个分片中.
修改默认分片大小:
xxxxxxxxxxuse configdb.settings.save({_id:"chunksize",value:1})
#测试完后记得改回来 不然不容易看到效果#use config#db.settings.save( { _id:"chunksize", value: 64 } )如使用作者收入字段作为片键,按照收入的值进行分片:
xxxxxxxxxxsh.shardCollection("articledb.author",{"income":1})范围分片测试:登录mongs后,向author循环插入80000条数据做测试:
xxxxxxxxxxuse articledbfor(i=1;i<80000;i++){ db.author.insert({"id":i,"name":"clsn","income":i+i*2,"date":new Date()}); }
通过db.author.count()来查看两分片内的数据条数即可看出效果


我们再来看一下当前的分片情况

哈希与范围分片规则对比:
基于范围的分片方式与基于哈希的分片方式性能对比:
基于范围的分片方式提供了更高效的范围查询,给定一个片键的范围,分发路由可以很简单地确定哪个数 据块存储了请求需要的数据,并将请求转发到相应的分片中.
不过,基于范围的分片会导致数据在不同分片上的不均衡,有时候,带来的消极作用会大于查询性能的积极 作用.比如,如果片键所在的字段是线性增长的,一定时间内的所有请求都会落到某个固定的数据块中,最终 导致分布在同一个分片中.在这种情况下,一小部分分片承载了集群大部分的数据,系统并不能很好地进行 扩展.
与此相比,基于哈希的分片方式以范围查询性能的损失为代价,保证了集群中数据的均衡.哈希值的随机性 使数据随机分布在每个数据块中,因此也随机分布在不同分片中.但是也正由于随机性,一个范围查询很难 确定应该请求哪些分片,通常为了返回需要的结果,需要请求所有分片.
如无特殊情况,一般推荐使用 Hash Sharding。
而使用 _id 作为片键是一个不错的选择,因为它是必有的,你可以使用数据文档 _id 的哈希作为片键。
这个方案能够是的读和写都能够平均分布,并且它能够保证每个文档都有不同的片键所以数据块能够很 精细。
似乎还是不够完美,因为这样的话对多个文档的查询必将命中所有的分片。虽说如此,这也是一种比较 好的方案了。
理想化的 shard key 可以让 documents 均匀地在集群中分布:
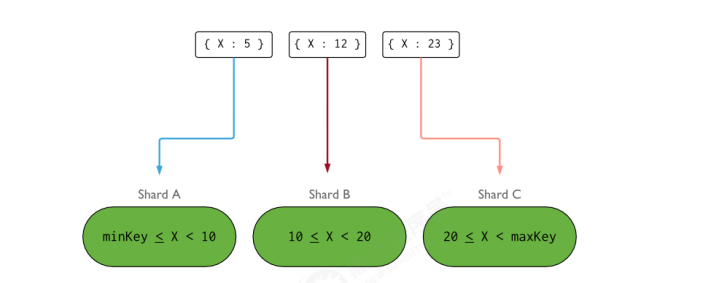
查看分片状态
显示集群的状态:
xxxxxxxxxxsh.status()显示集群的详细信息:
xxxxxxxxxxdb.printShardingStatus()查看均衡器是否工作(需要重新均衡时系统才会自动启动,不用管它):
xxxxxxxxxxsh.isBalancerRunning()查看当前Balancer状态:
xxxxxxxxxxsh.getBalancerState()分片不成功处理
如果查看状态发现没有分片,则可能是由于以下原因造成了:
1)系统繁忙,正在分片中。
2)数据块(chunk)没有填满,默认的数据块尺寸(chunksize)是64M,填满后才会考虑向其他片的 数据块填充数据,因此,为了测试,可以将其改小,这里改为1M,操作如下:
xxxxxxxxxxuse configdb.settings.save({_id:"chunksize",value:1})
测试完改回来:
xxxxxxxxxxdb.settings.save( { _id:"chunksize", value: 64 } )注意:要先改小,再设置分片。为了测试,可以先删除集合,重新建立集合的分片策略,再插入数据测 试即可。
增加第二个路由节点
和创建第一个节点的方式相同,开启服务后不需要再添加分配,会由配置服务自动同步。
xxxxxxxxxxmkdir -p /home/mongo/mongodb/mymongos_27117/log vim /home/mongo/mongodb/mymongos_27117/mongos.confmongos.conf
xxxxxxxxxxsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/home/mongo/mongodb/mymongos_27117/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: true#storage: #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。 #dbPath: "/home/mongo/mongodb/mymongos_27117/data/db" #journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 #enabled: trueprocessManagement: #启用在后台运行mongos或mongod进程的守护进程模式 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/home/mongo/mongodb/mymongos_27117/log/mongod.pid"net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll:true #服务实例绑定的IP bindIp: localhost #bindIp #绑定的端口 port: 27117sharding: #指定配置节点副本集 configDB: myconfigrs/localhost:27019,localhost:27119,localhost:27219启动并打开第二个mongos路由
xxxxxxxxxx/home/mongo/mongodb/bin/mongos -f /home/mongo/mongodb/mymongos_27117/mongos.conf
/home/mongo/mongodb/bin/mongo localhost:27117
使用mongo客户端登录27117,发现,第二个路由无需配置,因为分片配置都保存到了配置服务器中 了。

安全认证
常用的内置角色:
- 数据库用户角色:read、readWrite
- 所有数据库用户角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
- 数据库管理角色:dbAdmin、dbOwner、userAdmin
- 集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager
- 备份恢复角色:backup、restore
- 超级用户角色:root
- 内部角色:system
角色说明:
| 角色 | 权限描述 |
|---|---|
| read | 可以读取数据库中任何数据。 |
| readWrite | 可以读写所有数据库中任何数据,包括创建、重命名、删除集合 |
| readAnyDatabase | 可以读取所有数据库中任何数据(除了数据库config和local之外) |
| readWriteAnyDatabase | 可以读写所有数据库中任何数据(除了数据库config和local之外) |
| userAdminAnyDatabase | 可以在指定数据库创建和修改用户(除了数据库config和local之外) |
| dbAdminAnyDatabase | 可以读取任何数据库以及数据库进行清理、修改、压缩、获取统计信息、执行检查等操作(除了数据库config和local之外)。 |
| dbAdmin | 可以读取指定数据库以及对数据库进行清理、修改、压缩、获取统计信息、执行检查等操作。 |
| userAdmin | 可以指定数据库创建和修改用户 |
| clusterAdmin | 可以对整个集群或数据库系统进行管理操作 |
| backup | 备份MongoDB数据最小的权限 |
| restore | 从备份文件中还原恢复MongoDB数据(处理system.profile集合)的权限 |
| root | 超级账号,超级权限 |
一些问题
外部无法链接mongodb
将conf文件中的bindIp: localhost换成bindIp: 0.0.0.0

rs.add('localhost:27019')报错
错误信息:Either all host names in a replica set configuration must be localhost references, or none must be; found 1 out of 2
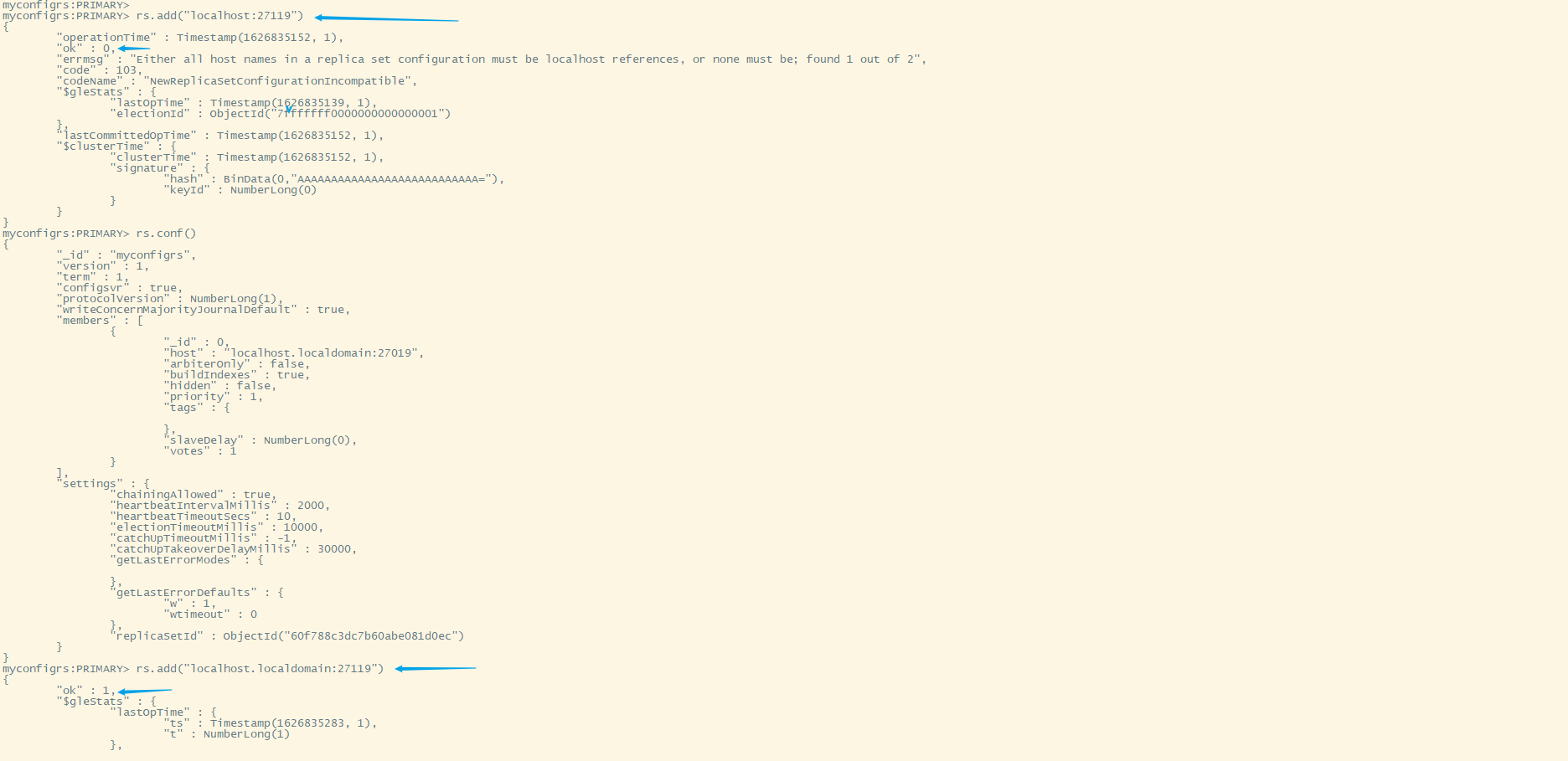
先执行rs.conf()看一下当前members的host值,如上图为localhost.localdomain所以我们将执行rs.add('localhost.localdomain:27019')
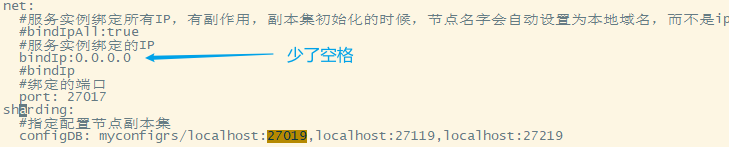
mongod启动报错
错误信息:Error parsing YAML config file: yaml-cpp: error at line 26, column 3: end of map not found
“:”之后有value的话,需要紧跟一个空格
sh.addShard("myshardrs01/localhost:27018,localhost:27118,localhost:27218")报错
错误信息1:Can't use localhost as a shard since all shards need to communicate. Either use all shards and configdbs in localhost or all in actual IPs. host: localhost:27018 isLocalHost:1
错误信息2:in seed list myshardrs01/0.0.0.0:27018,0.0.0.0:27118,0.0.0.0:27218, host 0.0.0.0:27018 does not belong to replica set myshardrs01; found { topologyVersion: { processId: ObjectId('60f7850d3bb7fdb985976f7b'), counter: 8 }, hosts: [ "localhost.localdomain:27018", "localhost.localdomain:27118", "localhost.localdomain:27218" ]...
在(myshardrs01)分片1中执行rs.conf()看一下当前members的host,为localhost.localdomain所以我们将执行以下命令
xxxxxxxxxxsh.addShard("myshardrs01/localhost.localdomain:27018,localhost.localdomain:27118,localhost.localdomain:27218")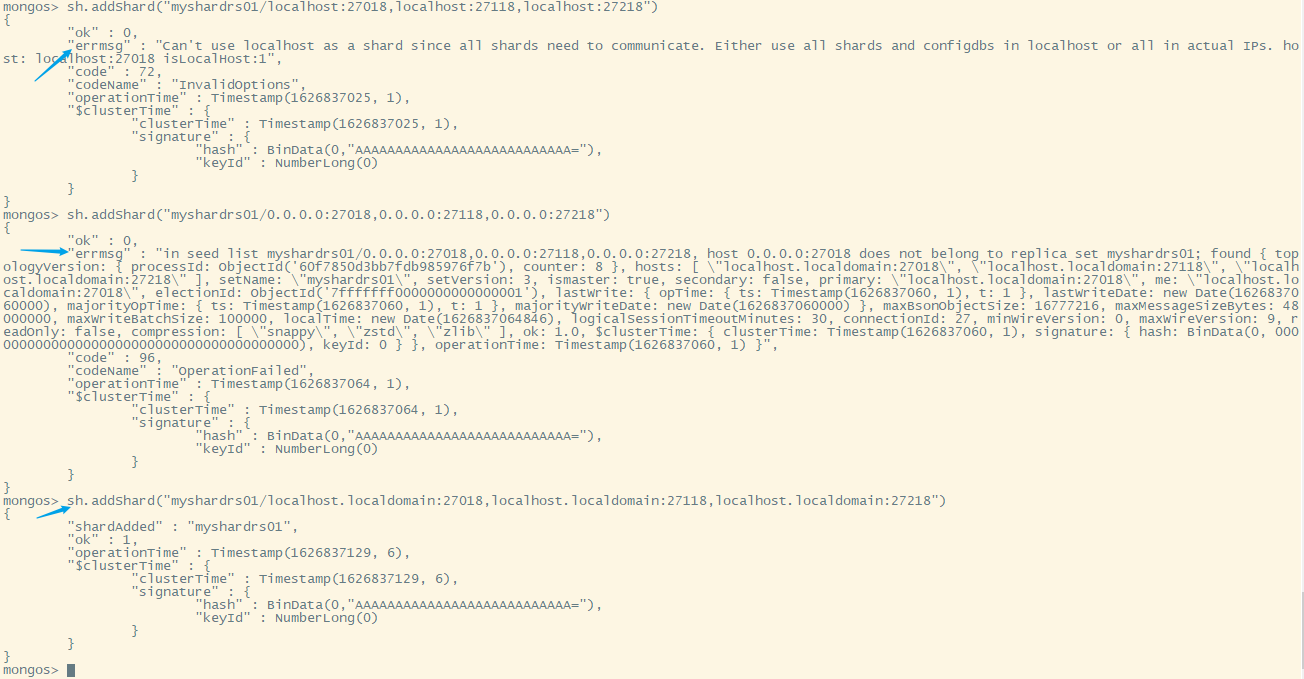
pymongo链接副本集集群
参考:Connection String URI Format — MongoDB Manual
一定要指定副本集的名称(replicaset),以pymongo为例
xxxxxxxxxxclient = pymongo.MongoClient(host=host, port=port,replicaset=replicaset)
pymongo链接分片集群
参考:Connection String URI Format — MongoDB Manual
xxxxxxxxxximport pymongo# client = pymongo.MongoClient(host='192.168.6.197', port=27017) 链接单个mongosclient = pymongo.MongoClient("mongodb://192.168.6.197:27017,192.168.6.197:27117") #链接多(单)个mongosdb = client['articledb']doc = db['comment']for i in range(20001,22000): doc.insert_one({'_id':i,'nickname':'BOBO'+str(i)})
itemList = list()for i in range(22001,30000): itemList.append({'_id':i,'nickname':'BOBO'+str(i)})
doc.insert_many(itemList)不要直接用kill -9 来强制关闭mongodb进程
参考:【MongoDB 高可用篇】MongoDB Sharding Cluster启动和关闭过程 - 追梦男生 - 博客园 (cnblogs.com)
关闭副本集集群
先关掉从节点、仲裁节点,最后关闭主节点
xxxxxxxxxxuse admindb.shutdownServer()关闭分片集群
先关闭所有的mongos路由服务
xxxxxxxxxxuse admindb.shutdownServer()再关闭所有的副本集,先关掉从节点、仲裁节点,最后关闭主节点
xxxxxxxxxxuse admindb.shutdownServer()最后关闭配置节点副本集,先关掉从节点、仲裁节点,最后关闭主节点
xxxxxxxxxxuse admindb.shutdownServer()mongodb插入时报错
错误信息:'errmsg': 'E11000 duplicate key error collection: articledb.comment index: id dup key: { _id: 999 }'}
_id:999 主键_Id重复了
mongodb插入时自动添加_t,_v属性
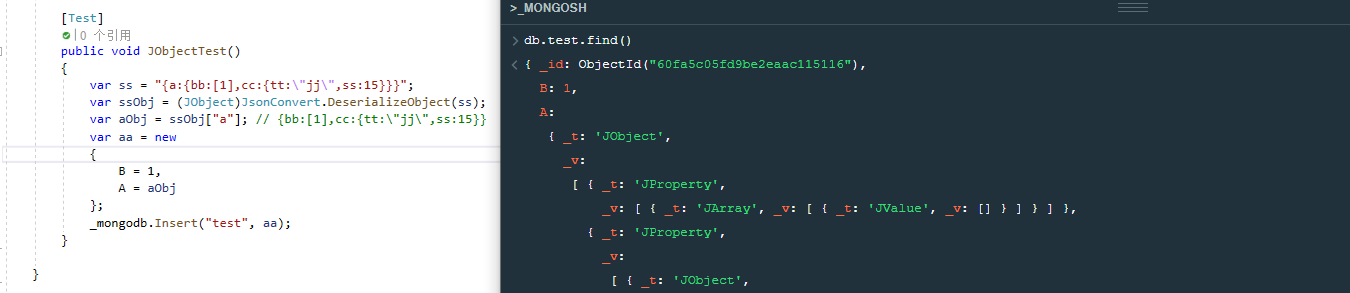
首先我们先插入一个匿名类,会自动出现_t,_v属性,JObject、JToken无法直接插入mongodb,失败
再改下代码,插入一个匿名类,此时不会出现_t,_v属性,成功
xxxxxxxxxxvar aa = new { B = 1, //A = JsonConvert.DeserializeObject<Dictionary<string, object>>(aObj.ToString()), //不管用 //A = JObject.Parse(aObj.ToString()), //不管用 A = BsonDocument.Parse(aObj.ToString()) };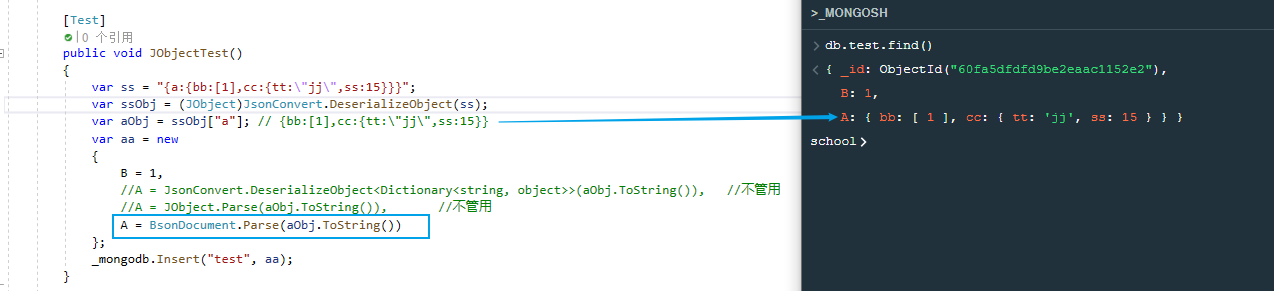
再改下代码,插入一个实体类,此时会出现_t,_v属性,失败
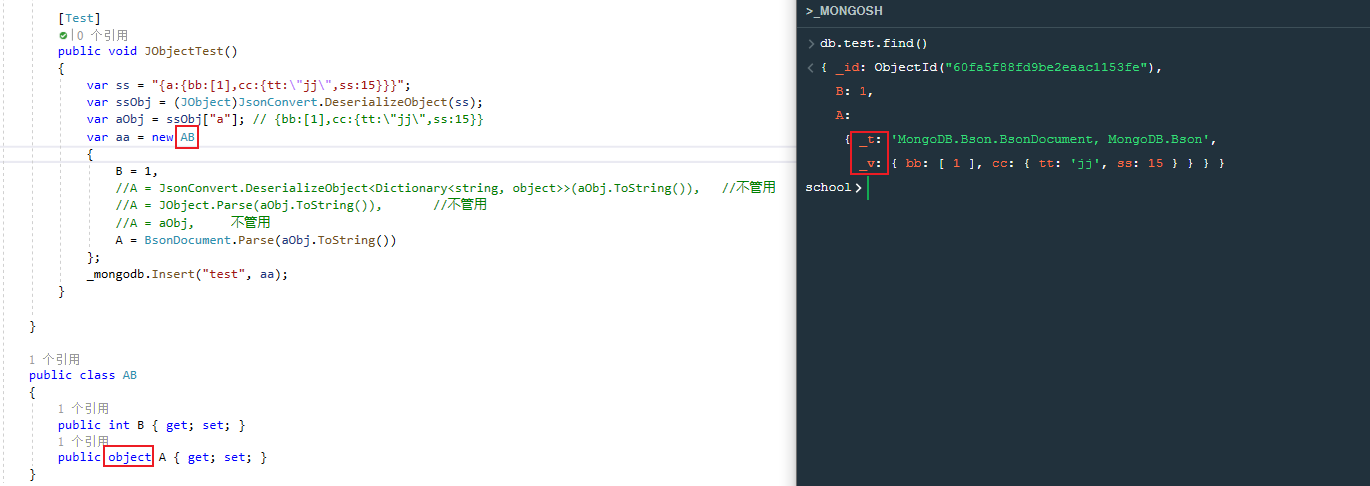
要将对象AB插入mongodb,此时字段A需要接收的是object类型,而我们却给他传递BsonDocument类型(具体类型),虽然程序是可以正常编译执行,但是插入mongodb时,mongodb会自动帮我们指出字段A的类型,也就是自动帮我们加上_t,_v属性。
再改下代码,插入一个实体类,并将字段A赋值匿名对象,此时不会_t,_v属性,但不符合逻辑,因为我们想要给A赋值为aObj对象,失败
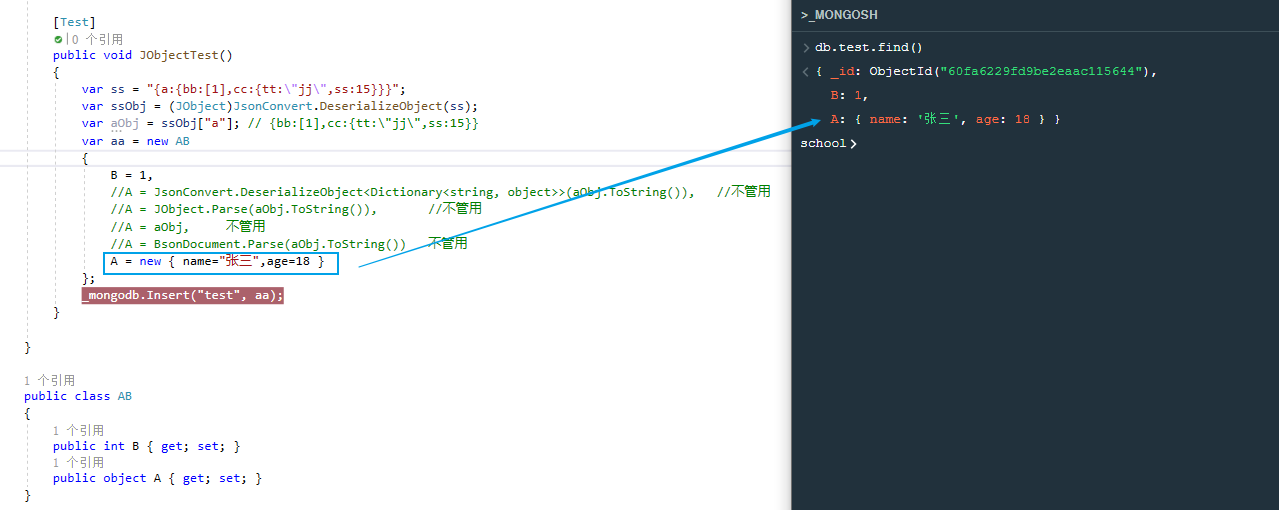
再改下代码,插入一个实体类,将对象AB中的字段A类型改为BsonDocument,此时不会_t,_v属性,成功
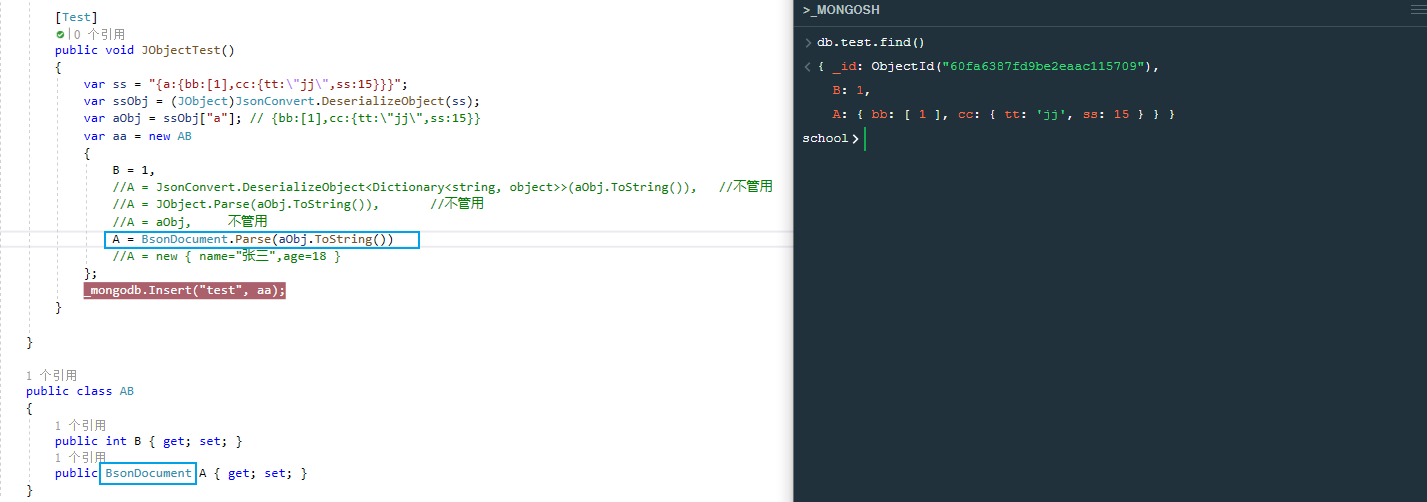
如果我们把对象AB中的字段A类型改为Jobject、JToken类型也是不可以的